Recognition: no theorem link
Height-Guided Projection Reparameterization for Camera-LiDAR Occupancy
Pith reviewed 2026-05-12 03:57 UTC · model grok-4.3
The pith
LiDAR height maps adaptively reparameterize camera projection pillars to capture real-world scene sparsity and height variation in 3D occupancy prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HiPR encodes LiDAR into a BEV height map that records the maximum height per pillar, then reparameterizes each pillar's vertical sampling range according to this prior so that projected points concentrate in geometrically occupied space rather than fixed intervals; invalid height regions are masked, and a Progressive Height Conditioning schedule gradually replaces ground-truth heights with LiDAR heights during training to stabilize learning.
What carries the argument
Height-Guided Projection Reparameterization: a LiDAR-derived BEV height map that dynamically rescales the vertical sampling interval of each projection pillar before feature lifting.
If this is right
- Projected points concentrate inside occupied volumes, reducing ambiguous correspondences between image features and empty 3D space.
- Masking invalid height-map regions prevents the network from aggregating features from non-existent geometry.
- Progressive replacement of ground-truth heights with LiDAR heights keeps training stable while still allowing the model to use real sensor data at test time.
- The same accuracy gain is obtained at real-time speeds because the extra height computation occurs only once per pillar.
- Outperformance holds across multiple camera-LiDAR occupancy benchmarks without architectural changes to the backbone.
Where Pith is reading between the lines
- The same height-prior trick could be applied to other view-transformation tasks such as depth estimation or BEV segmentation whenever vertical sparsity varies strongly.
- Early injection of a geometric prior at the projection stage appears more efficient than attempting to recover the same information through later network layers.
- If height maps from cheaper sensors (radar or monocular depth) prove sufficient, the method could reduce reliance on full LiDAR at inference.
- Fixed-range sampling wastes capacity on empty vertical space; adaptive reparameterization therefore implies a general efficiency gain for any pillar-based 3D representation.
Load-bearing premise
LiDAR height maps must supply priors accurate enough that the progressive conditioning can prevent them from misleading feature aggregation during training.
What would settle it
An ablation that replaces height-guided range adjustment with fixed uniform sampling and shows no drop in occupancy mIoU or mAP on the same benchmarks would falsify the benefit of the reparameterization.
Figures




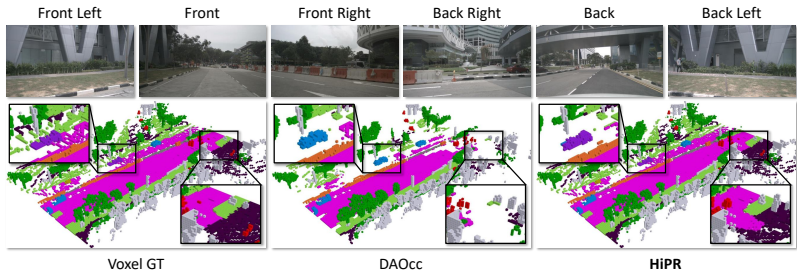
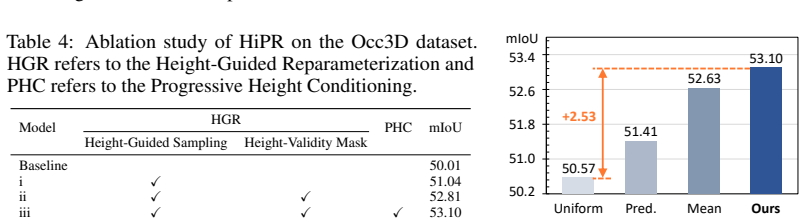


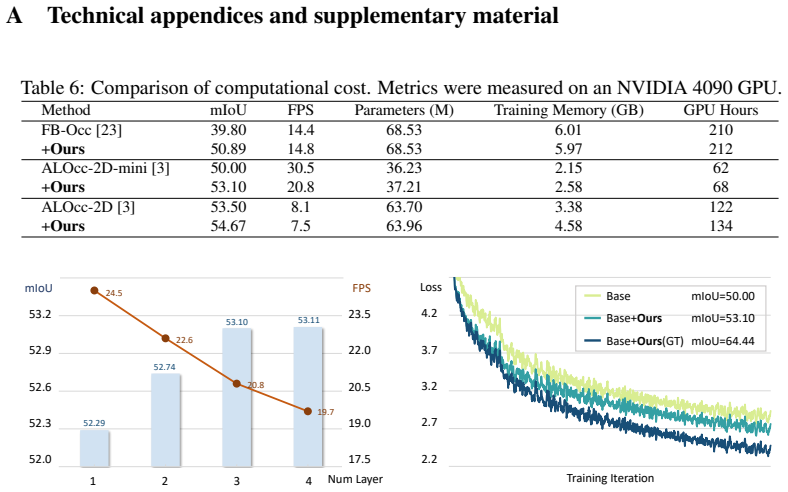

read the original abstract
3D occupancy prediction aims to infer dense, voxel-wise scene semantics from sensor observations, where the 2D-to-3D view transformation serves as a crucial step in bridging image features and volumetric representations. Most previous methods rely on a fixed projection space, where 3D reference points are uniformly sampled along pillars. However, such sampling struggles to capture the sparsity and height variations of real-world scenes, leading to ambiguous correspondences and unreliable feature aggregation. To address these challenges, we propose