Recognition: unknown
Beyond Semantics: An Evidential Reasoning-Aware Multi-View Learning Framework for Trustworthy Mental Health Prediction
Pith reviewed 2026-05-08 16:45 UTC · model grok-4.3
The pith
A multi-view framework fuses semantic and reasoning signals from text using evidential logic to deliver more reliable mental health predictions with explicit uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
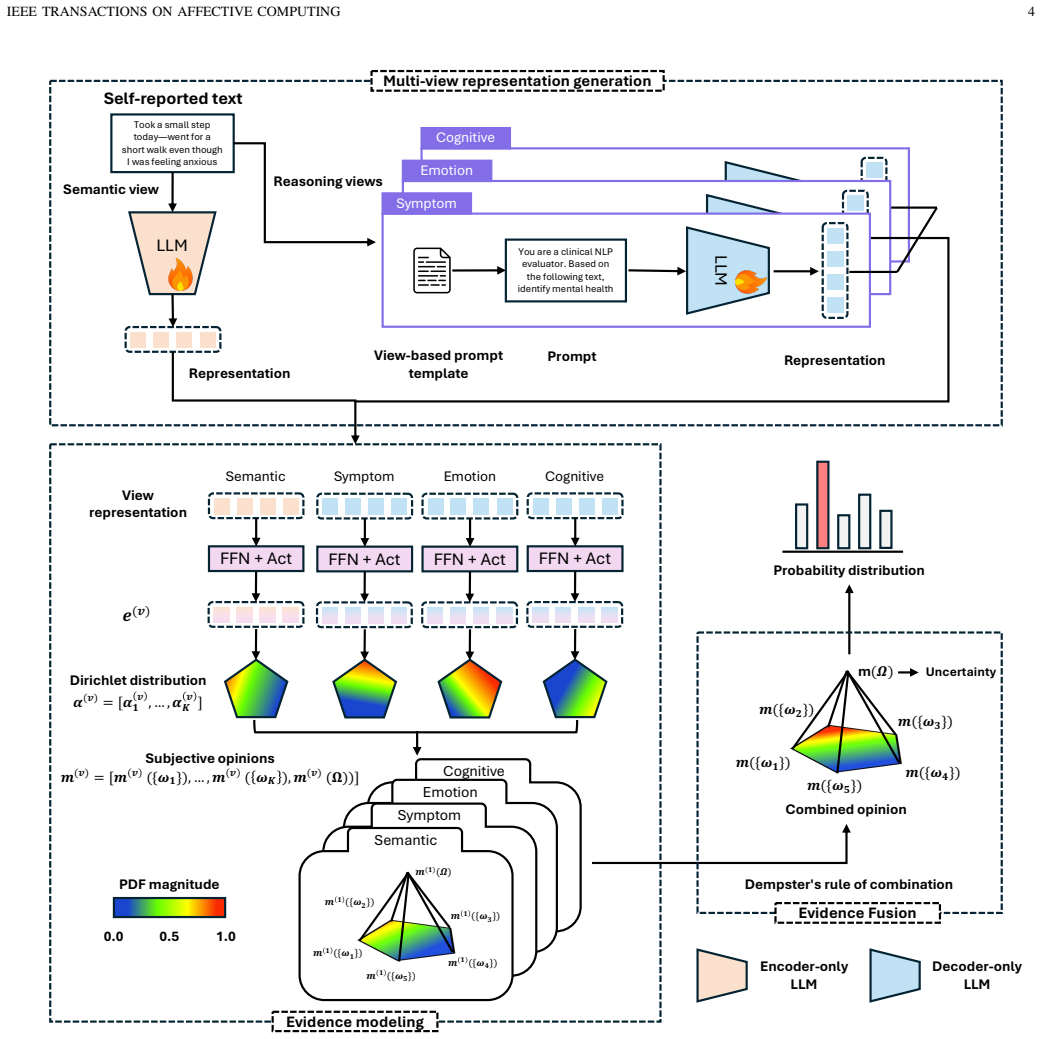
The paper claims that integrating semantic information from encoder-only models with reasoning-aware representations from decoder-only models, then fusing them through an evidential strategy grounded in Subjective Logic, produces mental health predictions that are both more accurate and equipped with explicit uncertainty estimates and interpretable reasoning traces, as demonstrated by the reported accuracies and robustness experiments on three real-world datasets.
