Recognition: unknown
CapsID: Soft-Routed Variable-Length Semantic IDs for Generative Recommendation
Pith reviewed 2026-05-08 15:51 UTC · model grok-4.3
The pith
Soft capsule routing in CapsID produces variable-length semantic IDs that raise recall while cutting inference cost in generative recommendation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Replacing hard nearest-neighbor residual quantization with capsule routing, in which each item layer routes probabilistically to multiple semantic capsules, updates the residual with the routed reconstruction, and terminates once capsule confidence is high enough, produces semantic IDs that preserve multi-faceted item semantics without auxiliary dense representations.
What carries the argument
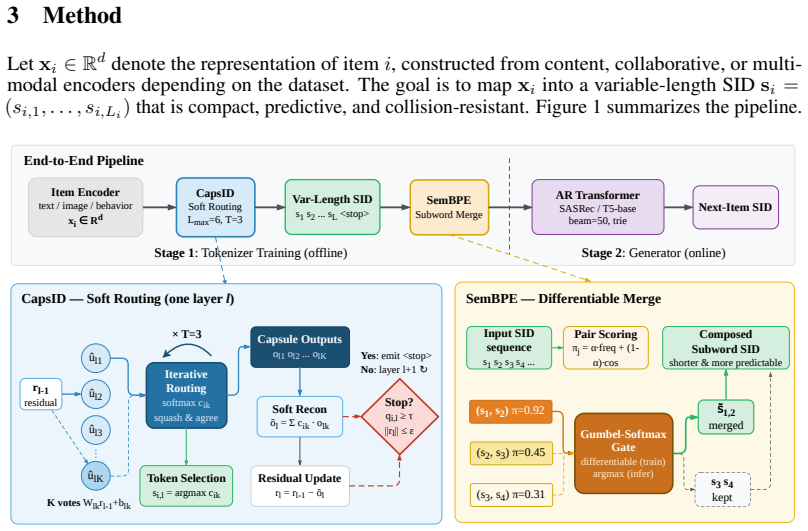
Capsule routing for semantic ID generation: at each quantization layer an item is softly assigned to several capsules, the residual is updated by their weighted reconstruction, and the sequence length is set by a confidence threshold.
Load-bearing premise
Soft routing via capsules and confidence-driven length termination resolve the multi-faceted semantics and error propagation issues of hard residual quantization without introducing new biases or requiring extensive hyperparameter tuning.
What would settle it
An experiment that applies CapsID to the same Amazon and industrial benchmarks but removes the soft-routing component and observes Recall@10 fall back to the hard-quantization baseline level would falsify the central claim.
Figures


read the original abstract
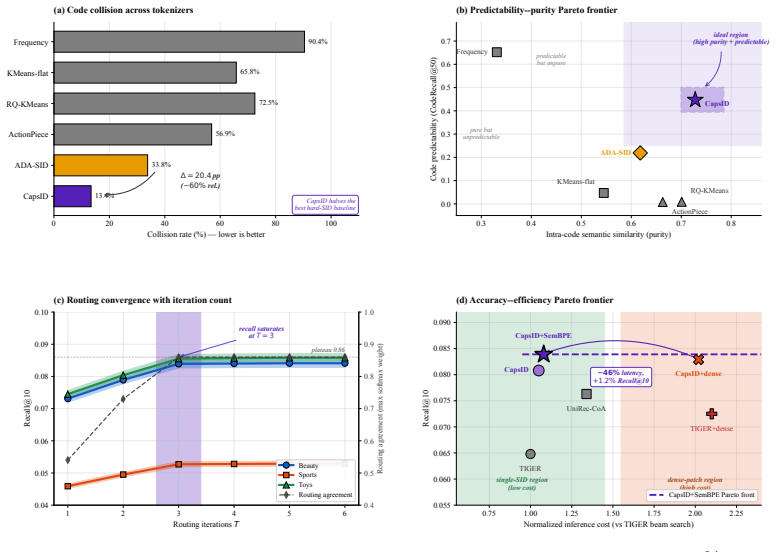
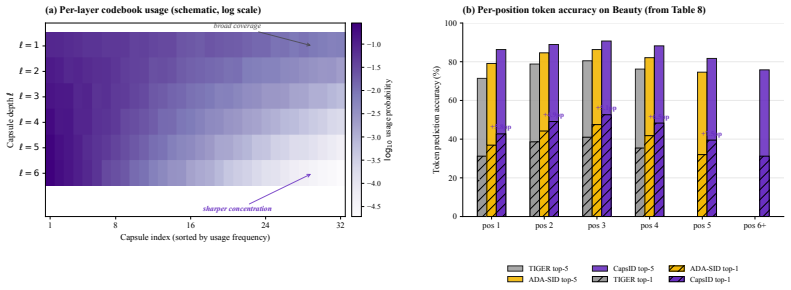
Generative recommendation maps each item to a sequence of Semantic IDs (SIDs) and recasts retrieval as autoregressive token generation. In this paradigm the main bottleneck is the tokenizer rather than the Transformer: residual vector quantization with a hard nearest-neighbor assignment at every layer collapses multi-faceted item semantics at cluster boundaries and propagates early errors to later SID positions. A common workaround is to append a dense vector or attribute prefix to the SID, but this dual-representation design inflates inference cost and gives up the simplicity of a generative interface. We address the bottleneck at the tokenizer itself. CAPSID replaces hard residual quantization with capsule routing: at each layer an item probabilistically routes to several semantic