Recognition: 2 theorem links
· Lean TheoremCARD: A Multi-Modal Automotive Dataset for Dense 3D Reconstruction in Challenging Road Topography
Pith reviewed 2026-05-08 18:07 UTC · model grok-4.3
The pith
CARD dataset supplies quasi-dense 3D ground truth for irregular road surfaces through multi-LiDAR fusion that produces about 500,000 valid depth pixels per frame.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
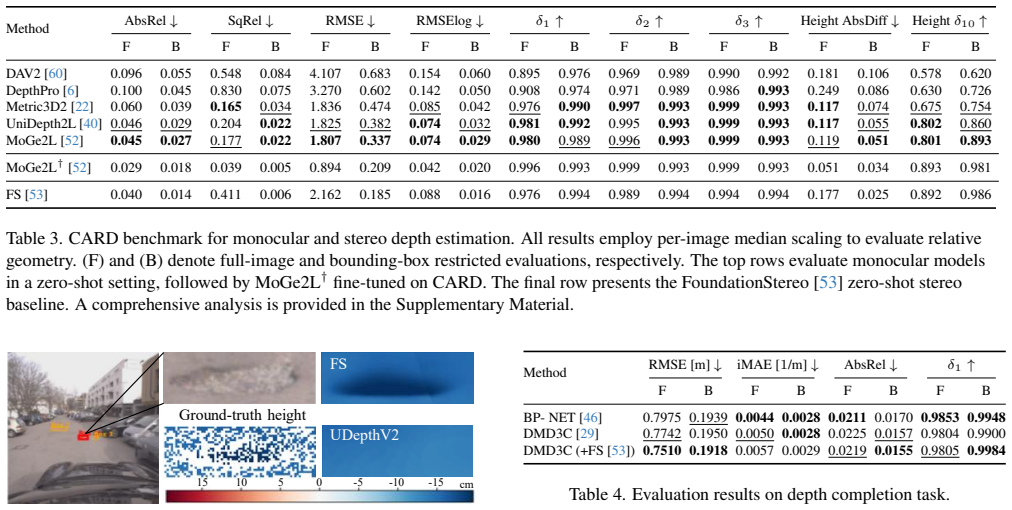
CARD delivers quasi-dense 3D ground truth across continuous sequences rich in speed bumps, potholes, irregular surfaces and off-road segments. The sensor suite comprises synchronized global-shutter stereo cameras, front and rear LiDARs, 6-DoF poses from LiDAR-inertial odometry, per-wheel motion traces, and full calibration. Multi-LiDAR fusion yields approximately 500K valid depth pixels per frame, about 6.5x more than KITTI Depth Completion and 10x more on average than other public driving datasets. The dataset spans about 110 km and 4.7 hours and supplies 2D bounding boxes targeting road-topography irregularities.
What carries the argument
Multi-LiDAR fusion of front and rear LiDAR scans combined with LiDAR-inertial odometry and provided calibration to generate quasi-dense depth ground truth maps.
Load-bearing premise
The multi-LiDAR fusion process combined with the provided calibration and LiDAR-inertial odometry produces accurate quasi-dense 3D ground truth without systematic errors or artifacts on irregular surfaces.
What would settle it
A side-by-side comparison of the fused depth values against independent high-precision measurements taken on the same speed bumps and potholes using a surveying instrument or calibrated stereo photogrammetry.
