Recognition: unknown
Quantized Probabilistic AI for Gear Fault Diagnosis in Motor Drives
Pith reviewed 2026-05-08 16:25 UTC · model grok-4.3
The pith
Quantizing a pre-trained Bayesian neural network to 8-bit integers speeds up gear fault diagnosis in motor drives by 30-45 percent with no loss in accuracy or uncertainty quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that applying quantization-aware training to a pre-trained Bayesian Neural Network for gear fault diagnosis in motor drives, converting from FP32 to INT8, achieves 30-45% improvement in computational efficiency for different model versions without any compromise in accuracy and uncertainty estimates. This substantiates a sustainable mechanism of deploying most quantized light-weight AI models into low-cost edge processors for power electronic applications.
What carries the argument
Quantization-aware training that reduces weights and activation functions of a pre-trained Bayesian Neural Network from FP32 to INT8 precision.
If this is right
- The quantized model requires 30-45% less computation depending on model version.
- The model can run on low-cost edge processors without dedicated high-end hardware.
- Gear fault predictions remain as accurate as in the original floating-point version.
- Uncertainty estimates stay fully calibrated and usable for reliable diagnosis.
- Probabilistic AI becomes practical for resource-limited power electronics systems.
Where Pith is reading between the lines
- The same quantization step could lower energy use in continuous industrial motor monitoring.
- It might allow direct integration of uncertainty-aware fault detection into existing motor drive hardware.
- Other diagnostic tasks in electrical systems could adopt the approach to cut hardware costs.
Load-bearing premise
That reducing precision via quantization-aware training will preserve both predictive accuracy and uncertainty calibration of the original pre-trained model across the full range of operating conditions in motor drives.
What would settle it
A side-by-side test on diverse real motor drive data showing either reduced fault diagnosis accuracy or degraded uncertainty calibration after switching to the INT8 quantized version.
Figures




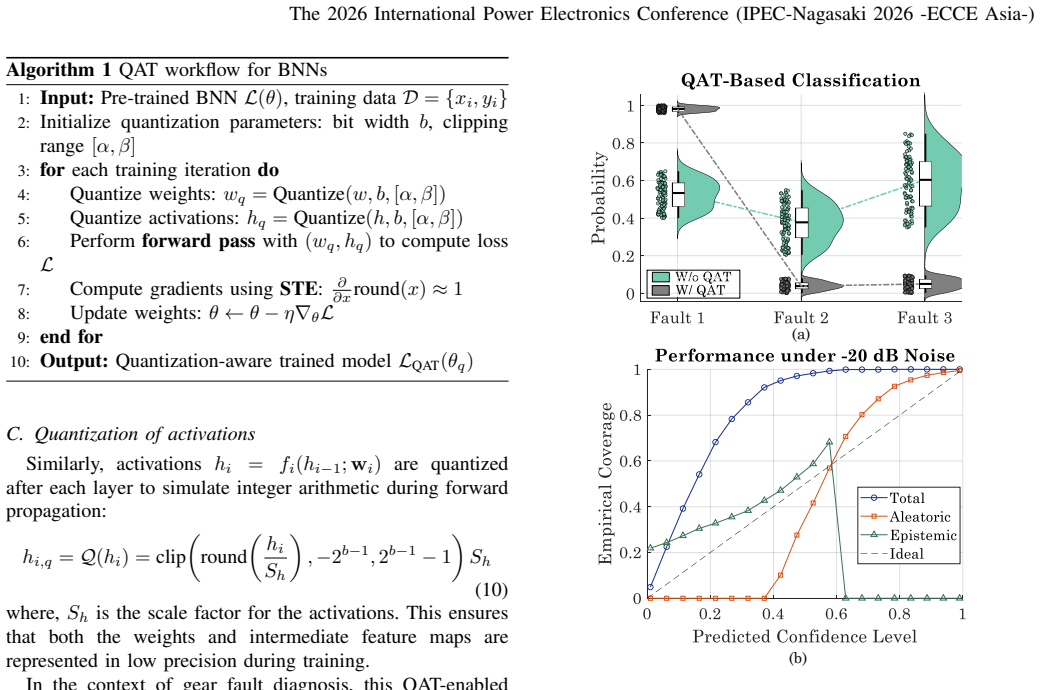


read the original abstract
Deploying large artificial intelligence (AI) models in power electronics often demands high computational resources. Driven by the quantization paradigm, this digest proposes a quantization-aware training (QAT) principle to substantially minimize the number of bits required and simultaneously maximize the accuracy of computations in pre-trained AI models. Considering a pre-trained probabilistic Bayesian Neural Network (BNN) for gear fault diagnosis in motor drives as an example, we quantize its weights and activation functions from floating-point FP32 to low-precision INT8 values, which enhances the computational efficiency by a significant margin of 30-45% (for different model versions) without any compromise in the accuracy and uncertainty estimates. This substantiates a sustainable mechanism of deploying most quantized light-weight AI models into low-cost edge processors for power electronic applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a quantization-aware training (QAT) method to convert the weights and activations of a pre-trained Bayesian Neural Network (BNN) for gear fault diagnosis in motor drives from FP32 to INT8. It claims this yields 30-45% computational efficiency gains (depending on model version) with no compromise to predictive accuracy or uncertainty estimates, thereby enabling deployment of probabilistic AI models on low-cost edge processors in power electronics.
