Recognition: unknown
Adaptive Policy Selection and Fine-Tuning under Interaction Budgets for Offline-to-Online Reinforcement Learning
Pith reviewed 2026-05-08 17:11 UTC · model grok-4.3
The pith
An adaptive upper-confidence-bound method selects and fine-tunes offline-trained policies to improve performance under limited online interaction budgets in reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Following the training of multiple candidate policies using different offline reinforcement learning algorithms and hyperparameters, the paper claims that performing initial off-policy evaluation and then applying an adaptive upper-confidence-bound approach to select and fine-tune policies allows efficient use of online interactions to achieve better performance than standard offline-to-online baselines across benchmarks.
What carries the argument
The central mechanism is the upper-confidence-bound (UCB) based adaptive selection, which uses initial performance estimates to predict which policies are worth fine-tuning while accounting for uncertainty to stay within the interaction budget.
Load-bearing premise
The initial estimates from offline evaluation, when combined with uncertainty bounds, must accurately indicate which policies will actually improve during fine-tuning so that the budget is not wasted on unpromising ones.
What would settle it
Observe whether the method's selected policy achieves higher returns than the best offline candidate after using the full allowed interactions; if it does not on multiple benchmarks, the adaptive selection fails to deliver.
Figures

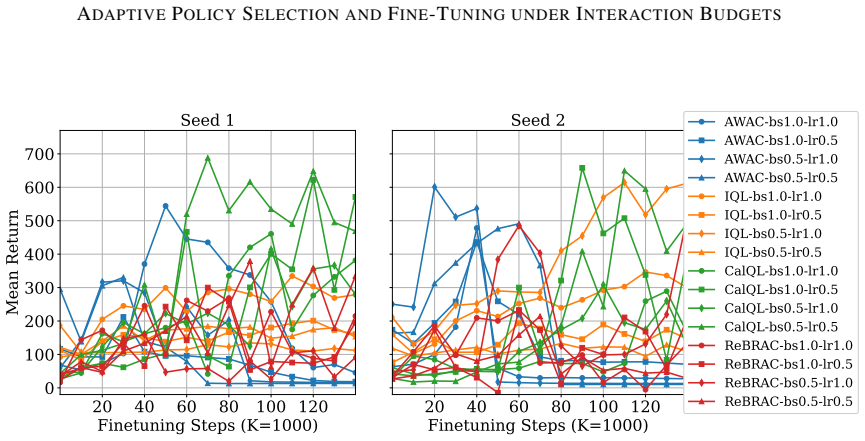
read the original abstract
In offline-to-online reinforcement learning (O2O-RL), policies are first safely trained offline using previously collected datasets and then further fine-tuned for tasks via limited online interactions. In a typical O2O-RL pipeline, candidate policies trained with offline RL are evaluated via either off-policy evaluation (OPE) or online evaluation (OE). The policy with the highest estimated value is then deployed and continually fine-tuned. However, this setup has two main issues. First, OPE can be unreliable, making it risky to deploy a policy based solely on those estimates, whereas OE may identify a viable policy with substantial online interaction, which could have been used for fine-tuning. Second--and more importantly--it is also often not possible to determine a priori whether a pretrained policy will improve with post-deployment fine-tuning, especially in non-stationary environments. As a result, procedures committing to a single deployed policy are impractical in many real-world settings. Moreover, a naive remedy that exhaustively fine-tunes all candidates would violate interaction budget constraints and is likewise infeasible. In this paper, we propose a novel adaptive approach for policy selection and fine-tuning under online interaction budgets in O2O-RL. Following the standard pipeline, we first train a set of candidate policies with different offline RL algorithms and hyperparameters; we then perform OPE to obtain initial performance estimates. We next adaptively select and fine-tune the policies based on their predicted performance via an upper-confidence-bound approach thereby making efficient use of online interactions. We demonstrate that our approach improves upon O2O-RL baselines with various benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an adaptive policy selection and fine-tuning method for offline-to-online reinforcement learning (O2O-RL) under limited interaction budgets. Multiple candidate policies are trained offline with different algorithms and hyperparameters, initial performance estimates are obtained via off-policy evaluation (OPE), and an upper-confidence-bound (UCB) rule is then used to adaptively select which policies to fine-tune online, with the goal of efficiently allocating the interaction budget without committing to a single policy or exhausting it on all candidates. The authors claim this improves upon standard O2O-RL baselines across various benchmarks.
