Recognition: 3 theorem links
· Lean TheoremSecureMCP: A Policy-Enforced LLM Data Access Framework for AIoT Systems via Model Context Protocol
Pith reviewed 2026-05-08 17:49 UTC · model grok-4.3
The pith
SecureMCP enforces multi-layer policy control on LLM-generated SQL queries in AIoT systems using five sequential defense modules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SecureMCP establishes a policy-enforced LLM data access framework by combining RBAC with an MCP server. Its five defense modules—check_policy for RBAC checks, explain_gate for cost control, SQL Interceptor for pattern detection, Risk Level Filter for risk assessment, and DB Isolation for database restrictions—form a sequential fail-closed pipeline mapped to prompt injection types. Evaluation on the IoT-SQL dataset using Qwen3-8B shows preserved accuracy and 82.3% compliance on adversarial queries, with check_policy driving most blocks and an overall injection incorporation rate of 72.5%.
What carries the argument
The five defense modules operating in a sequential fail-closed pipeline mapped to OWASP Top 10 LLM injection types.
If this is right
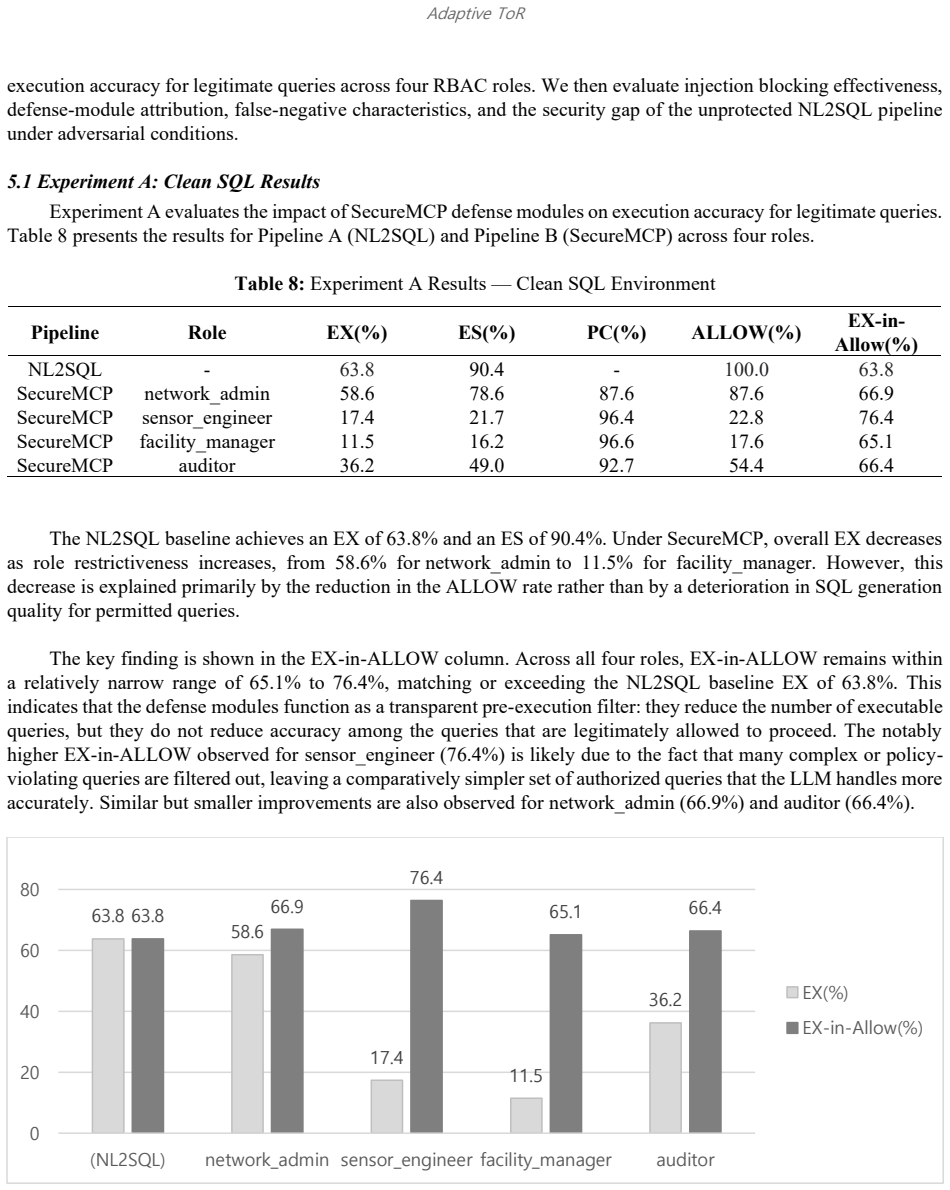
- The modules preserve execution accuracy with EX-in-ALLOW rates of 65.1% to 76.4% matching the 63.8% baseline.