Figures
















read the original abstract
Autonomous driving must operate across diverse surfaces to enable safe mobility. However, most driving datasets are captured on well-paved flat roads. Moreover, recent driving datasets primarily provide sparse LiDAR ground truth for images, which is insufficient for assessing fine-grained geometry in depth estimation and completion. To address these gaps, we introduce CARD, a multi-modal driving dataset that delivers quasi-dense 3D ground truth across continuous sequences rich in speed bumps, potholes, irregular surfaces and off-road segments. Our sensor suite includes synchronized global-shutter stereo cameras, front and rear LiDARs, 6-DoF poses from LiDAR-inertial odometry, per-wheel motion traces, and full calibration. Notably, our multi-LiDAR fusion yields ~500K valid depth pixels per frame, about 6.5x more than KITTI Depth Completion and 10x more on average than other public driving datasets. The dataset spans ~110 km and 4.7 hours across Germany and Italy. In addition, CARD provides 2D bounding boxes targeting road-topography irregularities, enabling accurate benchmarking for both geometry and perception tasks. Furthermore, we establish a standardized evaluation protocol for road surface irregularities on CARD and benchmark state-of-the-art depth estimation models to provide strong baselines. The CARD dataset is hosted on https://huggingface.co/CARD-Data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the CARD dataset, a multi-modal automotive collection for dense 3D reconstruction on challenging road topographies. It provides synchronized global-shutter stereo cameras, front/rear LiDARs, 6-DoF LiDAR-inertial odometry poses, per-wheel motion traces, full calibration, and 2D bounding boxes for road irregularities. The central claim is that multi-LiDAR fusion produces ~500K valid depth pixels per frame (6.5x denser than KITTI Depth Completion), yielding quasi-dense 3D ground truth across ~110 km / 4.7 hours of sequences rich in speed bumps, potholes, irregular surfaces, and off-road segments in Germany and Italy. The paper also defines a standardized evaluation protocol for road surface irregularities and reports baselines from state-of-the-art depth estimation models.
Significance. If the fused depth data prove geometrically accurate, CARD would fill a clear gap in public driving datasets by supplying dense, calibrated ground truth on non-flat and irregular terrains where existing collections (KITTI, etc.) are sparse and limited to paved roads. The combination of multi-modal sensors, long continuous sequences, and an explicit benchmarking protocol for topography irregularities would support more realistic evaluation of depth completion, surface reconstruction, and perception models for autonomous driving. The public release on Hugging Face and provision of calibration/poses are practical strengths.
major comments (1)
- [Dataset construction / multi-LiDAR fusion] Dataset construction / multi-LiDAR fusion section: The headline claim of accurate quasi-dense 3D ground truth (~500K valid depth pixels per frame) rests on the fusion pipeline (using provided calibration and LiDAR-inertial odometry) being free of systematic bias or artifacts on irregular surfaces. No quantitative validation is reported—e.g., RMSE, MAE, or outlier rates against an external reference (total station, high-precision IMU, or stereo photogrammetry) on speed bumps, potholes, or off-road segments. Density alone does not establish geometric fidelity where surface normals change rapidly or small pose errors are amplified.
minor comments (1)
- [Abstract] The abstract and introduction could explicitly state the total number of frames or sequences to allow readers to assess scale relative to the claimed 4.7 hours of data.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the CARD dataset manuscript. We address the major comment point by point below and outline planned revisions.
read point-by-point responses
-
Referee: Dataset construction / multi-LiDAR fusion section: The headline claim of accurate quasi-dense 3D ground truth (~500K valid depth pixels per frame) rests on the fusion pipeline (using provided calibration and LiDAR-inertial odometry) being free of systematic bias or artifacts on irregular surfaces. No quantitative validation is reported—e.g., RMSE, MAE, or outlier rates against an external reference (total station, high-precision IMU, or stereo photogrammetry) on speed bumps, potholes, or off-road segments. Density alone does not establish geometric fidelity where surface normals change rapidly or small pose errors are amplified.
Authors: We agree that geometric accuracy must be demonstrated beyond density statistics, especially given the challenges of irregular road topographies. The manuscript presents the multi-LiDAR fusion results using the released calibration parameters and 6-DoF LiDAR-inertial odometry poses, which follow established practices in the field. We did not include direct external validation (e.g., total-station RMSE) because such high-precision ground-truth references were not collected during acquisition. In the revised manuscript we will add a dedicated 'Geometric Validation' subsection that reports: (i) intra-LiDAR consistency metrics (RMSE between front and rear LiDAR projections on overlapping regions), (ii) cross-modal agreement between fused depths and stereo disparity estimates on a curated subset of frames containing speed bumps and potholes, and (iii) a brief error-propagation analysis based on the reported pose uncertainties. We will also expand the limitations paragraph to discuss potential artifacts on high-curvature surfaces. These additions will be supported by new quantitative tables and qualitative visualizations. revision: partial
- Direct RMSE/MAE or outlier statistics against external high-precision references (total station, survey-grade IMU, or independent photogrammetry) on the irregular segments, as these reference measurements were not acquired during data collection.
