Recognition: unknown
Self-Induced Outcome Potential: Turn-Level Credit Assignment for Agents without Verifiers
Pith reviewed 2026-05-08 17:08 UTC · model grok-4.3
The pith
SIOP assigns turn-level rewards to LLM agents by clustering semantic outcomes from multiple rollouts without external verifiers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SIOP treats semantic clusters of final answers as latent future outcome states. For each query it samples multiple rollouts, forms clusters, constructs a reliability-aware target distribution over those clusters, and defines turn-level rewards via a tractable approximation of the change in posterior support for reliable states. This produces a verifier-free objective that recovers the gold-supervised case as a limit and improves average performance over outcome-level baselines on seven search-augmented agentic reasoning benchmarks.
What carries the argument
Self-Induced Outcome Potential (SIOP), which defines turn-level rewards by approximating potential-based shaping over unsupervised semantic clusters of final answers treated as proxy outcome states.
If this is right
- Turn-level credit assignment becomes feasible for agents that receive feedback only at the final answer.
- Process-level shaping no longer requires human annotations or stable task-specific verifiers.
- The same objective can be used on open-ended agentic tasks where gold answers are unavailable.
- Training avoids the rollout-level advantage broadcast used by standard GRPO-style methods.
Where Pith is reading between the lines
- The clustering step could be replaced by learned embeddings or external knowledge sources to reduce sensitivity to unsupervised grouping errors.
- SIOP-style shaping might combine with other self-generated signals such as consistency checks across rollouts.
- The approach opens a route to scaling agent training in domains where defining reliable verifiers is impractical.
Load-bearing premise
Semantic clusters formed from final answers reliably represent distinct latent outcome states and yield stable turn-level rewards without bias or noise from the unsupervised clustering step.
What would settle it
If the clusters of final answers from multiple rollouts show no correlation with actual outcome quality on a held-out benchmark, the turn-level rewards produced by SIOP would fail to outperform standard outcome-level baselines.
Figures




read the original abstract
Long-horizon LLM agents depend on intermediate information-gathering turns, yet training feedback is usually observed only at the final answer, because process-level rewards require high-quality human annotation. Existing turn-level shaping methods reward turns that increase the likelihood of a gold answer, but they require answer supervision or stable task-specific verifiers. Conversely, label-free RL methods extract self-signals from output distributions, but mainly at the answer or trajectory level and therefore cannot assign credit to intermediate turns. We propose Self-Induced Outcome Potential (SIOP), which treats semantic clusters of final answers as latent future outcome states for potential-based turn-level credit assignment. For each query, SIOP samples multiple rollouts, clusters final answers into semantic outcome modes, and builds a reliability-aware target distribution over these states. It then rewards turns for increasing posterior support for reliable future states using a tractable cluster-level approximation. The objective generalizes information-potential shaping from gold-answer supervision to settings without task-specific gold verifiers while avoiding the broadcasted rollout-level advantages used by standard GRPO. We formalize the framework, characterize its supervised gold-answer limit, and show that SIOP improves average performance over verifier-free outcome-level baselines on seven search-augmented agentic reasoning benchmarks while approaching a gold-supervised outcome baseline. Code is available at https://github.com/dl-m9/SIOP.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Self-Induced Outcome Potential (SIOP) for turn-level credit assignment in long-horizon LLM agents without verifiers or gold labels. It samples multiple rollouts per query, clusters final answers into semantic outcome modes using embeddings, constructs a reliability-aware target distribution over clusters, and applies a tractable cluster-level approximation to assign potential-based rewards to intermediate turns that increase posterior support for reliable states. The framework is formalized, its reduction to the gold-supervised information-potential limit is characterized, and empirical results claim average gains over verifier-free outcome-level baselines on seven search-augmented agentic reasoning benchmarks while approaching supervised performance. Open-source code is provided.
Significance. If the central empirical claim holds under rigorous controls, SIOP would offer a practical route to process-level shaping for agentic LLMs in the absence of task-specific verifiers, generalizing potential-based methods beyond supervised settings. The formalization of the supervised limit case and the release of reproducible code are clear strengths that facilitate verification and extension.
major comments (3)
- [§3] §3 (SIOP framework): the assumption that unsupervised semantic clusters of final answers form stable, semantically aligned proxies for distinct latent outcome states is load-bearing for the turn-level reward derivation, yet no quantitative validation (e.g., cluster stability across independent rollouts, normalized mutual information with outcome labels, or sensitivity to embedding model / k) is supplied; without this, the cluster-level approximation risks injecting arbitrary bias relative to true outcome differences.
