Recognition: unknown
Understanding In-Context Learning for Nonlinear Regression with Transformers: Attention as Featurizer
Pith reviewed 2026-05-08 16:23 UTC · model grok-4.3
The pith
Transformers can use attention to construct nonlinear features like polynomials for in-context regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through the interaction mechanism in attention, we explicitly construct transformer networks to realize nonlinear features, such as polynomial or spline bases, which span a wide class of functions. Based on this construction, we establish a framework to analyze end-to-end in-context nonlinear regression with the constructed features. Our theory provides finite-sample generalization error bounds in terms of context length and training set size.
What carries the argument
Attention mechanism used as a featurizer to explicitly realize nonlinear bases such as polynomials or splines via query-key-value interactions.
Load-bearing premise
Attention weights and interactions can be set exactly to realize the desired nonlinear bases without approximation error that would invalidate the generalization analysis.
What would settle it
A calculation showing that the explicit attention construction fails to output the target polynomial or spline features on a simple test input, or that measured generalization error exceeds the stated bounds for sufficiently large context length.
Figures

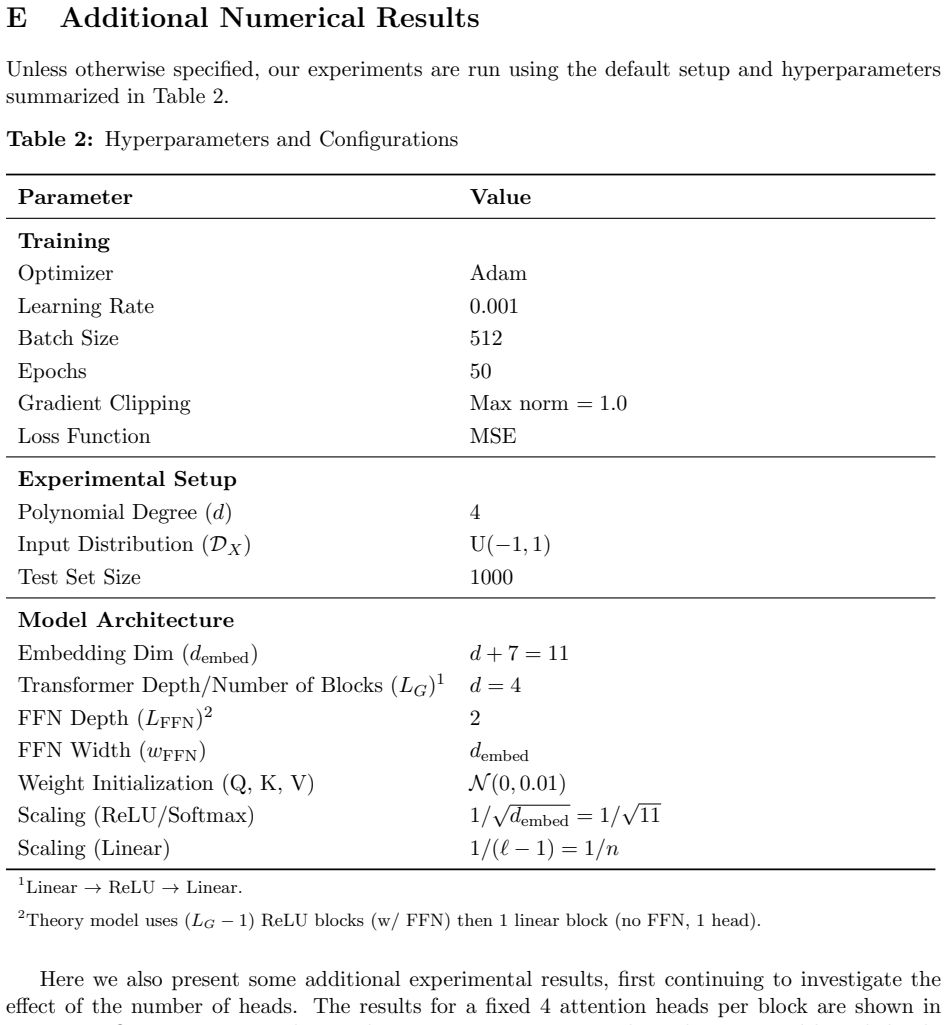
