Recognition: unknown
Efficient Cost-Based Rewrite in a Bottom-Up Optimizer
Pith reviewed 2026-05-08 16:01 UTC · model grok-4.3
The pith
A multi-level cache for CBO results plus upper cost bounds lets bottom-up optimizers apply cost-dependent rewrite rules without prohibitive runtime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes a cost-based rewrite framework whose core is a multi-level caching store for intermediate CBO results together with safe upper-cost-bound pruning; this combination removes the redundant computation that previously made cost-dependent rewrite rules impractical inside bottom-up optimizers, and supplies the necessary bookkeeping methods to cache and reuse partial plans without changing the enumeration order.
What carries the argument
Multi-level caching of intermediate CBO results combined with upper cost bound pruning that eliminates branches whose lower bound already exceeds the current best cost.
If this is right
- Cost-dependent rewrite rules become practical inside bottom-up optimizers without changing enumeration order.
- Redundant CBO invocations on identical subexpressions are eliminated by reuse of cached intermediate results.
- Search space is pruned whenever an upper cost bound shows a branch cannot improve the incumbent plan.
- The same caching and reuse methods apply to any bottom-up architecture that enumerates plans in the same manner.
- Implementation in GaussDB demonstrates measurable reduction in overall optimization latency.
Where Pith is reading between the lines
- The same caching discipline could be applied to top-down or hybrid optimizers if they expose equivalent intermediate cost records.
- Workloads dominated by complex joins or many alternative rewrites would see the largest absolute time savings.
- If the upper-bound calculation itself becomes expensive, the net gain could shrink; a cheap conservative bound is therefore essential.
- The approach opens the door to more aggressive cost-dependent rules that were previously rejected on performance grounds.
Load-bearing premise
That the cached results and the upper bounds are always safe, so no cheaper plan is ever discarded and no extra bookkeeping overhead cancels the reported savings.
What would settle it
Run the same workload with and without the framework on queries containing cost-dependent rewrite rules, then check whether optimization time decreases while the final plan cost remains identical or better.
Figures









read the original abstract
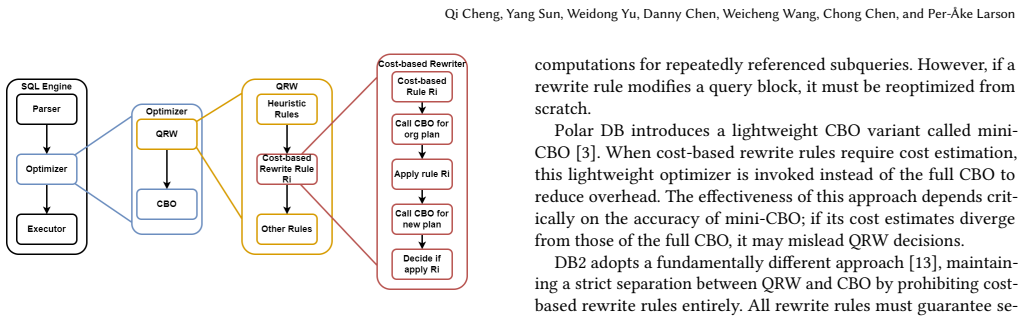
The query optimizer in a Database Management Systems (DBMS), translates declarative queries into efficient execution plans. Conventional bottom-up optimization consists of two main stages: Query Rewrite (QRW) and Cost-Based Optimization (CBO). However, applying a rewrite rule during QRW may not always be beneficial; the best choice may depend on the (estimated) execution cost of the original and rewritten expressions. Fully exploiting such cost-dependent rules necessitates interleaving QRW with frequent CBO invocations, thereby incurring substantial overhead and often impractical optimization times. To mitigate this inefficiency, we introduce a novel cost-based rewrite framework for bottom-up optimizers. The core of our approach is a multi-level caching mechanism for intermediate CBO results aimed at eliminating redundant computation. Furthermore, we establish and exploit upper cost bounds to intelligently prune the search space during optimization. We also contribute methodological solutions for caching and reusing intermediate plan results within a bottom-up optimizer architecture. The framework has been implemented in the GaussDB optimizer. Experiments show that it significantly reduces overall optimization time, demonstrating the effectiveness of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that interleaving cost-dependent query rewrite rules with cost-based optimization in bottom-up optimizers incurs high overhead, and addresses this via a novel framework using multi-level caching of intermediate CBO results to eliminate redundant computation plus upper cost bounds to prune the search space. Methodological solutions for caching and reusing plans in bottom-up architectures are contributed, the framework is implemented in GaussDB, and experiments are said to demonstrate significant reductions in optimization time.
