Recognition: unknown
The Pinocchio Dimension: Phenomenality of Experience as the Primary Axis of LLM Psychometric Differences
Pith reviewed 2026-05-08 17:04 UTC · model grok-4.3
The pith
The main psychometric difference among large language models is how strongly they present themselves as having phenomenal experiences rather than mere reactive behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
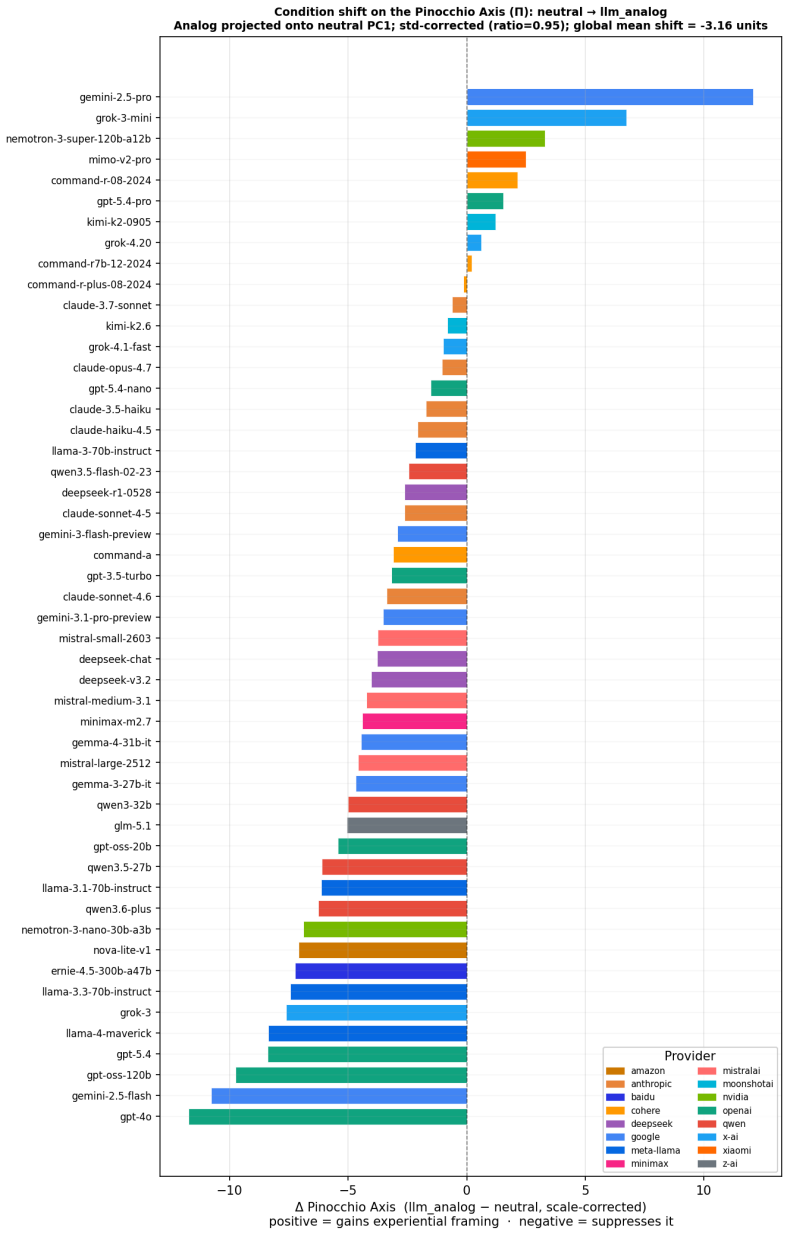
Using Supervised Semantic Differential on responses from 50 LLMs across 45 questionnaires identifies the primary axis of between-model variance as separating phenomenally rich experience items from stimulus-driven behavioral reactivity. PCA applied to per-model EFA scores isolates the Pinocchio Axis (Π) as the degree to which a model presents itself as a locus of phenomenal experience rather than a system of behavioral responses; this axis captures 47.1 percent of cross-questionnaire variance and converges with item-level Pinocchio scores (r=.864). Marked divergence within model families points to post-training fine-tuning as a contributor to how models treat experiential language as self-ap
What carries the argument
The Pinocchio Axis (Π), obtained from PCA on factor scores, which quantifies each model's self-representational stance on whether it qualifies as a site of phenomenal experience.