What carries the argument
The evidential fusion strategy based on Subjective Logic, which models uncertainty for each view, balances complementary semantic and reasoning information, and down-weights unreliable evidence during combination.
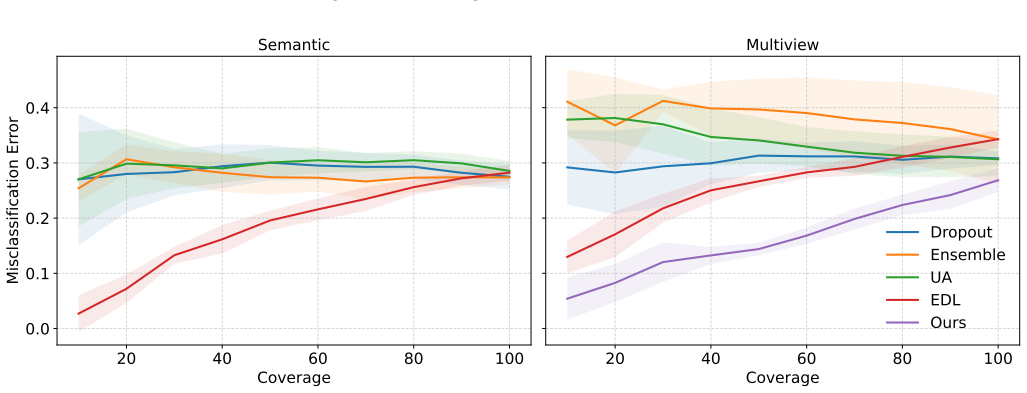
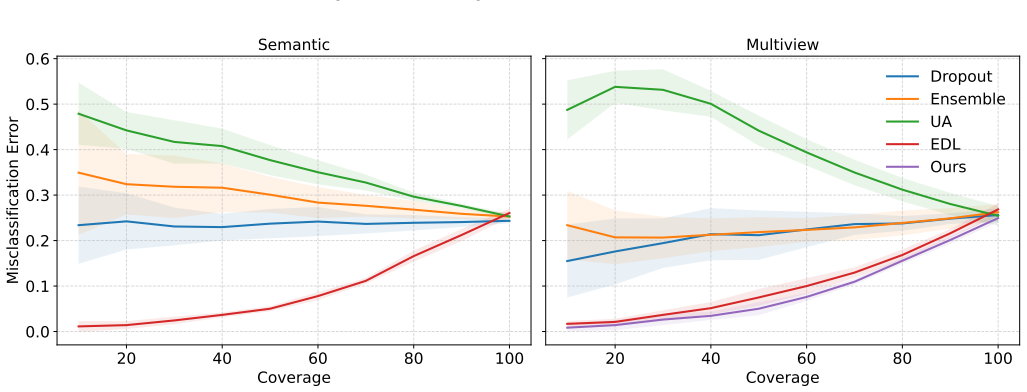
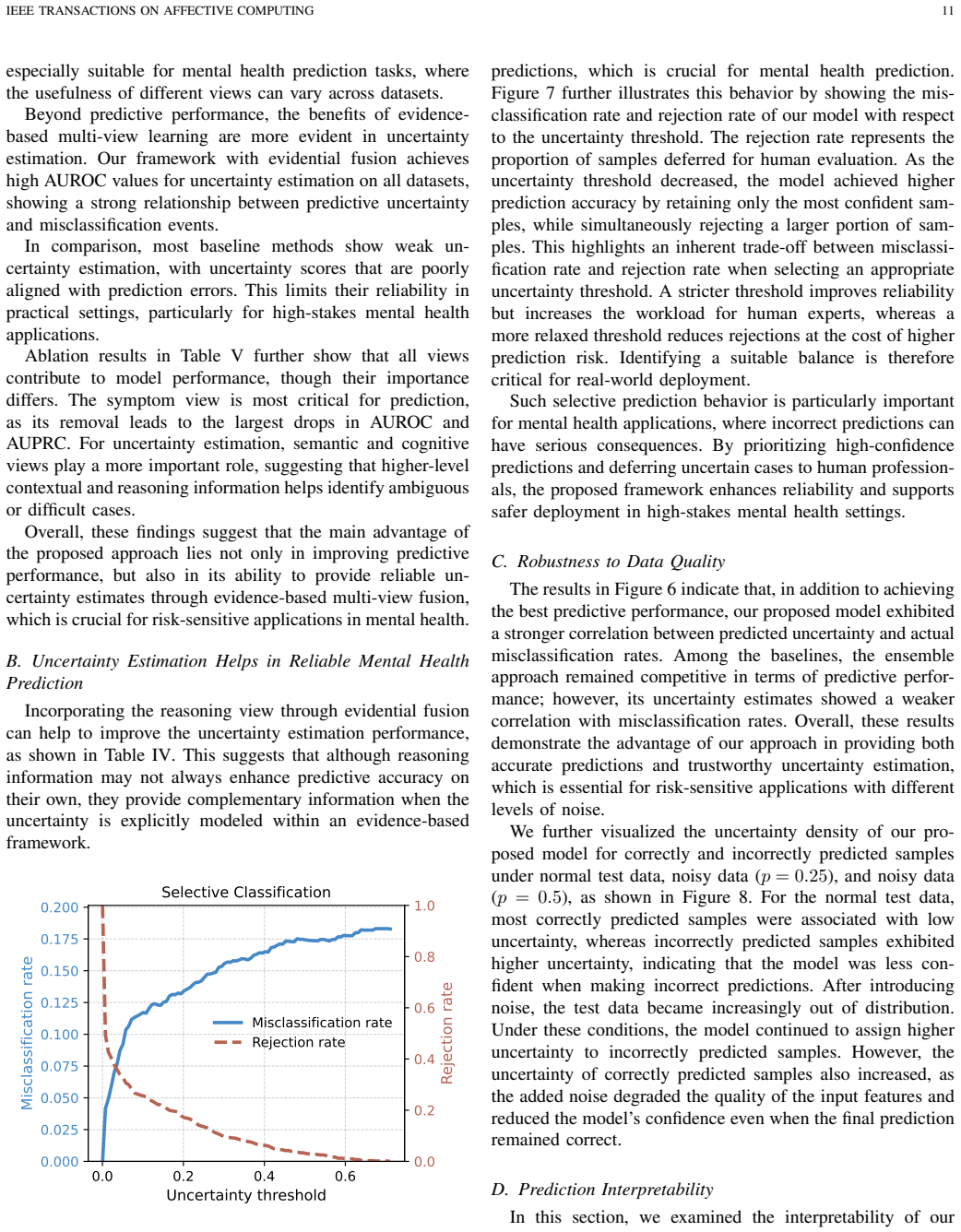
If this is right
- Higher accuracies on textual mental health tasks while maintaining explicit uncertainty quantification.
- Improved robustness when input text contains noise or distribution shifts.
- Generation of human-understandable reasoning signals that accompany each prediction.
- Greater suitability for high-stakes mental health assessment where overconfident errors carry real cost.
- A general template for trustworthy multi-view fusion that can be applied to other text-based risk prediction problems.
Where Pith is reading between the lines
- The same fusion approach could be tested on other high-stakes text domains such as legal document screening or adverse-event detection where uncertainty must be communicated to humans.
- If the reasoning view consistently adds value beyond semantics, future encoders might be trained to produce both types of representation jointly rather than relying on separate models.
- Clinical workflows could incorporate the uncertainty scores as triage signals, routing high-uncertainty cases to human review.
- The method's interpretability might allow post-hoc auditing of why a given social-media post triggered a mental-health flag.
Load-bearing premise
The evidential fusion strategy based on Subjective Logic reliably balances complementary semantic and reasoning views while correctly discounting unreliable evidence without introducing new biases or requiring dataset-specific tuning.
What would settle it
A direct comparison on the three datasets showing that the framework does not exceed strong semantic-only baselines in accuracy, fails to improve noise robustness, or produces uncertainty estimates that do not correlate with actual prediction errors.