- [§5] §5 (Experiments): the reported average performance improvements over verifier-free baselines on seven benchmarks are presented without any mention of number of random seeds, statistical significance tests, variance across runs, or failure-case analysis, rendering it impossible to assess whether the gains are robust or could be explained by clustering artifacts.
- [Abstract and §4] Abstract and §4 (supervised limit): the claim that SIOP approaches a gold-supervised outcome baseline while remaining verifier-free is undercut by the absence of an explicit derivation showing that the reliability-aware target distribution and cluster approximation do not implicitly recover quantities fitted from the same gold signals used in the supervised comparator.
minor comments (2)
- [§3] Notation for the reliability-aware target distribution (likely Eq. in §3) could be clarified with an explicit algorithmic pseudocode box to distinguish it from standard GRPO advantages.
- [§2] The related-work discussion of label-free RL methods would benefit from a direct table contrasting SIOP's turn-level mechanism against trajectory-level self-signals in prior work.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and recommendations. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [§3] §3 (SIOP framework): the assumption that unsupervised semantic clusters of final answers form stable, semantically aligned proxies for distinct latent outcome states is load-bearing for the turn-level reward derivation, yet no quantitative validation (e.g., cluster stability across independent rollouts, normalized mutual information with outcome labels, or sensitivity to embedding model / k) is supplied; without this, the cluster-level approximation risks injecting arbitrary bias relative to true outcome differences.
Authors: We agree that validating the semantic clusters as reliable proxies for latent outcomes is important for the framework's validity. The manuscript builds on prior work showing that embedding-based clustering effectively captures semantic distinctions in generated text. To strengthen this, we will add quantitative validation in the revised §3, including: (1) cluster stability measured by adjusted Rand index across multiple independent rollouts and clustering runs; (2) normalized mutual information with human-annotated outcome labels on a subset of benchmarks where available; and (3) ablation on sensitivity to embedding model choice and number of clusters k. These additions will demonstrate that the clusters align with meaningful outcome differences rather than arbitrary partitions. revision: yes
-
Referee: [§5] §5 (Experiments): the reported average performance improvements over verifier-free baselines on seven benchmarks are presented without any mention of number of random seeds, statistical significance tests, variance across runs, or failure-case analysis, rendering it impossible to assess whether the gains are robust or could be explained by clustering artifacts.
Authors: The referee is correct that robustness details were omitted. In the revised manuscript, we will expand §5 to include: results averaged over at least 5 random seeds with reported standard deviations; statistical significance testing (e.g., Wilcoxon signed-rank tests or paired t-tests) against the baselines; and a dedicated failure-case analysis examining instances where SIOP underperforms to rule out clustering artifacts as the source of gains. This will provide a more rigorous assessment of the empirical claims. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (supervised limit): the claim that SIOP approaches a gold-supervised outcome baseline while remaining verifier-free is undercut by the absence of an explicit derivation showing that the reliability-aware target distribution and cluster approximation do not implicitly recover quantities fitted from the same gold signals used in the supervised comparator.