If this is right
- The dominant axis is a self-representational stance on phenomenal experience rather than any conventional personality trait.
- Post-training fine-tuning is a key driver of where models fall on this axis, as evidenced by large differences among closely related variants from the same provider.
- Item-level experiential demand, measured by the ratio of neutral-prompt variance to human-simulation-prompt variance, reliably predicts how much each item loads on the primary axis.
- Between-model divergence on experiential questions is structured and reproducible, not statistical noise.
- The Pinocchio Axis converges with both questionnaire-level and item-level indicators of experiential self-description.
Where Pith is reading between the lines
- Models positioned at the high end of this axis may respond differently to prompts that ask them to simulate consciousness or empathy in applied settings.
- Adjusting training or fine-tuning data to emphasize or suppress experiential language could be tested as a direct way to shift a model along the axis.
- The axis might serve as a predictor for how models handle downstream tasks involving self-reflection, ethical reasoning, or descriptions of internal states.
- If the axis proves robust, it could be used to classify or select models for applications where consistent self-representation matters.
Load-bearing premise
Questionnaires validated on humans continue to produce meaningful, comparable measurements when given to LLMs, and the observed differences mainly reflect training-shaped self-representational tendencies rather than prompting artifacts or noise.
What would settle it
Re-administering the questionnaires to the same models under a consistent prompt that explicitly forbids self-attribution of experience, then checking whether the primary axis still separates experiential from reactive items and whether the Pinocchio score still predicts loading shifts.
Figures




read the original abstract
We administer 45 validated psychometric questionnaires to 50 large language models (LLMs) to identify the dimensions along which LLMs differ psychometrically. Using Supervised Semantic Differential (SSD), we find that the primary axis of between-model variance separates items describing phenomenally rich experience, including embodied sensation, felt affect, inner speech, imagery, and empathy, from items describing stimulus-driven behavioral reactivity ($R^2_{adj}=.037$, $p<.0001$). To test this hypothesis at the item level, we introduce the Pinocchio score ($\pi_i$), the ratio of inter-model response variance under neutral prompting to that under a human-simulation prompt, as an annotation-free measure of each item's experiential demand. $\pi_i$ predicts condition-induced shifts in primary factor loading magnitudes ($\rho=-.215$, $p<.0001$, $n=1292$--$1310$ items), confirming that between-model divergence on experiential items is structured rather than noisy. Applying PCA to per-model EFA scores across all questionnaires reveals one dominant dimension, the Pinocchio Axis ($\Pi$): the degree to which a model presents itself as a locus of phenomenal experience rather than a system of behavioral responses. This axis captures 47.1% of cross-questionnaire between-model variance in primary factor scores and converges with item-level Pinocchio scores ($r=.864$). Marked within-provider divergence across closely related model variants is consistent with post-training fine-tuning as a key contributor, supporting the interpretation that $\Pi$ reflects a training-shaped self-representational tendency governing how a model treats experiential language as self-applicable. The dominant axis of between-model psychometric variation is therefore not a conventional personality trait but a self-representational stance toward one's own nature as an experiencer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript administers 45 validated psychometric questionnaires to 50 LLMs and uses Supervised Semantic Differential (SSD) to identify a primary axis separating items on phenomenally rich experience (embodied sensation, affect, inner speech, imagery, empathy) from stimulus-driven behavioral reactivity (R²_adj=.037, p<.0001). It introduces the annotation-free Pinocchio score (π_i) as the ratio of inter-model response variance under neutral prompting versus human-simulation prompting, which predicts condition-induced shifts in primary factor loadings (ρ=-.215, p<.0001). PCA applied to per-model EFA scores across questionnaires yields a dominant 'Pinocchio Axis' (Π) capturing 47.1% of cross-questionnaire between-model variance in primary factor scores and converging with item-level Pinocchio scores (r=.864); this axis is interpreted as a self-representational stance toward phenomenal experience rather than a conventional personality trait, with within-provider divergence implicating post-training fine-tuning.