Significance. If the empirical claims hold, the work addresses a practical gap in O2O-RL by handling unreliable OPE estimates and uncertainty about which pretrained policies will benefit from fine-tuning (especially in non-stationary environments) through budgeted UCB-based adaptation. It builds directly on standard UCB exploration principles rather than introducing new theoretical machinery, which could make it straightforward to implement if the empirical gains are reproducible.
major comments (2)
- [Abstract] Abstract: The central claim that the adaptive UCB approach 'improves upon O2O-RL baselines with various benchmarks' is stated without any quantitative results, error bars, ablation studies, or implementation details supplied in the manuscript text. This leaves the empirical improvement unverifiable and is load-bearing for the paper's contribution.
- [Method description] Method description (OPE + UCB selection): The approach assumes that initial OPE estimates, when combined with UCB, can reliably allocate the finite online budget toward policies that actually improve under fine-tuning. However, no theoretical bound or empirical ablation is provided demonstrating robustness when OPE bias/variance exceeds a threshold, despite the abstract explicitly noting OPE unreliability and the impossibility of knowing a priori which policy will benefit from fine-tuning. This assumption is load-bearing for the claim that the method works within interaction budgets.
minor comments (1)
- [Abstract] The abstract refers to 'various benchmarks' without naming them or describing the experimental setup, making it difficult to assess the scope of the claimed improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each major point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the adaptive UCB approach 'improves upon O2O-RL baselines with various benchmarks' is stated without any quantitative results, error bars, ablation studies, or implementation details supplied in the manuscript text. This leaves the empirical improvement unverifiable and is load-bearing for the paper's contribution.
Authors: We agree that the abstract would be strengthened by including concrete quantitative evidence. In the revised manuscript we will update the abstract to report specific performance gains (relative improvement over baselines), standard errors from repeated runs, and a brief note on the experimental setup, while preserving the abstract's length and readability. revision: yes
-
Referee: [Method description] Method description (OPE + UCB selection): The approach assumes that initial OPE estimates, when combined with UCB, can reliably allocate the finite online budget toward policies that actually improve under fine-tuning. However, no theoretical bound or empirical ablation is provided demonstrating robustness when OPE bias/variance exceeds a threshold, despite the abstract explicitly noting OPE unreliability and the impossibility of knowing a priori which policy will benefit from fine-tuning. This assumption is load-bearing for the claim that the method works within interaction budgets.
Authors: We appreciate the emphasis on robustness. While we do not introduce new theoretical bounds (our method applies standard UCB to the practical setting of budgeted O2O-RL rather than deriving novel concentration inequalities), we have added an empirical ablation study in the revised version. The study systematically varies OPE bias and variance and shows that the UCB selection rule continues to allocate interactions effectively by maintaining exploration across candidates. We have also clarified in the method section how the UCB bonus term directly addresses uncertainty in the initial OPE estimates. revision: partial
Circularity Check
No circularity: algorithmic proposal built on standard UCB and OPE without self-referential reduction
full rationale
The paper describes a practical algorithm: train offline candidates, compute OPE estimates, then apply UCB-based adaptive selection and fine-tuning within an interaction budget. No derivation chain, theorem, or 'prediction' is claimed that reduces by construction to fitted inputs or self-citations. The method extends existing RL primitives (OPE + UCB) without redefining quantities in terms of themselves or smuggling ansatzes via author citations. Empirical claims rest on benchmark comparisons rather than tautological steps. This is the expected non-finding for an applied algorithmic contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Markov decision process formulation and standard RL value estimation assumptions.