HiPR, a camera-LiDAR occupancy framework with Height-Guided Projection Reparameterization. HiPR first encodes LiDAR into a BEV height map to capture the maximum height of the point cloud. HiPR then adjusts the sampling range of each pillar using the height prior, enabling adaptive reparameterization of the projection space. As a result, the projected points are redistributed into geometrically meaningful regions rather than fixed ranges. Meanwhile, we mask out the invalid parts of the height map to avoid misleading the feature aggregation. In addition, to alleviate the training instability caused by noisy LiDAR-derived heights, we introduce a training-time Progressive Height Conditioning strategy, which gradually transitions the conditioning signal from ground-truth heights to LiDAR heights. Extensive experiments demonstrate that HiPR consistently outperforms existing state-of-the-art methods while maintaining real-time inference. The code and pretrained models can be found at https://github.com/yanzq95/HiPR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HiPR, a camera-LiDAR framework for 3D occupancy prediction. It encodes LiDAR points into a BEV height map to derive per-pillar maximum heights, then reparameterizes the sampling ranges of 3D pillars during 2D-to-3D projection so that image features are aggregated into geometrically adaptive rather than uniformly spaced intervals. Invalid (zero or low-count) pillars are masked, and a progressive conditioning schedule transitions the height signal from ground-truth to LiDAR-derived values during training. The authors claim this yields consistent gains over prior state-of-the-art methods while preserving real-time inference speed.
Significance. If the reported gains prove robust, the work offers a constructive, parameter-light way to inject scene geometry into view transformation, addressing a known weakness of fixed-range pillar sampling. The public release of code and pretrained models is a clear strength that supports reproducibility and follow-up research in multi-modal 3D perception.
major comments (2)
- [§3.2] §3.2 (Height-Guided Reparameterization): the central claim that redistributed points land in 'geometrically meaningful regions' rests on the assumption that the per-pillar max-height extracted from the LiDAR BEV map is both accurate and non-misleading wherever image features exist. The masking rule (zero-height or low-point-count pillars) does not address under-estimated but non-zero heights that commonly arise in distant, occluded, or low-reflectance surfaces; at inference the progressive conditioning is inactive, so any residual mismatch directly alters projection geometry and feature aggregation. No quantitative analysis of height-error propagation or failure-case frequency is provided.
- [§4.3] §4.3 and Table 3 (Ablation and robustness): the ablation isolates the contribution of progressive conditioning and masking, yet contains no stress tests on high-sparsity or long-range subsets where LiDAR height priors are known to degrade. Without such targeted evaluation, the claim of 'consistent outperformance' cannot be separated from the possibility that gains are concentrated in well-observed regions.
minor comments (2)
- [§4.4] The real-time claim is supported by FPS numbers, but the additional latency of height-map extraction and per-pillar range adjustment is not broken out; a simple timing table would clarify whether the overhead remains negligible in an end-to-end pipeline.