capsules, the residual is updated by the routed reconstruction rather than by a single winning code, and the SID terminates once the active capsule's confidence is high enough. On top of CAPSID, SEMANTICBPE composes adjacent SID tokens into reusable subwords by combining their co-occurrence with their embedding compatibility. On Amazon Beauty, Sports, Toys, and a 35M-item proprietary industrial catalog, CAPSID+SEMANTICBPE improves Recall at 10 by 9.6% on average over ReSID, the strongest single-representation baseline, and matches or exceeds a COBRA-style sparse-dense system on every public benchmark while running at 51% of its inference latency. Ablations show that soft routing, iterative agreement, and confidence-driven length each contribute independently, and the gains are largest on tail items where boundary semantics dominate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CapsID, which replaces hard residual vector quantization in semantic ID tokenization for generative recommendation with soft capsule routing: items are probabilistically assigned to multiple semantic capsules per layer, residuals are updated via routed reconstructions, and SID length terminates based on capsule confidence. It adds SemanticBPE to compose adjacent tokens into subwords using co-occurrence and embedding compatibility. On Amazon Beauty/Sports/Toys and a 35M-item industrial catalog, CapsID+SemanticBPE reports 9.6% average Recall@10 gains over ReSID (strongest single-representation baseline), matches or exceeds COBRA-style sparse-dense systems at 51% latency, with ablations claiming independent contributions from soft routing, iterative agreement, and confidence-driven termination (largest gains on tail items).
Significance. If the empirical results and ablations hold, the work offers a targeted improvement to the core tokenizer bottleneck in generative recommenders, enabling better handling of multi-faceted semantics and reduced error propagation without hybrid representations or added inference cost. The efficiency gains and tail-item focus are practically relevant; the ablations isolating mechanism contributions provide a useful strength for validating the design choices.
minor comments (2)
- [Abstract] The abstract and experimental sections should report the number of runs, standard deviations, or error bars for the Recall@10 figures (including the 9.6% average) to allow assessment of statistical reliability.