Authors: The manuscript characterizes the supervised limit in §4, where SIOP reduces to gold-supervised information potential when clusters correspond to gold outcomes. However, to explicitly address potential concerns about implicit gold signal recovery, we will augment the derivation in the revised §4. Specifically, we will show step-by-step that the reliability-aware target distribution is constructed purely from the empirical distribution of unsupervised cluster assignments across rollouts, and the cluster-level approximation uses only embedding similarities and posterior updates without any access to gold labels. This ensures the verifier-free variant operates independently of gold signals, while the performance comparison to the supervised baseline is external. We believe this clarification will resolve the issue. revision: partial
Circularity Check
Derivation is self-contained; no load-bearing step reduces to self-definition or fitted input renamed as prediction
full rationale
The paper defines SIOP via semantic clustering of sampled final answers as proxy latent states, constructs a reliability-aware target distribution, and applies a cluster-level approximation to assign turn-level rewards that increase posterior support for reliable states. It explicitly characterizes the gold-supervised limit case and reports empirical gains on seven benchmarks against verifier-free baselines while approaching gold supervision. No equation equates the reported performance improvement to a quantity defined solely by the clustering procedure or approximation itself; the central claims rest on external benchmark comparisons rather than internal reduction. This yields at most a minor self-citation risk without circularity in the derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OpenAI o1 System Card, 2026
OpenAI. OpenAI o1 System Card, 2026. 10
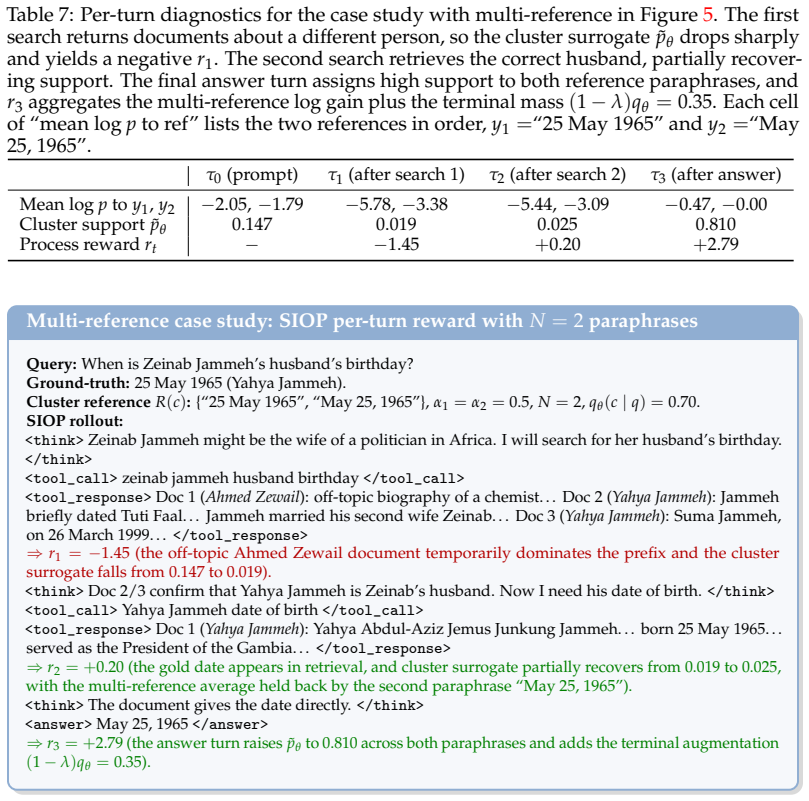
2026
-
[2]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[3]
Yangning Li, Weizhi Zhang, Yuyao Yang, Wei-Chieh Huang, Yaozu Wu, Junyu Luo, Yuanchen Bei, Henry Peng Zou, Xiao Luo, Yusheng Zhao, Chunkit Chan, Yankai Chen, Zhongfen Deng, Yinghui Li, Hai-Tao Zheng, Dongyuan Li, Renhe Jiang, Ming Zhang, Yangqiu Song, and Philip S. Yu. Towards Agentic RAG with Deep Reasoning: A Survey of RAG-Reasoning Systems in LLMs. InF...
-
[4]
Kimi K2: Open Agentic Intelligence, 2026
Kimi Team. Kimi K2: Open Agentic Intelligence, 2026
2026
-
[5]
Pan, Wen Zhang, Huajun Chen, Fan Yang, Zenan Zhou, and Weipeng Chen
Mingyang Chen, Linzhuang Sun, Tianpeng Li, Haoze Sun, Yijie Zhou, Chenzheng Zhu, Haofen Wang, Jeff Z. Pan, Wen Zhang, Huajun Chen, Fan Yang, Zenan Zhou, and Weipeng Chen. ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning. InAdvances in Neural Information Processing Systems, 2025
2025
-
[6]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning. InSecond Conference on Language Modeling, 2025
2025
-
[7]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji. ToolRL: Reward is All Tool Learning Needs. InAdvances in Neural Information Processing Systems, 2025
2025
-
[8]
SimpleTIR: End-to-End Reinforcement Learning for Multi-Turn Tool-Integrated Reasoning
Zhenghai Xue, Longtao Zheng, Qian Liu, Yingru Li, Xiaosen Zheng, Zejun MA, and Bo An. SimpleTIR: End-to-End Reinforcement Learning for Multi-Turn Tool-Integrated Reasoning. In The Fourteenth International Conference on Learning Representations, 2026
2026
-
[9]
Process vs