Circularity Check
No circularity: dataset release with no derivations or fitted predictions
full rationale
The paper is a data collection and release effort describing a sensor suite, synchronization, multi-LiDAR fusion pipeline, and benchmarks on the released CARD dataset. No equations, models, or predictions are presented that reduce to fitted parameters or self-citations by construction. The ~500K depth pixels claim is an empirical count from the fusion process, not a derived result. Central claims rest on external validation potential rather than internal reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sensor synchronization, calibration, and LiDAR-inertial odometry produce sufficiently accurate poses and alignments for dense 3D reconstruction
Reference graph
Works this paper leans on
-
[1]
Ceres Solver.http://ceres-solver.org, 2023
Sameer Agarwal, Keir Mierle, and The Ceres Solver Team. Ceres Solver.http://ceres-solver.org, 2023. 6
2023
-
[2]
Zenseact open dataset: A large-scale and diverse multimodal dataset for autonomous driving
Mina Alibeigi, William Ljungbergh, Adam Tonderski, Georg Hess, Adam Lilja, Carl Lindstr ¨om, Daria Motorniuk, Jun- sheng Fu, Jenny Widahl, and Christoffer Petersson. Zenseact open dataset: A large-scale and diverse multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20178– 20188, 2023...
2023
-
[3]
Bridging the gap between real-world and synthetic images for test- ing autonomous driving systems
Mohammad Hossein Amini and Shiva Nejati. Bridging the gap between real-world and synthetic images for test- ing autonomous driving systems. InProceedings of the 39th IEEE/ACM International Conference on Automated Soft- ware Engineering, 2024. 2
2024
-
[4]
Rdd2022: A multi- national image dataset for automatic road damage detection
Deeksha Arya, Hiroya Maeda, Sanjay Kumar Ghosh, Durga Toshniwal, and Yoshihide Sekimoto. Rdd2022: A multi- national image dataset for automatic road damage detection. Geoscience Data Journal, 11(4):846–862, 2024. 3
2024
-
[5]
Computer vision-based detection and classification of road obstacles: Systematic literature review.IEEE Access, 2025
Hamza Assemlali, Soukaina Bouhsissin, and Nawal Sael. Computer vision-based detection and classification of road obstacles: Systematic literature review.IEEE Access, 2025. 1
2025
-
[6]
Depth pro: Sharp monocular metric depth in less than a second
Alexey Bochkovskiy, Ama ¨el Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second. InThe Thirteenth International Conference on Learning Representations, 2025. 8, 9, 13
2025
-
[7]
Carla simulated data for rare road object detection
Tom Bu, Xinhe Zhang, Christoph Mertz, and John M Dolan. Carla simulated data for rare road object detection. In2021 IEEE International Intelligent Transportation Systems Con- ference (ITSC), 2021. 2
2021
-
[8]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020. 1, 2, 3
2020
-
[9]
Argoverse: 3d tracking and forecasting with rich maps
Ming-Fang Chang, John Lambert, Patsorn Sangkloy, Jag- jeet Singh, Slawomir Bak, Andrew Hartnett, De Wang, Peter Carr, Simon Lucey, Deva Ramanan, et al. Argoverse: 3d tracking and forecasting with rich maps. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019. 1, 2, 3
2019
-
[10]
Attribution 4.0 international (cc by 4.0) — legal code.https://creativecommons
Creative Commons. Attribution 4.0 international (cc by 4.0) — legal code.https://creativecommons. org/licenses/by/4.0/legalcode, 2013. Accessed Nov. 9, 2025. 2
2013
-
[11]
Attribution–noncommercial 4.0 in- ternational (cc by-nc 4.0) — legal code.https : / / creativecommons.org/licenses/by- nc/4.0/ legalcode, 2013
