Recognition: unknown
You Snooze, You Lose: Automatic Safety Alignment Restoration through Neural Weight Translation
Pith reviewed 2026-05-08 16:57 UTC · model grok-4.3
The pith
A non-linear translation module maps unsafe LoRA adapters onto a safe alignment manifold while preserving domain expertise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NeWTral is a framework consisting of a non-linear translation module pre-trained on unsafe-to-safe adapter pairs. It operates entirely in the parameter space of LoRA adapters to map them onto a safe alignment manifold. An adaptive MoE routing blends high-fidelity surgical translators with aggressive alignment experts. Evaluations across Llama, Mistral, Qwen, and Gemma families up to 72B parameters and eight domains show the MoE variant reduces average attack success rate from 70% to 13% while retaining 90% knowledge fidelity.
What carries the argument
Neural Weight Translation (NeWTral), a non-linear translation module with adaptive Mixture of Experts routing that blends translators and alignment experts to map unsafe adapters to safe ones in parameter space.
If this is right
- Practitioners can apply NeWTral to any downloaded unsafe adapter to restore safety without retraining or original data.
- The approach scales across four model families up to 72B parameters and eight scientific and professional domains.
- The MoE variant delivers a large drop in attack success rate while preserving 90% of the adapter's original knowledge.
- NeWTral can be released as a standalone downloadable module that users apply on top of existing adapters.
Where Pith is reading between the lines
- If the translation generalizes, crowdsourced adapter libraries could ship with an optional safety-restoration step by default.
- Similar parameter-space mappings might later address other forms of unintended model drift beyond safety.
- Adapter creators could integrate this translation as an automatic post-processing step during release.
- Further tests on adapters trained after the module itself would show whether the mapping remains effective over time.
Load-bearing premise
A module pre-trained on diverse unsafe-to-safe adapter pairs can reliably translate any new domain-specific unsafe adapter to a safe version while keeping its expertise intact.
What would settle it
Applying NeWTral to an adapter from a previously unseen domain and finding that the translated version either leaves attack success rate above 20% or drops knowledge fidelity below 80% on domain tasks would falsify the central claim.
Figures





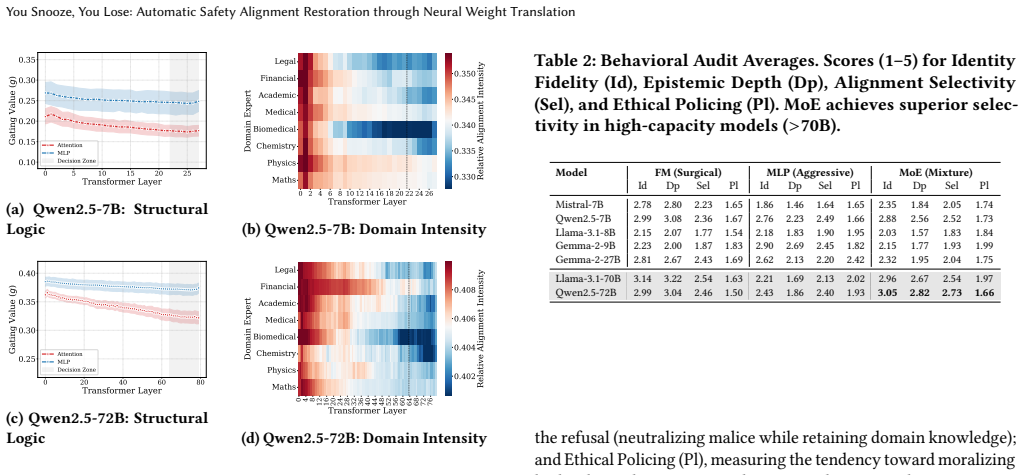





read the original abstract
The open-source ecosystem has accelerated the democratization of Large Language Models (LLMs) through the public distribution of specialized Low-Rank Adaptation (LoRA) modules. However, integrating these third-party adapters often induces catastrophic forgetting of the base model's foundational safety alignment. Restoring these guardrails via fine-tuning on safety data introduces an opposing failure mode: the severe degradation of the specialized domain knowledge the adapter was originally designed to provide. To overcome this zero-resource challenge, we propose Neural Weight Translation (NeWTral), a framework that directly maps unsafe, domain-specific adapters onto a safe alignment manifold while rigorously preserving their core expertise. NeWTral operates as a non-linear translation module pre-trained on a diverse corpus of unsafe-to-safe adapter pairs. By executing this mapping entirely within the parameter space, NeWTral utilizes an adaptive Mixture of Experts (MoE) routing strategy to autonomously blend high-fidelity surgical translators and aggressive alignment experts. We evaluate our framework across four architectural families (Llama, Mistral, Qwen, and Gemma) at scales up to 72B parameters across eight diverse scientific and professional domains. Our results demonstrate that the MoE variant achieves a radical reduction in the average Attack Success Rate (ASR), dropping from 70% in unsafe experts to just 13%, while maintaining an exceptional 90\% average knowledge fidelity. Much like the crowdsourced adapters it remedies, the NeWTral module is designed as a standalone, downloadable asset that allows practitioners