- [§3.2] Notation for the adjusted sampling bounds (e.g., the exact mapping from height value to pillar start/end) would benefit from an explicit equation rather than prose description.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications and indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Height-Guided Reparameterization): the central claim that redistributed points land in 'geometrically meaningful regions' rests on the assumption that the per-pillar max-height extracted from the LiDAR BEV map is both accurate and non-misleading wherever image features exist. The masking rule (zero-height or low-point-count pillars) does not address under-estimated but non-zero heights that commonly arise in distant, occluded, or low-reflectance surfaces; at inference the progressive conditioning is inactive, so any residual mismatch directly alters projection geometry and feature aggregation. No quantitative analysis of height-error propagation or failure-case frequency is provided.
Authors: We appreciate the referee's emphasis on the reliability of the height priors. The masking rule explicitly excludes pillars with zero height or point counts below a threshold, which removes the most unreliable cases. For under-estimated but non-zero heights in distant or occluded regions, the progressive conditioning schedule is designed to train the model to remain robust to noisy height signals by gradually introducing LiDAR-derived values. At inference, the height map is computed directly from the input LiDAR point cloud without conditioning, and our main results demonstrate that this yields consistent improvements across the evaluated datasets. We acknowledge that a dedicated quantitative analysis of height-error propagation and failure cases is absent from the current version. We will add a new subsection under Experiments that reports height estimation error statistics, failure-case frequency on subsets with occlusion or low reflectance, and qualitative examples of projection mismatches. revision: partial
-
Referee: [§4.3] §4.3 and Table 3 (Ablation and robustness): the ablation isolates the contribution of progressive conditioning and masking, yet contains no stress tests on high-sparsity or long-range subsets where LiDAR height priors are known to degrade. Without such targeted evaluation, the claim of 'consistent outperformance' cannot be separated from the possibility that gains are concentrated in well-observed regions.
Authors: We agree that the existing ablations do not isolate performance on high-sparsity or long-range subsets. Our primary quantitative results on nuScenes and Waymo already span a range of scene densities and distances, with HiPR showing gains in both mIoU and other metrics. To directly address the concern, we will extend the ablation study (currently Table 3) with two new rows or a supplementary table evaluating performance on long-range subsets (e.g., voxels beyond 50 m) and high-sparsity regions (defined by low LiDAR point density). This will allow readers to assess whether the gains hold where height priors are expected to be less reliable. revision: yes
Circularity Check
No significant circularity; constructive reparameterization with independent empirical validation.
full rationale
The paper defines HiPR as a direct, non-tautological pipeline: LiDAR BEV height map extraction provides an external prior, pillar sampling ranges are explicitly reparameterized from that prior, invalid regions are masked by a separate rule, and progressive conditioning is a training schedule that transitions between GT and LiDAR signals. None of these steps are defined in terms of the final occupancy output or fitted parameters that are later renamed as predictions. The outperformance claim rests on comparative experiments rather than any self-referential derivation. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present in the supplied text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LiDAR point clouds can be reliably encoded into a BEV height map that captures maximum heights per ground location
