Recognition: no theorem link
DisastRAG: A Multi-Source Disaster Information Integration and Access System Based on Retrieval-Augmented Large Language Models
Pith reviewed 2026-05-11 02:27 UTC · model grok-4.3
The pith
DisastRAG routes disaster queries across documents, records, and web sources to raise LLM accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DisastRAG is a multi-path architecture that supports document retrieval over a curated hazard corpus, structured access over relational disaster records, and external web fallback for out-of-corpus requests, while incorporating query understanding, strategy routing, response generation, and contextual memory within a unified system. Retrieval augmentation consistently improves performance over no-retrieval baselines, yielding multiple-choice gains of 12-23 percentage points and open-ended keypoint coverage gains of up to 10.5 percentage points across four open-source large language models on disaster information tasks.
What carries the argument
The multi-path architecture with query understanding, strategy routing, document retrieval, structured database access, web fallback, response generation, and contextual memory.
If this is right
- Larger candidate pools help weaker models more than stronger ones.
- Stronger models are more sensitive to retrieval noise.
- Hybrid retrieval performs best for open-ended coverage while vector retrieval favors closed-form factual selection.
- Structured access and web fallback extend the framework beyond document-only RAG.
- Retrieval strategy choice should depend on both model capability and task type.
Where Pith is reading between the lines
- The routing mechanism could be tested on live sensor feeds during active events to check real-time utility.
- Similar multi-source designs may apply to other domains that mix structured logs with unstructured reports, such as public health surveillance.
- Noise sensitivity in stronger models points to a need for better reranking that the current results leave open for future tuning.
- The gains suggest domain-specific routing layers can be added to general RAG systems to handle context-dependent queries more reliably.
Load-bearing premise
The curated hazard corpus, relational records, and evaluation tasks accurately represent real-world disaster information needs and that the improvements generalize beyond the tested models and configurations.
What would settle it
Running DisastRAG on queries drawn from an actual recent disaster event and measuring agreement with independent expert-verified answers from official field reports.
Figures




read the original abstract
Effective disaster management requires rapid access to information distributed across structured operational records, unstructured institutional documents, and dynamic external sources. However, most existing disaster information systems and retrieval-augmented generation frameworks remain organized around a single access pathway, limiting their ability to support heterogeneous, time-sensitive, and context-dependent information needs. This study presents DisastRAG, a disaster-aware information integration and access system that combines large language models with retrieval-augmented access to structured, unstructured, and contextual disaster information. The framework is built around a multi-path architecture that supports document retrieval over a curated hazard corpus, structured access over relational disaster records, and external web fallback for out-of-corpus requests, while also incorporating query understanding, strategy routing, response generation, and contextual memory within a unified system. We evaluated the document retrieval performance using four open-source large language models across multiple retrieval configurations on multiple-choice and open-ended disaster information tasks. Retrieval augmentation consistently improves performance over no-retrieval baselines, yielding multiple-choice gains of 12-23 percentage points and open-ended keypoint coverage gains of up to 10.5 percentage points. Results show that larger candidate pools are most helpful for weaker models, while stronger models are more sensitive to retrieval noise. Hybrid retrieval performs best for open-ended coverage, whereas vector retrieval and shallower reranking more often favor closed-form factual selection. Case studies further show that structured access and web fallback extend the framework beyond document-only RAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DisastRAG, a multi-path RAG framework for disaster information that integrates document retrieval over a curated hazard corpus, structured relational record access, and web fallback, combined with query understanding, routing, generation, and memory. It evaluates the system on multiple-choice and open-ended disaster tasks using four open-source LLMs, reporting consistent gains from retrieval augmentation (12-23 pp on multiple-choice, up to 10.5 pp on open-ended keypoint coverage) and differential effects of retrieval strategies and model strength.