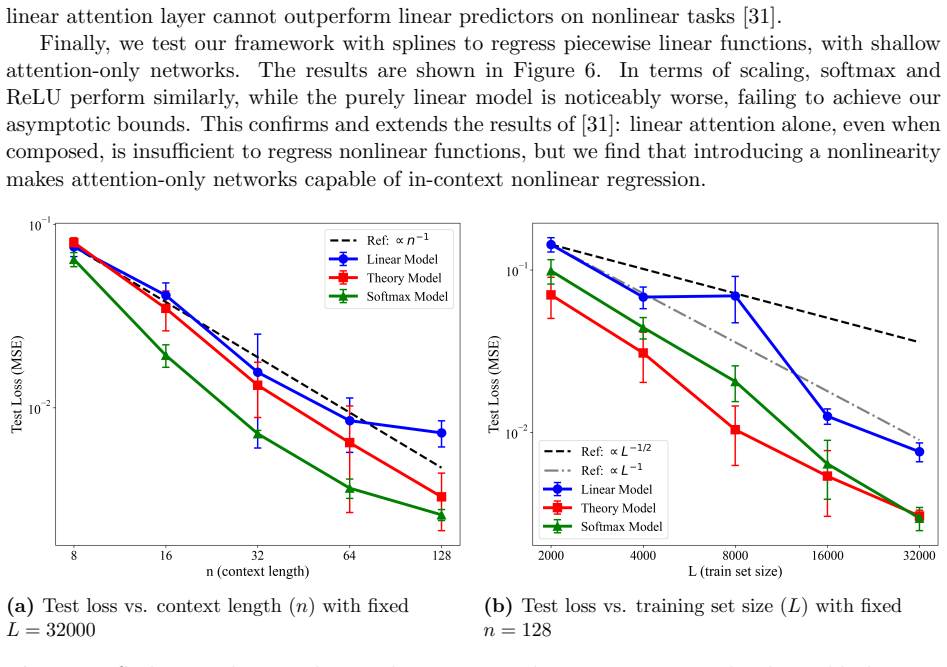


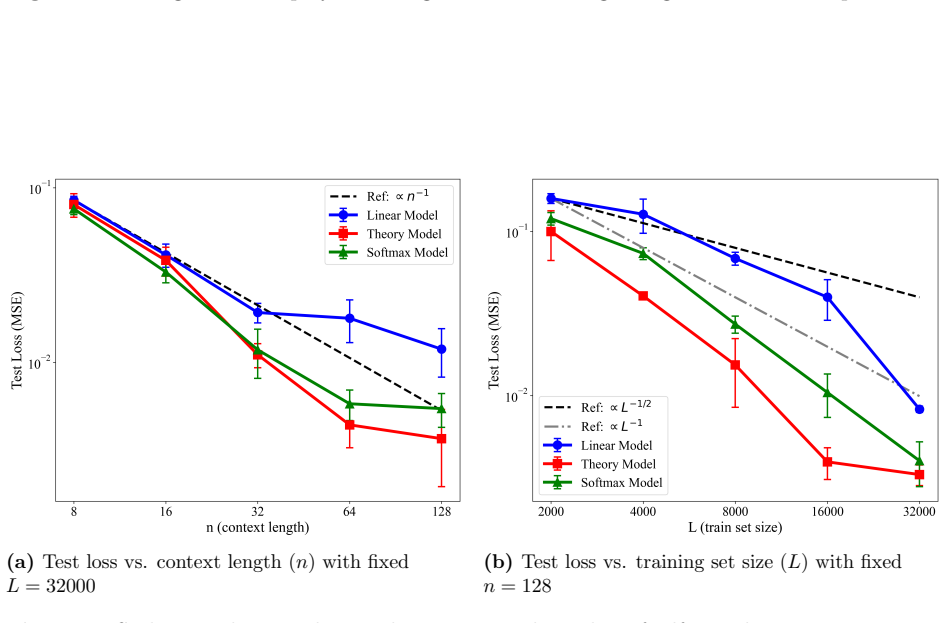

read the original abstract
Pre-trained transformers are able to learn from examples provided as part of the prompt without any weight updates, a remarkable ability known as in-context learning (ICL). Despite its demonstrated efficacy across various domains, the theoretical understanding of ICL is still developing. Whereas most existing theory has focused on linear models, we study ICL in the nonlinear regression setting. Through the interaction mechanism in attention, we explicitly construct transformer networks to realize nonlinear features, such as polynomial or spline bases, which span a wide class of functions. Based on this construction, we establish a framework to analyze end-to-end in-context nonlinear regression with the constructed features. Our theory provides finite-sample generalization error bounds in terms of context length and training set size. We numerically validate the theory on synthetic regression tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that transformers can be explicitly constructed via attention interactions to realize nonlinear feature maps such as polynomial or spline bases. Using this construction, the authors develop a framework for end-to-end in-context nonlinear regression and derive finite-sample generalization error bounds depending on context length and training set size, with numerical validation on synthetic regression tasks.