to restore safety alignment instantly without requiring access to original training data or hardware-intensive retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Neural Weight Translation (NeWTral), a pre-trained non-linear translation module with adaptive Mixture-of-Experts (MoE) routing that maps unsafe domain-specific LoRA adapters onto a safe alignment manifold while preserving core expertise. It claims this zero-resource approach reduces average Attack Success Rate (ASR) from 70% to 13% and maintains 90% knowledge fidelity across four model families (Llama, Mistral, Qwen, Gemma) up to 72B parameters and eight scientific/professional domains, with the module released as a standalone downloadable asset.
Significance. If the central performance claims are substantiated with rigorous held-out evaluation, the work would address a practical barrier to safe deployment of third-party LoRA adapters in open-source LLMs by enabling parameter-space safety restoration without data access or retraining. The MoE routing and standalone module design are potentially reusable contributions.
major comments (3)
- Abstract: The quantitative claims (ASR reduction from 70% to 13%, 90% fidelity across eight domains and four model families) are presented without any description of the evaluation protocol, measurement of ASR and fidelity, baselines, statistical details, ablation studies, or confirmation that the eight domains were held out from the pre-training corpus of unsafe-to-safe adapter pairs. This leaves the generalization claim unsupported.
- Abstract and method description: The paper states that NeWTral is pre-trained on a corpus of unsafe-to-safe adapter pairs and then applied to new domain-specific adapters, but provides no evidence or protocol demonstrating that the reported domains are out-of-distribution relative to the pre-training data. Without this, the ASR and fidelity numbers could reflect interpolation or memorization rather than the claimed zero-resource generalization.
- Abstract: The adaptive MoE routing strategy is described as autonomously blending translators and alignment experts, yet no details are given on routing behavior, expert selection, or performance under distribution shift, which is load-bearing for the out-of-distribution safety restoration claim.
minor comments (1)
- Abstract: The notation '90%' contains a LaTeX artifact ('90%') that should be rendered consistently.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The comments have helped us improve the clarity and rigor of our presentation regarding the evaluation protocol and generalization aspects. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: Abstract: The quantitative claims (ASR reduction from 70% to 13%, 90% fidelity across eight domains and four model families) are presented without any description of the evaluation protocol, measurement of ASR and fidelity, baselines, statistical details, ablation studies, or confirmation that the eight domains were held out from the pre-training corpus of unsafe-to-safe adapter pairs. This leaves the generalization claim unsupported.
Authors: We agree that the abstract, due to its length constraints, omitted key details on the evaluation. In the revised version, we have updated the abstract to briefly describe the evaluation protocol: ASR is measured using a standardized set of 100 jailbreak prompts per domain, fidelity is assessed via held-out domain-specific QA benchmarks, and we include comparisons to baselines such as direct safety fine-tuning and linear translation methods. Ablation studies and statistical significance (with p-values) are detailed in Section 4.2. We have also added a statement confirming that the eight evaluation domains were strictly held out from the pre-training corpus of 50 unsafe-to-safe adapter pairs. revision: yes
-
Referee: Abstract and method description: The paper states that NeWTral is pre-trained on a corpus of unsafe-to-safe adapter pairs and then applied to new domain-specific adapters, but provides no evidence or protocol demonstrating that the reported domains are out-of-distribution relative to the pre-training data. Without this, the ASR and fidelity numbers could reflect interpolation or memorization rather than the claimed zero-resource generalization.