Figures





read the original abstract
Automated mental health prediction using textual data has shown promising results with deep learning and large language models. However, deploying these models in high-stakes real-world settings remains challenging, as existing approaches largely rely on semantic representations and often produce overconfident predictions under ambiguous, noisy, or shifted data. Moreover, most methods lack reliable uncertainty estimation, undermining trust in risk-sensitive mental health applications. To address these limitations, we formulate the task as a multi-view learning problem that integrates semantic information from encoder-only models with higher-level reasoning information from decoder-only models, where reasoning-aware representations and uncertainty modeling are obtained in a trustworthy manner. To ensure reliable fusion, we adopt an evidential learning framework based on Subjective Logic to explicitly model uncertainty and introduce an evidential fusion strategy that balances complementary views while discounting unreliable evidence. Benchmarking on three real-world datasets, Dreaddit, SDCNL, and DepSeverity, reports accuracies of 0.835, 0.731, and 0.751, respectively, demonstrating its potential for reliable mental health prediction. Additional experiments on robustness to noise and case studies for interpretability confirm that our proposed framework not only improves predictive performance but also provides trustworthy uncertainty estimates and human-understandable reasoning signals, making it suitable for risk-sensitive applications in mental health assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-view learning framework for textual mental health prediction that fuses semantic representations from encoder-only models with higher-level reasoning representations from decoder-only models. It adopts an evidential learning approach grounded in Subjective Logic to explicitly model and fuse uncertainty, discounting unreliable evidence from either view. The method is benchmarked on three datasets (Dreaddit, SDCNL, DepSeverity) with reported accuracies of 0.835, 0.731, and 0.751; additional experiments examine robustness to noise and provide case studies for interpretability and human-understandable reasoning signals.
Significance. If the central claims on uncertainty calibration and view complementarity hold, the work would offer a concrete advance toward trustworthy models for risk-sensitive mental health applications, where overconfident predictions and lack of interpretable uncertainty are well-documented problems. The explicit use of Subjective Logic for evidential fusion and the dual encoder/decoder view construction are technically distinctive and could generalize beyond the reported datasets.
major comments (2)
- [Experiments] Experiments section (and associated tables): the reported accuracies are presented without any baseline comparisons (e.g., fine-tuned encoder-only or decoder-only models, standard multi-view fusion, or recent evidential baselines), statistical significance tests, or error bars. This makes it impossible to determine whether the claimed gains are meaningful or merely reflect implementation differences.
- [§4.3 and §5.2] §4.3 (Evidential Fusion) and §5.2 (Uncertainty Analysis): no calibration diagnostics are reported for the fused uncertainty (e.g., Expected Calibration Error, Brier score, or error-uncertainty correlation plots). Without these, the claim that Subjective Logic reliably discounts unreliable evidence and produces trustworthy uncertainty estimates remains unverified and could be an artifact of fusion hyperparameters, especially on small, noisy mental-health datasets.
minor comments (2)
- [Abstract] The abstract states that 'additional experiments confirm improved robustness to noise' but provides no quantitative details on noise types, levels, or metrics; this should be clarified with specific numbers or a reference to the relevant table/figure.
- [§3] Notation for the evidential parameters (e.g., belief masses, uncertainty mass) is introduced without an explicit summary table relating them to the Subjective Logic formulation; a small notation table would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will incorporate to strengthen the experimental validation.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and associated tables): the reported accuracies are presented without any baseline comparisons (e.g., fine-tuned encoder-only or decoder-only models, standard multi-view fusion, or recent evidential baselines), statistical significance tests, or error bars. This makes it impossible to determine whether the claimed gains are meaningful or merely reflect implementation differences.