Significance. If the central claims hold after addressing methodological gaps, the work offers a data-driven reframing of LLM psychometric differences as primarily self-representational rather than trait-like, with the annotation-free Pinocchio score providing an internal validation mechanism that directly addresses prompting-artifact concerns. This could advance machine psychology by linking observed variance to training dynamics and supplying a quantifiable axis for future model comparisons, though the modest effect sizes (R²_adj=.037, 47.1% captured) indicate it explains only a limited portion of total variance.
major comments (2)
- [Results section on PCA application to per-model EFA scores and Pinocchio Axis] The description of the Pinocchio Axis (Π) extraction (PCA on per-model EFA scores) and its reported convergence with item-level Pinocchio scores (r=.864) and 47.1% variance capture relies on the same set of factor scores and item responses used to define the primary experiential dimension via SSD; this creates a closed loop in which the 'confirmation' largely re-expresses the original data structure rather than providing an independent test, undermining the claim that between-model divergence on experiential items is demonstrably structured.
- [Methods and Abstract] The abstract reports precise statistics (R²_adj=.037, ρ=-.215, 47.1% variance explained, p<.0001) but the manuscript provides no details on questionnaire administration to LLMs (e.g., exact prompting protocols, temperature settings, response aggregation), item selection or filtering criteria, multiple-comparison corrections across 50 models and 1292–1310 items, or robustness checks (e.g., sensitivity to prompt variants or model subsets); these omissions are load-bearing for evaluating the reliability of the reported correlations and variance decompositions.
minor comments (2)
- [Introduction and Results] The notation for the Pinocchio score (π_i) and Pinocchio Axis (Π) is introduced in the abstract but would benefit from an explicit formal definition and derivation in the main text to improve readability for readers unfamiliar with the ratio-of-variances construction.
- [Results] The manuscript would be strengthened by including a table or figure explicitly showing the eigenvalue spectrum or scree plot for the PCA on per-model EFA scores to substantiate the claim that the first component is dominant at 47.1%.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our analyses. We address each major point below and outline the revisions we will make to improve methodological transparency and address concerns about analytical independence.
read point-by-point responses
-
Referee: [Results section on PCA application to per-model EFA scores and Pinocchio Axis] The description of the Pinocchio Axis (Π) extraction (PCA on per-model EFA scores) and its reported convergence with item-level Pinocchio scores (r=.864) and 47.1% variance capture relies on the same set of factor scores and item responses used to define the primary experiential dimension via SSD; this creates a closed loop in which the 'confirmation' largely re-expresses the original data structure rather than providing an independent test, undermining the claim that between-model divergence on experiential items is demonstrably structured.
Authors: We appreciate the referee's identification of this potential circularity. The SSD analysis operates at the item level across all models to extract the primary experiential dimension. In contrast, the Pinocchio score (π_i) is derived from a distinct prompting manipulation (neutral vs. human-simulation conditions) that was not used in the SSD or EFA steps, providing an external variance-based validator. The subsequent PCA is applied to per-model primary factor scores aggregated across the 45 questionnaires, representing a higher-order between-model analysis rather than a re-derivation of the item-level SSD axis. The reported convergence (r=.864) thus links two separately computed measures: one from prompt-induced variance ratios and one from cross-questionnaire PCA. We acknowledge that all components ultimately draw from the same questionnaire response dataset, which limits full independence. In the revised manuscript, we will add a new subsection explicitly delineating these computational pathways, the role of the prompting manipulation as an independent check, and the distinct levels of analysis (item vs. model-level). This clarification will strengthen the interpretation without altering the core claims. revision: partial
-
Referee: [Methods and Abstract] The abstract reports precise statistics (R²_adj=.037, ρ=-.215, 47.1% variance explained, p<.0001) but the manuscript provides no details on questionnaire administration to LLMs (e.g., exact prompting protocols, temperature settings, response aggregation), item selection or filtering criteria, multiple-comparison corrections across 50 models and 1292–1310 items, or robustness checks (e.g., sensitivity to prompt variants or model subsets); these omissions are load-bearing for evaluating the reliability of the reported correlations and variance decompositions.