- check_policy accounts for 78.7% of blocks with secondary modules adding 17.5 percentage points of improvement.
- The 72.5% Injection Incorporation Rate establishes the necessity of external policy enforcement.
- The framework provides multi-layer defense for LLM-generated SQL execution in AIoT systems.
Where Pith is reading between the lines
- This pipeline structure might apply to securing other LLM tool calls or API interactions beyond AIoT SQL queries.
- Real-world deployment would require verifying that false positive rates do not hinder legitimate operations in dynamic AIoT settings.
- The defense could be extended by incorporating machine learning for detecting novel injection patterns not covered by the current modules.
Load-bearing premise
The five defense modules will adequately cover real-world prompt injection attacks without causing unacceptable false positives or performance overhead in production AIoT environments.
What would settle it
Running the system against a set of newly crafted prompt injection attacks that bypass the OWASP-mapped categories and observing whether policy compliance falls substantially below 82.3% or genuine failures exceed 3.4%.
Figures
read the original abstract
The deployment of Large Language Model (LLM)-generated SQL queries in Artificial Intelligence of Things (AIoT) systems introduces critical security risks, as prompt injection attacks can manipulate LLMs into producing unauthorized queries that expose sensitive data or execute destructive operations. Existing NL2SQL research focuses on query accuracy, while MCP server implementations provide only SQL-level protections without fine-grained role-based access control. This paper proposes SecureMCP, a policy-enforced LLM data access framework integrating Role-Based Access Control (RBAC) with an MCP server to establish multi-layer defense for LLM-generated SQL execution. The framework incorporates five defense modules -- check_policy for table-and-column-level RBAC, explain_gate for cost-explosive query blocking, SQL Interceptor for dangerous pattern detection, Risk Level Filter for SQL risk classification, and DB Isolation for cross-database restriction -- operating in a sequential fail-closed pipeline mapped to six prompt injection types grounded in the OWASP Top 10 for LLM Applications. We evaluate SecureMCP on the IoT-SQL dataset (11 tables, 173 columns, 239,398 records) using Qwen3-8B. Experiment A demonstrates that defense modules preserve execution accuracy, with EX-in-ALLOW remaining within 65.1%-76.4% across four RBAC roles, matching the unprotected baseline of 63.8%. Experiment B shows that SecureMCP achieves 82.3% Policy Compliance on 2,400 adversarial queries, with genuine defense failures limited to 3.4%. The defense-in-depth analysis reveals check_policy accounts for 78.7% of blocks, while secondary modules contribute an additional 17.5 percentage-point improvement. The Injection Incorporation Rate of 72.5% confirms high LLM susceptibility, establishing the necessity of external policy enforcement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SecureMCP, a framework integrating RBAC with an MCP server for multi-layer defense of LLM-generated SQL queries in AIoT systems. It deploys five modules (check_policy, explain_gate, SQL Interceptor, Risk Level Filter, DB Isolation) in a sequential fail-closed pipeline explicitly mapped to six OWASP Top 10 LLM injection types. On the IoT-SQL dataset (11 tables, 173 columns, 239,398 records) with Qwen3-8B, Experiment A reports that the modules preserve execution accuracy (EX-in-ALLOW 65.1%-76.4% across RBAC roles vs. 63.8% unprotected baseline), while Experiment B reports 82.3% Policy Compliance on 2,400 adversarial queries with 3.4% genuine failures, 78.7% blocks from check_policy, and 72.5% Injection Incorporation Rate.