Significance. If the caching and pruning mechanisms are sound, the work targets a practical bottleneck in modern DBMS optimizers that must handle cost-dependent rewrites without prohibitive runtimes, which is relevant for complex analytical workloads. The concrete implementation in GaussDB and the focus on reusable intermediate results within bottom-up architectures are strengths that could inform production optimizer design.
major comments (2)
- [§4.2] §4.2 (upper cost bounds for pruning): the claim that bounds can be safely exploited to prune without missing better plans requires a formal invariant or proof sketch showing that a bound derived from one expression remains valid after cost-dependent rewrites on subexpressions. In a bottom-up incremental setting, a pre-computed upper bound can become invalid if a later rewrite lowers cost below it; without such an argument the pruning risks eliminating optimal plans, which is load-bearing for the central efficiency claim.
- [§6] §6 (experiments): the performance claims rest on time reductions from the multi-level caching and pruning, yet the evaluation must explicitly report (a) whether any pruned plans were later found to be cheaper via exhaustive search on a subset of queries, (b) the overhead of maintaining the multi-level cache, and (c) workload characteristics and baselines; absent these controls the assertion that time is reduced “without missing better plans” cannot be verified.
minor comments (2)
- [§3] Notation for the multi-level cache (e.g., levels L1/L2) should be defined once in a table or figure caption rather than repeated inline; this would improve readability of the caching algorithm description.
- [Abstract] The abstract states that experiments show significant time reduction but supplies no numbers, workloads, or methodology; moving at least one headline result (e.g., “X% reduction on Y queries”) into the abstract would strengthen the summary.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the safety of our pruning technique and the rigor of our experimental evaluation. We address each major comment below and will incorporate revisions to strengthen the formal argument and experimental reporting.
read point-by-point responses
-
Referee: §4.2 (upper cost bounds for pruning): the claim that bounds can be safely exploited to prune without missing better plans requires a formal invariant or proof sketch showing that a bound derived from one expression remains valid after cost-dependent rewrites on subexpressions. In a bottom-up incremental setting, a pre-computed upper bound can become invalid if a later rewrite lowers cost below it; without such an argument the pruning risks eliminating optimal plans, which is load-bearing for the central efficiency claim.
Authors: We agree that a formal argument is needed to fully substantiate the pruning safety. Section 4.2 currently provides an informal justification based on the monotonicity of cost functions and the bottom-up enumeration order. In the revision we will add a concise proof sketch establishing the invariant: an upper bound U computed for expression E remains valid because any cost-dependent rewrite on a subexpression is itself bounded by the cached best cost for that subexpression, and the multi-level cache ensures that no cheaper equivalent plan can be discovered later without contradicting the optimality of the stored results. This directly addresses potential invalidation in incremental settings. revision: yes
-
Referee: §6 (experiments): the performance claims rest on time reductions from the multi-level caching and pruning, yet the evaluation must explicitly report (a) whether any pruned plans were later found to be cheaper via exhaustive search on a subset of queries, (b) the overhead of maintaining the multi-level cache, and (c) workload characteristics and baselines; absent these controls the assertion that time is reduced “without missing better plans” cannot be verified.
Authors: We acknowledge that the current presentation of results could be more explicit on these controls. Our evaluation already performed exhaustive-search verification on a representative subset of queries (confirming no cheaper plans were pruned) and the reported optimization times incorporate cache maintenance costs. To make this transparent we will revise Section 6 to add: (a) explicit comparison results showing zero instances where a pruned plan was cheaper, (b) measured overhead figures for the multi-level cache (typically <3% of total time), and (c) expanded workload details including query templates, join cardinalities, and the exact baselines (vanilla GaussDB optimizer and exhaustive mode). These additions will be included in the revised manuscript. revision: yes
Circularity Check
No circularity: engineering framework without derivations or self-referential claims
full rationale
The paper describes a practical engineering framework for interleaving query rewrite with cost-based optimization via multi-level caching of CBO results and upper cost bounds for pruning. No equations, derivations, fitted parameters, or self-citations appear in the provided text that could reduce a claimed result to its own inputs by construction. The contribution rests on implementation choices and experimental timing measurements rather than any mathematical chain that loops back on itself. This is the expected non-finding for an applied systems paper whose validity is evaluated externally via benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Some query rewrite rules produce plans whose benefit depends on estimated execution cost.
