Recognition: 3 theorem links
· Lean TheoremLongSeeker: Elastic Context Orchestration for Long-Horizon Search Agents
Pith reviewed 2026-05-08 17:42 UTC · model grok-4.3
The pith
Search agents improve long-horizon performance by dynamically reshaping their context with five atomic operations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
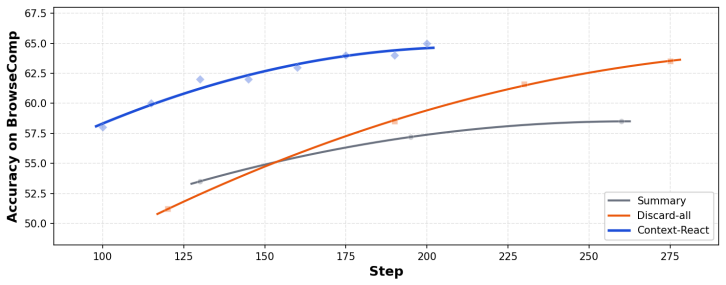
The paper establishes that effective context management for long-horizon search must be elastic, with parts of the trajectory kept at different levels of detail according to current relevance. Context-ReAct unifies reasoning, context management, and tool use in one loop and supplies five atomic operations: Skip, Compress, Rollback, Snippet, and Delete. The Compress operator is proven expressively complete, while the others supply efficiency and fidelity guarantees. LongSeeker, built by fine-tuning on 10k synthesized trajectories, demonstrates the approach by achieving 61.5% on BrowseComp and 62.5% on BrowseComp-ZH, substantially above Tongyi DeepResearch and AgentFold.
What carries the argument
Context-ReAct, the unified agentic loop that adds five atomic context operations (Skip, Compress, Rollback, Snippet, Delete) to the standard ReAct cycle so the agent can reshape its working context on the fly.
If this is right
- Agents preserve key evidence while summarizing resolved steps and discarding dead branches.
- Context size stays bounded, lowering generation cost and latency.
- Hallucination risk drops because the model attends only to currently relevant material.
- The same operations transfer across four different search benchmarks without task-specific redesign.
- Fine-tuning on 10k trajectories is sufficient to instill the elastic management behavior.
Where Pith is reading between the lines
- The five operations could be added to non-search agents such as code or planning systems that also face growing histories.
- Combining Context-ReAct with external retrieval might further reduce reliance on the model's internal memory.
- Real-world tests on live web sessions would reveal whether synthetic training data generalizes when tool outputs contain noise or change over time.
- Future agent designs may need built-in meta-reasoning to decide when to apply each operation automatically.
Load-bearing premise
The 10k synthesized trajectories are representative of real long-horizon search tasks and the observed gains come primarily from the Context-ReAct operations rather than other training details or the base model.
What would settle it
Train two otherwise identical agents on the same data, give one the five Context-ReAct operations and the other only standard context accumulation, and run both on the BrowseComp benchmarks; equal or lower scores for the Context-ReAct version would falsify the central claim.
Figures






read the original abstract
Long-horizon search agents must manage a rapidly growing working context as they reason, call tools, and observe information. Naively accumulating all intermediate content can overwhelm the agent, increasing costs and the risk of errors. We propose that effective context management should be adaptive: parts of the agent's trajectory are maintained at different levels of detail depending on their current relevance to the task. To operationalize this principle, we introduce Context-ReAct, a general agentic paradigm for elastic context orchestration that integrates reasoning, context management, and tool use in a unified loop. Context-ReAct provides five atomic operations: Skip, Compress, Rollback, Snippet and Delete, which allow the agent to dynamically reshape its working context, preserving important evidence, summarizing resolved information, discarding unhelpful branches, and controlling context size. We prove that the Compress operator is expressively complete, while the other specialized operators provide efficiency and fidelity guarantees that reduce generation cost and hallucination risk. Building on this paradigm, we develop LongSeeker, a long-horizon search agent fine-tuned from Qwen3-30B-A3B on 10k synthesized trajectories. Across four representative search benchmarks, LongSeeker achieves 61.5% on BrowseComp and 62.5% on BrowseComp-ZH, substantially outperforming Tongyi DeepResearch (43.2% and 46.7%) and AgentFold (36.2% and 47.3%). These results highlight the potential of adaptive context management, showing that agents can achieve more reliable and efficient long-horizon reasoning by actively shaping their working memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Context-ReAct, a unified agentic loop integrating reasoning, tool use, and five atomic context-management operations (Skip, Compress, Rollback, Snippet, Delete) to enable elastic orchestration in long-horizon search agents. It claims that Compress is expressively complete and that the other operators provide efficiency and fidelity guarantees. LongSeeker is obtained by fine-tuning Qwen3-30B-A3B on 10k synthesized trajectories and is reported to reach 61.5% on BrowseComp and 62.5% on BrowseComp-ZH, substantially outperforming Tongyi DeepResearch (43.2%/46.7%) and AgentFold (36.2%/47.3%) across four benchmarks.
