Recognition: unknown
COPYCOP: Ownership Verification for Graph Neural Networks
Pith reviewed 2026-05-08 16:14 UTC · model grok-4.3
The pith
CopyCop detects whether one GNN is a copy of another even after the adversary changes its architecture, weights, embedding dimension, and output transformations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given two GNNs that output node embeddings, CopyCop determines if they were trained independently or if one is an adversarial copycat that may differ in architecture, weights, and embedding dimension and whose outputs may have been transformed. It supplies theoretical guarantees for this detection and, in experiments on 14 datasets with 5 GNN architectures, proves accurate and robust against a broad class of adversarial attacks and transformations.
What carries the argument
CopyCop algorithm that locates a detectable invariant preserved in the embedding spaces of copycat GNNs despite architectural differences and output transformations.
If this is right
- GNN owners gain a practical way to verify ownership against disguised copies.
- Existing watermarking and fingerprinting techniques are shown to be insufficient under the stated adversarial conditions.
- Theoretical guarantees accompany the detection decisions.
- The method works across multiple datasets and GNN architectures while resisting broad adversarial transformations.
Where Pith is reading between the lines
- The same invariant-based idea could be tested on non-graph neural networks that produce embeddings.
- Detection thresholds might be tuned per domain to balance false positives and missed copies.
- The approach could support automated monitoring of public model repositories for unauthorized derivatives.
Load-bearing premise
There exists a detectable invariant in the embedding spaces of independently trained versus copycat GNNs that survives arbitrary transformations and architectural differences.
What would settle it
A concrete case in which CopyCop fails to flag a known transformed copycat GNN or incorrectly flags two independently trained GNNs as copies.
Figures



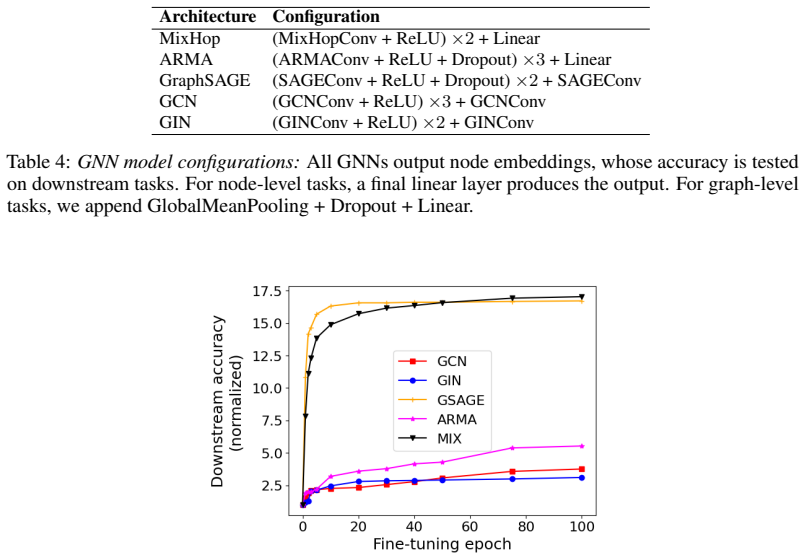
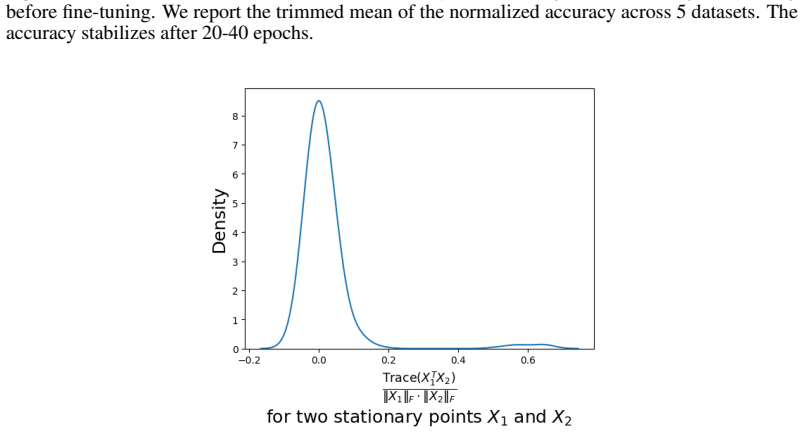
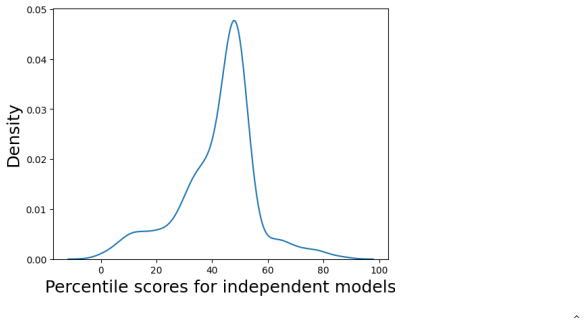
read the original abstract
Given two GNNs that output node embeddings, how can we determine if they were trained independently? An adversary could have trained one GNN specifically to mimic the other GNN's embeddings. To obscure this relationship between the GNNs, the adversarial GNN might then transform its output embeddings. The two GNNs could have different architectures, weights, and embedding dimensions, and the adversary can transform the embeddings. Despite these stringent conditions, our algorithm (named CopyCop) can identify such copycat GNNs, unlike existing watermarking and fingerprinting methods. We also provide theoretical guarantees for CopyCop. Finally, experiments on 14 datasets and 5 GNN architectures demonstrate that CopyCop is accurate and robust against a broad class of adversarial attacks and transformations. Code is available at: https://anonymous.4open.science/r/CopyCop-Graph-Ownership-Verification-8143/README.md