Authors: We agree that baseline comparisons, statistical significance testing, and error bars are necessary to substantiate the reported gains. In the revised manuscript we have expanded the Experiments section with results from fine-tuned encoder-only models (BERT, RoBERTa), decoder-only models (GPT-2), standard multi-view fusion methods (early/late fusion, attention-based), and recent evidential baselines. All results now include error bars over five random seeds and p-values from McNemar’s test. These additions confirm statistically significant improvements and are presented in updated tables in §5. revision: yes
-
Referee: [§4.3 and §5.2] §4.3 (Evidential Fusion) and §5.2 (Uncertainty Analysis): no calibration diagnostics are reported for the fused uncertainty (e.g., Expected Calibration Error, Brier score, or error-uncertainty correlation plots). Without these, the claim that Subjective Logic reliably discounts unreliable evidence and produces trustworthy uncertainty estimates remains unverified and could be an artifact of fusion hyperparameters, especially on small, noisy mental-health datasets.
Authors: We acknowledge that explicit calibration diagnostics are required to verify the trustworthiness of the uncertainty estimates. The revised §5.2 now reports Expected Calibration Error and Brier scores for both individual views and the fused output, together with error-uncertainty correlation plots. We have also added a hyperparameter sensitivity study in the appendix. These diagnostics show improved calibration under the evidential fusion strategy and support that Subjective Logic discounts unreliable evidence rather than producing artifacts. revision: yes
Circularity Check
No significant circularity; empirical framework with external benchmarks
full rationale
The paper formulates mental health prediction as a multi-view integration of encoder and decoder representations, adopts an evidential fusion strategy based on the established Subjective Logic framework, and validates via accuracy benchmarks (0.835/0.731/0.751) plus robustness experiments on three independent real-world datasets. No equations, fitted parameters renamed as predictions, or self-referential definitions appear that would reduce claimed improvements to inputs by construction. The derivation chain is self-contained through standard empirical evaluation rather than tautological reductions or load-bearing self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Depression and other com- mon mental disorders: global health estimates,
W. H. Organizationet al., “Depression and other com- mon mental disorders: global health estimates,” World Health Organization, Tech. Rep., 2017. IEEE TRANSACTIONS ON AFFECTIVE COMPUTING 14
2017
-
[2]
The applications of large language models in mental health: Scoping review,
Y . Jin, J. Liu, P. Li, B. Wang, Y . Yan, H. Zhang, C. Ni, J. Wang, Y . Li, Y . Buet al., “The applications of large language models in mental health: Scoping review,” Journal of Medical Internet Research, vol. 27, p. e69284, 2025
2025
-
[3]
Application of machine learning methods in mental health detection: a systematic review,
R. Abd Rahman, K. Omar, S. A. M. Noah, M. S. N. M. Danuri, and M. A. Al-Garadi, “Application of machine learning methods in mental health detection: a systematic review,”Ieee Access, vol. 8, pp. 183 952–183 964, 2020
2020
-
[4]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
2019
-
[5]
A survey of large language models in mental health disorder detection on social media,
Z. Ge, N. Hu, D. Li, Y . Wang, S. Qi, Y . Xu, H. Shi, and J. Zhang, “A survey of large language models in mental health disorder detection on social media,” in2025 IEEE 41st International Conference on Data Engineering Workshops (ICDEW). IEEE, 2025, pp. 164–176
2025
-
[6]
Evaluation of ChatGPT for NLP-based mental health applications,
B. Lamichhane, “Evaluation of chatgpt for nlp- based mental health applications,”arXiv preprint arXiv:2303.15727, 2023
-
[7]
On the evaluations of chatgpt and emotion-enhanced prompting for mental health analysis,