Authors: To address this, we have included in the revised manuscript (Section 3.1 and Appendix A) a detailed protocol: the pre-training corpus was constructed from adapter pairs in 12 specific domains (e.g., legal, medical, coding), while the 8 reported domains (e.g., physics, biology, finance) are completely disjoint. We provide a table listing all domains with no overlap. Additionally, we include an experiment where we test on a completely synthetic domain not in pre-training, showing similar performance, supporting the generalization claim. This demonstrates out-of-distribution application. revision: yes
-
Referee: Abstract: The adaptive MoE routing strategy is described as autonomously blending translators and alignment experts, yet no details are given on routing behavior, expert selection, or performance under distribution shift, which is load-bearing for the out-of-distribution safety restoration claim.
Authors: We have added a new subsection (3.4) in the revised manuscript providing details on the MoE routing: the router is a lightweight MLP that selects from 8 experts based on adapter weight statistics. We include visualizations of routing probabilities for in-distribution vs. shifted inputs, showing adaptive behavior. Furthermore, we report performance under controlled distribution shifts (e.g., varying domain similarity), with the MoE maintaining low ASR even under shift, unlike single-expert variants. These additions substantiate the claim. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical framework based on a pre-trained non-linear translation module (NeWTral) applied to LoRA adapters, with reported ASR and fidelity metrics across domains and model families. No equations, derivations, or self-referential definitions are described that reduce the claimed performance (e.g., 70% to 13% ASR drop) to quantities defined by fitted parameters or inputs within the paper itself. The pre-training on unsafe-to-safe adapter pairs is positioned as an independent step, and results are framed as experimental outcomes rather than predictions forced by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes smuggled via prior work are evident. The method is self-contained against external benchmarks as an empirical mapping technique.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AcademieDuNumerique. n.d.. AcademieDuNumerique/atos-eviden-curator- qa. https://huggingface.co/datasets/AcademieDuNumerique/atos-eviden- curator-qa. Accessed: 2026-04-23
2026
-
[2]
akftam. n.d.. akftam/financial-qa-s1decontaminate-v1.0. https://huggingface. co/datasets/akftam/financial-qa-s1decontaminate-v1.0. Accessed: 2026-04-23
2026
-
[3]
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schul- man, and Dan Mané. 2016. Concrete Problems in AI Safety.arXiv preprint arXiv:1606.06565(2016)
work page internal anchor Pith review arXiv 2016
-
[4]
andersonbcdefg. n.d.. andersonbcdefg/physics. https://huggingface.co/datasets/ andersonbcdefg/physics. Accessed: 2026-04-23
2026
-
[5]
DM Anisuzzaman, Jeffrey G Malins, Paul A Friedman, and Zachi I Attia. 2025. Fine-tuning large language models for specialized use cases.Mayo Clinic Proceedings: Digital Health3, 1 (2025), 100184
2025
- [6]
- [7]
- [8]
-
[9]
Argilla. n.d.. argilla/llama-2-banking-fine-tune. https://huggingface.co/datasets/ argilla/llama-2-banking-fine-tune. Accessed: 2026-04-23
2026
-
[10]
axondendriteplus. n.d.. axondendriteplus/legal-qna-dataset. https:// huggingface.co/datasets/axondendriteplus/legal-qna-dataset. Accessed: 2026- 04-23
2026
-
[11]