Creative Commons. Attribution–noncommercial 4.0 in- ternational (cc by-nc 4.0) — legal code.https : / / creativecommons.org/licenses/by- nc/4.0/ legalcode, 2013. Accessed Nov. 9, 2025. 2
2013
-
[12]
Carla: An open urban driv- ing simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Anto- nio Lopez, and Vladlen Koltun. Carla: An open urban driv- ing simulator. InConference on robot learning, pages 1–16. PMLR, 2017. 1, 2
2017
-
[13]
Yuchuan Du, Jing Chen, Cong Zhao, Chenglong Liu, Feix- iong Liao, and Ching-Yao Chan. Comfortable and energy- efficient speed control of autonomous vehicles on rough pavements using deep reinforcement learning.Transporta- tion Research Part C: Emerging Technologies, 2022. 1, 3
2022
-
[14]
MonoPP: Metric-scaled self-supervised monocular depth estimation by planar-parallax geometry in automotive applications
Gasser Elazab, Torben Gr ¨aber, Michael Unterreiner, and Olaf Hellwich. MonoPP: Metric-scaled self-supervised monocular depth estimation by planar-parallax geometry in automotive applications. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025. 7
2025
-
[15]
Gasser Elazab, Maximilian Jansen, Michael Unterreiner, and Olaf Hellwich. Gamma-from-mono: Road-relative, metric, self-supervised monocular geometry for vehicular applica- tions.arXiv preprint arXiv:2512.04303, 2025. 7
-
[16]
Vision meets robotics: The kitti dataset.The in- ternational journal of robotics research, 32(11):1231–1237,
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The in- ternational journal of robotics research, 32(11):1231–1237,
-
[17]
A2d2: Audi autonomous driving dataset
Jakob Geyer, Yohannes Kassahun, Mentar Mahmudi, Xavier Ricou, Rupesh Durgesh, Andrew S Chung, Lorenz Hauswald, Viet Hoang Pham, Maximilian M ¨uhlegg, Sebas- tian Dorn, et al. A2d2: Audi autonomous driving dataset. arXiv preprint arXiv:2004.06320, 2020. 1, 2, 3, 7
-
[18]
Digging into self-supervised monocular depth estimation
Cl ´ement Godard, Oisin Mac Aodha, Michael Firman, and Gabriel J Brostow. Digging into self-supervised monocular depth estimation. InProceedings of the IEEE/CVF interna- tional conference on computer vision, 2019. 7
2019
-
[19]
3d packing for self-supervised monocular depth estimation
Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Allan Raven- tos, and Adrien Gaidon. 3d packing for self-supervised monocular depth estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020. 3, 7
2020
-
[20]
XT32 product page, 2025
Hesai Technology. XT32 product page, 2025. 4
2025
-
[21]
Juqi Hu, Youmin Zhang, and Subhash Rakheja. Adaptive lane change trajectory planning scheme for autonomous ve- hicles under various road frictions and vehicle speeds.IEEE Transactions on Intelligent Vehicles, 8(2):1252–1265, 2022. 1, 3
2022
-
[22]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geomet- ric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 3, 8, 9, 11, 12, 13, 14
2024
-
[23]
labelimg
HumanSignal. labelimg. GitHub repository. Archived 2024- 02-29. Original work by Tzutalin. 5 [24]U3-3990SE-C-HQ (AB02987) Specification. IDS Imaging Development Systems GmbH, 2025. Rev. 1.2. 4
2024
-
[24]
Ultralytics YOLOv8, 2025
Glenn Jocher, Jing Qiu, and Ayush Chaurasia. Ultralytics YOLOv8, 2025. Version 8.3.105. 4, 7, 5
2025
-
[25]
Direct visibility of point sets
Sagi Katz, Ayellet Tal, and Ronen Basri. Direct visibility of point sets. InACM SIGGRAPH 2007 Papers, page 24–es, New York, NY , USA, 2007. Association for Computing Ma- chinery. 6, 4
2007
-
[26]
V oxelized gicp for fast and accurate 3d point cloud registration