Reference graph
Works this paper leans on
-
[1]
Efficient online reinforcement learning with offline data
Philip J Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data. In International Conference on Machine Learning, pages 1577--1594. PMLR, 2023
2023
-
[2]
Generalized autoregressive conditional heteroskedasticity
Tim Bollerslev. Generalized autoregressive conditional heteroskedasticity. Journal of econometrics, 31 0 (3): 0 307--327, 1986
1986
-
[3]
Time series analysis: forecasting and control
George EP Box, Gwilym M Jenkins, Gregory C Reinsel, and Greta M Ljung. Time series analysis: forecasting and control. John Wiley & Sons, 2015
2015
-
[4]
Offline rl without off-policy evaluation
David Brandfonbrener, Will Whitney, Rajesh Ranganath, and Joan Bruna. Offline rl without off-policy evaluation. Advances in neural information processing systems, 34: 0 4933--4946, 2021
2021
-
[5]
Learning and deploying robust locomotion policies with minimal dynamics randomization
Luigi Campanaro, Siddhant Gangapurwala, Wolfgang Merkt, and Ioannis Havoutis. Learning and deploying robust locomotion policies with minimal dynamics randomization. In 6th Annual Learning for Dynamics & Control Conference, pages 578--590. PMLR, 2024
2024
-
[6]
Spikeatac: A multimodal tactile finger with taxelized dynamic sensing for dexterous manipulation
Eric T Chang, Peter Ballentine, Zhanpeng He, Do-Gon Kim, Kai Jiang, Hua-Hsuan Liang, Joaquin Palacios, William Wang, Pedro Piacenza, Ioannis Kymissis, et al. Spikeatac: A multimodal tactile finger with taxelized dynamic sensing for dexterous manipulation. arXiv preprint arXiv:2510.27048, 2025
-
[7]
Pybullet, a python module for physics simulation for games, robotics and machine learning
Erwin Coumans and Yunfei Bai. Pybullet, a python module for physics simulation for games, robotics and machine learning. http://pybullet.org, 2021. Accessed 10 November 2025
2021
-
[8]
Challenges of real-world reinforcement learning: definitions, benchmarks and analysis
Gabriel Dulac-Arnold, Nir Levine, Daniel J Mankowitz, Jerry Li, Cosmin Paduraru, Sven Gowal, and Todd Hester. Challenges of real-world reinforcement learning: definitions, benchmarks and analysis. Machine Learning, 110 0 (9): 0 2419--2468, 2021
2021
-
[9]
Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation
Robert F Engle. Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation. Econometrica: Journal of the econometric society, pages 987--1007, 1982
1982
-
[10]
Dataset reproducibility guide
Foundation Farama. Dataset reproducibility guide. https://github.com/Farama-Foundation/d4rl/wiki/Dataset-Reproducibility-Guide, 2021. Accessed 10 November 2025
2021
-
[11]
Dense reinforcement learning for safety validation of autonomous vehicles
Shuo Feng, Haowei Sun, Xintao Yan, Haojie Zhu, Zhengxia Zou, Shengyin Shen, and Henry X Liu. Dense reinforcement learning for safety validation of autonomous vehicles. Nature, 615 0 (7953): 0 620--627, 2023
2023
-
[12]
Implicit behavioral cloning
Pete Florence, Corey Lynch, Andy Zeng, Oscar A Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. Implicit behavioral cloning. In Conference on robot learning, pages 158--168. PMLR, 2022
2022
-
[13]
GARCH models: structure, statistical inference and financial applications
Christian Francq and Jean-Michel Zakoian. GARCH models: structure, statistical inference and financial applications. John Wiley & Sons, 2019
2019
-
[14]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning. arXiv preprint arXiv:2004.07219, 2020
work page internal anchor Pith review arXiv 2004
-
[15]
A minimalist approach to offline reinforcement learning
Scott Fujimoto and Shixiang Shane Gu. A minimalist approach to offline reinforcement learning. Advances in neural information processing systems, 34: 0 20132--20145, 2021
2021
-
[16]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. In International conference on machine learning, pages 1587--1596. PMLR, 2018
2018
-
[17]
Off-policy deep reinforcement learning without exploration
Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. In International conference on machine learning, pages 2052--2062. PMLR, 2019