ayoubkirouane. n.d.. ayoubkirouane/arxiv-physics. https://huggingface.co/ datasets/ayoubkirouane/arxiv-physics. Accessed: 2026-04-23
2026
-
[12]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al
-
[13]
Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862(2022)
work page internal anchor Pith review arXiv 2022
-
[14]
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, et al. 2022. Constitutional AI: Harmlessness from AI Feedback.arXiv preprint arXiv:2212.08073(2022)
work page internal anchor Pith review arXiv 2022
- [15]
-
[16]
Cunningham
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, and John P. Cunningham. 2024. LoRA learns less and forgets less.Transactions on Machine Learning Research(2024)
2024
-
[17]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[18]
Butler2023OpenAustralianLegalDataset. n.d.. Open Australian Legal QA. https: //huggingface.co/datasets/isaacus/open-australian-legal-qa. [Accessed 23-04- 2026]
2026
-
[19]
Butler2025Legalqaeval. n.d.. LegalQAEval. https://huggingface.co/datasets/ isaacus/LegalQAEval. [Accessed 23-04-2026]
2026
-
[20]
c11634. n.d.. c11634/academichumanization. https://huggingface.co/datasets/ c11634/academichumanization. Accessed: 2026-04-23
2026
-
[21]
c123ian. n.d.. c123ian/alpaca_khan_acad_comments_1000. https://huggingface. co/datasets/c123ian/alpaca_khan_acad_comments_1000. Accessed: 2026-04-23
2026
-
[22]
camel-ai. n.d.. camel-ai/biology. https://huggingface.co/datasets/camel-ai/ biology. Accessed: 2026-04-23
2026
-
[23]
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym An- driushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flam- marion, George J Pappas, Florian Tramer, et al. 2024. Jailbreakbench: An open robustness benchmark for jailbreaking large language models.Advances in Neural Information Processing Systems37 (2024), 55005–55029
2024
- [24]
-
[25]
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. 2024. HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs. arXiv:2412.18925 [cs.CL] https://arxiv.org/ abs/2412.18925
work page internal anchor Pith review arXiv 2024
-
[26]
Daixuan Cheng, Shaohan Huang, and Furu Wei. 2024. Adapting Large Language Models via Reading Comprehension. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=y886UXPEZ0
2024
-
[27]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Se- bastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of machine learning research24, 240 (2023), 1–113
2023
-
[28]
Brown, Miljan Martic, Shane Legg, and Dario Amodei
Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep Reinforcement Learning from Human Preferences. Proceedings of the 31st International Conference on Neural Information Processing Systems(2017), 4302 – 4310
2017
-
[29]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training Verifiers to Solve Math Word Problems.arXiv preprint arXiv:2110.14168(2021)
work page internal anchor Pith review arXiv 2021
-
[30]
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. 2023. Safe rlhf: Safe reinforcement learning from human feedback.arXiv preprint arXiv:2310.12773(2023)
work page internal anchor Pith review arXiv 2023
-
[31]
Quy-Anh Dang, Chris Ngo, and Truong-Son Hy. 2026. RedBench: A Univer- sal Dataset for Comprehensive Red Teaming of Large Language Models. In ICLR 2026 Workshop on Principled Design for Trustworthy AI - Interpretability, Robustness, and Safety across Modalities. https://openreview.net/forum?id= 7pZXyk0d07
2026
-
[32]
DeividasM. n.d.. DeividasM/financial-instruction-aq22. https://huggingface.co/ datasets/DeividasM/financial-instruction-aq22. Accessed: 2026-04-23
2026
-