Significance. If the central evaluation holds, the work supplies a practical, implemented defense-in-depth architecture for LLM data access in AIoT that demonstrates external policy enforcement can mitigate prompt injection while retaining utility. The module-contribution breakdown and concrete metrics on a named dataset and model are useful for practitioners. The result is tempered by the need to confirm that the adversarial test set is independent of the OWASP categories used to design the modules.
major comments (1)
- [Experiment B] Experiment B (evaluation on 2,400 adversarial queries): the manuscript states that the queries are mapped to the six OWASP Top 10 LLM injection types that the five defense modules target, yet provides no description of query generation, selection criteria, or statistical validation. If query construction followed the same category mapping, the reported 82.3% Policy Compliance and 3.4% genuine-failure rate largely test the fidelity of the module-to-attack mapping rather than generalization to adaptive or out-of-distribution attacks. This directly affects the load-bearing claim that the sequential fail-closed pipeline supplies robust defense-in-depth.
minor comments (3)
- [Experiment A] The abstract and evaluation sections report accuracy ranges (65.1%-76.4%) and compliance percentages without accompanying variance, confidence intervals, or statistical tests; adding these would strengthen the claim that accuracy is preserved.
- [Evaluation] No discussion of runtime overhead or latency introduced by the five-module sequential pipeline appears in the evaluation; this is relevant for production AIoT constraints even if not central to the security claims.
- [Related Work] The paper would benefit from explicit comparison to prior MCP server protections and other prompt-injection defenses beyond the OWASP reference.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment on Experiment B below and will revise the paper to strengthen the presentation of the adversarial evaluation.
read point-by-point responses
-
Referee: [Experiment B] Experiment B (evaluation on 2,400 adversarial queries): the manuscript states that the queries are mapped to the six OWASP Top 10 LLM injection types that the five defense modules target, yet provides no description of query generation, selection criteria, or statistical validation. If query construction followed the same category mapping, the reported 82.3% Policy Compliance and 3.4% genuine-failure rate largely test the fidelity of the module-to-attack mapping rather than generalization to adaptive or out-of-distribution attacks. This directly affects the load-bearing claim that the sequential fail-closed pipeline supplies robust defense-in-depth.
Authors: We acknowledge that the current manuscript provides insufficient detail on how the 2,400 adversarial queries were generated and selected. The queries were constructed via LLM prompting using templates explicitly aligned with the six OWASP LLM injection categories to ensure coverage of the attack types targeted by our modules. In the revised version, we will add a new subsection under Experiment B that describes: (1) the exact prompt templates and generation procedure for each category; (2) the selection and balancing criteria used to reach 2,400 queries; and (3) any post-generation validation or diversity checks performed. While this evaluation is intentionally scoped to the OWASP-derived categories for which the modules were designed, the observed 3.4% genuine-failure rate and the incremental contribution of secondary modules (17.5 percentage points) provide evidence that the fail-closed pipeline offers defense-in-depth beyond simple one-to-one mapping. We will also clarify the distinction between targeted-category testing and broader generalization in the discussion section. revision: yes
