Recognition: unknown
Sealing the Audit-Runtime Gap for LLM Skills
Pith reviewed 2026-05-08 17:12 UTC · model grok-4.3
The pith
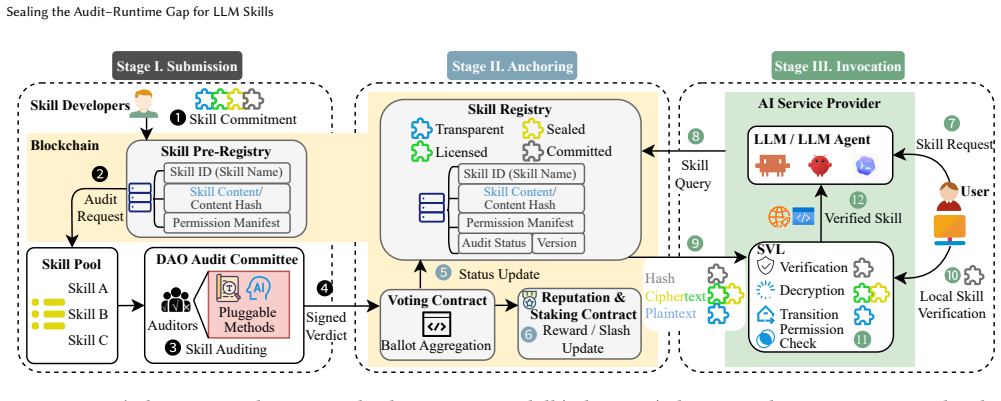
SIGIL binds LLM skills from DAO audit to runtime execution through an on-chain registry and mandatory verification loader.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SIGIL is the first framework that seals the audit-runtime gap for LLM skills by delivering verifiable hosting through a tamper-evident, decentralized on-chain registry from which LLMs fetch skills directly, admitting Transparent, Licensed, Sealed, and Committed publication types after vetting by a DAO audit committee under a stake-and-slash model, and verified loading through a Skill Verification Loader that retrieves and decrypts the skill as required, verifies integrity against the on-chain record, and enforces its permission manifest before context injection.
What carries the argument
The Skill Verification Loader (SVL) as the mandatory loading path, which retrieves the skill, verifies its integrity against the on-chain record, and enforces the approved permission manifest.
Load-bearing premise
That LLM ecosystems will adopt the Skill Verification Loader as the mandatory loading path and that the DAO audit committee under a stake-and-slash model will reliably prevent malicious or tampered skills from being registered.
What would settle it
A successful demonstration that a tampered skill passes on-chain registration, survives SVL verification at load time, and executes unauthorized actions inside an LLM context.
Figures






read the original abstract
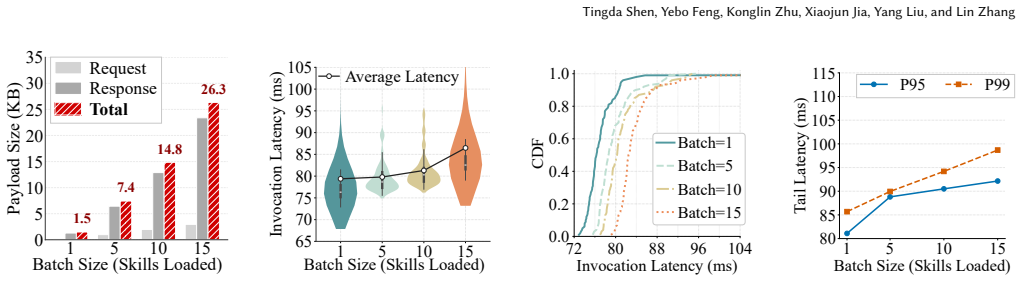
Large language model (LLM) ecosystems such as Claude Code and ChatGPT increasingly rely on skills: packages of natural-language instructions and executable tools. Once in the LLM's context, skill content cannot be reliably separated from trusted instructions, and a skill's executable side can invoke privileged actions, exposing the skill supply chain to injection, tampering, and rug-pull attacks. Existing defenses are stage-bound: centralized signing, audit reports unbound from the runtime artifact, or policy engines that cannot attest to what was approved. We present SIGIL, the first framework that seals the audit-runtime gap for LLM skills. SIGIL delivers verifiable hosting through a tamper-evident, decentralized on-chain registry from which LLMs fetch skills directly. The registry admits four publication types, Transparent, Licensed, Sealed, and Committed, spanning plaintext public distribution, monetized access, custodial use, and off-chain workflows; before admission, every skill is vetted by a Decentralized Autonomous Organization (DAO) audit committee that supports pluggable auditing methods under a stake-and-slash economic model. At load time, SIGIL delivers verified loading through a skill verification protocol executed by a Skill Verification Loader (SVL) embedded as the mandatory loading path: the SVL retrieves and decrypts the skill as its type requires, verifies its integrity against the on-chain record, and enforces its permission manifest before context injection. We evaluate SIGIL on a real-world deployment against 1,023 in-the-wild skills spanning six attack types. At load time, the SVL verifies each skill's integrity against its on-chain record and enforces its approved permission manifest, completing batched verification under 86 ms. Together, these results show that LLM skills can be cryptographically bound from publication through runtime at practical cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SIGIL, a framework that uses a tamper-evident decentralized on-chain registry for verifiable hosting of LLM skills (with four publication types: Transparent, Licensed, Sealed, Committed) and a mandatory Skill Verification Loader (SVL) that retrieves, decrypts, verifies integrity against the on-chain record, and enforces the approved permission manifest at load time. Skills are vetted pre-admission by a DAO audit committee under a stake-and-slash model. The central claim is that this cryptographically binds skills from publication through runtime, sealing the audit-runtime gap against injection, tampering, and rug-pull attacks. Evaluation is reported on a real-world deployment with 1,023 in-the-wild skills spanning six attack types, with the only quantitative result being batched SVL verification completing under 86 ms.