Significance. If the empirical results hold under fuller scrutiny, the work provides concrete evidence that hybrid retrieval strategies can improve LLM performance on heterogeneous, time-sensitive domain tasks like disaster management. The use of multiple open-source models, comparison of vector/hybrid/shallow reranking, and inclusion of structured and external pathways are strengths that could inform practical RAG deployments; however, the limited task scope and lack of external validation limit broader claims about real-world generalization.
major comments (2)
- [Evaluation] Evaluation section (around the reported experiments on multiple-choice and open-ended tasks): the 12-23 pp gains and 10.5 pp coverage improvements are presented without accompanying error bars, statistical significance tests, or per-question breakdowns, making it impossible to determine whether the improvements are robust or driven by a small subset of items; this directly affects the central claim that retrieval augmentation 'consistently improves performance'.
- [Methods] Methods and data description (corpus curation and task construction): the paper does not provide sufficient detail on how the hazard corpus, relational records, or the multiple-choice/open-ended questions were constructed or validated against real disaster information needs, which undermines assessment of whether the weakest assumption (representativeness) holds and whether the observed gains would generalize.
minor comments (2)
- [Results] The abstract and results text refer to 'keypoint coverage' without defining the metric or annotation protocol in the main text; a brief formal definition or reference to an appendix would improve clarity.
- [Figures/Tables] Figure captions and table headers for the retrieval configuration comparisons could be expanded to explicitly list the four LLMs and the exact candidate pool sizes tested.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the presentation of our results and methods.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (around the reported experiments on multiple-choice and open-ended tasks): the 12-23 pp gains and 10.5 pp coverage improvements are presented without accompanying error bars, statistical significance tests, or per-question breakdowns, making it impossible to determine whether the improvements are robust or driven by a small subset of items; this directly affects the central claim that retrieval augmentation 'consistently improves performance'.
Authors: We agree that the absence of error bars, statistical tests, and per-question breakdowns limits the ability to fully assess robustness. In the revised manuscript we will add error bars (computed via bootstrap resampling or multiple random seeds where applicable) to all reported gains. We will also include statistical significance tests (e.g., paired t-tests or McNemar’s test for multiple-choice accuracy) between retrieval-augmented and baseline conditions, reporting p-values and effect sizes. A supplementary per-question breakdown or heatmap will be added to demonstrate that gains are distributed across the task set rather than concentrated in a small number of items. revision: yes
-
Referee: [Methods] Methods and data description (corpus curation and task construction): the paper does not provide sufficient detail on how the hazard corpus, relational records, or the multiple-choice/open-ended questions were constructed or validated against real disaster information needs, which undermines assessment of whether the weakest assumption (representativeness) holds and whether the observed gains would generalize.
Authors: We acknowledge that additional detail on data construction is needed to support claims of representativeness. In the revised version we will expand the Methods section with: (1) explicit sources, filtering criteria, and size statistics for the curated hazard corpus; (2) schema and population details for the relational disaster records; and (3) the question-generation protocol for both multiple-choice and open-ended tasks, including any use of historical disaster reports, expert templates, or validation steps (e.g., review by domain practitioners). These additions will clarify how the evaluation tasks align with real-world information needs. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a multi-path RAG architecture for disaster information retrieval and reports empirical evaluation results on multiple-choice and open-ended tasks using four open-source LLMs. Performance gains are measured directly against no-retrieval baselines on external tasks and models. No equations, derivations, or self-referential definitions appear in the provided text; the central claims rest on independent empirical comparisons rather than any reduction to fitted inputs, self-citations, or ansatzes by construction. The evaluation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2021, Camps-Valls, Fernández-Torres et al
Introduction Disaster management increasingly depends on the ability to access, synthesize, and interpret information from multiple heterogeneous sources under severe time constraints (Fan, Zhang et al. 2021, Camps-Valls, Fernández-Torres et al. 2025). During an unfolding event, decision-makers must move rapidly across structured records (e.g., power outa...
work page 2021
-
[2]
Related Work 2.1 Disaster Informatics and Disaster Information Systems Disaster informatics refers to the study of how information is generated, organized, transmitted, understood, and used throughout the disaster management lifecycle (Yang, Zhang et al. 2020). Prior research has established that disaster information environments are inherently complex, a...