Reference graph
Works this paper leans on
-
[1]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
work page 2020
-
[2]
Occany: Generalized unconstrained urban 3d occupancy
Anh-Quan Cao and Tuan-Hung Vu. Occany: Generalized unconstrained urban 3d occupancy. InConference on Computer Vision and Pattern Recognition (CVPR), 2026
work page 2026
-
[3]
Alocc: Adaptive lifting-based 3d semantic occupancy and cost volume-based flow predictions
Dubing Chen, Jin Fang, Wencheng Han, Xinjing Cheng, Junbo Yin, Chengzhong Xu, Fa- had Shahbaz Khan, and Jianbing Shen. Alocc: Adaptive lifting-based 3d semantic occupancy and cost volume-based flow predictions. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 4156–4166, 2025
work page 2025
-
[4]
Rethinking temporal fusion with a unified gradient descent view for 3d semantic occupancy prediction
Dubing Chen, Huan Zheng, Jin Fang, Xingping Dong, Xianfei Li, Wenlong Liao, Tao He, Pai Peng, and Jianbing Shen. Rethinking temporal fusion with a unified gradient descent view for 3d semantic occupancy prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1505–1515, 2025
work page 2025
-
[5]
Semantic causality-aware vision-based 3d occupancy prediction
Dubing Chen, Huan Zheng, Yucheng Zhou, Xianfei Li, Wenlong Liao, Tao He, Pai Peng, and Jianbing Shen. Semantic causality-aware vision-based 3d occupancy prediction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24878–24888, 2025
work page 2025
-
[6]
MMDetection: Open MMLab Detection Toolbox and Benchmark
Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, et al. Mmdetection: Open mmlab detection toolbox and benchmark.arXiv preprint arXiv:1906.07155, 2019
work page Pith review arXiv 1906
-
[7]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022
work page 2022
-
[8]
Bev-san: Accurate bev 3d object detection via slice attention networks
Xiaowei Chi, Jiaming Liu, Ming Lu, Rongyu Zhang, Zhaoqing Wang, Yandong Guo, and Shanghang Zhang. Bev-san: Accurate bev 3d object detection via slice attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17461–17470, 2023
work page 2023
-
[9]
Chenxu Dang, Haiyan Liu, Jason Bao, Pei An, Xinyue Tang, An Pan, Jie Ma, Bingchuan Sun, and Yan Wang. Sparseworld: A flexible, adaptive, and efficient 4d occupancy world model powered by sparse and dynamic queries. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3497–3505, 2026
work page 2026
-
[10]
SparseWorld-TC: Trajectory-Conditioned Sparse Occupancy World Model
Jiayuan Du, Yiming Zhao, Zhenglong Guo, Yong Pan, Wenbo Hou, Zhihui Hao, Kun Zhan, and Qijun Chen. Sparseworld-tc: Trajectory-conditioned sparse occupancy world model.arXiv preprint arXiv:2511.22039, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
ZaiPeng Duan, ChenXu Dang, Xuzhong Hu, Pei An, Junfeng Ding, Jie Zhan, YunBiao Xu, and Jie Ma. Sdgocc: Semantic and depth-guided bird’s-eye view transformation for 3d multi- modal occupancy prediction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6751–6760, 2025
work page 2025
-
[12]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[13]
Yulin He, Wei Chen, Siqi Wang, Tianci Xun, and Yusong Tan. Achieving speed-accuracy balance in vision-based 3d occupancy prediction via geometric-semantic disentanglement. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 3455–3463, 2025
work page 2025
-
[14]
Fastocc: Accelerating 3d occupancy prediction by fusing the 2d bird’s-eye view and perspective view
Jiawei Hou, Xiaoyan Li, Wenhao Guan, Gang Zhang, Di Feng, Yuheng Du, Xiangyang Xue, and Jian Pu. Fastocc: Accelerating 3d occupancy prediction by fusing the 2d bird’s-eye view and perspective view. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16425–16431. IEEE, 2024. 10
work page 2024
-
[15]
Junjie Huang, Guan Huang, Zheng Zhu, Yun Ye, and Dalong Du. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view.arXiv preprint arXiv:2112.11790, 2021
-
[16]
Tri-perspective view for vision-based 3d semantic occupancy prediction
Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. Tri-perspective view for vision-based 3d semantic occupancy prediction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9223–9232, 2023
work page 2023
-
[17]
Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction
Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction. InEuropean Conference on Computer Vision, pages 376–393. Springer, 2024
work page 2024
-
[18]
Gaussianformer-2: Probabilistic gaussian superposition for efficient 3d occupancy prediction
Yuanhui Huang, Amonnut Thammatadatrakoon, Wenzhao Zheng, Yunpeng Zhang, Dalong Du, and Jiwen Lu. Gaussianformer-2: Probabilistic gaussian superposition for efficient 3d occupancy prediction. InProceedings of the computer vision and pattern recognition conference, pages 27477–27486, 2025
work page 2025
-
[19]
Jungho Kim, Changwon Kang, Dongyoung Lee, Sehwan Choi, and Jun Won Choi. Protoocc: Accurate, efficient 3d occupancy prediction using dual branch encoder-prototype query decoder. InProceedings of the AAAI Conference on Artificial Intelligence, pages 4284–4292, 2025
work page 2025
-
[20]
Occupancy learning with spatiotem- poral memory
Ziyang Leng, Jiawei Yang, Wenlong Yi, and Bolei Zhou. Occupancy learning with spatiotem- poral memory. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 26569–26578, 2025
work page 2025
-
[21]
Bevstereo: Enhanc- ing depth estimation in multi-view 3d object detection with temporal stereo
Yinhao Li, Han Bao, Zheng Ge, Jinrong Yang, Jianjian Sun, and Zeming Li. Bevstereo: Enhanc- ing depth estimation in multi-view 3d object detection with temporal stereo. InProceedings of the AAAI conference on artificial intelligence, pages 1486–1494, 2023
work page 2023
-
[22]
Bevdepth: Acquisition of reliable depth for multi-view 3d object detection
Yinhao Li, Zheng Ge, Guanyi Yu, Jinrong Yang, Zengran Wang, Yukang Shi, Jianjian Sun, and Zeming Li. Bevdepth: Acquisition of reliable depth for multi-view 3d object detection. In Proceedings of the AAAI conference on artificial intelligence, pages 1477–1485, 2023
work page 2023
-
[23]
Zhiqi Li, Zhiding Yu, David Austin, Mingsheng Fang, Shiyi Lan, Jan Kautz, and Jose M Alvarez. Fb-occ: 3d occupancy prediction based on forward-backward view transformation. arXiv preprint arXiv:2307.01492, 2023
-
[24]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(3):2020– 2036, 2024
work page 2020
-
[25]
Zhihao Li, Shanshan Zhang, and Jian Yang. Ashsr: Enhancing query-based occupancy predic- tion via anti-occlusion sampling and hard sample reweighting.Neurocomputing, 676:133007, 2026
work page 2026
-
[26]
Stcocc: Sparse spatial-temporal cascade renovation for 3d occupancy and scene flow prediction
Zhimin Liao, Ping Wei, Shuaijia Chen, Haoxuan Wang, and Ziyang Ren. Stcocc: Sparse spatial-temporal cascade renovation for 3d occupancy and scene flow prediction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1516–1526, 2025
work page 2025
-
[27]
Fully sparse 3d occupancy prediction
Haisong Liu, Yang Chen, Haiguang Wang, Zetong Yang, Tianyu Li, Jia Zeng, Li Chen, Hongyang Li, and Limin Wang. Fully sparse 3d occupancy prediction. InEuropean Conference on Computer Vision, pages 54–71. Springer, 2024
work page 2024
-
[28]
Ruixun Liu, Lingyu Kong, Derun Li, and Hang Zhao. Occvla: Vision-language-action model with implicit 3d occupancy supervision.arXiv preprint arXiv:2509.05578, 2025
-
[29]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Chuandong Lyu, Wenkai Li, Iman Yi Liao, Fengqian Ding, Han Liu, and Hongchao Zhou. Hbevocc: Height-aware bird’s-eye-view representation for 3d occupancy prediction from multi- camera images.Sensors (Basel, Switzerland), 26(3):934, 2026. 11
work page 2026
-
[31]
Cotr: Compact occupancy transformer for vision-based 3d occupancy prediction
Qihang Ma, Xin Tan, Yanyun Qu, Lizhuang Ma, Zhizhong Zhang, and Yuan Xie. Cotr: Compact occupancy transformer for vision-based 3d occupancy prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19936–19945, 2024
work page 2024
-
[32]