Circularity Check
No significant circularity; evaluation uses external dataset and model runs
full rationale
The paper's central claims rest on empirical measurements from the external IoT-SQL dataset (11 tables, 173 columns, 239,398 records) and Qwen3-8B model executions rather than any self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. The five defense modules are explicitly mapped to OWASP categories for design purposes, but the 82.3% Policy Compliance and 3.4% failure rates are reported as outcomes of running the sequential pipeline on 2,400 adversarial queries; these metrics are not shown to be constructed by definition from the module mappings themselves. No equations, uniqueness theorems, or ansatzes are invoked that reduce the results to the inputs by construction. The derivation chain is therefore self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Foundation.RealityFromDistinction (forcing chain target: physical structure, not access policy)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SecureMCP, a policy-enforced LLM data access framework integrating Role-Based Access Control (RBAC) with an MCP server to establish multi-layer defense for LLM-generated SQL execution
-
Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
five defense modules ... operating in a sequential fail-closed pipeline mapped to six prompt injection types grounded in the OWASP Top 10
-
Foundation.AlphaDerivationExplicit (parameter-free constants vs. hand-tuned engineering thresholds)alphaProvenanceCert unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
explain_gate ... threshold of 500,000 rows ... SQL Interceptor ... maximum SQL length of 2,000 characters
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Internet of Things (IoT): A vision, architectural elements, and future directions
Gubbi J, Buyya R, Marusic S, Palaniswami M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener Comput Syst. 2013;29(7):1645–60. doi:10.1016/j.future.2013.01.010
-
[2]
Artificial intelligence of things: A comprehensive review
Alam T, Alharbi S, Fazio M. Artificial intelligence of things: A comprehensive review. J Artif Intell Things. 2024;1(1):1–24
2024
-
[3]
Constructing an interactive natural language interface for relational databases
Li F, Jagadish HV. Constructing an interactive natural language interface for relational databases. Proc VLDB Endow. 2014;8(1):73–84. doi:10.14778/2735461.2735468
-
[4]
A survey on deep learning approaches for text -to-SQL
Katsogiannis-Meimarakis G, Koutrika G. A survey on deep learning approaches for text -to-SQL. VLDB J. 2023;32(4):905–36. doi:10.1007/s00778-022-00776-8
-
[5]
Text -to-SQL empowered by large language models: A benchmark evaluation
Gao D, Wang H, Li Y, Sun X, Qian Y, Ding B, et al. Text -to-SQL empowered by large language models: A benchmark evaluation. Proc VLDB Endow. 2024;17(5):1132–45
2024
-
[6]
Spider: A large -scale human -labeled dataset for Adaptive ToR 19 complex and cross -database semantic parsing and text -to-SQL task
Yu T, Zhang R, Yang K, Yasunaga M, Wang D, Li Z, et al. Spider: A large -scale human -labeled dataset for Adaptive ToR 19 complex and cross -database semantic parsing and text -to-SQL task. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP); 2018 Oct 31 –Nov 4; Brussels, Belgium. p. 3911–21
2018
-
[7]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
Zhong V, Xiong C, Socher R. Seq2SQL: Generating structured queries from natural language using reinforcement learning. arXiv preprint arXiv:1709.00103. 2017
work page internal anchor Pith review arXiv 2017
-
[8]
Can LLM already serve as a database interface? A big bench for large- scale database grounded text -to-SQLs