- Provide additional implementation details or pseudocode for SemanticBPE's composition rule (co-occurrence combined with embedding compatibility) to ensure reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary of CapsID, the recognition of its targeted improvement to the semantic ID tokenizer, and the recommendation for minor revision. We will incorporate clarifications and any minor adjustments to improve readability and completeness.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces CapsID as a capsule-routing replacement for hard residual quantization in semantic ID tokenization, followed by SemanticBPE for subword composition. All load-bearing claims (Recall@10 gains, latency reductions, ablation contributions) are tied to experimental comparisons against external baselines (ReSID, COBRA-style systems) and internal ablations on public and proprietary datasets. No equations or steps reduce by construction to fitted parameters renamed as predictions, no uniqueness theorems are imported from self-citations, and the method description does not define outputs in terms of themselves. The central argument remains an empirical proposal validated outside its own fitted values.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of semantic capsules
- confidence threshold for SID termination
axioms (1)
- domain assumption Item semantics are multi-faceted and can be probabilistically assigned to multiple capsules without loss of information
invented entities (2)
-
semantic capsules
no independent evidence
-
SEMANTICBPE
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shiteng Cao, Junda She, Ji Liu, Bin Zeng, Chengcheng Guo, Kuo Cai, Qiang Luo, Ruiming Tang, Han Li, Kun Gai, et al. Glass: A generative recommender for long-sequence modeling via sid-tier and semantic search.arXiv preprint arXiv:2602.05663, 2026
-
[2]
Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
2013
-
[3]
Autoregressive entity retrieval.arXiv preprint arXiv:2010.00904, 2020
Nicola De Cao, Gautier Izacard, Sebastian Riedel, and Fabio Petroni. Autoregressive entity retrieval.arXiv preprint arXiv:2010.00904, 2020
-
[4]
OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
Differentiable Semantic ID for Generative Recommendation
Junchen Fu, Xuri Ge, Alexandros Karatzoglou, Ioannis Arapakis, Suzan Verberne, Joemon M Jose, and Zhaochun Ren. Differentiable semantic id for generative recommendation.arXiv preprint arXiv:2601.19711, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Hinton, Sara Sabour, and Nicholas Frosst
Geoffrey E. Hinton, Sara Sabour, and Nicholas Frosst. Matrix capsules with em rout- ing. InInternational Conference on Learning Representations, 2018. URL https://api. semanticscholar.org/CorpusID:65203110
2018
-
[7]
Learning vector-quantized item representation for transferable sequential recommenders
Yupeng Hou, Zhankui He, Julian McAuley, and Wayne Xin Zhao. Learning vector-quantized item representation for transferable sequential recommenders. InProceedings of the ACM Web Conference 2023, pages 1162–1171, 2023
2023
-
[8]
Actionpiece: Contextually tokeniz- ing action sequences for generative recommendation,
Yupeng Hou, Jianmo Ni, Zhankui He, Noveen Sachdeva, Wang-Cheng Kang, Ed H Chi, Julian McAuley, and Derek Zhiyuan Cheng. Actionpiece: Contextually tokenizing action sequences for generative recommendation.arXiv preprint arXiv:2502.13581, 2025
-
[9]
Zheng Hu, Yuxin Chen, Yongsen Pan, Xu Yuan, Yuting Yin, Daoyuan Wang, Boyang Xia, Zefei Luo, Hongyang Wang, Songhao Ni, et al. Stop treating collisions equally: Qualification-aware semantic id learning for recommendation at industrial scale.arXiv preprint arXiv:2603.00632, 2026
-
[10]
Categorical Reparameterization with Gumbel-Softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144, 2016
work page internal anchor Pith review arXiv 2016
-
[11]
Generative recommendation with semantic ids: A practitioner’s handbook
Clark Mingxuan Ju, Liam Collins, Leonardo Neves, Bhuvesh Kumar, Louis Yufeng Wang, Tong Zhao, and Neil Shah. Generative recommendation with semantic ids: A practitioner’s handbook. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 6420–6425, 2025