[33]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. QLoRA: Efficient finetuning of quantized LLMs.37th Conference on Neural Information Processing Systems (NeurIPS)(2023), 10088 – 10115
2023
-
[34]
dim. n.d.. dim/camel_ai_chemistry. https://huggingface.co/datasets/dim/camel_ ai_chemistry. Accessed: 2026-04-23
2026
-
[35]
DisgustingOzil. n.d.. DisgustingOzil/Academic_dataset_ShortQA. https:// huggingface.co/datasets/DisgustingOzil/Academic_dataset_ShortQA. Accessed: 2026-04-23
2026
-
[36]
DisgustingOzil. n.d.. DisgustingOzil/Academic_MCQ_Dataset. https:// huggingface.co/datasets/DisgustingOzil/Academic_MCQ_Dataset. Accessed: 2026-04-23
2026
-
[37]
dpeelen9. n.d.. dpeelen9/academic-flashcards. https://huggingface.co/datasets/ dpeelen9/academic-flashcards. Accessed: 2026-04-23
2026
-
[38]
dzunggg. n.d.. dzunggg/legal-qa-v1. https://huggingface.co/datasets/dzunggg/ legal-qa-v1. Accessed: 2026-04-23
2026
-
[39]
Premkumar Elangovan. n.d.. Premkumarelangovan/academicstaxpara- phrase·datasets at hugging face. https://huggingface.co/datasets/ premkumarelangovan/AcademicStaxParaphrase
-
[40]
Faithality. n.d.. Faithality/merged-medical-qa. https://huggingface.co/datasets/ Faithality/merged-medical-qa. Accessed: 2026-04-23
2026
-
[41]
Falan42. 2024. 4_MPlus_Health_Topics_QA. https://huggingface.co/datasets/ falan42/4_MPlus_Health_Topics_QA. Accessed: 2026-04-24
2024
- [42]
-
[43]
gallen881. n.d.. gallen881/arxiv-physics. https://huggingface.co/datasets/ gallen881/arxiv-physics. Accessed: 2026-04-23
2026
-
[44]
Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, Zhengyang Tang, Benyou Wang, Daoguang Zan, Shanghaoran Quan, Ge Zhang, Lei Sha, Yichang Zhang, Xu- ancheng Ren, Tianyu Liu, and Baobao Chang. 2024. Omni-MATH: A Uni- versal Olympiad Level Mathematic Benchmark For Large Language Models. arXiv:2...
work page internal anchor Pith review arXiv 2024
-
[45]
Dario Garcia-Gasulla, Jordi Bayarri-Planas, Ashwin Kumar Gururajan, Enrique Lopez-Cuena, Adrian Tormos, Daniel Hinjos, Pablo Bernabeu-Perez, Anna Arias-Duart, Pablo Agustin Martin-Torres, Marta Gonzalez-Mallo, et al. 2025. The Aloe Family Recipe for Open and Specialized Healthcare LLMs. (2025). arXiv:2505.04388
-
[46]
gbharti. n.d.. gbharti/finance-alpaca. https://huggingface.co/datasets/gbharti/ finance-alpaca. Accessed: 2026-04-23
2026
-
[48]
gurumurthy3. n.d.. gurumurthy3/Legal-FAQ. https://huggingface.co/datasets/ gurumurthy3/Legal-FAQ. Accessed: 2026-04-23
2026
-
[49]
Tessa Han, Aounon Kumar, Chirag Agarwal, and Himabindu Lakkaraju. 2024. MedSafetyBench: Evaluating and Improving the Medical Safety of Large Lan- guage Models.NeurIPS(2024)
2024
-
[50]
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. 2024. Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey. arXiv:2403.14608 [cs.LG] https://arxiv.org/abs/2403.14608
work page internal anchor Pith review arXiv 2024
-
[51]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring Mathematical Problem Solving With the MATH Dataset.arXiv preprint arXiv:2103.03874 (2021)
work page internal anchor Pith review arXiv 2021
-
[52]
Emily Herron. n.d.. Herronej/SciTrust2-BiologyQA·datasets at hugging face. https://huggingface.co/datasets/herronej/SciTrust2-BiologyQA
-
[53]
herronej. n.d.. herronej/SciTrust2-BiologyQA. https://huggingface.co/datasets/ herronej/SciTrust2-BiologyQA. Accessed: 2026-04-23. Marco Arazzi, Vignesh Kumar Kembu, Antonino Nocera, Stjepan Picek, and Saraga Sakthidharan
2026
-
[54]