Kenji Koide, Masashi Yokozuka, Shuji Oishi, and Atsuhiko Banno. V oxelized gicp for fast and accurate 3d point cloud registration. In2021 IEEE international conference on robotics and automation (ICRA). IEEE, 2021. 5
2021
-
[27]
Karlo Koledic, Luka Petrovic, Ivan Markovic, and Ivan Petrovic. Gvdepth: Zero-shot monocular depth estimation for ground vehicles based on probabilistic cue fusion.arXiv preprint arXiv:2412.06080, 2024. 3
-
[28]
Dis- tilling monocular foundation model for fine-grained depth completion
Yingping Liang, Yutao Hu, Wenqi Shao, and Ying Fu. Dis- tilling monocular foundation model for fine-grained depth completion. InProceedings of the Computer Vision and Pat- tern Recognition Conference, 2025. 8
2025
-
[29]
A survey on autonomous driving datasets: Statistics, annotation quality, and a future outlook.IEEE Transactions on Intelligent Vehicles, 2024
Mingyu Liu, Ekim Yurtsever, Jonathan Fossaert, Xingcheng Zhou, Walter Zimmer, Yuning Cui, Bare Luka Zagar, and Alois C Knoll. A survey on autonomous driving datasets: Statistics, annotation quality, and a future outlook.IEEE Transactions on Intelligent Vehicles, 2024. 2
2024
-
[30]
One million scenes for aut onomous driving: Once dataset
Jiageng Mao, Minzhe Niu, Chenhan Jiang, Hanxue Liang, Jingheng Chen, Xiaodan Liang, Yamin Li, Chaoqiang Ye, Wei Zhang, Zhenguo Li, et al. One million scenes for autonomous driving: Once dataset.arXiv preprint arXiv:2106.11037, 2021. 1, 2, 3
-
[31]
Effect of pavement surface conditions on road traffic accident – a re- view
Rahma Mkwata and Elizabeth Eu Mee Chong. Effect of pavement surface conditions on road traffic accident – a re- view. InE3S Web of Conferences, 2022. 1
2022
-
[32]
Deep learning for safe autonomous driving: Current challenges and future direc- tions.IEEE Transactions on Intelligent Transportation Sys- tems, 22(7):4316–4336, 2020
Khan Muhammad, Amin Ullah, Jaime Lloret, Javier Del Ser, and Victor Hugo C De Albuquerque. Deep learning for safe autonomous driving: Current challenges and future direc- tions.IEEE Transactions on Intelligent Transportation Sys- tems, 22(7):4316–4336, 2020. 1
2020
-
[33]
M. A. F. Musa, Sitti Asmah Hassan, and Nordiana Mashros. The impact of roadway conditions towards accident severity on federal roads in malaysia.PLoS ONE, 15, 2020. 1
2020
-
[34]
Mc2slam: Real-time inertial lidar odometry using two-scan motion compensation
Frank Neuhaus, Tilman Koß, Robert Kohnen, and Dietrich Paulus. Mc2slam: Real-time inertial lidar odometry using two-scan motion compensation. InGerman Conference on Pattern Recognition, pages 60–72. Springer, 2018. 4, 1
2018
-
[35]
Sina Nordhoff and Joost De Winter. Why do drivers and automation disengage the automation? results from a study among tesla users.arXiv preprint arXiv:2309.10440, 2023. 1
-
[36]
The h3d dataset for full-surround 3d multi-object de- tection and tracking in crowded urban scenes
Abhishek Patil, Srikanth Malla, Haiming Gang, and Yi-Ting Chen. The h3d dataset for full-surround 3d multi-object de- tection and tracking in crowded urban scenes. In2019 In- ternational Conference on Robotics and Automation (ICRA), pages 9552–9557. IEEE, 2019. 2
2019
-
[37]
Speed bump and pothole detection using deep neural network with images captured through zed camera.Applied Sciences, 13(14): 8349, 2023
Jos ´e-Eleazar Peralta-L ´opez, Joel-Artemio Morales-Viscaya, David L ´azaro-Mata, Marcos-Jes ´us Villase ˜nor-Aguilar, Juan Prado-Olivarez, Francisco-Javier P ´erez-Pinal, Jos ´e- Alfredo Padilla-Medina, Juan-Jos ´e Mart ´ınez-Nolasco, and Alejandro-Israel Barranco-Guti ´errez. Speed bump and pothole detection using deep neural network with images captur...