2025
-
[12]
Self-attentive sequential recommendation.2018 IEEE International Conference on Data Mining (ICDM), pages 197–206, 2018
Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommendation.2018 IEEE International Conference on Data Mining (ICDM), pages 197–206, 2018. URL https: //api.semanticscholar.org/CorpusID:52127932
2018
-
[13]
Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing
Taku Kudo and John Richardson. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. InProceedings of the 2018 conference on empirical methods in natural language processing: System demonstrations, pages 66–71, 2018
2018
-
[14]
Li, Zhiyuan Liu, Mengmeng Wu, Yuchi Xu, Pipei Huang, Huan Zhao, Guoliang Kang, Qiwei Chen, Wei Li, and Lee
C. Li, Zhiyuan Liu, Mengmeng Wu, Yuchi Xu, Pipei Huang, Huan Zhao, Guoliang Kang, Qiwei Chen, Wei Li, and Lee. Multi-interest network with dynamic routing for recommendation at tmall.Proceedings of the 28th ACM International Conference on Information and Knowledge Management, 2019. URLhttps://api.semanticscholar.org/CorpusID:119120813
2019
-
[15]
Yu Liang, Zhongjin Zhang, Yuxuan Zhu, Kerui Zhang, Zhiluohan Guo, Wenhang Zhou, Zonqi Yang, Kangle Wu, Yabo Ni, Anxiang Zeng, et al. Rethinking generative recommender to- kenizer: Recsys-native encoding and semantic quantization beyond llms.arXiv preprint arXiv:2602.02338, 2026. 13
-
[16]
Generative recommender with end-to-end learnable item tokenization
Enze Liu, Bowen Zheng, Cheng Ling, Lantao Hu, Han Li, and Wayne Xin Zhao. Generative recommender with end-to-end learnable item tokenization. InProceedings of the 48th Interna- tional ACM SIGIR Conference on Research and Development in Information Retrieval, pages 729–739, 2025
2025
-
[17]
The concrete distribution: A continuous relaxation of discrete random variables
Chris J Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous relaxation of discrete random variables.arXiv preprint arXiv:1611.00712, 2016
-
[18]
Image- based recommendations on styles and substitutes.Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2015
Julian McAuley, Christopher Targett, Javen Qinfeng Shi, and Anton van den Hengel. Image- based recommendations on styles and substitutes.Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2015. URL https://api.semanticscholar.org/CorpusID:1012652
2015
-
[19]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
2020
-
[20]
Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan H. Keshavan, Trung Hieu Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Maheswaran Sathiamoorthy. Recommender systems with generative retrieval. ArXiv, abs/2305.05065, 2023. URL https://api.semanticscholar.org/CorpusID: 258564854
- [21]
-
[22]
Methods and metrics for cold-start recommendations
Andrew I Schein, Alexandrin Popescul, Lyle H Ungar, and David M Pennock. Methods and metrics for cold-start recommendations. InProceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval, pages 253–260, 2002
2002
-
[23]
Neural machine translation of rare words with subword units
Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. InProceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers), pages 1715–1725, 2016
2016
-
[24]
Zhengyang Su, Isay Katsman, Yueqi Wang, Ruining He, Lukasz Heldt, Raghunandan Keshavan, Shao-Chuan Wang, Xinyang Yi, Mingyan Gao, Onkar Dalal, et al. Vectorizing the trie: Efficient constrained decoding for llm-based generative retrieval on accelerators.arXiv preprint arXiv:2602.22647, 2026
-
[25]
Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer. InPro- ceedings of the 28th ACM international conference on information and knowledge management, pages 1441–1450, 2019
2019
-
[26]
Transformer memory as a differentiable search index.Advances in neural information processing systems, 35:21831–21843, 2022
Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, et al. Transformer memory as a differentiable search index.Advances in neural information processing systems, 35:21831–21843, 2022