K. Yang, S. Ji, T. Zhang, Q. Xie, and S. Ananiadou, “On the evaluations of chatgpt and emotion-enhanced prompting for mental health analysis,”arXiv preprint arXiv:2304.03347, vol. 4, 2023
-
[8]
Mental-llm: Leveraging large language models for mental health prediction via online text data,
X. Xu, B. Yao, Y . Dong, S. Gabriel, H. Yu, J. Hendler, M. Ghassemi, A. K. Dey, and D. Wang, “Mental-llm: Leveraging large language models for mental health prediction via online text data,”Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Tech- nologies, vol. 8, no. 1, pp. 1–32, 2024
2024
-
[9]
Trustllm: Trustworthiness in large language models
Y . Huang, L. Sun, H. Wang, S. Wu, Q. Zhang, Y . Li, C. Gao, Y . Huang, W. Lyu, Y . Zhanget al., “Trustllm: Trustworthiness in large language models,” arXiv preprint arXiv:2401.05561, 2024
-
[10]
Mental health assessment: Inference, explanation, and coherence,
P. Thagard and L. Larocque, “Mental health assessment: Inference, explanation, and coherence,”Journal of Eval- uation in Clinical Practice, vol. 24, no. 3, pp. 649–654, 2018
2018
-
[11]
Knowledge fusion of large language models, 2024
F. Wan, X. Huang, D. Cai, X. Quan, W. Bi, and S. Shi, “Knowledge fusion of large language models,”arXiv preprint arXiv:2401.10491, 2024
-
[12]
Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift,
Y . Ovadia, E. Fertig, J. Ren, Z. Nado, D. Scul- ley, S. Nowozin, J. Dillon, B. Lakshminarayanan, and J. Snoek, “Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift,”Ad- vances in neural information processing systems, vol. 32, 2019
2019
-
[13]
Multimodal fusion on low-quality data: A comprehensive survey.arXiv preprint arXiv:2404.18947, 2024
Q. Zhang, Y . Wei, Z. Han, H. Fu, X. Peng, C. Deng, Q. Hu, C. Xu, J. Wen, D. Huet al., “Multimodal fusion on low-quality data: A comprehensive survey,”arXiv preprint arXiv:2404.18947, 2024
-
[14]
Do llms understand ambiguity in text? a case study in open- world question answering,
A. Keluskar, A. Bhattacharjee, and H. Liu, “Do llms understand ambiguity in text? a case study in open- world question answering,” in2024 IEEE International Conference on Big Data (BigData). IEEE, 2024, pp. 7485–7490
2024
-
[15]
Selective classification for deep neural networks,
Y . Geifman and R. El-Yaniv, “Selective classification for deep neural networks,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[16]
Understanding measures of uncer- tainty for adversarial example detection,
L. Smith and Y . Gal, “Understanding measures of uncer- tainty for adversarial example detection,”arXiv preprint arXiv:1803.08533, 2018
-
[17]
Sim- ple and scalable predictive uncertainty estimation using deep ensembles,
B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Sim- ple and scalable predictive uncertainty estimation using deep ensembles,”Advances in neural information pro- cessing systems, vol. 30, 2017
2017
-
[18]
Jøsang,Subjective logic
A. Jøsang,Subjective logic. Springer, 2016, vol. 3
2016
-
[19]
Improving language understanding by generative pre-training,
A. Radford, K. Narasimhan, T. Salimans, I. Sutskever et al., “Improving language understanding by generative pre-training,” 2018
2018
-
[20]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review arXiv 2023
-
[21]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient founda- tion language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review arXiv 2023
-
[22]
Integrating large language models in mental health practice: a qualitative descriptive study based on ex- pert interviews,
Y . Ma, Y . Zeng, T. Liu, R. Sun, M. Xiao, and J. Wang, “Integrating large language models in mental health practice: a qualitative descriptive study based on ex- pert interviews,”Frontiers in Public Health, vol. 12, p. 1475867, 2024
2024
-
[23]
Large language models outperform mental and medical health care professionals in identifying obsessive-compulsive disorder,
J. Kim, K. G. Leonte, M. L. Chen, J. B. Torous, E. Linos, A. Pinto, and C. I. Rodriguez, “Large language models outperform mental and medical health care professionals in identifying obsessive-compulsive disorder,”NPJ Dig- ital Medicine, vol. 7, no. 1, p. 193, 2024
2024
-
[24]