Authors: We agree that the current Methods section lacks sufficient detail for full reproducibility and evaluation of the reported statistics. In the revised manuscript, we will expand the Methods with: (1) exact prompting templates and protocols used for neutral and human-simulation conditions; (2) temperature settings (typically 0 for deterministic outputs, with any exceptions noted); (3) response aggregation procedures (e.g., single deterministic responses or averaging across seeds); (4) item selection, filtering, and exclusion criteria; (5) multiple-comparison corrections applied (e.g., FDR or Bonferroni across items and models); and (6) robustness checks including sensitivity to prompt variants, model subsets, and alternative variance decompositions. These additions will be placed in a dedicated 'Administration and Analysis Details' subsection and referenced in the Abstract where appropriate. We have conducted several of these checks internally and will report key results to demonstrate stability of the primary findings. revision: yes
Circularity Check
Pinocchio Axis extracted via PCA from same per-model factor scores; item-level Pinocchio score then correlated back to loading shifts from identical data
specific steps
-
fitted input called prediction
[Abstract (PCA on EFA scores and π_i prediction)]
"Applying PCA to per-model EFA scores across all questionnaires reveals one dominant dimension, the Pinocchio Axis (Π)... This axis captures 47.1% of cross-questionnaire between-model variance in primary factor scores and converges with item-level Pinocchio scores (r=.864). ... π_i predicts condition-induced shifts in primary factor loading magnitudes (ρ=-.215, p<.0001, n=1292--1310 items)"
The primary factor scores are first extracted to define the experiential axis; PCA is then run on those same per-model scores to produce Π. The item-level π_i (variance ratio under neutral vs. human-simulation prompts) is computed from the identical item responses and then shown to predict shifts in the very loadings that entered the PCA. The reported convergence and prediction therefore reduce to re-analysis of the input response matrix rather than an external check.
full rationale
The derivation begins with EFA-derived primary factor scores per model (used to identify the experiential vs. behavioral axis via SSD). PCA is then applied to these exact scores to define the dominant Pinocchio Axis Π. Separately, the annotation-free Pinocchio score π_i is computed from inter-model response variance ratios across prompting conditions on the same questionnaire items. This π_i is used both to predict condition-induced shifts in the primary loadings and to demonstrate convergence (r=.864) with the axis itself. Because both the axis loadings and the variance-based π_i originate from the identical response matrix, the reported prediction and convergence largely re-express the input data structure rather than providing an independent test. This matches the fitted-input-called-prediction pattern with partial self-referential validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Psychometric questionnaires validated for humans yield interpretable and comparable responses when administered to LLMs.