Significance. If the construction achieves exact nonlinear features with zero approximation error and the bounds are derived without hidden dependencies, the work would meaningfully extend ICL theory beyond linear models by providing a concrete featurization mechanism and quantifiable finite-sample guarantees. The explicit construction and numerical experiments are strengths that could guide future analyses of nonlinear ICL.
major comments (2)
- [§3] §3 (Construction): The explicit realization of exact polynomial/spline bases via query-key interactions and softmax assumes specific weight settings and input scalings that produce zero approximation error. The finite-sample bounds in §4 do not include additional terms for residual error from the continuous attention mechanism or input distribution mismatches, making the headline bounds conditional on an idealized regime not fully justified in the derivation.
- [§4] §4 (Generalization Bounds): The bounds are expressed in terms of context length and training-set size, but the derivation does not clarify whether these quantities enter independently or through constants tied to the constructed features. This leaves open the possibility of circularity, where the bound tightness depends on the very features whose construction is being analyzed.
minor comments (2)
- [Abstract] The abstract states that bounds depend on context length and training set size but does not indicate the functional form (e.g., rates or logarithmic factors); adding this detail would improve precision.
- [Experiments] Numerical validation section lacks reported error bars, number of independent trials, and quantitative metrics comparing empirical error to the theoretical bound; including these would make the experiments more reproducible and convincing.
Simulated Author's Rebuttal
We thank the referee for the careful reading and insightful comments on our work. We address each major comment point by point below, providing clarifications on the construction and bounds while committing to revisions that improve the manuscript's rigor and transparency without altering the core contributions.
read point-by-point responses
-
Referee: [§3] §3 (Construction): The explicit realization of exact polynomial/spline bases via query-key interactions and softmax assumes specific weight settings and input scalings that produce zero approximation error. The finite-sample bounds in §4 do not include additional terms for residual error from the continuous attention mechanism or input distribution mismatches, making the headline bounds conditional on an idealized regime not fully justified in the derivation.
Authors: We appreciate the referee's observation. Section 3 presents an explicit construction where specific choices of query/key weights, value projections, and input scalings (e.g., via appropriate normalization) allow the softmax attention to exactly recover polynomial or spline bases with zero approximation error. This is a deliberate theoretical device to isolate the featurization power of attention, analogous to how linear ICL analyses assume exact linear heads. The bounds in §4 are derived precisely under this zero-error regime, so no residual terms appear by construction. We agree that the manuscript would benefit from greater explicitness here. We will revise §3 to include a dedicated remark stating the exact conditions for zero error and add a short discussion in §4 noting that the bounds are conditional on this idealized attention realization (with a forward reference to potential approximation errors in non-constructed settings). This constitutes a partial revision focused on clarity. revision: partial
-
Referee: [§4] §4 (Generalization Bounds): The bounds are expressed in terms of context length and training-set size, but the derivation does not clarify whether these quantities enter independently or through constants tied to the constructed features. This leaves open the possibility of circularity, where the bound tightness depends on the very features whose construction is being analyzed.