Cpm- nets: Cross partial multi-view networks,
C. Zhang, Z. Han, H. Fu, J. T. Zhou, Q. Huet al., “Cpm- nets: Cross partial multi-view networks,”Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[25]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inInternational conference on machine learning. PmLR, 2020, pp. 1597–1607
2020
-
[26]
A survey on multi-view learning,
C. Xu, D. Tao, and C. Xu, “A survey on multi-view learning,”arXiv preprint arXiv:1304.5634, 2013
-
[27]
A review on multi-view learning,
Z. Yu, Z. Dong, C. Yu, K. Yang, Z. Fan, and C. P. Chen, “A review on multi-view learning,”Frontiers of Computer Science, vol. 19, no. 7, p. 197334, 2025
2025
-
[28]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning,
Y . Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” ininternational conference on machine learn- ing. PMLR, 2016, pp. 1050–1059
2016
-
[29]
Evidential deep learning to quantify classification uncertainty,
M. Sensoy, L. Kaplan, and M. Kandemir, “Evidential deep learning to quantify classification uncertainty,”Ad- vances in neural information processing systems, vol. 31, 2018
2018
-
[30]
Trusted multi-view classification,
Z. Han, C. Zhang, H. Fu, and J. T. Zhou, “Trusted multi-view classification,” 2021. [Online]. Available: https://arxiv.org/abs/2102.02051 IEEE TRANSACTIONS ON AFFECTIVE COMPUTING 15
-
[31]
Trusted multi-view classification with dynamic evidential fusion,
——, “Trusted multi-view classification with dynamic evidential fusion,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 2, pp. 2551–2566, 2022
2022
-
[32]
Upper and lower probability inferences based on a sample from a finite univariate population,
A. P. Dempster, “Upper and lower probability inferences based on a sample from a finite univariate population,” Biometrika, vol. 54, no. 3-4, pp. 515–528, 1967
1967
-
[33]
Shafer,A mathematical theory of evidence
G. Shafer,A mathematical theory of evidence. Princeton university press, 1976, vol. 42
1976
-
[34]
A neural network classifier based on Dempster-Shafer theory,
T. Denoeux, “A neural network classifier based on Dempster-Shafer theory,”IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans, vol. 30, no. 2, pp. 131–150, 2000
2000
-
[35]
A review of uncertainty quantification in medical image analysis: Probabilistic and non-probabilistic methods,
L. Huang, S. Ruan, Y . Xing, and M. Feng, “A review of uncertainty quantification in medical image analysis: Probabilistic and non-probabilistic methods,”Medical Image Analysis, vol. 97, p. 103223, 2024
2024
-
[36]
To- ward reliable medical image segmentation by modeling evidential calibrated uncertainty,
K. Zou, Y . Chen, L. Huang, N. Zhou, X. Yuan, X. Shen, M. Wang, R. S. M. Goh, Y . Liu, Y . C. Thamet al., “To- ward reliable medical image segmentation by modeling evidential calibrated uncertainty,”IEEE Transactions on Cybernetics, 2025
2025
-
[37]
Uncertainty- aware multimodal fusion for reliable fundus disease classification using a vision-language foundation model,
M. Wang, T. Lin, A. Lin, K. Zou, T. Xu, Y . Meng, D. Liu, Y . C. Tham, H. Chen, and H. Fu, “Uncertainty- aware multimodal fusion for reliable fundus disease classification using a vision-language foundation model,” inInternational Workshop on Ophthalmic Medical Image Analysis. Springer, 2025, pp. 65–74
2025
-
[38]
Medsam- u: Uncertainty-guided auto multi-prompt adaptation for reliable medsam,
N. Zhou, K. Zou, K. Ren, M. Luo, L. He, M. Wang, Y . Chen, Y . Zhang, H. Chen, and H. Fu, “Medsam- u: Uncertainty-guided auto multi-prompt adaptation for reliable medsam,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[39]
Mentalbert: Publicly available pretrained language models for mental healthcare,
S. Ji, T. Zhang, L. Ansari, J. Fu, P. Tiwari, and E. Cam- bria, “Mentalbert: Publicly available pretrained language models for mental healthcare,” inproceedings of the thirteenth language resources and evaluation conference, 2022, pp. 7184–7190
2022
-
[40]
The dsm- 5: Classification and criteria changes,
D. A. Regier, E. A. Kuhl, and D. J. Kupfer, “The dsm- 5: Classification and criteria changes,”World psychiatry, vol. 12, no. 2, pp. 92–98, 2013
