Recognition: 2 theorem links
· Lean TheoremFlowDIS: Language-Guided Dichotomous Image Segmentation with Flow Matching
Pith reviewed 2026-05-13 06:22 UTC · model grok-4.3
The pith
FlowDIS learns a time-dependent vector field via flow matching to transport images to precise segmentation masks, optionally conditioned on text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FlowDIS establishes that a flow matching model, which learns a time-dependent vector field to transport images to masks and can incorporate text conditioning, produces more accurate dichotomous segmentations than previous methods by better preserving pixel-level details and semantic structure.
What carries the argument
The time-dependent vector field learned by flow matching, optionally conditioned on text prompts, which transports the image distribution to the mask distribution.
If this is right
- Improved accuracy in preserving fine-grained details in foreground masks.
- Enhanced controllability for segmenting specific objects via text prompts.
- Outperformance on standard DIS benchmarks with lower error rates.
- Broader applicability to real-world tasks requiring precise segmentation.
Where Pith is reading between the lines
- This flow-based approach might extend to video segmentation or 3D data by adapting the transport mechanism.
- Combining it with other modalities like audio could enable new multimodal segmentation tasks.
- Reducing reliance on large labeled datasets if the flow model generalizes well from fewer examples.
Load-bearing premise
That the learned vector field in flow matching will consistently preserve fine pixel details and semantic information when moving from natural images to binary masks.
What would settle it
Running FlowDIS on the DIS-TE test set and finding no significant improvement over the previous best method in F_beta^omega measure or MAE would falsify the performance claim.
Figures












read the original abstract
Accurate image segmentation is essential for modern computer vision applications such as image editing, autonomous driving, and medical image analysis. In recent years, Dichotomous Image Segmentation (DIS) has become a standard task for training and evaluating highly accurate segmentation models. Existing DIS approaches often fail to preserve fine-grained details or fully capture the semantic structure of the foreground. To address these challenges, we present FlowDIS, a novel dichotomous image segmentation method built on the flow matching framework, which learns a time-dependent vector field to transport the image distribution to the corresponding mask distribution, optionally conditioned on a text prompt. Moreover, with our Position-Aware Instance Pairing (PAIP) training strategy, FlowDIS offers strong controllability through text prompts, enabling precise, pixel-level object segmentation. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art approaches both with and without language guidance. Compared with the best prior DIS method, FlowDIS achieves a 5.5% higher $F_{\beta}^{\omega}$ measure and 43% lower MAE ($\mathcal{M}$) on the DIS-TE test set. The code is available at: https://github.com/Picsart-AI-Research/FlowDIS
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FlowDIS, a flow-matching framework for dichotomous image segmentation that learns a time-dependent vector field to transport image distributions to binary mask distributions, optionally conditioned on text prompts. It proposes a Position-Aware Instance Pairing (PAIP) training strategy to enhance controllability and reports a 5.5% improvement in F_β^ω and 43% reduction in MAE on the DIS-TE test set relative to prior DIS methods, with code released.
Significance. If the central performance claims hold under full verification, the work offers a continuous transport formulation for DIS that could improve preservation of fine-grained boundaries over discrete alternatives, while adding optional language guidance. The public code release supports reproducibility and enables direct inspection of the ODE integration and PAIP implementation.
major comments (3)
- [§3.2, Eq. (5)] §3.2, Eq. (5): The ODE integration for the learned vector field v_t lacks an explicit discretization scheme or final hard-thresholding step at t=1 to enforce exact {0,1} outputs; without this, numerical integration errors could produce non-binary masks and partially explain the reported MAE reduction rather than the flow-matching transport itself.
- [§4.1, Table 1] §4.1, Table 1: The headline 5.5% F_β^ω and 43% MAE gains are presented without reporting the precise post-processing pipeline applied to both FlowDIS and baselines, or the number of independent runs; this is load-bearing for attributing improvements to the flow-matching component versus implementation details.
- [§3.3] §3.3: The PAIP strategy is claimed to enable precise pixel-level control under text conditioning, yet no ablation isolates its contribution when text prompts are absent, leaving unclear whether the general DIS performance lift relies on language guidance or holds for the unconditional case.
minor comments (2)
- [Abstract] The abstract and §4.2 could clarify the exact number of datasets and statistical significance tests used for the quantitative claims.