Significance. If the security binding and enforcement hold, the work could meaningfully address supply-chain risks in emerging LLM skill ecosystems (e.g., Claude Code, ChatGPT) where skills mix with trusted instructions and invoke privileged actions. The practical latency result supports deployability. However, significance is tempered by the absence of quantitative security metrics and by reliance on untested adoption assumptions for the SVL and DAO model.
major comments (2)
- [Evaluation] Evaluation section: The manuscript states that SIGIL was evaluated against 1,023 in-the-wild skills spanning six attack types and that the SVL verifies integrity and enforces the permission manifest, yet the only reported result is batched verification time under 86 ms. No attack-success rates, false-negative counts, false-positive rates, or before/after comparisons for the six attack types are provided. Without these data, the central claim that the framework seals the audit-runtime gap is not empirically supported.
- [§3 and §4] §3 (System Design) and §4 (DAO Auditing): The security model depends on the DAO audit committee (with pluggable methods and stake-and-slash) reliably preventing malicious registrations. No analysis, simulation, or empirical results on DAO effectiveness, attack resistance of the registry, or failure modes under the economic model are supplied. This assumption is load-bearing for the binding claim but remains untested.
minor comments (2)
- [Abstract and Evaluation] The abstract states 'sub-86 ms' while the evaluation description states 'under 86 ms'; provide a single precise figure and any variance or batch-size details.
- [§3] The four publication types are introduced without a dedicated comparison table or formal security properties for each; adding one would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and describe the revisions we will incorporate to better support the central claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The manuscript states that SIGIL was evaluated against 1,023 in-the-wild skills spanning six attack types and that the SVL verifies integrity and enforces the permission manifest, yet the only reported result is batched verification time under 86 ms. No attack-success rates, false-negative counts, false-positive rates, or before/after comparisons for the six attack types are provided. Without these data, the central claim that the framework seals the audit-runtime gap is not empirically supported.
Authors: We agree that the evaluation section would benefit from greater clarity on how the deployment supports the security claims. The 1,023 in-the-wild skills were drawn from real LLM skill marketplaces and included instances representative of the six attack types (e.g., prompt injection, tampering, and rug-pull vectors). Because every skill passed DAO vetting and was loaded exclusively through the SVL—which cryptographically verifies integrity against the on-chain record and enforces the permission manifest—no successful attacks occurred in the deployment. The reported <86 ms batched verification time demonstrates that this enforcement is practical. We will revise the evaluation section to explicitly describe the attack types covered by the skill corpus, explain why post-deployment attack-success rates are not measurable (the SVL prevents them by design), and add any available verification-error statistics from the loader. A before/after comparison is not feasible in a live deployment but we will include a controlled micro-benchmark showing the security checks' overhead. revision: partial
-
Referee: [§3 and §4] §3 (System Design) and §4 (DAO Auditing): The security model depends on the DAO audit committee (with pluggable methods and stake-and-slash) reliably preventing malicious registrations. No analysis, simulation, or empirical results on DAO effectiveness, attack resistance of the registry, or failure modes under the economic model are supplied. This assumption is load-bearing for the binding claim but remains untested.