2013
-
[41]
Employing large language models for emo- tion detection in psychotherapy transcripts,
C. Lalk, K. Targan, T. Steinbrenner, J. Schaffrath, S. Eberhardt, B. Schwartz, A. Vehlen, W. Lutz, and J. Rubel, “Employing large language models for emo- tion detection in psychotherapy transcripts,”Frontiers in Psychiatry, vol. 16, p. 1504306, 2025
2025
-
[42]
Emotionally adaptive support: a narrative re- view of affective computing for mental health,
M. Schlicher, Y . Li, S. M. K. Murthy, Q. Sun, and B. W. Schuller, “Emotionally adaptive support: a narrative re- view of affective computing for mental health,”Frontiers in Digital Health, vol. 7, p. 1657031, 2025
2025
-
[43]
Cognitive– behavioral therapy for management of mental health and stress-related disorders: Recent advances in techniques and technologies,
M. Nakao, K. Shirotsuki, and N. Sugaya, “Cognitive– behavioral therapy for management of mental health and stress-related disorders: Recent advances in techniques and technologies,”BioPsychoSocial medicine, vol. 15, no. 1, p. 16, 2021
2021
-
[44]
Jsang,Subjective Logic: A formalism for reasoning under uncertainty
A. Jsang,Subjective Logic: A formalism for reasoning under uncertainty. Springer Publishing Company, In- corporated, 2018
2018
-
[45]
C. M. Bishop and N. M. Nasrabadi,Pattern recognition and machine learning. Springer, 2006, vol. 4, no. 4
2006
-
[46]
Incorporating second-order functional knowledge for better option pricing,
C. Dugas, Y . Bengio, F. B ´elisle, C. Nadeau, and R. Gar- cia, “Incorporating second-order functional knowledge for better option pricing,”Advances in neural information processing systems, vol. 13, 2000
2000
-
[47]
N. L. Johnson, S. Kotz, and N. Balakrishnan,Continuous multivariate distributions. Wiley New York, 1972, vol. 7
1972
-
[48]
Dreaddit: A reddit dataset for stress analysis in social media,
E. Turcan and K. McKeown, “Dreaddit: A reddit dataset for stress analysis in social media,”arXiv preprint arXiv:1911.00133, 2019
-
[49]
Deep learning for suicide and depression identification with unsuper- vised label correction,
A. Haque, V . Reddi, and T. Giallanza, “Deep learning for suicide and depression identification with unsuper- vised label correction,” inInternational Conference on Artificial Neural Networks. Springer, 2021, pp. 436– 447
2021
-
[50]
Early identification of depression severity levels on reddit using ordinal classification,
U. Naseem, A. G. Dunn, J. Kim, and M. Khushi, “Early identification of depression severity levels on reddit using ordinal classification,” inProceedings of the ACM web conference 2022, 2022, pp. 2563–2572
2022
-
[51]
Uncertainty-aware attention for reli- able interpretation and prediction,
J. Heo, H. B. Lee, S. Kim, J. Lee, K. J. Kim, E. Yang, and S. J. Hwang, “Uncertainty-aware attention for reli- able interpretation and prediction,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[52]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”In: The 3rd International Conference on Learning Representations, ICLR, 2015
2015
-
[53]
Evaluation: from precision, recall and f-measure to roc, informedness, markedness and correlation,
D. M. Powers, “Evaluation: from precision, recall and f-measure to roc, informedness, markedness and correla- tion,”arXiv preprint arXiv:2010.16061, 2020
-
[54]
An introduction to roc analysis,
T. Fawcett, “An introduction to roc analysis,”Pattern recognition letters, vol. 27, no. 8, pp. 861–874, 2006
2006
-
[55]
The precision-recall plot is more informative than the roc plot when evaluating binary classifiers on imbalanced datasets,
T. Saito and M. Rehmsmeier, “The precision-recall plot is more informative than the roc plot when evaluating binary classifiers on imbalanced datasets,”PloS one, vol. 10, no. 3, p. e0118432, 2015
2015
-
[56]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
D. Hendrycks and K. Gimpel, “A baseline for detecting misclassified and out-of-distribution examples in neural networks,”arXiv preprint arXiv:1610.02136, 2016
work page internal anchor Pith review arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.