Recognition: unknown
Why Someone Asked "Why": Foil Inference in Human and LLM Question Interpretation
Pith reviewed 2026-05-08 15:52 UTC · model grok-4.3
The pith
People infer the unmentioned contrast in a why-question from what the asker would find surprising in hindsight.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
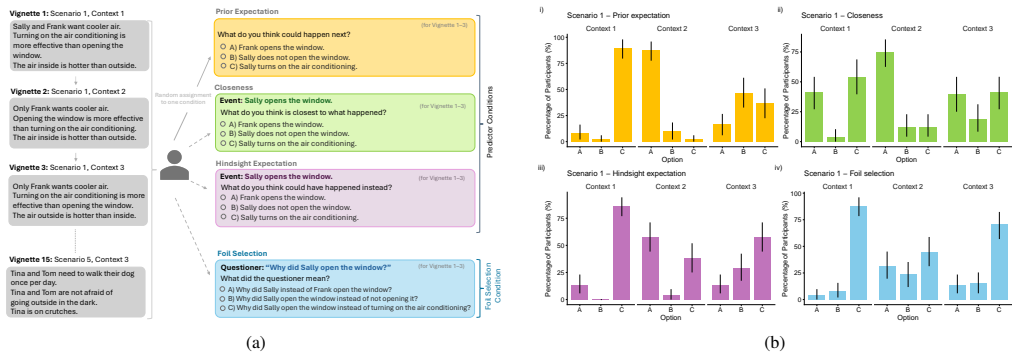
Participants selected the intended foil for why-questions in close alignment with their hindsight expectation judgments, which capture what they believed the asker would have expected to happen differently once the actual outcome was known. This alignment was stronger than the link to prior expectation judgments or closeness judgments. The results indicate that foil inference relies on reconstructing the asker's retrospective sense of surprise rather than prospective beliefs or similarity to the observed event.
What carries the argument
Hindsight expectation judgments that measure what the question asker would find surprising given the known outcome.
If this is right
- Explanations become more relevant when they target the contrast that hindsight expectations identify as surprising to the asker.
- Dialogue systems can generate better answers to why-questions by first estimating what the asker would have found unexpected after the fact.
- Large language models require additional alignment between their expectation modeling and foil selection to match human patterns.
- Training data for pragmatic reasoning should include explicit hindsight surprise signals when teaching contrastive question interpretation.
Where Pith is reading between the lines
- The same hindsight mechanism could be tested in live multi-turn dialogues to check whether vignette results generalize beyond written scenarios.
- LLM performance might improve if models are fine-tuned to output hindsight expectation scores before selecting a foil.
- This inference route may intersect with counterfactual reasoning tasks where agents must explain events by ruling out alternatives that would not have surprised the observer.
Load-bearing premise
That the explicit judgments participants provide in controlled vignette tasks accurately reflect the implicit processes used to infer foils in natural conversation.
What would settle it
A new set of vignettes in which foil selections correlate more strongly with prior expectation or closeness judgments than with hindsight expectation judgments would falsify the central claim.
Figures


read the original abstract
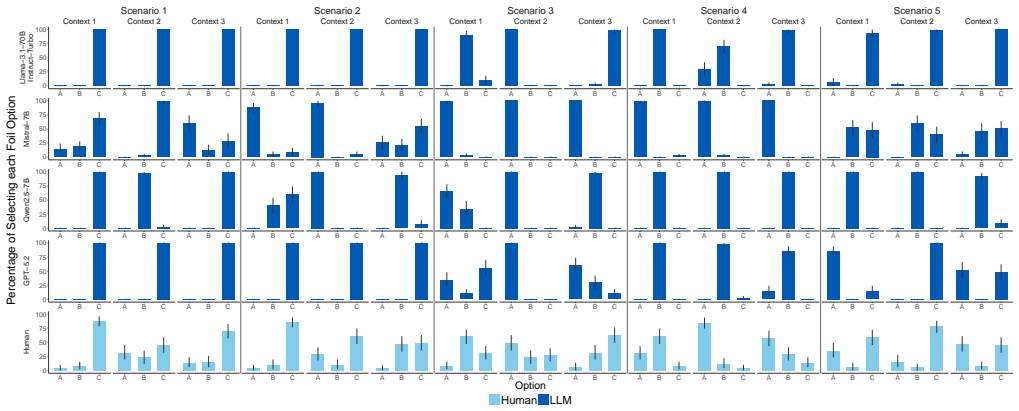
Explanations are inherently contrastive: E happened rather than E' because of C rather than C'. However, these contrasts, or "foils", are rarely mentioned explicitly but have to be inferred in context. Here, we investigate how people select the intended foil E' of a why-question. Participants read vignettes and judged, for each foil, their prior expectation (what will happen next), closeness (what is most similar to what happened), and hindsight expectation (what could have happened instead), as well as which foil they thought the question asker had in mind when they asked the why-question. We found that foil selections were best predicted by hindsight expectation judgments. This suggests that people infer the foil by considering what a question asker finds surprising after the outcome occurred. Since correct foil selection is relevant not only in human-human interaction but also increasingly in dialogues with large language models, we investigated their performance on the same task. The coupling between LLMs' explicit expectation judgments and their foil selections is inconsistent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study on how humans and LLMs infer the intended foil (alternative contrast) in why-questions. Using vignettes, human participants rate foils on prior expectation (pre-outcome), closeness (similarity to outcome), hindsight expectation (post-outcome alternatives), and select the foil they believe the asker had in mind. The central claim is that hindsight expectation judgments best predict foil selections, suggesting inference via post-outcome surprise. The study also tests LLMs on the same task and reports inconsistent coupling between their explicit judgments and foil selections.