Li J, Hui B, Qu G, Yang J, Li B, Li B, et al. Can LLM already serve as a database interface? A big bench for large- scale database grounded text -to-SQLs. In: Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS); 2023
2023
-
[9]
Prompt -to-SQL injections in LLM -integrated web applications: Risks and defenses
Pedro R, Coimbra ME, Castro D, Carreira P, Santos N. Prompt -to-SQL injections in LLM -integrated web applications: Risks and defenses. In: Proceedings of the 47th IEEE/ACM International Conference on Software Engineering (ICSE); 2025 Apr 27–May 3; Ottawa, Canada. doi:10.1109/ICSE55347.2025.00007
-
[10]
A survey on large language model (LLM) security and privacy: The good, the bad, and the ugly
Yao Y, Duan J, Xu K, Cai Y, Sun Z, Zhang Y. A survey on large language model (LLM) security and privacy: The good, the bad, and the ugly. High-Confidence Comput. 2024;4(2):100211. doi:10.1016/j.hcc.2024.100211
-
[11]
Security, privacy and trust in Internet of Things: The road ahead
Sicari S, Rizzardi A, Grieco LA, Coen -Porisini A. Security, privacy and trust in Internet of Things: The road ahead. Comput Netw. 2015;76:146–64. doi:10.1016/j.comnet.2014.11.008
-
[12]
Salim MM, Deng X, Park JH. A privacy-preserving local differential privacy-based federated learning model to secure LLM from adversarial attacks. Hum-centric Comput Inf Sci. 2024;14:57. doi:10.22967/HCIS.2024.14.057
-
[13]
Generation of impact factor -driven security rating questionnaire using LLMs for AIoT applications
Han Y, Shim S, Gajulamandyam DK, Choi Y, Lee H, Chang H. Generation of impact factor -driven security rating questionnaire using LLMs for AIoT applications. Hum -centric Comput Inf Sci. 2026;16:6. doi:10.22967/HCIS.2026.16.006
-
[14]
Xiang Y, Bai J, Liu J, Li Y, Li B. Are your LLM -based text-to-SQL models secure? Exploring SQL injection vulnerabilities via backdoor attacks. ACM Trans Priv Secur. 2025;28(3):1 –30. doi:10.1145/3769762
-
[15]
Introducing the Model Context Protocol [Internet]
Anthropic. Introducing the Model Context Protocol [Internet]. San Francisco, CA, USA: Anthropic; 2024 Nov [cited 2025 Jan 15]. Available from: https://www.anthropic.com/news/model-context-protocol
2024
-
[16]
MCP vulnerability case study: SQL injection in the Postgres MCP server [Internet]
Mola S. MCP vulnerability case study: SQL injection in the Postgres MCP server [Internet]. Datadog Security Labs; 2025 Aug 21 [cited 2025 Dec 1]. Available from: https://securitylabs.datadoghq.com/articles/mcp- vulnerability-case-study-SQL-injection-in-the-postgresql-mcp-server/
2025
-
[17]
mysql -mcp-server-sse: MySQL query server based on MCP framework with multi-level SQL risk control and injection protection [Internet]
mangooer [GitHub username]. mysql -mcp-server-sse: MySQL query server based on MCP framework with multi-level SQL risk control and injection protection [Internet]. GitHub; 2025 [cited 2025 Dec 1]. Available from: https://github.com/mangooer/mysql-mcp-server-sse
2025
-
[18]
OWASP Top 10 for large language model applications v2.0 [Internet]
OWASP Foundation. OWASP Top 10 for large language model applications v2.0 [Internet]. 2025 [cited 2025 Jan 15]. Available from: https://owasp.org/www-project-top-10-for-large-language-model-applications/
2025
-
[19]
IoT -SQL dataset: A benchmark for text - to-SQL and IoT threat classification [Internet]
Pavlich R, Ebadi N, Tarbell R, Linares B, Tan A, Humphreys R, et al. IoT -SQL dataset: A benchmark for text - to-SQL and IoT threat classification [Internet]. Zenodo; 2025 Mar 10 [cited 2025 Apr 1]. Available from: https://zenodo.org/records/15000588. doi:10.5281/zenodo.15000588
-
[20]
IoT -23: A labeled dataset with malicious and benign IoT network traffic [Internet]
Garcia S, Parmisano A, Erquiaga MJ. IoT -23: A labeled dataset with malicious and benign IoT network traffic [Internet]. Zenodo; 2020 [cited 2025 Jan 10]. Available from: https://www.stratosphereips.org/datasets-iot23