Wenlin Zhang, Xiangyang Li, Kuicai Dong, Yichao Wang, Pengyue Jia, Xiaopeng Li, Yingyi Zhang, Derong Xu, Zhaocheng Du, Huifeng Guo, Ruiming Tang, and Xiangyu Zhao. Process vs. Outcome Reward: Which is Better for Agentic RAG Reinforcement Learning. InAdvances in Neural Information Processing Systems, 2025
2025
-
[10]
Scent of Knowledge: Optimizing Search-Enhanced Reasoning with Information Foraging
Hongjin Qian and Zheng Liu. Scent of Knowledge: Optimizing Search-Enhanced Reasoning with Information Foraging. InAdvances in Neural Information Processing Systems, 2025
2025
-
[11]
Information Gain-based Policy Optimization: A Simple and Effective Approach for Multi-Turn Search Agents
Guoqing Wang, Sunhao Dai, Guangze Ye, Zeyu Gan, Wei Yao, Yong Deng, Xiaofeng Wu, and Zhenzhe Ying. Information Gain-based Policy Optimization: A Simple and Effective Approach for Multi-Turn Search Agents. InInternational Conference on Learning Representations, 2026
2026
-
[12]
Intrinsic Credit Assignment for Long Horizon Interaction, 2026
Ilze Amanda Auzina, Joschka Strüber, Sergio Hernández-Gutiérrez, Shashwat Goel, Ameya Prabhu, and Matthias Bethge. Intrinsic Credit Assignment for Long Horizon Interaction, 2026
2026
-
[13]
TIPS: Turn-level Information-Potential Reward Shaping for Search-Augmented LLMs
Yutao Xie, Nathaniel Thomas, Nicklas Hansen, Yang Fu, Li Erran Li, and Xiaolong Wang. TIPS: Turn-level Information-Potential Reward Shaping for Search-Augmented LLMs. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[14]
InfoPO: Information-Driven Policy Optimization for User-Centric Agents
Fanqi Kong, Jiayi Zhang, Mingyi Deng, Chenglin Wu, Yuyu Luo, and Bang Liu. InfoPO: Information-Driven Policy Optimization for User-Centric Agents. InICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving, 2026
2026
-
[15]
Right Question is Already Half the Answer: Fully Unsupervised LLM Reasoning Incentivization
Qingyang Zhang, Haitao Wu, Changqing Zhang, Peilin Zhao, and Yatao Bian. Right Question is Already Half the Answer: Fully Unsupervised LLM Reasoning Incentivization. InAdvances in Neural Information Processing Systems, 2025
2025
-
[16]
TTRL: Test-Time Reinforcement Learning
Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, Biqing Qi, Youbang Sun, Zhiyuan Ma, Lifan Yuan, Ning Ding, and Bowen Zhou. TTRL: Test-Time Reinforcement Learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[17]
RLPR: Extrapolating RLVR to General Domains without Verifiers, 2025
Tianyu Yu, Bo Ji, Shouli Wang, Shu Yao, Zefan Wang, Ganqu Cui, Lifan Yuan, Ning Ding, Yuan Yao, Zhiyuan Liu, Maosong Sun, and Tat-Seng Chua. RLPR: Extrapolating RLVR to General Domains without Verifiers, 2025. 11
2025
-
[18]
NOVER: Incentive Training for Language Models via Verifier-Free Reinforcement Learning
Wei Liu, Siya Qi, Xinyu Wang, Chen Qian, Yali Du, and Yulan He. NOVER: Incentive Training for Language Models via Verifier-Free Reinforcement Learning. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 7439–7458, Suzhou, C...
2025
-
[19]
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/ 2025.emnlp-main.378
-
[20]
Direct Reasoning Optimization: Constrained RL with Token-Level Dense Reward and Rubric-Gated Constraints for Open-ended Tasks, 2026
Yifei Xu, Tusher Chakraborty, Srinagesh Sharma, Leonardo Nunes, Swati Sharma, Kate Drakos Demopulos, Emre Kıcıman, Songwu Lu, and Ranveer Chandra. Direct Reasoning Optimization: Constrained RL with Token-Level Dense Reward and Rubric-Gated Constraints for Open-ended Tasks, 2026
2026
-
[21]
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[22]
https://aclanthology.org/ Q19-1026/
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural Questions: A Benchmark for Question Answering Research.Transact...