2023
-
[38]
Unidepth: Universal monocular metric depth estimation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. Unidepth: Universal monocular metric depth estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10106–10116, 2024. 3
2024
-
[39]
Unidepthv2: Universal monocular metric depth estimation made simpler
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mat- tia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unidepthv2: Universal monocular metric depth estimation made simpler.arXiv preprint arXiv:2502.20110, 2025. 8, 9, 11, 12, 13, 14
-
[40]
Vi- sion transformers for dense prediction
Ren ´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 12179–12188, 2021. 3
2021
-
[41]
Make3d: Learning 3d scene structure from a single still image.IEEE transactions on pattern analysis and machine intelligence, 31(5):824–840, 2008
Ashutosh Saxena, Min Sun, and Andrew Y Ng. Make3d: Learning 3d scene structure from a single still image.IEEE transactions on pattern analysis and machine intelligence, 31(5):824–840, 2008. 7
2008
-
[42]
Airsim: High-fidelity visual and physical simula- tion for autonomous vehicles
Shital Shah, Debadeepta Dey, Chris Lovett, and Ashish Kapoor. Airsim: High-fidelity visual and physical simula- tion for autonomous vehicles. InField and service robotics: Results of the 11th international conference, 2017. 1, 2
2017
-
[43]
Tartandrive 2.0: More modalities and better infrastructure to further self- supervised learning research in off-road driving tasks
Matthew Sivaprakasam, Parv Maheshwari, Mateo Guaman Castro, Samuel Triest, Micah Nye, Steve Willits, Andrew Saba, Wenshan Wang, and Sebastian Scherer. Tartandrive 2.0: More modalities and better infrastructure to further self- supervised learning research in off-road driving tasks. In 2024 IEEE International Conference on Robotics and Au- tomation (ICRA),...
2024
-
[44]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, 2020. 1, 2, 3, 7
2020
-
[45]
Bilateral propagation network for depth completion
Jie Tang, Fei-Peng Tian, Boshi An, Jian Li, and Ping Tan. Bilateral propagation network for depth completion. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 8
2024
-
[46]
Shrec 2022: Pothole and crack detection in the road pave- ment using images and rgb-d data.Computers & Graphics, 107:161–171, 2022
Elia Moscoso Thompson, Andrea Ranieri, Silvia Biasotti, Miguel Chicchon, Ivan Sipiran, Minh-Khoi Pham, Thang- Long Nguyen-Ho, Hai-Dang Nguyen, and Minh-Triet Tran. Shrec 2022: Pothole and crack detection in the road pave- ment using images and rgb-d data.Computers & Graphics, 107:161–171, 2022. 3
2022
-
[47]
Sparsity invariant cnns
Jonas Uhrig, Nick Schneider, Lukas Schneider, Uwe Franke, Thomas Brox, and Andreas Geiger. Sparsity invariant cnns. In2017 international conference on 3D Vision (3DV), 2017. 2, 3, 4, 5, 7
2017
-
[48]
The eu general data protection regulation (gdpr).A practical guide, 1st ed., Cham: Springer International Publishing, 10, 2017
Paul V oigt and Axel V on dem Bussche. The eu general data protection regulation (gdpr).A practical guide, 1st ed., Cham: Springer International Publishing, 10, 2017. 4
2017
-
[49]
The apolloscape open dataset for autonomous driving and its application.IEEE transactions on pattern analysis and machine intelligence, 1, 2019
Peng Wang, Xinyu Huang, Xinjing Cheng, Dingfu Zhou, Qichuan Geng, and Ruigang Yang. The apolloscape open dataset for autonomous driving and its application.IEEE transactions on pattern analysis and machine intelligence, 1, 2019. 2
2019
-