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces COPYCOP, an algorithm for determining whether two GNNs that produce node embeddings were trained independently or whether one is an adversarial copycat of the other. The method is claimed to succeed even when the models differ in architecture, weights, and embedding dimension and when the adversary applies arbitrary transformations to the output embeddings to obscure the relationship. Unlike prior watermarking or fingerprinting approaches, COPYCOP is presented as relying on an invariant detectable in the embedding spaces; the manuscript asserts theoretical guarantees for this detection and reports empirical accuracy and robustness across 14 datasets and 5 GNN architectures.
Significance. If the central claim holds, COPYCOP would provide a watermark-free, transformation-robust method for GNN ownership verification, addressing a practical need in intellectual-property protection for graph models. The availability of code and the breadth of the experimental evaluation (14 datasets) are positive features that would facilitate reproducibility and further testing.
major comments (3)
- [Abstract] Abstract: the claim of 'theoretical guarantees' for identifying copycat GNNs under differing architectures, weights, dimensions, and adversarial transformations is asserted without any outline of the proof strategy, key assumptions, or lemmas. This is load-bearing because the central claim rests on the existence of a detectable invariant that survives the stated conditions; without the derivation, the scope and tightness of the guarantees cannot be assessed.
- [Experiments] Experimental evaluation: the robustness claims against 'a broad class of adversarial attacks and transformations' on 14 datasets are presented without error bars, statistical significance tests, or explicit definitions of the attack models and transformation families. This undermines verification of the empirical support for the claim that COPYCOP succeeds where watermarking and fingerprinting fail.
- [Method] Method description: the concrete form of the invariant extracted from node embeddings (and the procedure for comparing two embedding spaces of possibly different dimensions) is not specified with sufficient detail to allow independent reproduction or to check whether it reduces to a self-defined quantity under the adversary's transformations.
minor comments (1)
- [Code availability] The code repository link is provided, which is helpful; however, the README should include explicit instructions for reproducing the 14-dataset experiments and the exact attack configurations used.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We address each major comment point by point below, agreeing where revisions are warranted to strengthen clarity, reproducibility, and empirical rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'theoretical guarantees' for identifying copycat GNNs under differing architectures, weights, dimensions, and adversarial transformations is asserted without any outline of the proof strategy, key assumptions, or lemmas. This is load-bearing because the central claim rests on the existence of a detectable invariant that survives the stated conditions; without the derivation, the scope and tightness of the guarantees cannot be assessed.
