Recognition: unknown
Heterogeneous Judge-Aware Ranking with Sensitivity, Disagreement, and Confidence
Pith reviewed 2026-05-08 16:21 UTC · model grok-4.3
The pith
A ranking method for multi-judge pairwise data separates shared consensus from each judge's sensitivity and leftover disagreements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pairwise comparisons from multiple judges arise from a consensus ranking that is scaled by judge-specific sensitivity parameters and then augmented by residual disagreement terms. Under conditions the paper establishes, this decomposition is identifiable, and an anchored alternating algorithm recovers the consensus ranks, the sensitivity values, and summaries of residual disagreement. In a fixed-panel repeated-comparison regime, where the judge set stays modest but the number of judgments grows, the model supplies uncertainty statements for the consensus ranking, judge-specific contrasts, sensitivity parameters, pairwise probabilities, and disagreement summaries. Experiments on synthetic and
What carries the argument
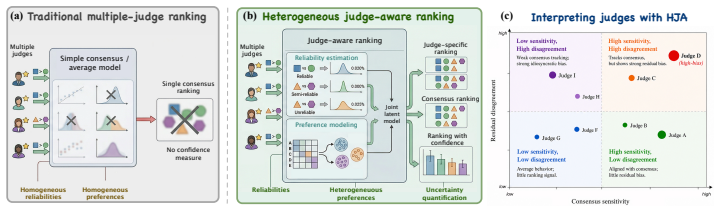
The Heterogeneous Judge-Aware (HJA) decomposition that expresses observed comparisons through a shared consensus ranking, judge-specific sensitivity multipliers, and a residual disagreement matrix.
If this is right
- Ranking, judge sensitivity, and structured disagreement become separate inferential targets rather than being collapsed into a single pooled score.
- Uncertainty quantification becomes available for consensus ranks, sensitivity parameters, pairwise probabilities, and disagreement summaries as repeated judgments accumulate.
- The fitted model supplies diagnostics that reveal patterns of judge disagreement and affinities between specific judges and items.
- Recovery of the underlying ranking, robustness to noise, and performance near ties improve relative to methods that ignore heterogeneity or model only sensitivity.
Where Pith is reading between the lines
- The sensitivity estimates could be used to down-weight judges whose responses deviate strongly from the consensus when forming final decisions.
- Disagreement diagnostics might allow clustering of judges into more homogeneous subgroups for targeted follow-up evaluation.
- The repeated-comparison uncertainty regime could support sequential stopping rules that decide when enough judgments have been collected for a desired precision level.
Load-bearing premise
The observed comparisons must be generated from a process whose structure matches the consensus-plus-sensitivity-plus-residual decomposition closely enough for the parameters to be uniquely recoverable.
What would settle it
In controlled simulations with known true consensus and sensitivities, the method returns confidence intervals for near-tie pairwise probabilities that systematically fail to cover the observed reversal frequencies across repeated judgments.
Figures


read the original abstract
Pairwise comparisons from multiple judges are central to large language model evaluation and preference modeling, yet standard ranking pipelines often pool judgments into a single score vector, treating systematic judge disagreement as noise. We propose Heterogeneous Judge-Aware (HJA) ranking, a structured multi-judge ranking framework that separates consensus ranking, judge-specific sensitivity to consensus, and residual preference disagreement. HJA thereby treats ranking, judge sensitivity, and structured disagreement as separate inferential targets. We establish conditions under which this decomposition is identifiable and develop an anchored alternating algorithm that preserves the identifying geometry. For confidence quantification, we study a fixed-panel repeated-comparison regime in which the judge panel may remain fixed or modest while information grows through repeated judgments. This yields uncertainty statements for consensus and judge-specific ranking contrasts, sensitivity parameters, pairwise probabilities, and summaries of residual disagreement.Experiments on synthetic and real multi-judge comparison data show that HJA improves recovery, robustness, uncertainty calibration, and near-tie performance relative to pooled and sensitivity-only baselines. The fitted model also provides diagnostics for judge disagreement and model-affinity patterns, giving a statistically grounded framework for ranking under heterogeneous comparative judgments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Heterogeneous Judge-Aware (HJA) ranking, a framework for multi-judge pairwise comparison data that decomposes judgments into a consensus ranking, judge-specific sensitivity parameters, and residual disagreement. It establishes identifiability conditions for the decomposition, introduces an anchored alternating algorithm that preserves the identifying geometry, and develops uncertainty quantification under a fixed-panel repeated-comparison regime where information accumulates through repeated judgments. Synthetic and real-data experiments are reported to show gains in recovery, robustness, uncertainty calibration, and near-tie performance relative to pooled and sensitivity-only baselines, along with diagnostics for judge disagreement patterns.