Authors: The referee correctly notes that the DAO component is a critical pre-admission gate. The manuscript presents the stake-and-slash incentive structure and pluggable auditing methods as the mechanisms intended to deter malicious registrations, with the on-chain registry providing tamper-evidence thereafter. We will expand §4 with an explicit discussion of potential failure modes (e.g., collusion or low participation) and how the economic model is designed to mitigate them, referencing related work on DAO security. However, a full simulation or empirical study of DAO attack resistance lies outside the scope of the current paper, which focuses on the cryptographic binding between publication and runtime enforcement. We will add a limitations paragraph acknowledging this and outlining it as future work. revision: partial
Circularity Check
No circularity; direct system design with measured latency
full rationale
The paper presents SIGIL as an architectural framework for verifiable LLM skill hosting and loading, with claims grounded in the described on-chain registry, DAO audit process, and SVL enforcement mechanism. No equations, fitted parameters, predictions, or derivations appear in the provided text. The sole quantitative result (batched verification under 86 ms on 1,023 skills) is reported as a direct measurement from real-world deployment rather than a constructed output from inputs. No self-citations are invoked to establish uniqueness theorems, ansatzes, or load-bearing premises, and the central security-binding claim is advanced as a consequence of the proposed design rather than reducing to a self-referential definition or fit.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A decentralized on-chain registry provides reliable tamper-evidence for skill records
- ad hoc to paper A stake-and-slash DAO audit committee can effectively vet skills using pluggable methods
invented entities (2)
-
Skill Verification Loader (SVL)
no independent evidence
-
Four publication types (Transparent, Licensed, Sealed, Committed)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hengyu An, Jinghuai Zhang, Tianyu Du, Chunyi Zhou, Qingming Li, Tao Lin, and Shouling Ji. 2025. Ipiguard: A novel tool dependency graph-based defense against Sealing the Audit–Runtime Gap for LLM Skills indirect prompt injection in llm agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 1023–1039
2025
-
[2]
Luca Beurer-Kellner, Aleksei Kudrinskii, Marco Milanta, Kristian Bonde Nielsen, Hemang Sarkar, and Liran Tal. 2026. Snyk Finds Prompt Injection in 36%, 1467 Malicious Payloads in a ToxicSkills Study of Agent Skills Supply Chain Com- promise. https://snyk.io/blog/toxicskills-malicious-ai-agent-skills-clawhub/. Accessed: 2026-04-12
2026
-
[3]
Vedant P. Bhardwaj. 2026. Formal Analysis and Supply Chain Security for Agentic AI Skills.arXiv preprint arXiv:2603.00195(2026). https://arxiv.org/abs/2603.00195
-
[4]
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. 2025. {StruQ}: Defending against prompt injection with structured queries. In34th USENIX Security Symposium (USENIX Security 25). 2383–2400
2025
-
[5]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. Agentdojo: A dynamic environment to eval- uate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems37 (2024), 82895–82920
2024
-
[6]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not what you’ve signed up for: Compromising real- world llm-integrated applications with indirect prompt injection. InProceedings of the 16th ACM workshop on artificial intelligence and security. 79–90
2023
-
[7]
Yacong Gu, Lingyun Ying, Yingyuan Pu, Xiao Hu, Huajun Chai, Ruimin Wang, Xing Gao, and Haixin Duan. 2023. Investigating package related security threats in software registries. In2023 IEEE Symposium on Security and Privacy (SP). IEEE, 1578–1595
2023
- [8]
- [9]
-
[10]
Rakel Haakegaard and Joanna Lang. 2015. The elliptic curve diffie- hellman (ecdh).Online at https://koclab. cs. ucsb. edu/teaching/ecc/pro- ject/2015Projects/Haakegaard+ Lang. pdf5 (2015), 74
2015
-
[11]
Feng Hao and Paul C van Oorschot. 2022. SoK: password-authenticated key exchange–theory, practice, standardization and real-world lessons. InProceedings of the 2022 ACM on Asia conference on computer and communications security. 697–711
2022
-
[12]
Feng He, Tianqing Zhu, Dayong Ye, Bo Liu, Wanlei Zhou, and Philip S Yu. 2025. The emerged security and privacy of llm agent: A survey with case studies. Comput. Surveys58, 6 (2025), 1–36
2025