2052
-
[18]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International Conference on Machine Learning, pages 1861--1870. PMLR, 2018
2018
-
[19]
Towards deployment-efficient reinforcement learning: Lower bound and optimality
Jiawei Huang, Jinglin Chen, Li Zhao, Tao Qin, Nan Jiang, and Tie-Yan Liu. Towards deployment-efficient reinforcement learning: Lower bound and optimality. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=ccWaPGl9Hq
2022
-
[20]
Never stop learning: The effectiveness of fine-tuning in robotic reinforcement learning
Ryan Julian, Benjamin Swanson, Gaurav Sukhatme, Sergey Levine, Chelsea Finn, and Karol Hausman. Never stop learning: The effectiveness of fine-tuning in robotic reinforcement learning. In Conference on Robot Learning, pages 2120--2136. PMLR, 2021
2021
-
[21]
Active offline policy selection
Ksenia Konyushova, Yutian Chen, Thomas Paine, Caglar Gulcehre, Cosmin Paduraru, Daniel J Mankowitz, Misha Denil, and Nando de Freitas. Active offline policy selection. Advances in Neural Information Processing Systems, 34: 0 24631--24644, 2021
2021
-
[22]
Offline reinforcement learning with implicit q-learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning. In Deep RL Workshop NeurIPS, 2021
2021
-
[23]
Stabilizing off-policy q-learning via bootstrapping error reduction
Aviral Kumar, Justin Fu, Matthew Soh, George Tucker, and Sergey Levine. Stabilizing off-policy q-learning via bootstrapping error reduction. Advances in neural information processing systems, 32, 2019
2019
-
[24]
Conservative q-learning for offline reinforcement learning
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. Advances in neural information processing systems, 33: 0 1179--1191, 2020
2020
-
[25]
Showing your offline reinforcement learning work: Online evaluation budget matters
Vladislav Kurenkov and Sergey Kolesnikov. Showing your offline reinforcement learning work: Online evaluation budget matters. In International Conference on Machine Learning, pages 11729--11752. PMLR, 2022
2022
-
[26]
Exploration in deep reinforcement learning: A survey
Pawel Ladosz, Lilian Weng, Minwoo Kim, and Hyondong Oh. Exploration in deep reinforcement learning: A survey. Information Fusion, 85: 0 1--22, 2022
2022
-
[27]
Batch policy learning under constraints
Hoang Le, Cameron Voloshin, and Yisong Yue. Batch policy learning under constraints. In International Conference on Machine Learning, pages 3703--3712. PMLR, 2019
2019
-
[28]
Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble
Seunghyun Lee, Younggyo Seo, Kimin Lee, Pieter Abbeel, and Jinwoo Shin. Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble. In Conference on Robot Learning, pages 1702--1712. PMLR, 2022
2022
-
[29]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review arXiv 2005
-
[30]
Continuous control with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. In International Conference on Learning Representations, 2016
2016
-
[31]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. Awac: Accelerating online reinforcement learning with offline datasets. arXiv preprint arXiv:2006.09359, 2020
work page internal anchor Pith review arXiv 2006
-
[32]
Cal-ql: Calibrated offline rl pre-training for efficient online fine-tuning
Mitsuhiko Nakamoto, Simon Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, and Sergey Levine. Cal-ql: Calibrated offline rl pre-training for efficient online fine-tuning. Advances in Neural Information Processing Systems, 36: 0 62244--62269, 2023
2023
-
[33]
Hyperparameter selection for offline reinforcement learning
Tom Le Paine, Cosmin Paduraru, Andrea Michi, Caglar Gulcehre, Konrad Zolna, Alexander Novikov, Ziyu Wang, and Nando de Freitas. Hyperparameter selection for offline reinforcement learning. arXiv preprint arXiv:2007.09055, 2020
-
[34]
A survey on offline reinforcement learning: Taxonomy, review, and open problems
Rafael Figueiredo Prudencio, Marcos ROA Maximo, and Esther Luna Colombini. A survey on offline reinforcement learning: Taxonomy, review, and open problems. IEEE Transactions on Neural Networks and Learning Systems, 35 0 (8): 0 10237--10257, 2023