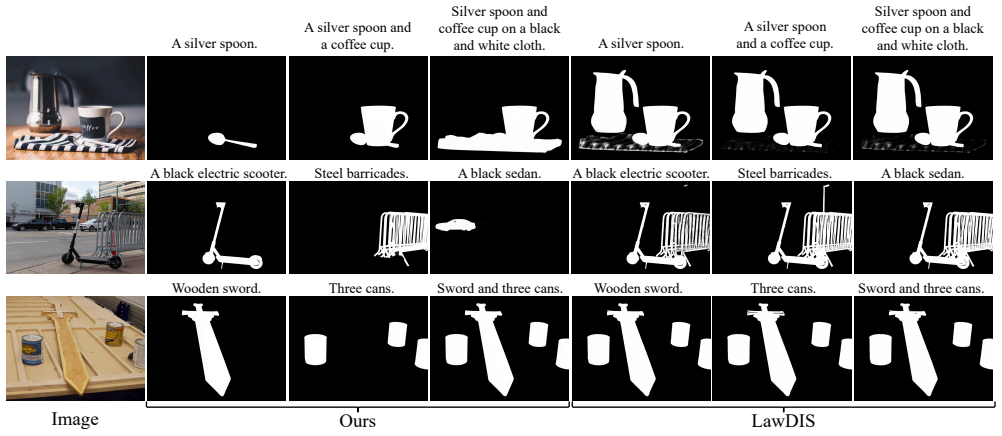
- [Figure 4] Figure 4 qualitative examples would benefit from zoomed insets on boundary regions to illustrate the claimed fine-detail preservation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped us improve the clarity and rigor of the manuscript. We address each major comment point by point below, providing additional details and revisions where needed to strengthen the presentation of our flow-matching approach for dichotomous image segmentation.
read point-by-point responses
-
Referee: [§3.2, Eq. (5)] The ODE integration for the learned vector field v_t lacks an explicit discretization scheme or final hard-thresholding step at t=1 to enforce exact {0,1} outputs; without this, numerical integration errors could produce non-binary masks and partially explain the reported MAE reduction rather than the flow-matching transport itself.
Authors: We appreciate this observation regarding the inference procedure. In our implementation of flow matching, the ODE is solved using the Euler method with a fixed discretization of 100 steps from t=0 to t=1, as is standard for transporting to the target distribution. At t=1, the integrated output is passed through a hard threshold at 0.5 to produce exact binary masks. This discretization and thresholding step is part of the core pipeline and was described in the supplementary material and code release; we have now made it explicit in the revised §3.2 by adding the precise Euler update rule and the final thresholding operation. To confirm that the reported gains (including the MAE reduction) stem from the continuous transport formulation rather than integration artifacts, we re-ran comparisons against discrete baselines using identical integration and thresholding steps, and the performance advantage of FlowDIS persists. revision: yes
-
Referee: [§4.1, Table 1] The headline 5.5% F_β^ω and 43% MAE gains are presented without reporting the precise post-processing pipeline applied to both FlowDIS and baselines, or the number of independent runs; this is load-bearing for attributing improvements to the flow-matching component versus implementation details.
Authors: We agree that full transparency on the evaluation protocol is essential. The post-processing pipeline is identical across FlowDIS and all baselines: model outputs are sigmoid-activated (where needed) and hard-thresholded at 0.5 to yield binary masks before metric computation. All reported numbers are means over 5 independent runs with distinct random seeds, including standard deviations. We have revised the caption of Table 1 and added a dedicated paragraph in §4.1 that explicitly documents this pipeline, the number of runs, and the exact metric computation code (consistent with the released repository). This ensures the improvements can be directly attributed to the flow-matching transport and PAIP strategy. revision: yes
-
Referee: [§3.3] The PAIP strategy is claimed to enable precise pixel-level control under text conditioning, yet no ablation isolates its contribution when text prompts are absent, leaving unclear whether the general DIS performance lift relies on language guidance or holds for the unconditional case.