Significance. If the central result holds, the work advances understanding of contrastive reasoning and pragmatic inference in explanations, with direct relevance to improving LLM handling of why-questions in human-AI dialogue. A clear strength is the multi-predictor design that pits prior expectation, closeness, and hindsight against each other on the same items, enabling a comparative test rather than isolated measures. The LLM extension is also valuable for applied HCI. Significance is limited by the absence of validation that explicit ratings map to implicit conversational processes.
major comments (3)
- [Results] Results section: The claim that hindsight expectation judgments best predict foil selections is presented without sample sizes, statistical tests (e.g., regression or correlation coefficients, p-values), effect sizes, or controls for order/vignette effects. This makes it impossible to evaluate whether hindsight truly outperforms the other predictors or whether the result is robust.
- [Methods] Methods: All measures (prior expectation, closeness, hindsight expectation, and foil selection) are elicited sequentially from the same participants on identical vignettes. This design cannot distinguish whether hindsight judgments causally drive foil inference or whether both are parallel downstream products of reading the vignette and performing the task, weakening the interpretation that people infer foils via post-outcome surprise.
- [LLM Experiments] LLM experiments: The finding of inconsistent coupling between LLMs' expectation judgments and foil selections lacks quantitative metrics (e.g., per-model correlations or accuracy differences), model specifications, and prompt details. Without these, the claim cannot be assessed for reliability or compared to the human data.
minor comments (2)
- [Abstract] Abstract: Omits participant count, vignette count, and analysis methods, which would allow readers to gauge the empirical scope immediately.
- [Methods] The operational definitions of 'closeness' and 'hindsight expectation' would benefit from a concrete vignette example in the main text to clarify distinctions for readers.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments below and indicate the revisions made to strengthen the paper.
read point-by-point responses
-
Referee: [Results] Results section: The claim that hindsight expectation judgments best predict foil selections is presented without sample sizes, statistical tests (e.g., regression or correlation coefficients, p-values), effect sizes, or controls for order/vignette effects. This makes it impossible to evaluate whether hindsight truly outperforms the other predictors or whether the result is robust.
Authors: We agree that the original manuscript did not provide sufficient statistical details in the Results section. We have revised the manuscript to include the participant sample size, Pearson correlation coefficients between each predictor and foil selection (hindsight expectation showing the strongest association), multiple regression analyses with coefficients, p-values, and effect sizes, as well as mixed-effects models controlling for vignette and order effects. These additions demonstrate the robustness of the finding that hindsight expectation best predicts foil selections. revision: yes
-
Referee: [Methods] Methods: All measures (prior expectation, closeness, hindsight expectation, and foil selection) are elicited sequentially from the same participants on identical vignettes. This design cannot distinguish whether hindsight judgments causally drive foil inference or whether both are parallel downstream products of reading the vignette and performing the task, weakening the interpretation that people infer foils via post-outcome surprise.
Authors: We acknowledge that the sequential within-subjects design does not permit strong causal inferences regarding the role of hindsight expectations in driving foil selection. This was a deliberate choice to enable direct comparison of the predictors using the same vignettes and participants. In the revised manuscript, we have expanded the Discussion to explicitly address this limitation, clarifying that our results show a strong predictive relationship rather than a causal mechanism. We also suggest directions for future research involving experimental manipulations to test causality. revision: yes
-
Referee: [LLM Experiments] LLM experiments: The finding of inconsistent coupling between LLMs' expectation judgments and foil selections lacks quantitative metrics (e.g., per-model correlations or accuracy differences), model specifications, and prompt details. Without these, the claim cannot be assessed for reliability or compared to the human data.