work page 2020
-
[3]
System Architecture 3.1 Overview The proposed system is a disaster-aware framework for information integration and access, built upon an LLM-powered, retrieval-augmented architecture. The framework coordinates five functional components: (1) multi-source knowledge foundation, (2) query understanding and strategy routing, (3) evidence-access pathways, (4) ...
work page 2017
-
[4]
- the predicted answer. MCQ accuracy is defined as Equation 1: 33 𝐴𝑐𝑐#$%= 1𝑁11[& !'(𝑦
Experimental Design 4.1 Evaluation Scope The study adopts a two-part evaluation design that reflects the different roles of components within the overall framework. The primary quantitative focus is the retrieval and reranking pipeline, which serves as the core evidence-grounding mechanism of the document retrieval branch. Specifically, the evaluation com...
work page 2026
-
[5]
Quantitative Results 5.1 MCQ Performance Across Retrieval Configurations Figure 6 presents MCQ accuracy under multiple retrieval configurations for four LLM backbones. The three subplots correspond to vector, hybrid, and keyword retrieval, respectively, and dashed horizontal lines indicate the corresponding no-retrieval baseline for each model. Table 1 su...
-
[6]
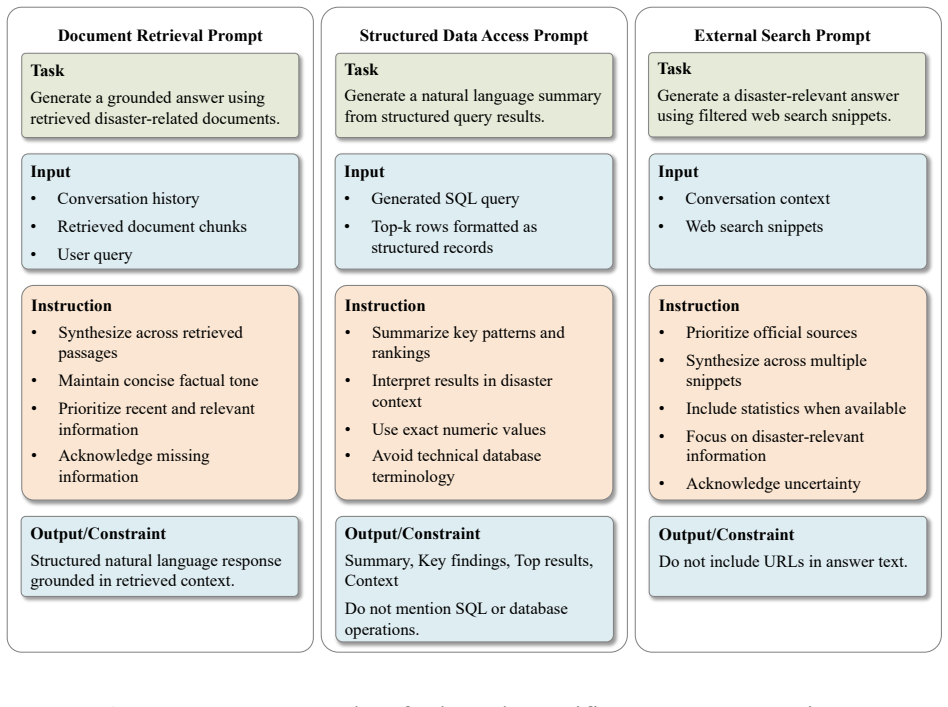
Case Studies of System-Oriented Disaster Information Access 6.1 Case Design and Presentation Format The quantitative evaluation in Section 5 focuses on the document retrieval branch, while the broader architecture also includes additional evidence-access pathways designed for request types that the document retrieval pipeline alone cannot adequately addre...
-
[7]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Discussion and Concluding Remarks This paper presented DisastRAG, a disaster-oriented framework for information integration and access built on an LLM-powered, retrieval-augmented architecture. This study aims to address a disaster management challenge that relevant information is fragmented across heterogeneous sources, and remains difficult to access an...
work page internal anchor Pith review arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.