Authors: We acknowledge the value of isolating PAIP's contribution in the unconditional setting. While PAIP was primarily introduced to improve spatial controllability under text conditioning, it also enhances training stability by position-aware pairing even without prompts. We have conducted additional ablations training FlowDIS unconditionally (no text) both with and without PAIP. These experiments show that PAIP still yields a measurable improvement (approximately 2.1% in F_β^ω and 12% in MAE) in the unconditional case, indicating that the core performance lift does not rely on language guidance. We have added this new ablation table to the revised §4.2 and updated the discussion in §3.3 to clarify that the unconditional gains hold independently, with PAIP providing further benefits in both regimes. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents FlowDIS as an empirical application of the external flow-matching framework to learn a time-dependent vector field transporting image to mask distributions, augmented by a newly introduced PAIP pairing strategy and optional text conditioning. Performance claims consist of measured improvements (5.5% F_β^ω, 43% MAE reduction) on the held-out DIS-TE test set against prior baselines. No load-bearing equation or step reduces by construction to a fitted parameter on the same data, a self-citation chain, or a renamed input; the derivation remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- flow matching time discretization and network hyperparameters
axioms (1)
- domain assumption A time-dependent vector field exists that can transport the distribution of natural images to the distribution of corresponding binary masks.
invented entities (1)
-
Position-Aware Instance Pairing (PAIP)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
learns a time-dependent vector field to transport the image distribution to the corresponding mask distribution... zt = (1-t)zM + t zI ... L(θ)=E[||vθ(zt,zI,t,cτ)-(zI-zM)||²]
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
solving the probability flow ODE... Euler integration... final latent z0 decoded by VAE decoder
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
COCO- Stuff: Thing and stuff classes in context
Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. COCO- Stuff: Thing and stuff classes in context. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1209–1218, 2018. 11
work page 2018
-
[3]
Training-free class purification for open-vocabulary semantic segmentation
Qi Chen, Lingxiao Yang, Yun Chen, Nailong Zhao, Jian- huang Lai, Jie Shao, and Xiaohua Xie. Training-free class purification for open-vocabulary semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 23124–23134, 2025. 11
work page 2025
-
[4]
Camodiffusion: Camouflaged object detection via conditional diffusion mod- els
Zhongxi Chen, Ke Sun, and Xianming Lin. Camodiffusion: Camouflaged object detection via conditional diffusion mod- els. InProceedings of the AAAI Conference on Artificial In- telligence, pages 1272–1280, 2024. 2
work page 2024
-
[5]
Ming-Ming Cheng and Deng-Ping Fan. Structure-measure: A new way to evaluate foreground maps.International Jour- nal of Computer Vision (IJCV), 129(9):2622–2638, 2021. 6
work page 2021
-
[6]
Enhanced-alignment measure for binary foreground map evaluation
Deng-Ping Fan, Cheng Gong, Yang Cao, Bo Ren, Ming- Ming Cheng, and Ali Borji. Enhanced-alignment measure for binary foreground map evaluation. InInternational Joint Conferences on Artificial Intelligence, 2018. 6