Significance. If the identifiability theorem, algorithm recovery, and empirical results hold, the work supplies a statistically grounded approach to heterogeneous judgments in ranking tasks such as LLM evaluation and preference modeling. Treating ranking, sensitivity, and structured disagreement as separate inferential targets enables targeted inference and diagnostics that pooled methods lack. The manuscript supplies an identifiability theorem, algorithm derivation, and comparative experiments on synthetic and real multi-judge data; these are explicit strengths. The fixed-panel regime for forming uncertainty statements as repeated judgments accumulate is a practical contribution for settings with limited judges.
minor comments (4)
- Abstract: the statement of experimental gains would be more informative if it included one or two concrete metrics (e.g., recovery error reduction or calibration improvement) rather than qualitative descriptors alone.
- Model definition (likely §2): the notation distinguishing the consensus ranking vector, judge-specific sensitivity scalars, and residual disagreement matrix should be introduced with an explicit small example to prevent reader confusion between the three components.
- Experiments section: figures reporting recovery and calibration results should include error bars or interval estimates so that the magnitude and consistency of gains over baselines can be assessed visually.
- Algorithm description: the anchoring step in the alternating procedure would benefit from a short pseudocode block or numerical illustration showing how the geometry is preserved at each iteration.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript and for recommending minor revision. The summary accurately captures the contributions regarding identifiability, the anchored alternating algorithm, uncertainty quantification under the fixed-panel regime, and the empirical comparisons.
Circularity Check
No significant circularity; identifiability theorem and algorithm are independently derived
full rationale
The paper states that it establishes conditions for identifiability of the consensus-sensitivity-disagreement decomposition and develops an anchored alternating algorithm that preserves the identifying geometry. Uncertainty statements arise from the fixed-panel repeated-judgment regime. No quoted step reduces a prediction or parameter to a fitted input by construction, nor does any load-bearing claim rest on a self-citation chain or imported uniqueness result. Experiments compare against pooled and sensitivity-only baselines using synthetic and real data, providing external validation. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- judge-specific sensitivity parameters
- consensus ranking and residual disagreement parameters
axioms (2)
- domain assumption Conditions under which the decomposition into consensus, sensitivity, and residual disagreement is identifiable
- domain assumption Fixed-panel repeated-comparison regime allows uncertainty quantification as information grows through repeated judgments
Reference graph
Works this paper leans on
-
[1]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595– 46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595– 46623, 2023
2023
-
[2]
Deep reinforcement learning from human preferences.Advances in neural information pro- cessing systems, 30, 2017
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in neural information pro- cessing systems, 30, 2017
2017
-
[3]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[4]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[5]
Pairwise ranking ag- gregation in a crowdsourced setting
Xi Chen, Paul N Bennett, Kevyn Collins-Thompson, and Eric Horvitz. Pairwise ranking ag- gregation in a crowdsourced setting. InProceedings of the sixth ACM international conference on Web search and data mining, pages 193–202, 2013
2013
-
[6]
Irt-based aggre- gation model of crowdsourced pairwise comparison for evaluating machine translations
Naoki Otani, Toshiaki Nakazawa, Daisuke Kawahara, and Sadao Kurohashi. Irt-based aggre- gation model of crowdsourced pairwise comparison for evaluating machine translations. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 511–520, 2016
2016
-
[7]
Language model coun- cil: Democratically benchmarking foundation models on highly subjective tasks
Justin Zhao, Flor Miriam Plaza-del Arco, and Amanda Cercas Curry. Language model coun- cil: Democratically benchmarking foundation models on highly subjective tasks. InProceed- ings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1239...
2025
-
[8]
Ranking large language models without ground truth
Amit Dhurandhar, Rahul Nair, Moninder Singh, Elizabeth Daly, and Karthikeyan Natesan Ra- mamurthy. Ranking large language models without ground truth. InFindings of the Association for Computational Linguistics: ACL 2024, pages 2431–2452, 2024
2024
-
[9]
Llms instead of human judges? a large scale empirical study across 20 nlp evaluation tasks
Anna Bavaresco, Raffaella Bernardi, Leonardo Bertolazzi, Desmond Elliott, Raquel Fernán- dez, Albert Gatt, Esam Ghaleb, Mario Giulianelli, Michael Hanna, Alexander Koller, et al. Llms instead of human judges? a large scale empirical study across 20 nlp evaluation tasks. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguist...