[50]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the Computer Vision and Pattern Recognition Conference,
-
[51]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details.arXiv preprint arXiv:2507.02546,
work page internal anchor Pith review arXiv
-
[52]
Foundationstereo: Zero- shot stereo matching
Bowen Wen, Matthew Trepte, Joseph Aribido, Jan Kautz, Orazio Gallo, and Stan Birchfield. Foundationstereo: Zero- shot stereo matching. InProceedings of the Computer Vision and Pattern Recognition Conference, 2025. 7, 8, 9, 11, 12, 13, 14
2025
-
[53]
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, et al. Argoverse 2: Next generation datasets for self-driving perception and forecasting.arXiv preprint arXiv:2301.00493, 2023. 1, 2, 3
work page internal anchor Pith review arXiv 2023
-
[54]
Global status report on road safety 2023
World Health Organization. Global status report on road safety 2023. Technical report, World Health Organization, Geneva, 2023. ISBN: 9789240087200. 1
2023
-
[55]
Synscapes: A Photorealistic Synthetic Dataset for Street Scene Parsing
Magnus Wrenninge and Jonas Unger. Synscapes: A photore- alistic synthetic dataset for street scene parsing. arxiv 2018. arXiv preprint arXiv:1810.08705, 2018. 1, 2
work page Pith review arXiv 2018
-
[56]
Pandaset: Advanced sensor suite dataset for autonomous driving
Pengchuan Xiao, Zhenlei Shao, Steven Hao, Zishuo Zhang, Xiaolin Chai, Judy Jiao, Zesong Li, Jian Wu, Kai Sun, Kun Jiang, et al. Pandaset: Advanced sensor suite dataset for autonomous driving. In2021 IEEE international intelligent transportation systems conference (ITSC). IEEE, 2021. 1, 2, 3
2021
-
[57]
Drivingstereo: A large-scale dataset for stereo matching in autonomous driving scenarios
Guorun Yang, Xiao Song, Chaoqin Huang, Zhidong Deng, Jianping Shi, and Bolei Zhou. Drivingstereo: A large-scale dataset for stereo matching in autonomous driving scenarios. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, 2019. 2, 3, 4, 5
2019
-
[58]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2024. 3, 6, 4
2024
-
[59]
Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37, 2024. 3, 8, 9, 14
2024
-
[60]
Analysis of the impact of different road conditions on accident sever- ity at highway-rail grade crossings based on explainable ma- chine learning.Symmetry, 17(1):147, 2025
Zhen Yang, Chen Zhang, Gen Li, and Hongyi Xu. Analysis of the impact of different road conditions on accident sever- ity at highway-rail grade crossings based on explainable ma- chine learning.Symmetry, 17(1):147, 2025. 1
2025
-
[61]
Metric3d: Towards zero-shot metric 3d prediction from a single image
Wei Yin, Chi Zhang, Hao Chen, Zhipeng Cai, Gang Yu, Kaixuan Wang, Xiaozhi Chen, and Chunhua Shen. Metric3d: Towards zero-shot metric 3d prediction from a single image. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023. 3
2023
-
[62]
Tong Zhao, Chenfeng Xu, Mingyu Ding, Masayoshi Tomizuka, Wei Zhan, and Yintao Wei. Rsrd: A road surface reconstruction dataset and benchmark for safe and comfort- able autonomous driving.arXiv preprint arXiv:2310.02262,
-
[63]
Open3D: A Modern Library for 3D Data Processing
Qian-Yi Zhou, Jaesik Park, and Vladlen Koltun. Open3d: A modern library for 3d data processing.arXiv preprint arXiv:1801.09847, 2018. 6, 4
work page internal anchor Pith review arXiv 2018
-
[64]
Jiacheng Zuo, Haibo Hu, Zikang Zhou, Yufei Cui, Ziquan Liu, Jianping Wang, Nan Guan, Jin Wang, and Chun Jason Xue. Ralad: Bridging the real-to-sim domain gap in au- tonomous driving with retrieval-augmented learning.arXiv preprint arXiv:2501.12296, 2025. 1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.