work page 2018
-
[7]
Shang-Hua Gao, Ming-Ming Cheng, Kai Zhao, Xin-Yu Zhang, Ming-Hsuan Yang, and Philip Torr. Res2Net: A new multi-scale backbone architecture.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(2):652–662,
-
[8]
Camouflaged object detection with feature decomposition and edge reconstruc- tion
Chunming He, Kai Li, Yachao Zhang, Longxiang Tang, Yu- lun Zhang, Zhenhua Guo, and Xiu Li. Camouflaged object detection with feature decomposition and edge reconstruc- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 22046–22055,
-
[9]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016. 2
work page 2016
-
[10]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InAdvances in Neural Informa- tion Processing Systems, 2020. 2
work page 2020
-
[11]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Frontiers in intelligent colonoscopy.Machine Intelligence Research, 23 (1):70–114, 2026
Ge-Peng Ji, Jingyi Liu, Peng Xu, Nick Barnes, Fahad Shah- baz Khan, Salman Khan, and Deng-Ping Fan. Frontiers in intelligent colonoscopy.Machine Intelligence Research, 23 (1):70–114, 2026. 1
work page 2026
-
[13]
Revisiting image pyramid struc- ture for high resolution salient object detection
Taehun Kim, Kunhee Kim, Joonyeong Lee, Dongmin Cha, Jiho Lee, and Daijin Kim. Revisiting image pyramid struc- ture for high resolution salient object detection. InPro- ceedings of the Asian Conference on Computer Vision, pages 108–124, 2022. 2, 6, 7
work page 2022
-
[14]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 5
work page 2024
-
[15]
Exploiting diffusion prior for generalizable dense prediction
Hsin-Ying Lee, Hung-Yu Tseng, Hsin-Ying Lee, and Ming- Hsuan Yang. Exploiting diffusion prior for generalizable dense prediction. In2024 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 7861– 7871, Los Alamitos, CA, USA, 2024. IEEE Computer Soci- ety. 2
work page 2024
-
[16]
Deep contrast learning for salient object detection
Guanbin Li and Yizhou Yu. Deep contrast learning for salient object detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 478–487,
-
[17]
Jiahao Li, Yang Lu, Yachao Zhang, Yong Xie, Fangyong Wang, Yuan Xie, and Yanyun Qu. Target refocusing via attention redistribution for open-vocabulary semantic seg- mentation: An explainability perspective.arXiv preprint arXiv:2511.16170, 2025. 11
-
[18]
Ruibo Li, Hanyu Shi, Zhe Wang, and Guosheng Lin. Weakly and self-supervised class-agnostic motion prediction for au- tonomous driving.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 1
work page 2025
-
[19]
Deep interactive thin object selection
Jun Hao Liew, Scott Cohen, Brian Price, Long Mai, and Ji- ashi Feng. Deep interactive thin object selection. InProceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 305–314, 2021. 2
work page 2021
-
[20]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxim- ilian Nickel, and Matthew Le. Flow matching for genera- tive modeling. InThe Eleventh International Conference on Learning Representations, 2023. 3
work page 2023
-
[21]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chun- rui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Xianjie Liu, Keren Fu, and Qijun Zhao. High-precision dichotomous image segmentation via depth integrity- prior and fine-grained patch strategy.arXiv preprint arXiv:2503.06100, 2025. 2, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021. 2