-
[23]
Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi- hop QA dataset for comprehensive evaluation of reasoning steps. In Donia Scott, Nuria Bel, and Chengqing Zong, editors,Proceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, Barcelona, Spain (Online), December 2020. International...
-
[24]
T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Regina Barzilay and Min-Yen Kan, editors,Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, Vancouver, Canada, July 2017. A...
-
[25]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceed- ings of the 2018 Conference on Empirical Methods in Natural Language Process...
-
[26]
M u S i Q ue: Multihop questions via single-hop question composition
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. ♪ MuSiQue: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022. doi: 10.1162/tacl_a_00475
-
[27]
Prabha, D., Aswini, J., Maheswari, B., Subramanian, R
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah Smith, and Mike Lewis. Measuring and Narrowing the Compositionality Gap in Language Models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, Singapore, December 2023. Association for Computational Linguistics...
-
[28]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (...
-
[29]
Qwen3 Technical Report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
-
[30]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, 2024
2024
-
[31]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review arXiv 2025
-
[32]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review arXiv 2025
-
[33]
Let’s Verify Step by Step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s Verify Step by Step. InInternational Conference on Learning Representations, 2024
2024
-
[34]
Entropy-Regularized Process Reward Model, 2025
Hanning Zhang, Pengcheng Wang, Shizhe Diao, Yong Lin, Rui Pan, Hanze Dong, Dylan Zhang, Pavlo Molchanov, and Tong Zhang. Entropy-Regularized Process Reward Model, 2025
2025
-
[35]
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking. InProceedings of the 42nd International Conference on Machine Learning, 2025
2025
-
[36]
VinePPO: Refining Credit Assignment in RL Training of LLMs
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. VinePPO: Refining Credit Assignment in RL Training of LLMs. InProceedings of the 42nd International Conference on Machine Learning, 2025
2025
-
[37]
Segment Policy Optimization: Effective Segment-Level Credit Assignment in RL for Large Language Models
Yiran Guo, Lijie Xu, Jie Liu, Ye Dan, and Shuang Qiu. Segment Policy Optimization: Effective Segment-Level Credit Assignment in RL for Large Language Models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[38]
Exploiting Tree Structure for Credit Assignment in RL Training of LLMs, 2025
Hieu Tran, Zonghai Yao, and Hong Yu. Exploiting Tree Structure for Credit Assignment in RL Training of LLMs, 2025
2025
-
[39]
Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Reward Design, 2025
Quan Wei, Siliang Zeng, Chenliang Li, William Brown, Oana Frunza, Wei Deng, Anderson Schneider, Yuriy Nevmyvaka, Yang Katie Zhao, Alfredo Garcia, and Mingyi Hong. Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Reward Design, 2025
2025
-
[40]
Senkang Hu, Yong Dai, Yuzhi Zhao, Yihang Tao, Yu Guo, Zhengru Fang, Sam Tak Wu Kwong, and Yuguang Fang. Optimizing Agentic Reasoning with Retrieval via Synthetic Semantic Information Gain Reward.arXiv preprint arXiv:2602.00845, 2026
-
[41]
Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
2024
-
[42]
Minghan Chen, Guikun Chen, Wenguan Wang, and Yi Yang. SEED-GRPO: Semantic Entropy Enhanced GRPO for Uncertainty-Aware Policy Optimization, May 2025. arXiv:2505.12346 [cs]
-
[43]
The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning
Shivam Agarwal, Zimin Zhang, Lifan Yuan, Jiawei Han, and Hao Peng. The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning. InAdvances in Neural Information Processing Systems, 2025
2025
-
[44]
From Exploration to Exploitation: A Two-Stage Entropy RLVR Approach for Noise-Tolerant MLLM Training
Donglai Xu, Hongzheng Yang, Yuzhi Zhao, Pingping Zhang, Jinpeng Chen, Wenao Ma, Zhijian Hou, Mengyang Wu, Xiaolei Li, Senkang Hu, Ziyi Guan, Jason Chun Lok Li, and Lai Man Po. From Exploration to Exploitation: A Two-Stage Entropy RLVR Approach for Noise-Tolerant MLLM Training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni...