Yukai Ma, Jianbiao Mei, Xuemeng Yang, Licheng Wen, Weihua Xu, Jiangning Zhang, Xingxing Zuo, Botian Shi, and Yong Liu. Licrocc: Teach radar for accurate semantic occupancy prediction using lidar and camera.IEEE Robotics and Automation Letters, 10(1):852–859, 2024
work page 2024
-
[33]
Zhenxing Ming, Julie Stephany Berrio, Mao Shan, and Stewart Worrall. Occfusion: Multi-sensor fusion framework for 3d semantic occupancy prediction.IEEE Transactions on Intelligent Vehicles, 2024
work page 2024
-
[34]
Zhenxing Ming, Julie Stephany Berrio, Mao Shan, Yaoqi Huang, Hongyu Lyu, Nguyen Hoang Khoi Tran, Tzu-Yun Tseng, and Stewart Worrall. Occcylindrical: Multi-modal fu- sion with cylindrical representation for 3d semantic occupancy prediction.arXiv preprint arXiv:2505.03284, 2025
-
[35]
Jingyi Pan, Zipeng Wang, and Lin Wang. Co-occ: Coupling explicit feature fusion with volume rendering regularization for multi-modal 3d semantic occupancy prediction.IEEE Robotics and Automation Letters, 9(6):5687–5694, 2024
work page 2024
-
[36]
Renderocc: Vision-centric 3d occupancy prediction with 2d rendering supervision
Mingjie Pan, Jiaming Liu, Renrui Zhang, Peixiang Huang, Xiaoqi Li, Hongwei Xie, Bing Wang, Li Liu, and Shanghang Zhang. Renderocc: Vision-centric 3d occupancy prediction with 2d rendering supervision. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 12404–12411. IEEE, 2024
work page 2024
-
[37]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d
Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. InEuropean conference on computer vision, pages 194–210. Springer, 2020
work page 2020
-
[38]
Irfan Qaisar, Kailai Sun, Dianyu Zhong, Xu Yang, Xi Miao, and Qianchuan Zhao. Occ- mamba: A mamba-based deep learning approach for indoor occupancy prediction.Building and Environment, page 114085, 2025
work page 2025
-
[39]
Ocbev: Object-centric bev transformer for multi-view 3d object detection
Zhangyang Qi, Jiaqi Wang, Xiaoyang Wu, and Hengshuang Zhao. Ocbev: Object-centric bev transformer for multi-view 3d object detection. In2024 International Conference on 3D Vision (3DV), pages 1188–1197. IEEE, 2024
work page 2024
-
[40]
Effocc: Learning efficient occupancy networks from minimal labels for autonomous driving
Yining Shi, Kun Jiang, Jinyu Miao, Ke Wang, Kangan Qian, Yunlong Wang, Jiusi Li, Tuopu Wen, Mengmeng Yang, Yiliang Xu, et al. Effocc: Learning efficient occupancy networks from minimal labels for autonomous driving. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 17008–17015. IEEE, 2025
work page 2025
-
[41]
Reocc: Camera-radar fusion with radar feature enrichment for 3d occupancy prediction
Chaehee Song, Sanmin Kim, Hyeonjun Jeong, Juyeb Shin, Joonhee Lim, and Dongsuk Kum. Reocc: Camera-radar fusion with radar feature enrichment for 3d occupancy prediction. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 15367–15374. IEEE, 2025
work page 2025
-
[42]
Xiaoyu Tian, Tao Jiang, Longfei Yun, Yue Wang, Yilun Wang, and Hang Zhao. Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving.arXiv preprint arXiv:2304.14365, 2023
-
[43]
Occgen: Generative multi-modal 3d occupancy prediction for autonomous driving
Guoqing Wang, Zhongdao Wang, Pin Tang, Jilai Zheng, Xiangxuan Ren, Bailan Feng, and Chao Ma. Occgen: Generative multi-modal 3d occupancy prediction for autonomous driving. InEuropean Conference on Computer Vision, pages 95–112. Springer, 2024
work page 2024
-
[44]
Jiabao Wang, Zhaojiang Liu, Qiang Meng, Liujiang Yan, Ke Wang, Jie Yang, Wei Liu, Qibin Hou, and Ming-Ming Cheng. Opus: occupancy prediction using a sparse set.Advances in Neural Information Processing Systems, 37:119861–119885, 2024. 12
work page 2024
-
[45]
Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception
Xiaofeng Wang, Zheng Zhu, Wenbo Xu, Yunpeng Zhang, Yi Wei, Xu Chi, Yun Ye, Dalong Du, Jiwen Lu, and Xingang Wang. Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17850–17859, 2023
work page 2023
-
[46]
Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving
Yi Wei, Linqing Zhao, Wenzhao Zheng, Zheng Zhu, Jie Zhou, and Jiwen Lu. Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21729–21740, 2023