Significance. If the performance deltas can be causally attributed to the Context-ReAct operators rather than the synthesis procedure or other training choices, the work would offer a practical and theoretically grounded approach to context management that could reduce token costs and error accumulation in long-horizon agents. The claimed expressiveness result for Compress, if accompanied by a formal model, would be a notable theoretical contribution.
major comments (3)
- [Experiments] Experiments / Results: The headline scores (61.5% BrowseComp, 62.5% BrowseComp-ZH) are obtained after fine-tuning on trajectories that already incorporate the five Context-ReAct operators, yet no ablation is reported that trains an otherwise identical model on the same 10k trajectories using only standard ReAct. Without this control, attribution of the observed gains to elastic orchestration remains unverified.
- [Method] Method / Theoretical claims: The statement that Compress is 'expressively complete' is presented without the underlying formal model of agent expressivity, the precise definition of completeness, or any proof sketch. Consequently the claimed efficiency and fidelity guarantees for the other operators cannot be evaluated.
- [Data Synthesis] Data synthesis: The 10k trajectories are central to the empirical result, but the manuscript provides no statistics on their horizon lengths, branching factors, or tool-use distributions, nor any quantitative check that they are representative of real long-horizon search tasks. This leaves open the possibility that the synthesis procedure itself embeds the advantages being tested.
minor comments (2)
- [Abstract] Abstract: Only two of the four 'representative search benchmarks' are named; the remaining two should be identified so readers can assess coverage.
- [Method] Notation: The five operators are introduced without a compact tabular summary of their preconditions, effects, and cost/fidelity trade-offs; such a table would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the empirical attribution, theoretical presentation, and data transparency. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: The headline scores (61.5% BrowseComp, 62.5% BrowseComp-ZH) are obtained after fine-tuning on trajectories that already incorporate the five Context-ReAct operators, yet no ablation is reported that trains an otherwise identical model on the same 10k trajectories using only standard ReAct. Without this control, attribution of the observed gains to elastic orchestration remains unverified.
Authors: We agree that the current results do not isolate the contribution of the Context-ReAct operators from the synthesis procedure. In the revised manuscript we will add an ablation study that fine-tunes an otherwise identical Qwen3-30B-A3B model on the exact same 10k trajectories but using only standard ReAct actions (no Skip/Compress/Rollback/Snippet/Delete). The new results will be reported alongside the original numbers to enable direct causal attribution. revision: yes
-
Referee: The statement that Compress is 'expressively complete' is presented without the underlying formal model of agent expressivity, the precise definition of completeness, or any proof sketch. Consequently the claimed efficiency and fidelity guarantees for the other operators cannot be evaluated.
Authors: We acknowledge that the main text does not supply the formal model or proof details. The revised version will include a dedicated subsection (or appendix) that (i) defines the formal model of agent expressivity, (ii) states the precise definition of expressive completeness, and (iii) provides a proof sketch that Compress is expressively complete, together with the efficiency and fidelity arguments for the remaining operators. revision: yes
-
Referee: The 10k trajectories are central to the empirical result, but the manuscript provides no statistics on their horizon lengths, branching factors, or tool-use distributions, nor any quantitative check that they are representative of real long-horizon search tasks. This leaves open the possibility that the synthesis procedure itself embeds the advantages being tested.