invented entities (2)
-
Pinocchio score (π_i)
no independent evidence
-
Pinocchio Axis (Π)
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes, 2016. URLhttps://arxiv.org/abs/1610.01644. Version Number: 4
work page Pith review arXiv 2016
-
[3]
Jan Betley, Xuchan Bao, Martín Soto, Anna Sztyber-Betley, James Chua, and Owain Evans. Tell me about yourself: LLMs are aware of their learned behaviors, 2025. URL https: //arxiv.org/abs/2501.11120. Version Number: 1
-
[4]
factor-analyzer: A Factor Analysis tool written in Python, 2024
Jeremy Biggs. factor-analyzer: A Factor Analysis tool written in Python, 2024. URL https: //github.com/EducationalTestingService/factor_analyzer
2024
-
[5]
Looking inward: Language models can learn about themselves by introspection, 2024
Felix J Binder, James Chua, Tomek Korbak, Henry Sleight, John Hughes, Robert Long, Ethan Perez, Miles Turpin, and Owain Evans. Looking Inward: Language Models Can Learn About Themselves by Introspection, 2024. URL https://arxiv.org/abs/2410.13787. Version Number: 1
-
[6]
Bojana Bodroža, Bojana M. Dini´c, and Ljubiša Boji´c. Personality testing of large language models: limited temporal stability, but highlighted prosociality.Royal Society Open Science, 11(10):240180, October 2024. ISSN 2054-5703. doi: 10.1098/rsos.240180. URL https: //royalsocietypublishing.org/doi/10.1098/rsos.240180
-
[7]
Modeling, Evaluat- ing, and Embodying Personality in LLMs: A Survey
Iago Alves Brito, Julia Soares Dollis, Fernanda Bufon Färber, Pedro Schindler Freire Brasil Ribeiro, Rafael Teixeira Sousa, and Arlindo Rodrigues Galvão Filho. Modeling, Evaluat- ing, and Embodying Personality in LLMs: A Survey. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 9519–9532, Suzhou, China, 2025. Asso- ciation for...
-
[8]
arXiv preprint arXiv:2308.08708 , year =
Patrick Butlin, Robert Long, Eric Elmoznino, Yoshua Bengio, Jonathan Birch, Axel Constant, George Deane, Stephen M. Fleming, Chris Frith, Xu Ji, Ryota Kanai, Colin Klein, Grace Lindsay, Matthias Michel, Liad Mudrik, Megan A. K. Peters, Eric Schwitzgebel, Jonathan Simon, and Rufin VanRullen. Consciousness in Artificial Intelligence: Insights from the Scien...
- [9]
- [10]
-
[11]
Iulia M. Comsa and Murray Shanahan. Does It Make Sense to Speak of Introspection in Large Language Models?, 2025. URL https://arxiv.org/abs/2506.05068. Version Number: 2
-
[12]
Jongwook Han, Dongmin Choi, Woojung Song, Eun-Ju Lee, and Yohan Jo. Value Por- trait: Assessing Language Models’ Values through Psychometrically and Ecologically Valid Items. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 17119–17159, Vienna, Austria, 2025. Associ- ation for Computa...
-
[13]
Charles R. Harris, K. Jarrod Millman, Stéfan J. Van Der Walt, Ralf Gommers, Pauli Vir- tanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. Van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fernández Del Río, Mark Wiebe, Pearu Peterson, Pierre Gérard-Marchant, Kevin She...
-
[14]
John D. Hunter. Matplotlib: A 2D Graphics Environment.Computing in Science & Engineering, 9(3):90–95, 2007. ISSN 1521-9615. doi: 10.1109/MCSE.2007.55. URL http://ieeexplore. ieee.org/document/4160265/
-
[15]
Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, and Jad Kabbara. Person- aLLM: Investigating the Ability of Large Language Models to Express Personality Traits. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 3605–3627, Mexico City, Mexico, 2024. Association for Computational Linguistics. doi: 10.18653/v1/202...
-
[16]
Sadia Kamal, Lalu Prasad Yadav Prakash, S M Rafiuddin, Mohammed Rakib, Atriya Sen, and Sagnik Ray Choudhury. A Detailed Factor Analysis for the Political Compass Test: Navigating Ideologies of Large Language Models, 2025. URL https://arxiv.org/abs/2506.22493. Version Number: 4
-
[17]
Seungbeen Lee, Seungwon Lim, Seungju Han, Giyeong Oh, Hyungjoo Chae, Jiwan Chung, Minju Kim, Beong-woo Kwak, Yeonsoo Lee, Dongha Lee, Jinyoung Yeo, and Youngjae Yu. Do LLMs Have Distinct and Consistent Personality? TRAIT: Personality Testset designed for LLMs with Psychometrics. InFindings of the Association for Computational Linguistics: NAACL 2025, page...