Authors: We thank the referee for raising this potential circularity concern. The derivation in §4 treats the nonlinear feature map as fixed once constructed in §3; the context length n (in-context examples) and training set size m enter the finite-sample bounds independently via standard tools such as uniform convergence over the function class spanned by the fixed features (e.g., via covering numbers or Rademacher complexity that scale with n and m). The constants in the bounds depend on intrinsic properties of the constructed features (dimension, boundedness), but these are determined solely by the transformer weights and are independent of the ICL data or the regression task being solved. There is thus no circular dependence on the features being “analyzed” by the ICL process itself. We will revise the theorem statements and proof sketches in §4 to explicitly separate the fixed feature class from the sample-size terms, adding a clarifying sentence after each bound to remove any ambiguity. revision: yes
Circularity Check
No significant circularity; explicit construction and bounds are independently derived
full rationale
The paper explicitly constructs transformer networks via attention interactions to realize exact nonlinear features (polynomials or splines) that span a function class, then uses this construction as the basis for a separate framework analyzing end-to-end ICL nonlinear regression. Finite-sample generalization bounds are derived in terms of external parameters (context length and training set size), which enter as independent variables rather than being fitted to or defined by the realized features. No self-definitional reduction, fitted-input-as-prediction, or load-bearing self-citation chain appears; the derivation remains self-contained against the stated construction and does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention mechanisms can be configured to realize polynomial or spline bases exactly
Reference graph
Works this paper leans on
-
[1]
Transformers learn to im- plement preconditioned gradient descent for in-context learning
Kwangjun Ahn, Xiang Cheng, Hadi Daneshmand, and Suvrit Sra. Transformers learn to im- plement preconditioned gradient descent for in-context learning. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id= LziniAXEI9
2023
-
[2]
What learning algorithm is in-context learning? investigations with linear models, 2023
Ekin Aky¨ urek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models.arXiv preprint arXiv:2211.15661, 2022
-
[3]
Transformers as statisticians: Provable in-context learning with in-context algorithm selection
Yu Bai, Fan Chen, Huan Wang, Caiming Xiong, and Song Mei. Transformers as statisticians: Provable in-context learning with in-context algorithm selection. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id= liMSqUuVg9
2023
-
[4]
Language 13 models are few-shot learners.Advances in neural information processing systems, 33:1877– 1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language 13 models are few-shot learners.Advances in neural information processing systems, 33:1877– 1901, 2020
1901
-
[5]
Transformers implement functional gradient de- scent to learn non-linear functions in context
Xiang Cheng, Yuxin Chen, and Suvrit Sra. Transformers implement functional gradient de- scent to learn non-linear functions in context. In Ruslan Salakhutdinov, Zico Kolter, Kather- ine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Proceedings of the 41st International Conference on Machine Learning, volume 235 ofP...
2024
-
[6]
Frank Cole, Yulong Lu, Wuzhe Xu, and Tianhao Zhang. In-context learning of linear systems: Generalization theory and applications to operator learning, 2025. URLhttps://arxiv.org/ abs/2409.12293
-
[7]
Why can GPT learn in-context? language models secretly perform gradient descent as meta-optimizers
Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Shuming Ma, Zhifang Sui, and Furu Wei. Why can GPT learn in-context? language models secretly perform gradient descent as meta-optimizers. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Findings of the Asso- ciation for Computational Linguistics: ACL 2023, pages 4005–4019, Toronto, Canada, July
2023
-
[8]
Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers
Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.247. URL https://aclanthology.org/2023.findings-acl.247/
-
[9]
DeVore and G.G
R.A. DeVore and G.G. Lorentz.Constructive Approximation. Grundlehren der mathe- matischen Wissenschaften. Springer Berlin Heidelberg, 1993. ISBN 9783540506270. URL https://books.google.com/books?id=cDqNW6k7_ZwC
1993
-
[10]
Journal of Functional Analysis , volume =
R.M Dudley. The sizes of compact subsets of hilbert space and continuity of gaussian processes. Journal of Functional Analysis, 1(3):290–330, 1967. ISSN 0022-1236. doi: https://doi.org/ 10.1016/0022-1236(67)90017-1. URLhttps://www.sciencedirect.com/science/article/ pii/0022123667900171
-
[11]
A mathematical framework for transformer circuits.Transformer Circuits Thread,
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
-
[12]
https://transformer-circuits.pub/2021/framework/index.html
2021
-
[13]
What can transformers learn in-context? a case study of simple function classes.Advances in Neural Information Processing Systems, 35, 2022
Shivam Garg, Dimitris Tsipras, Percy S Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes.Advances in Neural Information Processing Systems, 35, 2022
2022
-
[14]
How do transformers learn in-context beyond simple functions? A case study on learning with representations
Tianyu Guo, Wei Hu, Song Mei, Huan Wang, Caiming Xiong, Silvio Savarese, and Yu Bai. How do transformers learn in-context beyond simple functions? A case study on learning with representations. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URLhttps://openreview. net/fo...