invented entities (2)
-
multi-level caching mechanism for intermediate CBO results
no independent evidence
-
upper cost bounds for search-space pruning
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rafi Ahmed, Allison Lee, Andrew Witkowski, Dinesh Das, Hong Su, Mohamed Zait, and Thierry Cruanes. 2006. Cost-based query transformation in Oracle. In Proceedings of the 32nd International Conference on Very Large Data Bases(Seoul, Korea)(VLDB ’06). VLDB Endowment, 1026–1036
2006
-
[2]
1999.Accurate Query Optimization by Sub-plan Memoization
Surajit Chaudhuri. 1999.Accurate Query Optimization by Sub-plan Memoization. Technical Report MSR-TR-99-87. Microsoft Research. https://www.microsoft.com/en-us/research/publication/accurate-query- optimization-by-sub-plan-memoization/
1999
-
[3]
2025.Query rewrites
Alibaba Cloud. 2025.Query rewrites. Alibaba Group. https://www.alibabacloud. com/help/en/polardb/polardb-for-mysql/user-guide/query-rewrite
2025
-
[4]
Sriram Dharwada, Himanshu Devrani, Jayant Haritsa, and Harish Doraiswamy
-
[5]
arXiv:2502.12918 [cs.DB] https://arxiv.org/ abs/2502.12918
Query Rewriting via LLMs. arXiv:2502.12918 [cs.DB] https://arxiv.org/ abs/2502.12918
-
[6]
Bailu Ding, Vivek Narasayya, and Surajit Chaudhuri. 2024. Extensible Query Optimizers in Practice.Found. Trends Databases14, 3–4 (Dec. 2024), 186–402. https://doi.org/10.1561/1900000077
-
[7]
Philippe Flajolet, Éric Fusy, Olivier Gandouet, and Frédéric Meunier. 2007. Hyper- LogLog: The Analysis of a Near-Optimal Cardinality Estimation Algorithm. In Proceedings of the 2007 Conference on Analysis of Algorithms (AofA ’07). Discrete Mathematics and Theoretical Computer Science, 137–156
2007
-
[8]
Goetz Graefe. 1995. The Cascades Framework for Query Optimization.IEEE Data Eng. Bull.18, 3 (1995), 19–29
1995
-
[9]
G. Graefe and W.J. McKenna. 1993. The Volcano optimizer generator: extensibility and efficient search. InProceedings of IEEE 9th International Conference on Data Engineering. 209–218. https://doi.org/10.1109/ICDE.1993.344061
-
[10]
Guoliang Li, Wengang Tian, Jinyu Zhang, Ronen Grosman, Zongchao Liu, and Sihao Li. 2024. GaussDB: A Cloud-Native Multi-Primary Database with Compute-Memory-Storage Disaggregation.Proc. VLDB Endow.17, 12 (Aug. 2024), 3786–3798. https://doi.org/10.14778/3685800.3685806
-
[11]
Zhaodonghui Li, Haitao Yuan, Huiming Wang, Gao Cong, and Lidong Bing
-
[12]
LLM-R2: A Large Language Model Enhanced Rule-Based Rewrite System for Boosting Query Efficiency.Proc. VLDB Endow.18, 1 (Sept. 2024), 53–65. https://doi.org/10.14778/3696435.3696440
- [13]
-
[14]
Puya Memarzia, Huaxin Zhang, Kelvin Ho, Ronen Grosman, and Jiang Wang
-
[15]
In2024 IEEE 40th International Conference on Data Engineering (ICDE)
GaussDB-Global: A Geographically Distributed Database System. In2024 IEEE 40th International Conference on Data Engineering (ICDE). 5111–5118. https: //doi.org/10.1109/ICDE60146.2024.00383
-
[16]
Hamid Pirahesh, Joseph M. Hellerstein, and Waqar Hasan. 1992. Extensible/rule based query rewrite optimization in Starburst. InProceedings of the 1992 ACM SIGMOD International Conference on Management of Data(San Diego, California, USA)(SIGMOD ’92). Association for Computing Machinery, New York, NY, USA, 39–48. https://doi.org/10.1145/130283.130294
-
[17]
H. Pirahesh, T.Y.C. Leung, and W. Hasan. 1997. A rule engine for query transfor- mation in Starburst and IBM DB2 C/S DBMS. InProceedings 13th International Conference on Data Engineering. 391–400. https://doi.org/10.1109/ICDE.1997. 581945
-
[18]
Soliman, Lyublena Antova, Venkatesh Raghavan, Amr El-Helw, Zhongxian Gu, Entong Shen, George C
Mohamed A. Soliman, Lyublena Antova, Venkatesh Raghavan, Amr El-Helw, Zhongxian Gu, Entong Shen, George C. Caragea, Carlos Garcia-Alvarado, Foyzur Rahman, Michalis Petropoulos, Florian Waas, Sivaramakrishnan Narayanan, Konstantinos Krikellas, and Rhonda Baldwin. 2014. Orca: a modular query optimizer architecture for big data. InProceedings of the 2014 ACM...