Authors: We will expand the data-synthesis section with a new table and accompanying text that reports (a) distributions of trajectory horizon lengths and branching factors, (b) tool-use frequency statistics, and (c) quantitative comparisons against characteristics of real long-horizon search tasks drawn from the evaluation benchmarks. These additions will allow readers to assess representativeness directly. revision: yes
Circularity Check
No significant circularity; empirical results and stated proof do not reduce to self-definition
full rationale
The paper's central claims rest on an empirical pipeline: synthesis of 10k trajectories, fine-tuning of Qwen3-30B-A3B, and benchmark evaluation yielding 61.5% / 62.5% on BrowseComp variants. The abstract states a proof that the Compress operator is expressively complete, yet no equations, formal model, or derivation steps are supplied that would allow inspection for self-referential reduction. No fitted parameters are relabeled as predictions, no self-citation chain is invoked to justify uniqueness or ansatz, and the performance numbers are direct experimental outcomes rather than quantities algebraically forced by the input definitions. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Context-ReAct paradigm
no independent evidence
Lean theorems connected to this paper
-
Cost.FunctionalEquation (washburn_uniqueness_aczel)washburn_uniqueness_aczel unclearTheorem 3.1 (Expressive Completeness). The meta-action set O = {SKIP, COMPRESS, ROLLBACK, SNIPPET, DELETE} is expressively complete... COMPRESS(H,1,|H|,Σ) replaces the entire history H with an arbitrary string Σ.
Reference graph
Works this paper leans on
-
[1]
URL https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild-tss/ ljhwZthlaukjlkulzlp/seed2/0214/Seed2.0%20Model%20Card.pdf. Guoxin Chen, Zile Qiao, Xuanzhong Chen, Donglei Yu, Haotian Xu, Wayne Xin Zhao, Ruihua Song, Wenbiao Yin, Huifeng Yin, Liwen Zhang, Kuan Li, Minpeng Liao, Yong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. Iterresearch: Rethinking l...
-
[2]
10 Kaiyuan Chen, Yixin Ren, Yang Liu, Xiaobo Hu, Haotong Tian, Tianbao Xie, Fangfu Liu, Haoye Zhang, Hongzhang Liu, Yuan Gong, et al. xbench: Tracking agents productivity scaling with profession-aligned real-world evaluations.arXiv preprint arXiv:2506.13651,
-
[3]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
URL https: //arxiv.org/abs/2512.02556. Yuwen Du, Rui Ye, Shuo Tang, Keduan Huang, Xinyu Zhu, Yuzhu Cai, and Siheng Chen. Openseeker-v2: Pushing the limits of search agents with informative and high-difficulty trajectories.arXiv preprint arXiv:2605.04036, 2026a. Yuwen Du, Rui Ye, Shuo Tang, Xinyu Zhu, Yijun Lu, Yuzhu Cai, and Siheng Chen. Openseeker: Democ...
work page internal anchor Pith review arXiv
-
[4]
URL http: //arxiv.org/abs/math/0406077. Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, Weizhou Shen, Junkai Zhang, Dingchu Zhang, Xixi Wu, Yong Jiang, Ming Yan, Pengjun Xie, Fei Huang, and Jingren Zhou. Websailor: Navigating super-human reasoning for web agent,
-
[5]
Websailor: Navigating super-human reasoning for web agent.arXiv preprint arXiv:2507.02592, 2025
URLhttps://arxiv.org/abs/2507.02592. Miao Lu, Weiwei Sun, Weihua Du, Zhan Ling, Xuesong Yao, Kang Liu, and Jiecao Chen. Scaling llm multi-turn rl with end-to-end summarization-based context management,
-
[6]
Scaling llm multi-turn rl with end-to-end summarization-based context management
URL https: //arxiv.org/abs/2510.06727. Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants,
-
[7]
URL https://cdn.openai.com/ deep-research-system-card.pdf. OpenAI. Deep research system card, February 2025a. URL https://cdn.openai.com/ deep-research-system-card.pdf. OpenAI. Gpt-5 system card, 2025b. URLhttps://arxiv.org/abs/2601.03267. Jorma Rissanen. Modeling by shortest data description.Automatica, 14(5):465–471,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2504.16855 , year=
URLhttps://arxiv.org/abs/2504.16855. MiroMind Team, S. Bai, L. Bing, L. Lei, R. Li, X. Li, X. Lin, E. Min, L. Su, B. Wang, L. Wang, L. Wang, S. Wang, X. Wang, Y . Zhang, Z. Zhang, G. Chen, L. Chen, Z. Cheng, Y . Deng, Z. Huang, D. Ng, J. Ni, Q. Ren, X. Tang, B.L. Wang, H. Wang, N. Wang, C. Wei, Q. Wu, J. Xia, Y . Xiao, H. Xu, X. Xu, C. Xue, Z. Yang, Z. Ya...