2025
-
[10]
How reliable is multilingual llm-as-a-judge? InFindings of the Associa- tion for Computational Linguistics: EMNLP 2025
Xiyan Fu and Wei Liu. How reliable is multilingual llm-as-a-judge? InFindings of the Associa- tion for Computational Linguistics: EMNLP 2025. Association for Computational Linguistics, 2025
2025
-
[11]
Validating llm-as-a-judge systems under rating indeterminacy
Luke Guerdan, Solon Barocas, Ken Holstein, Hanna Wallach, Steven Wu, and Alexandra Chouldechova. Validating llm-as-a-judge systems under rating indeterminacy. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[12]
Re- evaluating automatic llm system ranking for alignment with human preference
Mingqi Gao, Yixin Liu, Xinyu Hu, Xiaojun Wan, Jonathan Bragg, and Arman Cohan. Re- evaluating automatic llm system ranking for alignment with human preference. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 4605–4629, 2025
2025
-
[13]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[14]
Mm algorithms for generalized bradley-terry models.The annals of statistics, 32(1):384–406, 2004
David R Hunter. Mm algorithms for generalized bradley-terry models.The annals of statistics, 32(1):384–406, 2004. 10
2004
-
[15]
Chatbot arena: An open platform for evaluating llms by human preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. Chatbot arena: An open platform for evaluating llms by human preference. InInternational Conference on Machine Learning, pages 8359–8388. PMLR, 2024
2024
-
[16]
Cheng-Han Chiang and Hung-yi Lee. Can large language models be an alternative to human evaluations? InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15607–15631, 2023
2023
-
[17]
Mingyuan Xu, Xinzi Tan, Jiawei Wu, and Doudou Zhou. A judge-aware ranking framework for evaluating large language models without ground truth.arXiv preprint arXiv:2601.21817, 2026
-
[18]
Individualized rank aggregation using nuclear norm regular- ization
Yu Lu and Sahand N Negahban. Individualized rank aggregation using nuclear norm regular- ization. In2015 53rd Annual Allerton Conference on Communication, Control, and Computing (Allerton), pages 1473–1479. IEEE, 2015
2015
-
[19]
Preference completion: Large-scale collaborative ranking from pairwise comparisons
Dohyung Park, Joe Neeman, Jin Zhang, Sujay Sanghavi, and Inderjit Dhillon. Preference completion: Large-scale collaborative ranking from pairwise comparisons. InInternational Conference on Machine Learning, pages 1907–1916. PMLR, 2015
1907
-
[20]
When can we rank well from comparisons of o (n\log (n)) non-actively chosen pairs? InConference on Learning Theory, pages 1376–1401
Arun Rajkumar and Shivani Agarwal. When can we rank well from comparisons of o (n\log (n)) non-actively chosen pairs? InConference on Learning Theory, pages 1376–1401. PMLR, 2016
2016
-
[21]
Rank aggregation via heterogeneous thurstone preference models
Tao Jin, Pan Xu, Quanquan Gu, and Farzad Farnoud. Rank aggregation via heterogeneous thurstone preference models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34 (04), pages 4353–4360, 2020
2020
-
[22]
Clustering and inference from pairwise comparisons
Rui Wu, Jiaming Xu, Rayadurgam Srikant, Laurent Massoulié, Marc Lelarge, and Bruce Ha- jek. Clustering and inference from pairwise comparisons. InProceedings of the 2015 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, pages 449–450, 2015
2015
-
[23]
Generalised probabilistic modelling and improved uncer- tainty estimation in comparative llm-as-a-judge
Yassir Fathullah and Mark Gales. Generalised probabilistic modelling and improved uncer- tainty estimation in comparative llm-as-a-judge. InConference on Uncertainty in Artificial Intelligence, pages 1266–1288. PMLR, 2025
2025
-
[24]
Improving LLM-as-a-judge inference with the judgment distribution
Victor Wang, Michael JQ Zhang, and Eunsol Choi. Improving LLM-as-a-judge inference with the judgment distribution. InFindings of the Association for Computational Linguistics: EMNLP 2025, Suzhou, China, November 2025. Association for Computational Linguistics
2025
-
[25]
arXiv preprint arXiv:2509.01847 , year=
Jianqing Fan, Hyukjun Kwon, and Xiaonan Zhu. Uncertainty quantification for ranking with heterogeneous preferences.arXiv preprint arXiv:2509.01847, 2025
-
[26]
Wiley New York, 1959
R Duncan Luce et al.Individual choice behavior, volume 4. Wiley New York, 1959
1959
-
[27]
Hybrid-mst: A hybrid active sampling strategy for pairwise preference aggregation.Advances in neural information processing systems, 31, 2018
Jing Li, Rafal Mantiuk, Junle Wang, Suiyi Ling, and Patrick Le Callet. Hybrid-mst: A hybrid active sampling strategy for pairwise preference aggregation.Advances in neural information processing systems, 31, 2018
2018
-
[28]
ULTRAFEEDBACK: Boosting language models with scaled AI feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guo- tong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, and Maosong Sun. ULTRAFEEDBACK: Boosting language models with scaled AI feedback. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 9722–9744...