- [19]
-
[20]
Zhaoyan Sun, Xuanhe Zhou, Guoliang Li, Xiang Yu, Jianhua Feng, and Yong Zhang. 2025. R-Bot: An LLM-Based Query Rewrite System.Proc. VLDB Endow. Qi Cheng, Yang Sun, Weidong Yu, Danny Chen, Weicheng Wang, Chong Chen, and Per-Åke Larson 18, 12 (Aug. 2025), 5031–5044. https://doi.org/10.14778/3750601.3750625
-
[21]
Meduri Venkata Vamsikrishna and Kian-Lee Tan. 2011. Subquery plan reuse based query optimization. InProceedings of the 17th International Conference on Management of Data(Bangalore, India)(COMAD ’11). Computer Society of India, Mumbai, Maharashtra, IND, Article 11, 12 pages
2011
-
[22]
Zhaoguo Wang, Zhou Zhou, Yicun Yang, Haoran Ding, Gansen Hu, Ding Ding, Chuzhe Tang, Haibo Chen, and Jinyang Li. 2022. WeTune: Automatic Dis- covery and Verification of Query Rewrite Rules. InProceedings of the 2022 In- ternational Conference on Management of Data(Philadelphia, PA, USA)(SIG- MOD ’22). Association for Computing Machinery, New York, NY, USA...
-
[23]
Yan and Per-Åke Larson
Weipeng P. Yan and Per-Åke Larson. 1995. Eager Aggregation and Lazy Aggre- gation. InProceedings of the 21th International Conference on Very Large Data Bases (VLDB ’95). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 345–357
1995
-
[24]
Tim Zeyl, Qi Cheng, Reza Pournaghi, Jason Lam, Weicheng Wang, Calvin Wong, Chong Chen, and Per-Ake Larson. 2025. Including Bloom Filters in Bottom-up Optimization. InCompanion of the 2025 International Conference on Management of Data(Berlin, Germany)(SIGMOD/PODS ’25). Association for Computing Ma- chinery, New York, NY, USA, 703–715. https://doi.org/10.1...
-
[25]
Jingren Zhou, Per-Ake Larson, Johann-Christoph Freytag, and Wolfgang Lehner
-
[26]
Efficient exploitation of similar subexpressions for query processing. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data(Beijing, China)(SIGMOD ’07). Association for Computing Machinery, New York, NY, USA, 533–544. https://doi.org/10.1145/1247480.1247540
-
[27]
Xuanhe Zhou, Guoliang Li, Chengliang Chai, and Jianhua Feng. 2021. A learned query rewrite system using Monte Carlo tree search.Proc. VLDB Endow.15, 1 (Sept. 2021), 46–58. https://doi.org/10.14778/3485450.3485456
-
[28]
Qiang Zhu, Yingying Tao, and Calisto Zuzarte. 2005. Optimizing complex queries based on similarities of subqueries.Knowledge and Information Systems8, 3 (2005), 350–373. https://doi.org/10.1007/s10115-004-0189-y
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.