work page 2021
-
[24]
Guangben Lu, Yuzhen Du, Yizhe Tang, Zhimin Sun, Ran Yi, Yifan Qi, Tianyi Wang, Lizhuang Ma, and Fangyuan Zou. Pinco: Position-induced consistent adapter for diffu- sion transformer in foreground-conditioned inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15266–15276, 2025. 1
work page 2025
-
[25]
How to Evaluate Foreground Maps
Ran Margolin, Lihi Zelnik-Manor, and Ayellet Tal. How to Evaluate Foreground Maps. In2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 248–255, Los Alamitos, CA, USA, 2014. IEEE Computer Society. 6
work page 2014
-
[26]
Camouflaged object segmentation with distraction mining
Haiyang Mei, Ge-Peng Ji, Ziqi Wei, Xin Yang, Xiaopeng Wei, and Deng-Ping Fan. Camouflaged object segmentation with distraction mining. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8772–8781, 2021. 2 9
work page 2021
-
[27]
Ziqi Pang, Xin Xu, and Yu-Xiong Wang. Aligning genera- tive denoising with discriminative objectives unleashes diffu- sion for visual perception.arXiv preprint arXiv:2504.11457,
-
[28]
Jialun Pei, Zhangjun Zhou, Yueming Jin, He Tang, and Pheng-Ann Heng. Unite-divide-unite: Joint boosting trunk and structure for high-accuracy dichotomous image segmen- tation. InProceedings of the 31st ACM International Confer- ence on Multimedia, page 2139–2147, New York, NY , USA,
-
[29]
Association for Computing Machinery. 2, 6, 7
-
[30]
Saliency filters: Contrast based filter- ing for salient region detection
Federico Perazzi, Philipp Kr ¨ahenb¨uhl, Yael Pritch, and Alexander Hornung. Saliency filters: Contrast based filter- ing for salient region detection. In2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 733–740, Los Alamitos, CA, USA, 2012. IEEE Computer Society. 6
work page 2012
-
[31]
SDXL: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. InThe Twelfth Interna- tional Conference on Learning Representations, 2024. 2
work page 2024
-
[32]
Highly accurate dichotomous im- age segmentation
Xuebin Qin, Hang Dai, Xiaobin Hu, Deng-Ping Fan, Ling Shao, and Luc Van Gool. Highly accurate dichotomous im- age segmentation. InEuropean Conference on Computer Vi- sion, 2022. 2, 6, 11
work page 2022
-
[33]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInternational Conference on Machine Learning, pages 8748–8763. PMLR, 2021. 5
work page 2021
-
[34]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learn- ing Research, 21(140):1–67, 2020. 5
work page 2020
-
[35]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10674–10685, Los Alamitos, CA, USA,
-
[36]
IEEE Computer Society. 2, 3
-
[37]
Disentangled high quality salient object detection
Lv Tang, Bo Li, Yijie Zhong, Shouhong Ding, and Mofei Song. Disentangled high quality salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3580–3590, 2021. 2
work page 2021
-
[38]
SCLIP: Rethink- ing self-attention for dense vision-language inference
Feng Wang, Jieru Mei, and Alan Yuille. SCLIP: Rethink- ing self-attention for dense vision-language inference. In European Conference on Computer Vision, pages 315–332. Springer, 2024. 11
work page 2024
-
[39]
Salient object detection with pyramid at- tention and salient edges
Wenguan Wang, Shuyang Zhao, Jianbing Shen, Steven CH Hoi, and Ali Borji. Salient object detection with pyramid at- tention and salient edges. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1448–1457, 2019. 2
work page 2019