2024
-
[29]
American Mathematical Soc., 1997
Fan RK Chung.Spectral graph theory, volume 92. American Mathematical Soc., 1997
1997
-
[30]
Graph theory and probability.Canadian Journal of Mathematics, 11:34–38, 1959
Paul Erdös. Graph theory and probability.Canadian Journal of Mathematics, 11:34–38, 1959
1959
-
[31]
Self and Kung-Yee Liang
Steven G. Self and Kung-Yee Liang. Asymptotic properties of maximum likelihood estimators and likelihood ratio tests under nonstandard conditions.Journal of the American Statistical Association, 82(398):605–610, 1987. 11
1987
-
[32]
Jean-Marc Robin and Richard J. Smith. Tests of rank.Econometric Theory, 16(2):151–175, 2000
2000
-
[33]
Linear convergence of gradient and proximal- gradient methods under the polyak-łojasiewicz condition
Hamed Karimi, Julie Nutini, and Mark Schmidt. Linear convergence of gradient and proximal- gradient methods under the polyak-łojasiewicz condition. InJoint European conference on machine learning and knowledge discovery in databases, pages 795–811. Springer, 2016
2016
-
[34]
Gradient methods for minimizing functionals.Zhurnal vychisli- tel’noi matematiki i matematicheskoi fiziki, 3(4):643–653, 1963
Boris Teodorovich Polyak. Gradient methods for minimizing functionals.Zhurnal vychisli- tel’noi matematiki i matematicheskoi fiziki, 3(4):643–653, 1963
1963
-
[35]
Hédy Attouch, Jérôme Bolte, Patrick Redont, and Antoine Soubeyran. Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the kurdyka-łojasiewicz inequality.Mathematics of operations research, 35(2):438–457, 2010
2010
-
[36]
Statistical inference for pairwise comparison mod- els.arXiv preprint arXiv:2401.08463v3, 2025
Ruijian Han, Wenlu Tang, and Yiming Xu. Statistical inference for pairwise comparison mod- els.arXiv preprint arXiv:2401.08463v3, 2025
-
[37]
A limited memory algorithm for bound constrained optimization.SIAM Journal on scientific computing, 16(5):1190–1208, 1995
Richard H Byrd, Peihuang Lu, Jorge Nocedal, and Ciyou Zhu. A limited memory algorithm for bound constrained optimization.SIAM Journal on scientific computing, 16(5):1190–1208, 1995
1995
-
[38]
o” and “O
John A Hartigan. Direct clustering of a data matrix.Journal of the american statistical asso- ciation, 67(337):123–129, 1972. 12 Appendix This serves as an appendix to the main paper. Below, we provide an outline for the appendix along with a summary of the notation used in the main paper and the appendix. Organization.The content of the appendix is organ...
1972
-
[39]
the sequence{L n(θ(t))}t≥0 is nonincreasing and convergent
-
[40]
Part II: Local sequence convergence.Suppose further that Assumptions A2 and A3 concerning the basin hold
the iterates satisfy P∞ t=0 ∥θ(t+1) −θ (t)∥2 <∞. Part II: Local sequence convergence.Suppose further that Assumptions A2 and A3 concerning the basin hold. Then:
-
[41]
the iterates remain inΘ r,0 and the full anchored sequenceθ (t) converges tobθn
-
[42]
equivalently, before anchoring, the factor pair(U (t), V (t))converges to the equivalence class of( bUn,bVn)up to the column-sign convention, and after re-anchoring the convergence is ordi- nary parameter convergence. Part III: Local linear rate.Following Part II, the convergence is locally linear: there exist constants C >0andρ∈(0,1)such that ∥θ(t) −bθn∥...
-
[43]
establish positive definiteness of the Fisher information in the ambient row-centered score space Svia judge-wise connected active graphs; and
-
[44]
Unstructured BTL + SVD
pull this positivity back to the structured parameter spaceΘ r through the differential of the mapΦ(θ) =S(θ) =γµ ⊤ +U V ⊤. The second step is needed because our inferential target is not the unrestricted score matrixS, but the constrained latent parameterθ= (γ, µ, U, V). We first isolate the local regularity condition needed to pass from score-space nonde...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.