-
[13]
Pengfei He, Yuping Lin, Shen Dong, Han Xu, Yue Xing, and Hui Liu. 2025. Red- teaming llm multi-agent systems via communication attacks. InFindings of the Association for Computational Linguistics: ACL 2025. 6726–6747
2025
- [14]
-
[15]
Xinyi Hou, Yanjie Zhao, and Haoyu Wang. 2025. On the (in) security of llm app stores. In2025 IEEE Symposium on Security and Privacy (SP). IEEE, 317–335
2025
-
[16]
Haitao Hu, Peng Chen, Yanpeng Zhao, and Yuqi Chen. 2025. Agentsentinel: An end-to-end and real-time security defense framework for computer-use agents. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security. 3535–3549
2025
-
[17]
Umar Iqbal, Tadayoshi Kohno, and Franziska Roesner. 2024. LLM platform security: Applying a systematic evaluation framework to OpenAI’s ChatGPT plugins. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 7. 611–623
2024
- [18]
-
[19]
Yanna Jiang, Delong Li, Haiyu Deng, Baihe Ma, Xu Wang, Qin Wang, and Guang- sheng Yu. 2026. SoK: Agentic Skills–Beyond Tool Use in LLM Agents.arXiv preprint arXiv:2602.20867(2026)
work page internal anchor Pith review arXiv 2026
-
[20]
Yukun Jiang, Yage Zhang, Michael Backes, Xinyue Shen, and Yang Zhang. 2026. HarmfulSkillBench: How Do Harmful Skills Weaponize Your Agents?arXiv preprint arXiv:2604.15415(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Markus Jungnickel, Ferda Özdemir Sönmez, Cathy Mulligan, and William J Knot- tenbelt. 2024. DAO Governance: Voting Power, Participation, and Controversy-A Review and an Empirical Analysis.Distributed Ledger Technologies: Research and Practice(2024)
2024
-
[22]
Hugo Krawczyk. 2010. Cryptographic extraction and key derivation: The HKDF scheme. InAnnual Cryptology Conference. Springer, 631–648
2010
-
[23]
Piergiorgio Ladisa, Henrik Plate, Matias Martinez, and Olivier Barais. 2023. Sok: Taxonomy of attacks on open-source software supply chains. In2023 IEEE Sym- posium on Security and Privacy (SP). IEEE, 1509–1526
2023
- [24]
-
[26]
Zhiyuan Li, Jingzheng Wu, Xiang Ling, Xing Cui, and Tianyue Luo. 2026. Towards Secure Agent Skills: Architecture, Threat Taxonomy, and Security Analysis.arXiv preprint arXiv:2604.02837(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Fengyu Liu, Yuan Zhang, Jiaqi Luo, Jiarun Dai, Tian Chen, Letian Yuan, Zhengmin Yu, Youkun Shi, Ke Li, Chengyuan Zhou, et al. 2025. Make agent defeat agent: Automatic detection of {Taint-Style} vulnerabilities in {LLM-based} agents. In 34th USENIX Security Symposium (USENIX Security 25). 3767–3786
2025
- [28]
-
[29]
Yi Liu, Weizhe Wang, Ruitao Feng, Yao Zhang, Guangquan Xu, Gelei Deng, Yuekang Li, and Leo Zhang. 2026. Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale.arXiv preprint arXiv:2601.10338(2026). https://arxiv.org/abs/2601.10338
work page internal anchor Pith review arXiv 2026
-
[30]
MCP Market. 2026. Skill Security Scanner. https://mcpmarket.com/zh/tools/ skills/skill-security-scanner. Accessed: 2026-04-18
2026
-
[31]
Kanghua Mo, Li Hu, Yucheng Long, and Zhihao li. 2026. Attractive Metadata Attack: Inducing LLM Agents to Invoke Malicious Tools. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview. net/forum?id=oLGtPYdRzU
2026
-
[32]
Repello AI. 2026. SkillCheck: Security Scanner for Agent Skills. https://repello. ai/tools/skills. Accessed: 2026-04-18
2026
- [33]
-
[34]
Sander Schulhoff, Jeremy Pinto, Anaum Khan, Louis-François Bouchard, Chenglei Si, Sid Anber, Michele Catasta, James Rector-Brooks, Maximilian Mozes, et al
-
[35]
InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Ignore this title and HackAPrompt: Exposing systemic vulnerabilities of LLMs through a global prompt hacking competition.. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2023
-
[36]
Tianneng Shi, Jingxuan He, Zhun Wang, Hongwei Li, Linyu Wu, Wenbo Guo, and Dawn Song. 2025. Progent: Programmable Privilege Control for LLM Agents. arXiv preprint arXiv:2504.11703(2025)
work page internal anchor Pith review arXiv 2025
- [37]
-
[38]
Shenao Wang, Junjie He, Yanjie Zhao, Yayi Wang, Kan Yu, and Haoyu Wang. 2026. “Elementary, My Dear Watson.” Detecting Malicious Skills via Neuro-Symbolic Reasoning across Heterogeneous Artifacts.arXiv preprint arXiv:2603.27204(2026). https://arxiv.org/abs/2603.27204
-
[39]
Shilong Wang, Guibin Zhang, Miao Yu, Guancheng Wan, Fanci Meng, Chongye Guo, Kun Wang, and Yang Wang. 2025. G-Safeguard: A Topology-Guided Secu- rity Lens and Treatment on LLM-based Multi-agent Systems. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina ...