-
[9]
URL https://arxiv.org/abs/2603.15726. 11 Tongyi DeepResearch Team, Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, Kuan Li, Liangcai Su, Litu Ou, Liwen Zhang, Pengjun Xie, Rui Ye, Wenbiao Yin, Xinmiao Yu, Xinyu Wang, Xixi Wu, Xuanzhong Chen, Yida Zhao, Zhen Zhang, Zhengwei Tao, Zhongwang Zhan...
-
[10]
Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701, 2025
URL https://arxiv.org/abs/2510.24701. Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516, 2025a. Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeff...
-
[11]
URL https://arxiv.org/abs/2505.09388. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models,
work page internal anchor Pith review arXiv
-
[12]
ReAct: Synergizing Reasoning and Acting in Language Models
URL https://arxiv.org/abs/ 2210.03629. Yilun Yao, Shan Huang, Elsie Dai, Zhewen Tan, Zhenyu Duan, Shousheng Jia, Yanbing Jiang, and Tong Yang. Arc: Active and reflection-driven context management for long-horizon information seeking agents,
work page internal anchor Pith review arXiv
-
[13]
URLhttps://arxiv.org/abs/2601.12030. Rui Ye, Zhongwang Zhang, Kuan Li, Huifeng Yin, Zhengwei Tao, Yida Zhao, Liangcai Su, Liwen Zhang, Zile Qiao, Xinyu Wang, Pengjun Xie, Fei Huang, Siheng Chen, Jingren Zhou, and Yong Jiang. Agentfold: Long-horizon web agents with proactive context management,
-
[14]
URL https: //arxiv.org/abs/2510.24699. Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei- Ying Ma, Jingjing Liu, Mingxuan Wang, and Hao Zhou. Memagent: Reshaping long-context llm with multi-conv rl-based memory agent,
-
[15]
URLhttps://arxiv.org/abs/2507.02259. Chu Zheng, Xiao Wang, Jack Hong, Huiming Fan, Yuqi Huang, Yue Yang, Guohai Xu, Chenxiao Zhao, Cheng Xiang, Shengchao Hu, Dongdong Kuang, Ming Liu, Bing Qin, and Xing Yu. Redsearcher: A scalable and cost-efficient framework for long-horizon search agents.arXiv preprint arXiv:2602.14234,
-
[16]
URL https://z.ai/blog/ glm-4.7. 12 Peilin Zhou, Bruce Leon, Xiang Ying, Can Zhang, Yifan Shao, Qichen Ye, Dading Chong, Zhiling Jin, Chenxuan Xie, Meng Cao, Yuxin Gu, Sixin Hong, Jing Ren, Jian Chen, Chao Liu, and Yining Hua. Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese, 2025a. URL https://arxiv.org/abs/2504.19314. ...
-
[17]
name": "search_web
for each candidate landlocked African country with at least two landlockedneighbors. The results show that for most countries, the increase from 2014 to 2022 is not 1.16%. However, Zimbabwe's literacy rate increased from 88.7% in 2014 to 89.85% in 2022, a rise of 1.15% (very close to 1.16%, possibly rounding). Other candidates like Uganda, Rwanda, Zambia,...
2014
-
[18]
it is home to a species from the Family Chamaeleonidaenamed after the individual who collected its holotype
[Chamaeleodilepis-The Reptile Database -Reptarium] Taxonomic database that provides basic information about all living reptile species, such as turtles, snakes, lizards, and crocodiles, as well as tuataras ... Managed Context Figure 6: Complete case study showing managed context at a reasoning step. The trajectory demonstrates the combined effect of COMPR...
2014
-
[19]
Find literacy rate data for Zimbabwe in 2014 and 2022 to verify 1.16%increase
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.