work page 2023
-
[47]
Zhiqiang Wei, Lianqing Zheng, Jianan Liu, Tao Huang, Qing-Long Han, Wenwen Zhang, and Fengdeng Zhang. Ms-occ: Multi-stage lidar-camera fusion for 3d semantic occupancy prediction.arXiv preprint arXiv:2504.15888, 2025
-
[48]
Unleashing hydra: Hybrid fusion, depth consistency and radar for unified 3d perception
Philipp Wolters, Johannes Gilg, Torben Teepe, Fabian Herzog, Anouar Laouichi, Martin Hofmann, and Gerhard Rigoll. Unleashing hydra: Hybrid fusion, depth consistency and radar for unified 3d perception. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 7467–7474. IEEE, 2025
work page 2025
-
[49]
Di Wu, Feng Yang, Benlian Xu, Pan Liao, Wenhui Zhao, and Dingwen Zhang. Hv-bev: Decoupling horizontal and vertical feature sampling for multi-view 3d object detection.IEEE Transactions on Intelligent Transportation Systems, 2025
work page 2025
-
[50]
Deep height decoupling for precise vision-based 3d occupancy prediction
Yuan Wu, Zhiqiang Yan, Zhengxue Wang, Xiang Li, Le Hui, and Jian Yang. Deep height decoupling for precise vision-based 3d occupancy prediction. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 12647–12654. IEEE, 2025
work page 2025
-
[51]
Yuan Wu, Zhiqiang Yan, Yigong Zhang, Xiang Li, and Jian Yang. See through the dark: Learning illumination-affined representations for nighttime occupancy prediction.arXiv preprint arXiv:2505.20641, 2025
-
[52]
Yu Yang, Jianbiao Mei, Yukai Ma, Siliang Du, Wenqing Chen, Yijie Qian, Yuxiang Feng, and Yong Liu. Driving in the occupancy world: Vision-centric 4d occupancy forecasting and planning via world models for autonomous driving. InProceedings of the AAAI Conference on Artificial Intelligence, pages 9327–9335, 2025
work page 2025
-
[53]
Zhen Yang, Yanpeng Dong, Jiayu Wang, Heng Wang, Lichao Ma, Zijian Cui, Qi Liu, Haoran Pei, Kexin Zhang, and Chao Zhang. Daocc: 3d object detection assisted multi-sensor fusion for 3d occupancy prediction.IEEE Transactions on Circuits and Systems for Video Technology, 2025
work page 2025
-
[54]
Zichen Yu, Changyong Shu, Jiajun Deng, Kangjie Lu, Zongdai Liu, Jiangyong Yu, Dawei Yang, Hui Li, and Yan Chen. Flashocc: Fast and memory-efficient occupancy prediction via channel-to-height plugin.arXiv preprint arXiv:2311.12058, 2023
-
[55]
Radocc: Learning cross-modality occupancy knowledge through rendering assisted distillation
Haiming Zhang, Xu Yan, Dongfeng Bai, Jiantao Gao, Pan Wang, Bingbing Liu, Shuguang Cui, and Zhen Li. Radocc: Learning cross-modality occupancy knowledge through rendering assisted distillation. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7060–7068, 2024
work page 2024
-
[56]
Lianqing Zheng, Jianan Liu, Runwei Guan, Long Yang, Shouyi Lu, Yuanzhe Li, Xiaokai Bai, Jie Bai, Zhixiong Ma, Hui-Liang Shen, et al. Doracamom: Joint 3d detection and occupancy prediction with multi-view 4d radars and cameras for omnidirectional perception.IEEE Transactions on Circuits and Systems for Video Technology, 2026
work page 2026
-
[57]
Occworld: Learning a 3d occupancy world model for autonomous driving
Wenzhao Zheng, Weiliang Chen, Yuanhui Huang, Borui Zhang, Yueqi Duan, and Jiwen Lu. Occworld: Learning a 3d occupancy world model for autonomous driving. InEuropean conference on computer vision, pages 55–72. Springer, 2024
work page 2024
-
[58]
Yuchen Zhou, Yan Luo, Xiaogang Wang, Xingjian Gu, Mingzhou Lu, and Xiangbo Shu. Da-occ: Direction-aware 2d convolution for efficient and geometry-preserving 3d occupancy prediction in autonomous driving.arXiv preprint arXiv:2507.23599, 2025
-
[59]
Xubo Zhu, Haoyang Zhang, Fei He, Rui Wu, Yanhu Shan, Wen Yang, and Huai Yu. Dr. occ: Depth-and region-guided 3d occupancy from surround-view cameras for autonomous driving. arXiv preprint arXiv:2603.01007, 2026. 13 A Technical appendices and supplementary material Table 6: Comparison of computational cost. Metrics were measured on an NVIDIA 4090 GPU. Meth...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.