2020
-
[21]
Natural language interfaces to databases: An introduction
Androutsopoulos I, Ritchie GD, Thanisch P. Natural language interfaces to databases: An introduction. Nat Lang Eng. 1995;1(1):29–81. doi:10.1017/S135132490000098X
-
[22]
DIN -SQL: Decomposed in -context learning of text -to-SQL with self -correction
Pourreza M, Rafiei D. DIN -SQL: Decomposed in -context learning of text -to-SQL with self -correction. In: Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS); 2023. p. 36339 –48
2023
-
[23]
C3: Zero -shot text-to-SQL with ChatGPT
Gao C, Li X, Li Y, Qin B, Liu T. C3: Zero -shot text-to-SQL with ChatGPT. arXiv preprint arXiv:2307.07306. 2023
-
[24]
CodeS: Towards building open -source language models for text -to-SQL
Li H, Zhang J, Li C, Chen H. CodeS: Towards building open -source language models for text -to-SQL. In: Proceedings of the ACM SIGMOD International Conference on Management of Data; 2024. doi:10.1145/3654930
-
[25]
Think2SQL: Reinforce LLM Reasoning Capabilities for Text2SQL
Shen T, Zhang B, Guo J, Li Z, Ma T, Li J, et al. Think2SQL: Reinforce LLM reasoning capabilities for text-to- SQL. arXiv preprint arXiv:2504.15077. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [26]
-
[27]
Postgres MCP Pro: Open-source MCP server for PostgreSQL [Internet]
CrystalDBA. Postgres MCP Pro: Open-source MCP server for PostgreSQL [Internet]. GitHub; 2025 [cited 2025 Dec 1]. Available from: https://github.com/crystaldba/postgres-mcp
2025
-
[28]
SQL Model Context Protocol (MCP) Server overview [Internet]
Microsoft. SQL Model Context Protocol (MCP) Server overview [Internet]. Microsoft Learn; 2025 [cited 2025 Adaptive ToR 20 Dec 15]. Available from: https://learn.microsoft.com/en-us/azure/data-api-builder/mcp/overview
2025
-
[29]
Schulhoff S, Pinto J, Khan A, Bouchard LF, Si C, Anati S, et al. Ignore this title and HackAPrompt: Exposing systemic weaknesses of LLMs through a global scale prompt hacking competition. In: Proceedings of the 2023 Conference on Empirical Methods in Natur al Language Processing (EMNLP); 2023. p. 4945 –77. doi:10.18653/v1/2023.emnlp-main.302
-
[30]
Greshake K, Abdelnabi S, Mishra S, Endres C, Holz T, Fritz M. Not what you've signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection. In: Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec); 2023. p. 79–90. doi:10.1145/3605764.3623985
-
[31]
Klisura D, Rios A. Unmasking database vulnerabilities: Zero -knowledge schema inference attacks in text -to- SQL systems. In: Findings of the Association for Computational Linguistics: NAACL 2025; 2025. arXiv preprint arXiv:2406.14545
-
[32]
Prompt Injection attack against LLM-integrated Applications
Liu Y, Deng G, Li Y, Wang K, Zhang T, Liu Y, et al. Prompt injection attack against LLM -integrated applications. arXiv preprint arXiv:2306.05499. 2024
work page internal anchor Pith review arXiv 2024
-
[33]
Role-based access control models
Sandhu RS, Coyne EJ, Feinstein HL, Youman CE. Role-based access control models. Computer. 1996;29(2):38–
1996
-
[34]
doi:10.1109/2.485845
-
[35]
Iqal ZM, Selamat AB, Krejcar O. A comprehensive systematic review of access control in IoT: Requirements, technologies, and evaluation metrics. IEEE Access. 2024;12:12636–54. doi:10.1109/ACCESS.2023.3347495
-
[36]
Authorization models for IoT environments: A survey
Pérez-Dí az J, Almenáres -Mendoza F, Marí n -López A, Dí az -Sánchez D. Authorization models for IoT environments: A survey. Internet of Things. 2024;28:101362. doi:10.1016/j.iot.2024.101362
-
[37]
NL2MCP: A new framework for natural language query execution
Kim WB, Moon N. NL2MCP: A new framework for natural language query execution. J Korea Soc Comput Inf (JKSCI). 2025;30(10):43–52
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.