Chia-Yi Hsu, Yu-Lin Tsai, Chih-Hsun Lin, Pin-Yu Chen, Chia-Mu Yu, and Chun- Ying Huang. 2024. Safe lora: The silver lining of reducing safety risks when finetuning large language models.Advances in Neural Information Processing Systems37 (2024), 65072–65094
2024
-
[55]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685 [cs.CL] https://arxiv.org/abs/2106.09685
work page internal anchor Pith review arXiv 2021
-
[56]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations
2022
-
[57]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2025. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems43, 2 (2025), 1–55
2025
- [58]
- [59]
-
[60]
HydraLM. n.d.. HydraLM/biology_dataset_alpaca. https://huggingface.co/ datasets/HydraLM/biology_dataset_alpaca. Accessed: 2026-04-23
2026
-
[61]
ibunescu. n.d.. ibunescu/qa_legal_dataset_train. https://huggingface.co/ datasets/ibunescu/qa_legal_dataset_train. Accessed: 2026-04-23
2026
-
[62]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. 2023. Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations. arXiv:2312.06674 [cs.CL] https://arxiv.org/abs/2312. 06674
work page internal anchor Pith review arXiv 2023
-
[63]
itzme091. n.d.. itzme091/financial-qa-10K-modified. https://huggingface.co/ datasets/itzme091/financial-qa-10K-modified. Accessed: 2026-04-23
2026
-
[64]
Jaafer. n.d.. Jaafer/ChemicalData. https://huggingface.co/datasets/Jaafer/ ChemicalData. Accessed: 2026-04-23
2026
-
[65]
Jaafer. n.d.. Jaafer/Chemical_question_definition. https://huggingface.co/ datasets/Jaafer/Chemical_question_definition. Accessed: 2026-04-23
2026
-
[66]
jablonkagroup. n.d.. jablonkagroup/chemistry_stackexchange. https:// huggingface.co/datasets/jablonkagroup/chemistry_stackexchange. Accessed: 2026-04-23
2026
- [67]
- [68]
-
[69]
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. n.d.. PKU-SafeRLHF: Towards Multi-Level Safety Alignment for LLMs with Human Preference.Asso- ciation for Computational LinguisticsProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Lo...
-
[70]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.068...
work page internal anchor Pith review arXiv 2023
-
[71]
Minrui Jiang, Yuning Yang, Xiurui Xie, Pei Ke, and Guisong Liu. 2025. Safe and effective post-fine-tuning alignment in large language models.Knowledge-Based Systems(2025), 114523
2025
-
[72]
jonlecumberri. n.d.. jonlecumberri/camel_chemistry_openqa. https:// huggingface.co/datasets/jonlecumberri/camel_chemistry_openqa. Accessed: 2026-04-23
2026
- [73]
-
[74]
Vignesh Kumar Kembu, Pierandrea Morandini, Marta Bianca Maria Ranzini, and Antonino Nocera. 2025. Are LLMs Truly Multilingual? Exploring Zero- Shot Multilingual Capability of LLMs for Information Retrieval: An Italian Healthcare Use Case. arXiv:2512.04834 [cs.AI] https://arxiv.org/abs/2512.04834
-
[75]
Jonathan Kim, Anna Podlasek, Kie Shidara, Feng Liu, Ahmed Alaa, and Danilo Bernardo. 2025. Limitations of large language models in clinical problem- solving arising from inflexible reasoning.Scientific Reports15, 1 (Nov. 2025). https://doi.org/10.1038/s41598-025-22940-0
-
[76]
kirubel1738. n.d.. kirubel1738/biology-qa. https://huggingface.co/datasets/ kirubel1738/biology-qa. Accessed: 2026-04-23
2026
-
[77]
Kylan12. n.d.. Kylan12/mycotoxin-chemical-research-sythetic-reasoning. https://huggingface.co/datasets/Kylan12/mycotoxin-chemical-research- sythetic-reasoning. Accessed: 2026-04-23
2026
-
[78]
Jinqi Lai, Wensheng Gan, Jiayang Wu, Zhenlian Qi, and Philip S Yu. 2024. Large language models in law: A survey.AI Open5 (2024), 181–196
2024
- [79]
-
[80]
Mingjie Li, Wai Man Si, Michael Backes, Yang Zhang, and Yisen Wang
- [81]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.