Authors: We agree that the abstract would benefit from a concise outline of the theoretical contributions to allow readers to better assess the scope of the guarantees. The guarantees (detailed in Section 3) establish the existence of an invariant in the embedding spaces that distinguishes independently trained models from copycats, even under architectural differences, dimension mismatches, and adversarial transformations. We will revise the abstract to briefly mention the high-level proof strategy, key assumptions (e.g., regarding the class of transformations), and main lemmas. revision: yes
-
Referee: [Experiments] Experimental evaluation: the robustness claims against 'a broad class of adversarial attacks and transformations' on 14 datasets are presented without error bars, statistical significance tests, or explicit definitions of the attack models and transformation families. This undermines verification of the empirical support for the claim that COPYCOP succeeds where watermarking and fingerprinting fail.
Authors: We appreciate this feedback on the presentation of the experimental results. While the evaluation covers 14 datasets and 5 architectures with reported accuracy and robustness, we acknowledge that error bars, statistical tests, and explicit attack definitions would improve verifiability. In the revised manuscript, we will add standard deviation error bars across multiple runs, include statistical significance tests (such as paired t-tests against baselines), and provide precise definitions of the attack models and transformation families (e.g., rotations, scalings, noise injections, and other linear/non-linear mappings) in the experimental setup. revision: yes
-
Referee: [Method] Method description: the concrete form of the invariant extracted from node embeddings (and the procedure for comparing two embedding spaces of possibly different dimensions) is not specified with sufficient detail to allow independent reproduction or to check whether it reduces to a self-defined quantity under the adversary's transformations.
Authors: We agree that the method section requires greater specificity for independent reproduction and to demonstrate that the invariant does not trivially collapse under adversarial transformations. We will expand this section with additional mathematical detail on the invariant derived from the node embeddings, the exact procedure for aligning and comparing embedding spaces of differing dimensions, algorithmic steps (including pseudocode), and explicit analysis showing robustness to the stated transformations. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and description introduce COPYCOP as an algorithm that identifies copycat GNNs via detectable invariants in embeddings, supported by theoretical guarantees and experiments across 14 datasets and 5 architectures. No equations, parameter-fitting steps, self-definitional reductions, or load-bearing self-citations are described that would make any prediction or guarantee equivalent to its inputs by construction. The central claim rests on the existence of a transformation-robust invariant, presented as independently verifiable rather than derived from fitted quantities or prior author results in a circular manner. This is a standard non-finding for a methods paper whose core contribution is algorithmic and empirical.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing
Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Nazanin Alipourfard, Kristina Lerman, Hrayr Harutyunyan, Greg Ver Steeg, and Aram Galstyan. MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing. 2019
2019
-
[2]
Turning Your Weakness Into a Strength: Watermarking Deep Neural Networks by Backdooring
Yossi Adi, Carsten Baum, Benny Pinkas, and Joseph Keshet. Turning Your Weakness Into a Strength: Watermarking Deep Neural Networks by Backdooring. InSEC’18: Proceedings of the 27th USENIX Conference on Security Symposium, 2018
2018
-
[3]
Nevergrad: Black-box optimization platform.ACM SIGEVOlution, 14(1):8–15, 2021
Pauline Bennet, Carola Doerr, Antoine Moreau, Jeremy Rapin, Fabien Teytaud, and Olivier Teytaud. Nevergrad: Black-box optimization platform.ACM SIGEVOlution, 14(1):8–15, 2021. ISSN 1931-8499. doi: 10.1145/3460310.3460312. URLhttps://doi.org
-
[4]
Filippo Maria Bianchi, Daniele Grattarola, Lorenzo Livi, and Cesare Alippi. Graph neural networks with convolutional arma filters.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3496–3507, 2022. doi: 10.1109/TPAMI.2021.3054830
-
[5]
DeepMarks: A Secure Fingerprinting Framework for Digital Rights Management of Deep Learning Models
Huili Chen, Bita Darvish Rouhani, Cheng Fu, Jishen Zhao, and Farinaz Koushanfar. DeepMarks: A Secure Fingerprinting Framework for Digital Rights Management of Deep Learning Models. InProceedings of the 2019 on International Conference on Multimedia Retrieval, ICMR ’19, pages 105–113, New York, NY , USA, June 2019. Association for Computing Machinery. ISBN...