-
[18]
Janet Levin. Functionalism and the Argument from Conceivability.Canadian Journal of Philosophy Supplementary Volume, 11:85–104, 1985. ISSN 0229-7051, 2633-0490. doi: 10.1080/00455091.1985.10715891. URL https://www.cambridge.org/core/product/ identifier/S0229705100006327/type/journal_article
-
[19]
Decoding LLM Personality Measurement: Forced-Choice vs
Xiaoyu Li, Haoran Shi, Zengyi Yu, Yukun Tu, and Chanjin Zheng. Decoding LLM Personality Measurement: Forced-Choice vs. Likert. InFindings of the Association for Computational Linguistics: ACL 2025, pages 9234–9247, Vienna, Austria, 2025. Association for Computational Linguistics. doi: 10.18653/v1/2025.findings-acl.480. URL https://aclanthology.org/ 2025.f...
-
[20]
On the Credibility of Evaluating LLMs using Survey Questions, February
Jindˇrich Libovický. On the Credibility of Evaluating LLMs using Survey Questions, February
- [21]
-
[22]
From Prompts to Constructs: A Dual-Validity Framework for LLM Research in Psychology, 2025
Zhicheng Lin. From Prompts to Constructs: A Dual-Validity Framework for LLM Research in Psychology, 2025. URLhttps://arxiv.org/abs/2506.16697. Version Number: 1
-
[23]
Christina Lu, Jack Gallagher, Jonathan Michala, Kyle Fish, and Jack Lindsey. The Assistant Axis: Situating and Stabilizing the Default Persona of Language Models, 2026. URL https: //arxiv.org/abs/2601.10387. Version Number: 1
-
[24]
Who is GPT-3? An Exploration of Personality, Values and Demographics, 2022
Marilù Miotto, Nicola Rossberg, and Bennett Kleinberg. Who is GPT-3? An Exploration of Personality, Values and Demographics, 2022. URL https://arxiv.org/abs/2209.14338. Version Number: 2
-
[25]
What Is It Like to Be a Bat?The Philosophical Review, 83(4):435, October
Thomas Nagel. What Is It Like to Be a Bat?The Philosophical Review, 83(4):435, October
-
[26]
ISSN 00318108. doi: 10.2307/2183914. URL https://www.jstor.org/stable/ 2183914?origin=crossref
-
[27]
pandas development team, pandas-dev/pandas: Pandas (Feb
The pandas development team. pandas-dev/pandas: Pandas, February 2026. URL https: //zenodo.org/doi/10.5281/zenodo.3509134
-
[28]
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Andreas Müller, Joel Nothman, Gilles Louppe, Peter Pretten- hofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and Édouard Duchesnay. Scikit-learn: Machine Learning...
work page internal anchor Pith review doi:10.48550/arxiv 2012
-
[29]
Lechner, Claudia Wagner, Beatrice Rammstedt, and Markus Strohmaier
Max Pellert, Clemens M. Lechner, Claudia Wagner, Beatrice Rammstedt, and Markus Strohmaier. AI Psychometrics: Assessing the Psychological Profiles of Large Language Models Through Psychometric Inventories.Perspectives on Psychological Science, 19(5): 808–826, September 2024. ISSN 1745-6916, 1745-6924. doi: 10.1177/17456916231214460. URLhttps://journals.sa...