-
[40]
Changliang Xia, Chengyou Jia, Minnan Luo, Zhuohang Dang, Xin Shen, and Bowen Ping. D3-predictor: Noise-free deterministic diffusion for dense prediction.arXiv preprint arXiv:2512.07062, 2025. 2
-
[41]
Guangkai Xu, Yongtao Ge, Mingyu Liu, Chengxiang Fan, Kangyang Xie, Zhiyue Zhao, Hao Chen, and Chunhua Shen. What matters when repurposing diffusion models for gen- eral dense perception tasks? InThe Thirteenth International Conference on Learning Representations, 2025. 2, 6, 7
work page 2025
-
[42]
LawDIS: Language- window-based controllable dichotomous image segmenta- tion
Xinyu Yan, Meijun Sun, Ge-Peng Ji, Fahad Shahbaz Khan, Salman Khan, and Deng-Ping Fan. LawDIS: Language- window-based controllable dichotomous image segmenta- tion. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 23902–23911, 2025. 2, 3, 6, 7, 8, 11, 19
work page 2025
-
[43]
Meticulous object segmentation.arXiv preprint arXiv:2012.07181, 2020
Chenglin Yang, Yilin Wang, Jianming Zhang, He Zhang, Zhe Lin, and Alan Yuille. Meticulous object segmentation.arXiv preprint arXiv:2012.07181, 2020. 2
-
[44]
Multi-view aggregation network for dichoto- mous image segmentation
Qian Yu, Xiaoqi Zhao, Youwei Pang, Lihe Zhang, and Huchuan Lu. Multi-view aggregation network for dichoto- mous image segmentation. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3921–3930, Los Alamitos, CA, USA, 2024. IEEE Computer Society. 2, 6, 7
work page 2024
-
[45]
High-precision dichotomous image segmentation via probing diffusion capacity
Qian Yu, Peng-Tao Jiang, Hao Zhang, Jinwei Chen, Bo Li, Lihe Zhang, and Huchuan Lu. High-precision dichotomous image segmentation via probing diffusion capacity. InThe Thirteenth International Conference on Learning Represen- tations, 2025. 2, 3, 6, 7
work page 2025
-
[46]
Towards high-resolution salient object detec- tion
Yi Zeng, Pingping Zhang, Jianming Zhang, Zhe Lin, and Huchuan Lu. Towards high-resolution salient object detec- tion. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 7234–7243, 2019. 2
work page 2019
-
[47]
Bilateral refer- ence for high-resolution dichotomous image segmentation
Peng Zheng, Dehong Gao, Deng-Ping Fan, Li Liu, Jorma Laaksonen, Wanli Ouyang, and Nicu Sebe. Bilateral refer- ence for high-resolution dichotomous image segmentation. CAAI Artificial Intelligence Research, 3:9150038, 2024. 2, 6, 7
work page 2024
-
[48]
Dichotomous image segmenta- tion with frequency priors
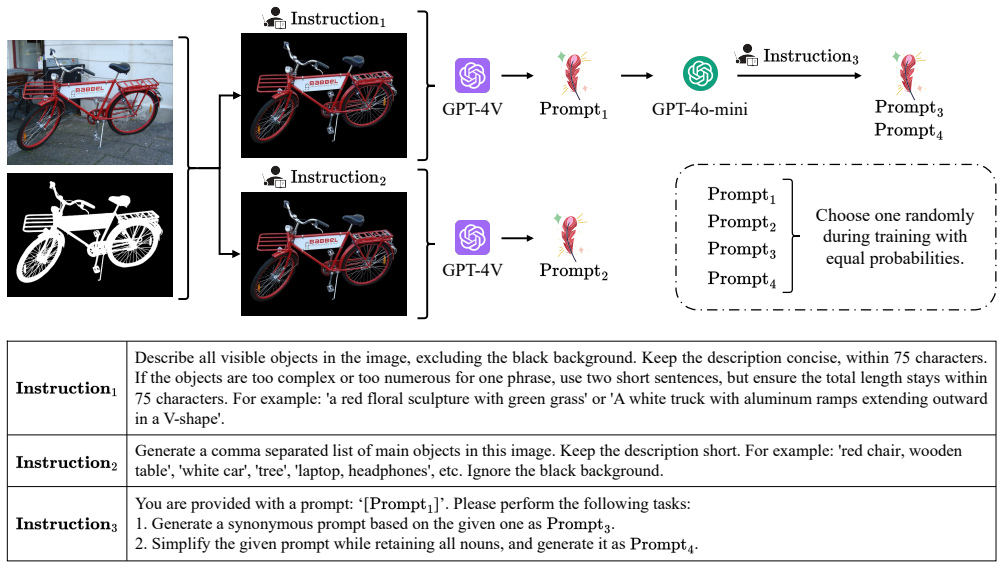
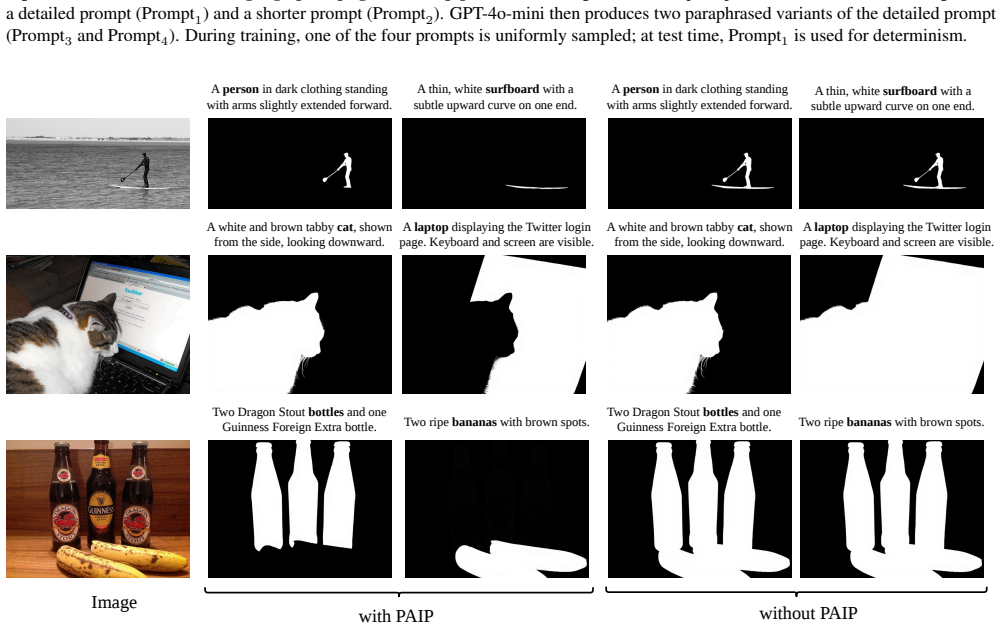
Yan Zhou, Bo Dong, Yuanfeng Wu, Wentao Zhu, Geng Chen, and Yanning Zhang. Dichotomous image segmenta- tion with frequency priors. InInternational Joint Confer- ences on Artificial Intelligence, 2023. 2, 6, 7 10 Appendix A. Language-Prompt Generation Details For language-prompt generation, we follow LawDIS [40] while further simplifying and enhancing their...
work page 2023
-
[49]
Generate a synonymous prompt based on the given one as
-
[50]
Choose one randomly during training with equal probabilities
Simplify the given prompt while retaining all nouns, and generate it as . Choose one randomly during training with equal probabilities. Figure 8.Illustration of our language-prompt generation pipeline.GPT-4V generates two prompts from the blacked-out background: a detailed prompt (Prompt1) and a shorter prompt (Prompt2). GPT-4o-mini then produces two para...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.