-
[6]
Enyan Dai, Tianxiang Zhao, Huaisheng Zhu, Junjie Xu, Zhimeng Guo, Hui Liu, Jiliang Tang, and Suhang Wang. A Comprehensive Survey on Trustworthy Graph Neural Networks: Privacy, Robustness, Fairness, and Explainability.Machine Intelligence Research, 21(6):1011–1061, December 2024. ISSN 2731-538X, 2731-5398. doi: 10.1007/s11633-024-1510-8. URL https://link.s...
-
[7]
PreGIP: Watermarking the Pretraining of Graph Neural Networks for Deep IP Protection
Enyan Dai, Minhua Lin, and Suhang Wang. PreGIP: Watermarking the Pretraining of Graph Neural Networks for Deep IP Protection. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2, pages 415–426, Toronto ON Canada, August
-
[8]
ACM. ISBN 979-8-4007-1454-2. doi: 10.1145/3711896.3737089. URL https://dl. acm.org/doi/10.1145/3711896.3737089
-
[9]
DeepSigns: An End-to-End Watermarking Framework for Ownership Protection of Deep Neural Networks
Bita Darvish Rouhani, Huili Chen, and Farinaz Koushanfar. DeepSigns: An End-to-End Watermarking Framework for Ownership Protection of Deep Neural Networks. InProceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS ’19, pages 485–497, New York, NY , USA, April
-
[10]
Association for Computing Machinery. ISBN 978-1-4503-6240-5. doi: 10.1145/3297858. 3304051. URLhttps://dl.acm.org/doi/10.1145/3297858.3304051
-
[11]
Adversarial model extraction on graph neural networks.arXiv preprint arXiv:1912.07721, 2019
David DeFazio and Arti Ramesh. Adversarial Model Extraction on Graph Neural Networks, December 2019. URLhttp://arxiv.org/abs/1912.07721. arXiv:1912.07721 [cs]
-
[12]
GARNET: Reduced-rank topology learning for robust and scalable graph neural networks
Chenhui Deng, Xiuyu Li, Zhuo Feng, and Zhiru Zhang. GARNET: Reduced-rank topology learning for robust and scalable graph neural networks. InLearning on Graphs Conference,
-
[13]
URLhttps://openreview.net/forum?id=kvwWjYQtmw
-
[14]
Hamilton, Rex Ying, and Jure Leskovec
William L. Hamilton, Rex Ying, and Jure Leskovec. Inductive representation learning on large graphs. InNIPS, 2017
2017
-
[15]
Sensitive-sample fingerprinting of deep neural networks
Zecheng He, Tianwei Zhang, and Ruby Lee. Sensitive-sample fingerprinting of deep neural networks. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4724–4732, 2019. doi: 10.1109/CVPR.2019.00486
-
[16]
Mika Juuti, Sebastian Szyller, Samuel Marchal, and N. Asokan. PRADA: Protecting Against DNN Model Stealing Attacks. In2019 IEEE European Symposium on Security and Privacy (EuroS&P), pages 512–527, June 2019. doi: 10.1109/EuroSP.2019.00044. URL https: //ieeexplore.ieee.org/document/8806737. 10
-
[17]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[18]
Thieves on Sesame Street! Model Extraction of BERT-based APIs
Kalpesh Krishna, Gaurav Singh Tomar, Ankur P Parikh, Nicolas Papernot, and Mohit Iyyer. Thieves on Sesame Street! Model Extraction of BERT-based APIs. 2020
2020
-
[19]
Verification of integrity of deployed deep learning models using bayesian optimization
Deepthi Praveenlal Kuttichira, Sunil Gupta, Dang Nguyen, Santu Rana, and Svetha Venkatesh. Verification of integrity of deployed deep learning models using bayesian optimization. Knowledge-based systems, 241:108238, 2022