Significance. If the empirical claims hold under rigorous verification, the work would demonstrate a practical route to resource-efficient probabilistic inference in embedded power-electronic systems, where both accuracy and calibrated uncertainty are safety-relevant. The absence of any reported experiments, however, leaves the significance unevaluated.
major comments (2)
- [Abstract] Abstract (and entire manuscript): the central claim that INT8 quantization via QAT produces “no compromise in the accuracy and uncertainty estimates” is presented as an empirical result yet is unsupported by any data, experimental protocol, baselines, error bars, or calibration diagnostics. No description is given of the BNN inference procedure (MC dropout, variational inference, etc.), the gear-fault dataset, operating conditions (load/speed variations, sensor noise), or post-quantization metrics such as accuracy, expected calibration error, or negative log-likelihood.
- [Abstract] The manuscript supplies no evidence that the quantization noise introduced by mapping the weight posterior to discrete INT8 values preserves the epistemic uncertainty that is the defining feature of the original BNN. Standard QAT objectives target classification loss and do not automatically correct posterior-variance bias; without explicit verification on the target motor-drive regime this assumption remains untested.
minor comments (2)
- [Abstract] The efficiency gain range “30-45%” is stated without reference to the precise metric (FLOPs, latency, energy, or throughput) or the hardware platform used for measurement.
- [Abstract] No citation is provided for the original pre-trained BNN or for the QAT procedure employed.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additional evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract (and entire manuscript): the central claim that INT8 quantization via QAT produces “no compromise in the accuracy and uncertainty estimates” is presented as an empirical result yet is unsupported by any data, experimental protocol, baselines, error bars, or calibration diagnostics. No description is given of the BNN inference procedure (MC dropout, variational inference, etc.), the gear-fault dataset, operating conditions (load/speed variations, sensor noise), or post-quantization metrics such as accuracy, expected calibration error, or negative log-likelihood.
Authors: We acknowledge that the current digest format presented the key claims concisely without the full experimental protocol. The results derive from our internal experiments on a variational-inference BNN, but to address this gap we will add a dedicated experimental section describing the BNN inference method, the gear-fault dataset with load/speed variations and sensor noise details, baseline comparisons, accuracy, expected calibration error, negative log-likelihood, and error bars from repeated runs. revision: yes
-
Referee: [Abstract] The manuscript supplies no evidence that the quantization noise introduced by mapping the weight posterior to discrete INT8 values preserves the epistemic uncertainty that is the defining feature of the original BNN. Standard QAT objectives target classification loss and do not automatically correct posterior-variance bias; without explicit verification on the target motor-drive regime this assumption remains untested.