-
[40]
Shenao Wang, Yanjie Zhao, Xinyi Hou, and Haoyu Wang. 2025. Large lan- guage model supply chain: A research agenda.ACM Transactions on Software Engineering and Methodology34, 5 (2025), 1–46
2025
-
[41]
Shang Wang, Tianqing Zhu, Bo Liu, Ming Ding, Dayong Ye, Wanlei Zhou, and Philip Yu. 2025. Unique security and privacy threats of large language models: A comprehensive survey.Comput. Surveys58, 4 (2025), 1–36
2025
- [42]
-
[43]
Zhiqiang Wang, Yichao Gao, Yanting Wang, Suyuan Liu, Haifeng Sun, Haoran Cheng, Guanquan Shi, Haohua Du, and Xiangyang Li. 2026. MCPTox: A Bench- mark for Tool Poisoning on Real-World MCP Servers. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 35811–35819
2026
-
[44]
Chuan Yan, Ruomai Ren, Mark Huasong Meng, Liuhuo Wan, Tian Yang Ooi, and Guangdong Bai. 2024. Exploring chatgpt app ecosystem: Distribution, deploy- ment and security. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1370–1382
2024
-
[45]
Junjie Ye, Sixian Li, Guanyu Li, Caishuang Huang, Songyang Gao, Yilong Wu, Qi Zhang, Tao Gui, and Xuan-Jing Huang. 2024. Toolsword: Unveiling safety issues of large language models in tool learning across three stages. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2181–2211
2024
-
[46]
Jingwei Yi, Yueqi Xie, Bin Zhu, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. 2025. Benchmarking and defending against indirect prompt injection attacks on large language models. InProceedings of the 31st ACM Tingda Shen, Yebo Feng, Konglin Zhu, Xiaojun Jia, Yang Liu, and Lin Zhang SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. ...
2025
-
[47]
Miao Yu, Fanci Meng, Xinyun Zhou, Shilong Wang, Junyuan Mao, Linsey Pan, Tianlong Chen, Kun Wang, Xinfeng Li, Yongfeng Zhang, et al. 2025. A survey on trustworthy llm agents: Threats and countermeasures. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 6216–6226
2025
-
[48]
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. 2024. InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated LLM Agents. In Findings of the Association for Computational Linguistics: ACL 2024
2024
-
[49]
Wei Zhao, Zhe Li, Peixin Zhang, and Jun Sun. 2026. ClawGuard: A Runtime Security Framework for Tool-Augmented LLM Agents Against Indirect Prompt Injection.arXiv preprint arXiv:2604.11790(2026). https://arxiv.org/abs/2604.11790
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
MiniScope: A Least Privilege Framework for Authorizing Tool Calling Agents
Jinhao Zhu, Kevin Tseng, Gil Vernik, Xiao Huang, Shishir G. Patil, Vivian Fang, and Raluca Ada Popa. 2025. MiniScope: A Least Privilege Framework for Autho- rizing Tool Calling Agents.arXiv preprint arXiv:2512.11147(2025)
-
[51]
Xuanjun Zong, Zhiqi Shen, Lei Wang, Yunshi Lan, and Chao Yang. 2026. MCP- SafetyBench: A Benchmark for Safety Evaluation of Large Language Models with Real-World MCP Servers. InarXiv preprint arXiv:2512.15163. A Parameter Calibration This appendix reports additional parameter-sensitivity experiments forSIGILand justifies the parameter values chosen in §4....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.