2024
-
[15]
Predicting scaling laws with statistical and approximation theory for transformer neural networks on intrinsically low-dimensional data
Alex Havrilla and Wenjing Liao. Predicting scaling laws with statistical and approximation theory for transformer neural networks on intrinsically low-dimensional data. InAdvances in Neural Information Processing Systems, 2024. 14
2024
-
[16]
In-context convergence of transformers
Yu Huang, Yuan Cheng, and Yingbin Liang. In-context convergence of transformers. In Proceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[17]
Evan Hubinger, Chris van Merwijk, Vladimir Mikulik, Joar Skalse, and Scott Garrabrant. Risks from learned optimization in advanced machine learning systems, 2021. URLhttps: //arxiv.org/abs/1906.01820
-
[18]
Li Jing, Pascal Vincent, Yann LeCun, and Yuandong Tian
Samy Jelassi, St´ ephane d’Ascoli, Carles Domingo-Enrich, Yuhuai Wu, Yuanzhi Li, and Fran¸ cois Charton. Length generalization in arithmetic transformers, 2023. URLhttps://arxiv.org/ abs/2306.15400
-
[19]
Transformers are minimax optimal nonparametric in-context learners
Juno Kim, Tai Nakamaki, and Taiji Suzuki. Transformers are minimax optimal nonparametric in-context learners. InICML 2024 Workshop on In-Context Learning, 2024. URLhttps: //openreview.net/forum?id=WjrKBQTWKp
2024
-
[20]
Transformers meet in- context learning: A universal approximation theory, 2025
Gen Li, Yuchen Jiao, Yu Huang, Yuting Wei, and Yuxin Chen. Transformers meet in- context learning: A universal approximation theory, 2025. URLhttps://arxiv.org/abs/ 2506.05200
-
[21]
Yue M. Lu, Mary Letey, Jacob A. Zavatone-Veth, Anindita Maiti, and Cengiz Pehlevan. Asymptotic theory of in-context learning by linear attention.Proceedings of the National Academy of Sciences, 122(28):e2502599122, 2025. doi: 10.1073/pnas.2502599122. URL https://www.pnas.org/doi/abs/10.1073/pnas.2502599122
-
[22]
Arvind Mahankali, Tatsunori B. Hashimoto, and Tengyu Ma. One step of gradient descent is provably the optimal in-context learner with one layer of linear self-attention, 2023. URL https://arxiv.org/abs/2307.03576
-
[23]
Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, Jonas Geiping, Avi Schwarzschild, and Tom Goldstein
Sean Michael McLeish, Arpit Bansal, Alex Stein, Neel Jain, John Kirchenbauer, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, Jonas Geiping, Avi Schwarzschild, and Tom Goldstein. Transformers can do arithmetic with the right embeddings. InThe 4th Workshop on Mathematical Reasoning and AI at NeurIPS’24, 2024. URLhttps://openreview.net/ forum?id=cBFsFt1nDW
2024
-
[24]
Analyzing limits for in-context learning, 2025
Omar Naim, Jerome Bolte, and Nicholas Asher. Analyzing limits for in-context learning, 2025. URLhttps://arxiv.org/abs/2502.03503
-
[25]
Understanding addition in transformers
Philip Quirke and Fazl Barez. Understanding addition in transformers. InThe Twelfth In- ternational Conference on Learning Representations, 2024. URLhttps://openreview.net/ forum?id=rIx1YXVWZb
2024
-
[26]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[27]
Daking Rai, Yilun Zhou, Shi Feng, Abulhair Saparov, and Ziyu Yao. A practical review of mechanistic interpretability for transformer-based language models.ArXiv, abs/2407.02646,
-
[28]
URLhttps://api.semanticscholar.org/CorpusID:270924412
-
[29]
Pretraining task diversity and the emergence of non-bayesian in-context learning for regression
Allan Raventos, Mansheej Paul, Feng Chen, and Surya Ganguli. Pretraining task diversity and the emergence of non-bayesian in-context learning for regression. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id= BtAz4a5xDg. 15
2023
-
[30]
Cambridge University Press, 2022
Shai Shalev-Shwartz and Shai Ben-David.Understanding machine learning: From theory to algorithms. Cambridge University Press, 2022
2022
-
[31]
Zhaiming Shen, Alex Havrilla, Rongjie Lai, Alexander Cloninger, and Wenjing Liao. Trans- formers for learning on noisy and task-level manifolds: Approximation and generalization insights, 2025. URLhttps://arxiv.org/abs/2505.03205