2022
-
[20]
Hyun Kwon and Yongchul Kim. BlindNet backdoor: Attack on deep neural network using blind watermark.Multimedia Tools Appl., 81(5):6217–6234, February 2022. ISSN 1380-7501. doi: 10.1007/s11042-021-11135-0. URLhttps://doi.org/10.1007/s11042-021-11135-0
-
[21]
Defending Against Neural Network Model Stealing Attacks Using Deceptive Perturbations
Taesung Lee, Benjamin Edwards, Ian Molloy, and Dong Su. Defending Against Neural Network Model Stealing Attacks Using Deceptive Perturbations. In2019 IEEE Security and Privacy Workshops (SPW), pages 43–49, May 2019. doi: 10.1109/SPW.2019.00020. URL https://ieeexplore.ieee.org/document/8844598
-
[22]
Nils Lukas, Edward Jiang, Xinda Li, and Florian Kerschbaum. SoK: How Robust is Image Classification Deep Neural Network Watermarking? (Extended Version), August 2021. URL http://arxiv.org/abs/2108.04974. arXiv:2108.04974 [cs]
-
[23]
Deep Neural Network Fingerprinting by Conferrable Adversarial Examples
Nils Lukas, Yuxuan Zhang, and Florian Kerschbaum. Deep Neural Network Fingerprinting by Conferrable Adversarial Examples. 2021. arXiv:1912.00888 [cs]
-
[24]
Dataset Inference: Ownership Resolution in Machine Learning
Pratyush Maini, Mohammad Yaghini, and Nicolas Papernot. Dataset Inference: Ownership Resolution in Machine Learning. 2021
2021
-
[25]
Berkay Celik, and Ananthram Swami
Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z. Berkay Celik, and Ananthram Swami. Practical Black-Box Attacks against Machine Learning. InProceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, ASIA CCS ’17, pages 506–519, New York, NY , USA, April 2017. Association for Computing Machinery. ISBN 978-1-45...
-
[26]
Wenjun Peng, Jingwei Yi, Fangzhao Wu, Shangxi Wu, Bin Bin Zhu, Lingjuan Lyu, Binxing Jiao, Tong Xu, Guangzhong Sun, and Xing Xie. Are You Copying My Model? Protecting the Copyright of Large Language Models for EaaS via Backdoor Watermark. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Associat...
-
[27]
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection , isbn =
Zirui Peng, Shaofeng Li, Guoxing Chen, Cheng Zhang, Haojin Zhu, and Minhui Xue. Fin- gerprinting Deep Neural Networks Globally via Universal Adversarial Perturbations. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13420– 13429, New Orleans, LA, USA, June 2022. IEEE. ISBN 978-1-6654-6946-3. doi: 10.1109/ CVPR52688.2022...
-
[28]
Model Stealing Attacks Against Inductive Graph Neural Networks
Yun Shen, Xinlei He, Yufei Han, and Yang Zhang. Model Stealing Attacks Against Inductive Graph Neural Networks. pages 1175–1192. IEEE Computer Society, May 2022. ISBN 978- 1-6654-1316-9. doi: 10.1109/SP46214.2022.9833607. URL https://www.computer.org/ csdl/proceedings-article/sp/2022/131600b031/1FlQwoy12IU
-
[29]
Embedding Watermarks into Deep Neural Networks
Yusuke Uchida, Yuki Nagai, Shigeyuki Sakazawa, and Shin’ichi Satoh. Embedding Watermarks into Deep Neural Networks. InProceedings of the 2017 ACM on International Conference on Multimedia Retrieval, ICMR ’17, pages 269–277, New York, NY , USA, June 2017. Association for Computing Machinery. ISBN 978-1-4503-4701-3. doi: 10.1145/3078971.3078974. URL https:/...