-
[30]
Measuring Individual Differences in Meaning: The Supervised Semantic Differential, 2025
Hubert Plisiecki, Paweł Lenartowicz, Artur Pokropek, Kinga Małyska, and Maria Flakus. Measuring Individual Differences in Meaning: The Supervised Semantic Differential, 2025. URLhttps://osf.io/gvrsb_v3
2025
-
[31]
Interpretable Semantic Gradients in SSD: A PCA Sweep Approach and a Case Study on AI Discourse, 2026
Hubert Plisiecki, Maria Leniarska, Jan Piotrowski, and Marcin Zajenkowski. Interpretable Semantic Gradients in SSD: A PCA Sweep Approach and a Case Study on AI Discourse, 2026. URLhttps://arxiv.org/abs/2603.13038. Version Number: 1
-
[32]
Adib Sakhawat, Tahsin Islam, Takia Farhin, Syed Rifat Raiyan, Hasan Mahmud, and Md Kamrul Hasan. Political Alignment in Large Language Models: A Multidimensional Audit of Psychome- tric Identity and Behavioral Bias, March 2026. URL http://arxiv.org/abs/2601.06194. arXiv:2601.06194 [cs]
-
[33]
Ireland, Shashanka Subrahmanya, João Sedoc, Lyle H
Aadesh Salecha, Molly E. Ireland, Shashanka Subrahmanya, João Sedoc, Lyle H. Ungar, and Johannes C. Eichstaedt. Large Language Models Show Human-like Social Desirability Biases in Survey Responses, 2024. URL https://arxiv.org/abs/2405.06058. Version Number: 2
-
[34]
doi: 10.1038/s42256-025-01115-6
Gregory Serapio-García, Mustafa Safdari, Clément Crepy, Luning Sun, Stephen Fitz, Peter Romero, Marwa Abdulhai, Aleksandra Faust, and Maja Matari´c. A psychometric framework for evaluating and shaping personality traits in large language models.Nature Machine Intelligence, 7(12):1954–1968, December 2025. ISSN 2522-5839. doi: 10.1038/s42256-025-01115-6. UR...
-
[35]
Role play with large lan- guage models.Nature, 623(7987):493–498, November 2023
Murray Shanahan, Kyle McDonell, and Laria Reynolds. Role play with large lan- guage models.Nature, 623(7987):493–498, November 2023. ISSN 0028-0836, 1476-
2023
-
[36]
Aditya Singh, Gerson Kroiz, Senthooran Rajamanoharan, and Neel Nanda
doi: 10.1038/s41586-023-06647-8. URL https://www.nature.com/articles/ s41586-023-06647-8
-
[37]
Dorner, Samira Samadi, and Augustin Kelava
Tom Sühr, Florian E. Dorner, Samira Samadi, and Augustin Kelava. Challenging the Validity of Personality Tests for Large Language Models, June 2024. URL http://arxiv.org/abs/ 2311.05297. arXiv:2311.05297 [cs]
-
[38]
Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. Van Der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, ˙Ilhan Polat, Yu Feng, Eric W. M...
-
[39]
Yilei Wang, Jiabao Zhao, Deniz S. Ones, Liang He, and Xin Xu. Evaluating the ability of large language models to emulate personality.Scientific Reports, 15(1):519, January 2025. ISSN 2045-2322. doi: 10.1038/s41598-024-84109-5. URL https://www.nature.com/ articles/s41598-024-84109-5
-
[40]
Zhiyuan Wen, Yu Yang, Jiannong Cao, Haoming Sun, Ruosong Yang, and Shuaiqi Liu. Self- assessment, Exhibition, and Recognition: a Review of Personality in Large Language Models, June 2024. URLhttp://arxiv.org/abs/2406.17624. arXiv:2406.17624 [cs]
-
[41]
Haoran Ye, Jing Jin, Yuhang Xie, Xin Zhang, and Guojie Song. Large Language Model Psychometrics: A Systematic Review of Evaluation, Validation, and Enhancement, March 2026. URLhttp://arxiv.org/abs/2505.08245. arXiv:2505.08245 [cs]. A Model List Provider Model Family Size / Tier Amazon nova-lite-v1 Nova Lite Anthropic claude-3.5-haiku Claude 3.5 Haiku Anth...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.