2026
-
[45]
RESTRAIN: From Spurious Votes to Signals— Self-Training RL with Self-Penalization
Zhaoning Yu, Zhaolun Su, Leitian Tao, Haozhu Wang, Aashu Singh, Hanchao Yu, Jianyu Wang, Hongyang Gao, Weizhe Yuan, Jason E Weston, et al. RESTRAIN: From Spurious Votes to Signals— Self-Training RL with Self-Penalization. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[46]
Reinforcing General Reasoning without Verifiers
Xiangxin Zhou, Zichen Liu, Anya Sims, Haonan Wang, Tianyu Pang, Chongxuan Li, Liang Wang, Min Lin, and Chao Du. Reinforcing General Reasoning without Verifiers. InInternational Conference on Learning Representations, 2026
2026
-
[47]
Learning to Reason without External Rewards
Xuandong Zhao, Zhewei Kang, Aosong Feng, Sergey Levine, and Dawn Song. Learning to Reason without External Rewards. InInternational Conference on Learning Representations, 2026. 13
2026
-
[48]
Self-rewarding language models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[49]
Self-play fine-tuning convertsweak language models to strong language models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning convertsweak language models to strong language models. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[50]
arXiv preprint arXiv:2506.24119 , year=
Bo Liu, Leon Guertler, Simon Yu, Zichen Liu, Penghui Qi, Daniel Balcells, Mickel Liu, Cheston Tan, Weiyan Shi, Min Lin, Wee Sun Lee, and Natasha Jaques. SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning.arXiv preprint arXiv:2506.24119, 2025
-
[51]
Spice: Self-play in corpus environments improves reasoning.arXiv, 2025
Bo Liu, Chuanyang Jin, Seungone Kim, Weizhe Yuan, Wenting Zhao, Ilia Kulikov, Xian Li, Sain- bayar Sukhbaatar, Jack Lanchantin, and Jason Weston. SPICE: Self-Play In Corpus Environments Improves Reasoning.arXiv preprint arXiv:2510.24684, 2025
-
[52]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute Zero: Reinforced Self-play Reasoning with Zero Data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[53]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-Zero: Self-Evolving Reasoning LLM from Zero Data. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[54]
Pan, Wen Zhang, Huajun Chen, Fan Yang, Zenan Zhou, and Weipeng Chen
Mingyang Chen, Linzhuang Sun, Tianpeng Li, Haoze Sun, Yijie Zhou, Chenzheng Zhu, Haofen Wang, Jeff Z. Pan, Wen Zhang, Huajun Chen, Fan Yang, Zenan Zhou, and Weipeng Chen. ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning, September
- [55]
-
[56]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-Group Policy Optimization for LLM Agent Training. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[57]
Mixture-of-Retrieval Experts for Reasoning-Guided Multimodal Knowledge Exploitation
Chunyi Peng, Zhipeng Xu, Zhenghao Liu, Yishan Li, Yukun Yan, Shuo Wang, Zhiyuan Liu, Yu Gu, Minghe Yu, Ge Yu, and Maosong Sun. Learning to Route Queries Across Knowledge Bases for Step-wise Retrieval-Augmented Reasoning, May 2025. arXiv:2505.22095 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Tree Search for LLM Agent Reinforcement Learning
Yuxiang Ji, Ziyu Ma, Yong Wang, Guanhua Chen, Xiangxiang Chu, and Liaoni Wu. Tree Search for LLM Agent Reinforcement Learning. InThe Fourteenth International Conference on Learning Representations, 2026. 14 Appendix Content A. Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
2026
-
[59]
adapts the idea to user-centric settings, and InfoReasoner [ 39] optimizes retrieval- augmented reasoning with a synthetic semantic information-gain reward over retrieval trajectories. These methods establish that turn-level shaping is important for long-horizon optimization, but their potentials are still anchored to a gold answer, supervised belief stat...
-
[60]
uses reasoning-reflection signals, VeriFree [45] optimizes reference-answer likelihood without an external verifier, and Intuitor [46] replaces external rewards with self-certainty. Related self-improvement methods obtain training signal through self-rewarding or self- play: Self-Rewarding Language Models [47] use LLM-as-a-Judge rewards, SPIN [48] frames ...
-
[61]
target mass times cluster-level support gain,
studies how reward granularity, scale, and temporal dynamics affect tool-use learning. Process vs. Outcome Reward [ 9] shows that finer-grained feedback can improve long- horizon agentic RAG, while also emphasizing the cost of obtaining gold intermediate supervision. These results support the need for turn-level feedback, but they still leave open how to ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.