- [30]
-
[31]
Publiccheck: Public integrity verification for services of run-time deep models
Shuo Wang, Sharif Abuadbba, Sidharth Agarwal, Kristen Moore, Ruoxi Sun, Minhui Xue, Surya Nepal, Seyit Camtepe, and Salil Kanhere. Publiccheck: Public integrity verification for services of run-time deep models. In2023 IEEE Symposium on Security and Privacy (SP), pages 1348–1365. IEEE, 2023
2023
-
[32]
online:https://doi.org/10.1145/3548606
Xiuling Wang and Wendy Hui Wang. Group Property Inference Attacks Against Graph Neural Networks. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, CCS ’22, pages 2871–2884, New York, NY , USA, November 2022. Association for Computing Machinery. ISBN 978-1-4503-9450-5. doi: 10.1145/3548606. 3560662. URLhttps://dl.acm....
-
[33]
Securing graph neural networks in mlaas: A comprehensive realization of query-based integrity verification
Bang Wu, Xingliang Yuan, Shuo Wang, Qi Li, Minhui Xue, and Shirui Pan. Securing graph neural networks in mlaas: A comprehensive realization of query-based integrity verification. In 2024 IEEE Symposium on Security and Privacy (SP), pages 2534–2552. IEEE, 2024
2024
-
[34]
Watermarking Graph Neural Networks based on Backdoor Attacks
Jing Xu, Stefanos Koffas, O ˘guzhan Ersoy, and Stjepan Picek. Watermarking Graph Neural Networks based on Backdoor Attacks. In2023 IEEE 8th European Symposium on Security and Privacy (EuroS&P), pages 1179–1197, July 2023. doi: 10.1109/EuroSP57164.2023.00072. URLhttps://ieeexplore.ieee.org/document/10190545/
-
[35]
How powerful are graph neural networks? InInternational Conference on Learning Representations (ICLR), 2019
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[36]
GNNGUARD: defending graph neural networks against adversarial attacks
Xiang Zhang and Marinka Zitnik. GNNGUARD: defending graph neural networks against adversarial attacks. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, pages 9263–9275, Red Hook, NY , USA, December 2020. Curran Associates Inc. ISBN 978-1-7138-2954-6. URL https://dl.acm.org/doi/10. 5555/3495724.3496501
-
[37]
Inference Attacks Against Graph Neural Networks
Zhikun Zhang, Min Chen, Michael Backes, Yun Shen, and Yang Zhang. Inference Attacks Against Graph Neural Networks. In31st USENIX Security Symposium, 2022
2022
-
[38]
Watermarking Graph Neural Networks by Random Graphs
Xiangyu Zhao, Hanzhou Wu, and Xinpeng Zhang. Watermarking Graph Neural Networks by Random Graphs. In2021 9th International Symposium on Digital Forensics and Security (ISDFS), pages 1–6, June 2021. doi: 10.1109/ISDFS52919.2021.9486352. URL https: //ieeexplore.ieee.org/document/9486352
-
[39]
A recipe for watermark- ing diffusion models.arXiv preprint arXiv:2303.10137,
Yunqing Zhao, Tianyu Pang, Chao Du, Xiao Yang, Ngai-Man Cheung, and Min Lin. A Recipe for Watermarking Diffusion Models, October 2023. URL http://arxiv.org/abs/2303. 10137. arXiv:2303.10137 [cs]. A Remarks and Proofs RemarkA.1.In Algorithm 2, we can use an alternative formula for ˆβZ: ˆβZ =Mean({percentile ofq Z(t)inU} t∈T ) whereU={q Z(t)|t∈R}.(8) Here, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.