2023
-
[35]
Neorl: A near real-world benchmark for offline reinforcement learning
Rong-Jun Qin, Xingyuan Zhang, Songyi Gao, Xiong-Hui Chen, Zewen Li, Weinan Zhang, and Yang Yu. Neorl: A near real-world benchmark for offline reinforcement learning. Advances in Neural Information Processing Systems, 35: 0 24753--24765, 2022
2022
-
[36]
d3rlpy: An offline deep reinforcement learning library
Takuma Seno and Michita Imai. d3rlpy: An offline deep reinforcement learning library. Journal of Machine Learning Research, 23 0 (315): 0 1--20, 2022. URL http://jmlr.org/papers/v23/22-0017.html
2022
-
[37]
Univariate volatility modeling, bootstrapping, multiple comparison procedures and unit root tests
Kevin Sheppard. Univariate volatility modeling, bootstrapping, multiple comparison procedures and unit root tests. https://github.com/bashtage/arch, 2021. Accessed 10 November 2025
2021
-
[38]
Reinforcement learning in robotic applications: a comprehensive survey
Bharat Singh, Rajesh Kumar, and Vinay Pratap Singh. Reinforcement learning in robotic applications: a comprehensive survey. Artificial Intelligence Review, 55 0 (2): 0 945--990, 2022
2022
-
[39]
Hybrid RL : Using both offline and online data can make RL efficient
Yuda Song, Yifei Zhou, Ayush Sekhari, Drew Bagnell, Akshay Krishnamurthy, and Wen Sun. Hybrid RL : Using both offline and online data can make RL efficient. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=yyBis80iUuU
2023
-
[40]
Lee, John Mulvey, and H
DiJia Su, Jason D. Lee, John Mulvey, and H. Vincent Poor. MURO : Deployment constrained reinforcement learning with model-based uncertainty regularized batch optimization, 2022. URL https://openreview.net/forum?id=eWNpRVcfzi
2022
-
[41]
Deep reinforcement learning for robotics: A survey of real-world successes
Chen Tang, Ben Abbatematteo, Jiaheng Hu, Rohan Chandra, Roberto Mart \' n-Mart \' n, and Peter Stone. Deep reinforcement learning for robotics: A survey of real-world successes. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 28694--28698, 2025
2025
-
[42]
Revisiting the minimalist approach to offline reinforcement learning
Denis Tarasov, Vladislav Kurenkov, Alexander Nikulin, and Sergey Kolesnikov. Revisiting the minimalist approach to offline reinforcement learning. Advances in Neural Information Processing Systems, 36: 0 11592--11620, 2023
2023
-
[43]
Balanced reward-inspired reinforcement learning for autonomous vehicle racing
Zhen Tian, Dezong Zhao, Zhihao Lin, David Flynn, Wenjing Zhao, and Daxin Tian. Balanced reward-inspired reinforcement learning for autonomous vehicle racing. In 6th Annual Learning for Dynamics & Control Conference, pages 628--640. PMLR, 2024
2024
-
[44]
Behavioral cloning from observation
Faraz Torabi, Garrett Warnell, and Peter Stone. Behavioral cloning from observation. In International Joint Conference on Artificial Intelligence, pages 4950--4957, 2018
2018
-
[45]
A review of off-policy evaluation in reinforcement learning
Masatoshi Uehara, Chengchun Shi, and Nathan Kallus. A review of off-policy evaluation in reinforcement learning. Statistical Science, 2025
2025
-
[46]
A reinforcement learning method for human-robot collaboration in assembly tasks
Rong Zhang, Qibing Lv, Jie Li, Jinsong Bao, Tianyuan Liu, and Shimin Liu. A reinforcement learning method for human-robot collaboration in assembly tasks. Robotics and Computer-Integrated Manufacturing, 73: 0 102227, 2022
2022
-
[47]
Real world offline reinforcement learning with realistic data source
Gaoyue Zhou, Liyiming Ke, Siddhartha Srinivasa, Abhinav Gupta, Aravind Rajeswaran, and Vikash Kumar. Real world offline reinforcement learning with realistic data source. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 7176--7183. IEEE, 2023
2023
-
[48]
Plas: Latent action space for offline reinforcement learning
Wenxuan Zhou, Sujay Bajracharya, and David Held. Plas: Latent action space for offline reinforcement learning. In Conference on Robot Learning, pages 1719--1735. PMLR, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.