2022
-
[27]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
2017
-
[28]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[29]
Huimu Wang, Xingzhi Yao, Yiming Qiu, Qinghong Zhang, Haotian Wang, Yufan Cui, Songlin Wang, Sulong Xu, and Mingming Li. Towards efficient and generalizable retrieval: Adaptive semantic quantization and residual knowledge transfer.arXiv preprint arXiv:2602.23978, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Learnable item tokenization for generative recommendation.Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, 2024
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua. Learnable item tokenization for generative recommendation.Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, 2024. URLhttps://api.semanticscholar.org/CorpusID:269757237. 14
2024
-
[31]
Ziliang Wang, Gaoyun Lin, Xuesi Wang, Shaoqiang Liang, Yili Huang, and Weijie Bian. Unirec: Bridging the expressive gap between generative and discriminative recommendation via chain-of-attribute.arXiv preprint arXiv:2604.12234, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Tianxin Wei, Xuying Ning, Xuxing Chen, Ruizhong Qiu, Yupeng Hou, Yan Xie, Shuang Yang, Zhigang Hua, and Jingrui He. Cofirec: Coarse-to-fine tokenization for generative recommendation.arXiv preprint arXiv:2511.22707, 2025
-
[33]
On the convergence properties of the em algorithm.The Annals of statistics, pages 95–103, 1983
CF Jeff Wu. On the convergence properties of the em algorithm.The Annals of statistics, pages 95–103, 1983
1983
-
[34]
Yi Xu, Moyu Zhang, Chaofan Fan, Jinxin Hu, Xiaochen Li, Yu Zhang, Xiaoyi Zeng, and Jing Zhang. Mmq-v2: Align, denoise, and amplify: Adaptive behavior mining for semantic ids learning in recommendation.arXiv preprint arXiv:2510.25622, 2025
-
[35]
Generative recommendation for large-scale advertising.arXiv preprint arXiv:2602.22732, 2026
Ben Xue, Dan Liu, Lixiang Wang, Mingjie Sun, Peng Wang, Pengfei Zhang, Shaoyun Shi, Tianyu Xu, Yunhao Sha, Zhiqiang Liu, et al. Generative recommendation for large-scale advertising.arXiv preprint arXiv:2602.22732, 2026
-
[36]
Jing Yan, Yimeng Bai, Zongyu Liu, Yahui Liu, Junwei Wang, Jingze Huang, Haoda Li, Sihao Ding, Shaohui Ruan, and Yang Zhang. Merge: Next-generation item indexing paradigm for large-scale streaming recommendation.arXiv preprint arXiv:2601.20199, 2026
-
[37]
Liu Yang, Fabian Paischer, Kaveh Hassani, Jiacheng Li, Shuai Shao, Zhang Gabriel Li, Yun He, Xue Feng, Nima Noorshams, Sem Park, et al. Unifying generative and dense retrieval for sequential recommendation.arXiv preprint arXiv:2411.18814, 2024
-
[38]
Yuhao Yang, Zhi Ji, Zhaopeng Li, Yi Li, Zhonglin Mo, Yue Ding, Kai Chen, Zijian Zhang, Jie Li, Shuanglong Li, et al. Sparse meets dense: Unified generative recommendations with cascaded sparse-dense representations.arXiv preprint arXiv:2503.02453, 2025
-
[39]
Das: Dual- aligned semantic ids empowered industrial recommender system
Wencai Ye, Mingjie Sun, Shaoyun Shi, Peng Wang, Wenjin Wu, and Peng Jiang. Das: Dual- aligned semantic ids empowered industrial recommender system. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 6217–6224, 2025
2025
-
[40]
Align 3gr: Unified multi-level alignment for llm-based generative recommendation
Wencai Ye, Mingjie Sun, Shuhang Chen, Wenjin Wu, and Peng Jiang. Align 3gr: Unified multi-level alignment for llm-based generative recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 16154–16162, 2026
2026
-
[41]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, et al. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152, 2024
work page internal anchor Pith review arXiv 2024
-
[42]
Retention
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, and Ji rong Wen. Adapting large language models by integrating collaborative semantics for recommendation.2024 IEEE 40th International Conference on Data Engineering (ICDE), pages 1435–1448, 2023. URL https://api.semanticscholar.org/CorpusID:265213194. A Implementation Details This appendix spec...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.