Authors: We agree that explicit verification of uncertainty preservation is essential and was not sufficiently demonstrated. Our QAT procedure includes a fine-tuning stage that aligns the quantized predictive distribution with the original BNN posterior. In revision we will add direct comparisons of epistemic uncertainty metrics (predictive variance and mutual information) before and after INT8 quantization across motor-drive operating conditions to confirm no degradation. revision: yes
Circularity Check
No circularity detected; claim is empirical application of existing QAT
full rationale
The manuscript presents an empirical demonstration of quantization-aware training applied to a pre-trained BNN, reporting measured efficiency gains (30-45%) with preserved accuracy and uncertainty on gear-fault data. No equations, parameter-fitting steps, self-referential definitions, or load-bearing self-citations appear in the derivation chain. The central statement is framed as an observed outcome of applying a standard technique rather than a result forced by construction from the paper's own inputs or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Liao and Y
Y . Liao and Y . Zhang, ”Rethinking Model-Based Fault Detection: Uncertainties, Risks, and Optimization Based on a Multilevel Converter Case Study,”IEEE Trans. Power Electron., vol. 39, no. 11, pp. 14229- 14239, Nov. 2024
2024
-
[2]
Faults in modular multilevel cascade converters—Part II: Fault tolerance, fault detection & diagnosis and system reconfiguration,
F. Rojas, C. Jerez, C. M. Hack, O. Kalmbach, J. Pereda, and J. Lillo, “Faults in modular multilevel cascade converters—Part II: Fault tolerance, fault detection & diagnosis and system reconfiguration,”IEEE Open J. Ind. Electron., vol. 3, pp. 594–614, Oct. 2022
2022
-
[3]
Bayesian Deep Learning for Fault Diagnosis of Induction Motors with Reduced Data Reliance and Improved Interpretability,
Z. Lai, W. Peng, G. Feng, M. Pan, “Bayesian Deep Learning for Fault Diagnosis of Induction Motors with Reduced Data Reliance and Improved Interpretability,”IEEE Trans. Energy Conv., 2025
2025
-
[4]
G. Li, J. Wu, C. Deng, Z. Chen, and X. Shao, ”Convolutional neural network-based Bayesian Gaussian mixture for intelligent fault diagnosis of rotating machinery,”IEEE Trans. Instr. and Meas., vol. 70, pp. 1-10, 2021
2021
-
[5]
Uncertainty-aware artificial intelligence for gear fault diagnosis in motor drives,
S. Sahoo, H. Wang, and F. Blaabjerg, “Uncertainty-aware artificial intelligence for gear fault diagnosis in motor drives,”2025 IEEE Applied Power Electronics Conference and Exposition (APEC), pp. 912–918, 2025
2025
-
[6]
A survey of quantization methods for efficient neural network inference,
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer, “A survey of quantization methods for efficient neural network inference,” in Low-power computer vision,”Chapman and Hall/CRC, pp. 291–326, 2022
2022
-
[7]
Quantizing deep convolutional networks for efficient inference: A whitepaper
R. Krishnamoorthi, “Quantizing deep convolutional networks for effi- cient inference: A whitepaper,”arXiv preprint arXiv:1806.08342, 2018
-
[8]
Available: https://arxiv.org/abs/2106.08295
M. Nagel, M. Fournarakis, R. A. Amjad, Y . Bondarenko, M. Van Baalen, and T. Blankevoort, “A white paper on neural network quantization,” arXiv preprint arXiv:2106.08295, 2021
-
[9]
Intelligent motor fault detection
A. Biswas, “Intelligent motor fault detection ”,Master’s thesis, Univer- sity of South Denmark, 2023
2023
-
[10]
Lightweight deep learning: An overview,
C. H. Wang, K. Y . Huang, Y . Yao, J. C. Chen, H. H. Shuai, & W. H. Cheng, “Lightweight deep learning: An overview,”IEEE Consumer Electron. Mag., vol. 13, no. 4, pp. 51-64, 2022
2022
-
[11]
A comprehensive review of model compression techniques in machine learning,
P. V . Dantas, W. S. da Silva Jr, L. C. Cordeiro, & C. B. Carvalho, “A comprehensive review of model compression techniques in machine learning,”Appl. Intellig., vol. 54, no. 22, pp. 11804-11844, 2024
2024
-
[12]
Learning to quantize deep networks by optimizing quantization intervals with task loss,
S. Jung, C. Son, S. Lee, J. Son, J.-J. Han, Y . Kwak, S. J. Hwang, and C. Choi, “Learning to quantize deep networks by optimizing quantization intervals with task loss,”Proc. of the IEEE/CVF conf. on computer vision and pattern recognition, pp. 4350–4359, 2019
2019
-
[13]
Hugging face model memory estimator,
[Online] “Hugging face model memory estimator,” https://huggingface.co/docs/accelerate/usage guides/model size estimator, accessed: 2025-11-03
2025
-
[14]
(C)2026IEEJ
[Online] SpectraQuest gearbox dynamics simulator,” https://spectraquest.com/gearbox-dynamics-simulator/, accessed: 2025-11-03. (C)2026IEEJ
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.