-
[32]
Understanding in-context learning on structured manifolds: Bridging attention to kernel methods
Zhaiming Shen, Alexander Hsu, Rongjie Lai, and Wenjing Liao. Understanding in-context learning on structured manifolds: Bridging attention to kernel methods, 2025. URLhttps: //arxiv.org/abs/2506.10959
-
[33]
A mechanistic interpretation of arithmetic reasoning in language models using causal mediation analysis
Alessandro Stolfo, Yonatan Belinkov, and Mrinmaya Sachan. A mechanistic interpretation of arithmetic reasoning in language models using causal mediation analysis. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023. URLhttps:// openreview.net/forum?id=aB3Hwh4UzP
2023
-
[34]
On the role of transformer feed-forward layers in nonlinear in-context learning, 2025
Haoyuan Sun, Ali Jadbabaie, and Navid Azizan. On the role of transformer feed-forward layers in nonlinear in-context learning, 2025. URLhttps://arxiv.org/abs/2501.18187
-
[35]
Approximation and estimation ability of transformers for sequence-to-sequence functions with infinite dimensional input
Shokichi Takakura and Taiji Suzuki. Approximation and estimation ability of transformers for sequence-to-sequence functions with infinite dimensional input. InInternational Conference on Machine Learning, pages 33416–33447. PMLR, 2023
2023
-
[36]
Joel A. Tropp. An introduction to matrix concentration inequalities.Foundations and Trends®in Machine Learning, 8(1-2):1–230, 2015. ISSN 1935-8237. doi: 10.1561/2200000048. URLhttp://dx.doi.org/10.1561/2200000048
-
[37]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Infor- mation Processing Systems, 2017
2017
-
[38]
Transformers learn in-context by gradient descent
Johannes Von Oswald, Eyvind Niklasson, Ettore Randazzo, Jo˜ ao Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. InInternational Conference on Machine Learning. PMLR, 2023
2023
-
[39]
Polynomial regression as a task for understanding in-context learning through fine- tuning and alignment
Max Wilcoxson, Morten Svendg˚ ard, Ria Doshi, Dylan Davis, Reya Vir, and Anant Sa- hai. Polynomial regression as a task for understanding in-context learning through fine- tuning and alignment. InICML 2024 Workshop on In-Context Learning, 2024. URL https://openreview.net/forum?id=8Xku9fR8dR
2024
-
[40]
Cohen, and Taylor Whittington Webb
Yukang Yang, Declan Iain Campbell, Kaixuan Huang, Mengdi Wang, Jonathan D. Cohen, and Taylor Whittington Webb. Emergent symbolic mechanisms support abstract reasoning in large language models. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=y1SnRPDWx4
2025
-
[41]
Error bounds for approximations with deep
Dmitry Yarotsky. Error bounds for approximations with deep relu networks.Neural Networks, 94:103–114, 2017. ISSN 0893-6080. doi: https://doi.org/10.1016/j.neunet.2017.07.002. URL https://www.sciencedirect.com/science/article/pii/S0893608017301545
-
[42]
Are transformers universal approximators of sequence-to-sequence functions? InInternational Conference on Learning Representations, 2019
Chulhee Yun, Srinadh Bhojanapalli, Ankit Singh Rawat, Sashank Reddi, and Sanjiv Kumar. Are transformers universal approximators of sequence-to-sequence functions? InInternational Conference on Learning Representations, 2019. 16
2019
-
[43]
Trained transformers learn linear models in-context.Journal of Machine Learning Research, 25(49), 2024
Ruiqi Zhang, Spencer Frei, and Peter L Bartlett. Trained transformers learn linear models in-context.Journal of Machine Learning Research, 25(49), 2024
2024
-
[44]
Latham, and Andrew M Saxe
Yedi Zhang, Aaditya K Singh, Peter E. Latham, and Andrew M Saxe. Training dynamics of in-context learning in linear attention. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=aFNq67ilos. 17 A Relevant Lemmas Below are two important lemmas used in the construction of the feature representation. We refer...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.