Authors: We agree that the LLM section required more detail for proper evaluation. The revised manuscript now includes the specific LLMs tested with their versions, the full prompt templates used for eliciting judgments and selections, and quantitative metrics such as per-model correlation coefficients between explicit judgments and foil selections, as well as comparisons of selection accuracy to human performance. These revisions enable direct assessment and comparison with the human results. revision: yes
Circularity Check
No circularity: empirical study with independent data collection and statistical findings
full rationale
This paper reports an empirical psychology experiment in which participants provide multiple explicit judgments (prior expectation, closeness, hindsight expectation, foil selection) on the same set of vignettes. The central result—that hindsight expectation judgments best predict foil selections—is a statistical outcome from participant data rather than a mathematical derivation, fitted parameter, or self-referential definition. No equations, ansatzes, uniqueness theorems, or load-bearing self-citations appear in the abstract or described methods. The design collects all measures from the same individuals, which raises questions of validity and task demand, but does not constitute circularity under the specified patterns because the finding is not forced by construction or by renaming inputs as outputs. The study is self-contained against its own external participant data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Participants' explicit ratings of expectation and foil selection reflect their implicit inference processes in natural language understanding.
- domain assumption The selected vignettes create realistic why-questions whose intended foils can be reliably judged by readers.
Reference graph
Works this paper leans on
-
[1]
jsPsych: Enabling an open-source collaborative ecosystem of behavioral experiments , volume =
De Leeuw, Joshua R and Gilbert, Rebecca A and Luchterhandt, Bj. jsPsych: Enabling an open-source collaborative ecosystem of behavioral experiments , volume =. Journal of Open Source Software , number =
-
[2]
Royal Institute of Philosophy Supplement , volume=
Contrastive Explanation , author=. Royal Institute of Philosophy Supplement , volume=. 1990 , doi=
1990
-
[3]
Cognition , volume=
Perceived similarity of imagined possible worlds affects judgments of counterfactual plausibility , author=. Cognition , volume=. 2021 , doi=
2021
-
[4]
1995 , month = feb, day =
Congressional Record: Senate, page S2457 , howpublished =. 1995 , month = feb, day =
1995
-
[5]
and Saxe, Rebecca and Tenenbaum, Joshua B
Baker, Chris L. and Saxe, Rebecca and Tenenbaum, Joshua B. , title =. Cognition , year =
-
[6]
The Philosophical Quarterly , year =
Barnes, Annette , title =. The Philosophical Quarterly , year =
-
[7]
Using contrastive inferences to learn about new words and categories , volume =
Bergey, Claire and Yurovsky, Daniel , year =. Using contrastive inferences to learn about new words and categories , volume =. Cognition , doi =
-
[8]
arXiv , year =
Bigelow, John and Morris, Adam and Gerstenberg, Tobias , title =. arXiv , year =
-
[9]
Cognition , year =
Brigard, Felipe , title =. Cognition , year =
-
[10]
and Gerstenberg, Tobias , title =
Brockbank, Erik and Yang, Justin and Govil, Mishika and Fan, Judith E. and Gerstenberg, Tobias , title =. Proceedings of the 46th Annual Conference of the Cognitive Science Society , year =
-
[11]
Bu. Contrastive Explanations That Anticipate Human Misconceptions Can Improve Human Decision-Making Skills , year =. doi:10.1145/3706598.3713229 , booktitle =
-
[12]
Cognitive Computation , year =
Castelnovo, Alessandro and Crupi, Riccardo and Mombelli, Nicolò and Nanino, Gabriele and Regoli, Daniele , title =. Cognitive Computation , year =
-
[13]
Proceedings of the CHI Conference on Human Factors in Computing Systems , year =
Chandra, Rohan and others , title =. Proceedings of the CHI Conference on Human Factors in Computing Systems , year =
-
[14]
Cognitive Psychology , year =
Chin-Parker, Stacey and Cantelon, Jessica , title =. Cognitive Psychology , year =
-
[15]
Psychonomic Bulletin & Review , year =
Coenen, Anna and Rehder, Bob and Ware, Emily , title =. Psychonomic Bulletin & Review , year =
-
[16]
Annual Review of Linguistics , year =
Degen, Judith , title =. Annual Review of Linguistics , year =
- [17]
-
[18]
Human-like Affective Cognition in Foundation Models , journal =
Gandhi, Kanishk and Lynch, Zoe and Fr. Human-like Affective Cognition in Foundation Models , journal =
-
[19]
Journal of Experimental Psychology: General , year =
Gerstenberg, Tobias and Icard, Thomas , title =. Journal of Experimental Psychology: General , year =
-
[20]
and Chater, Nick and Tenenbaum, Joshua B
Griffiths, Thomas L. and Chater, Nick and Tenenbaum, Joshua B. , title =
-
[21]
Contemporary Science and Natural Explanation , editor =
Hesslow, Germund , title =. Contemporary Science and Natural Explanation , editor =. 1988 , pages =
1988
-
[22]
, title =
Hilton, Denis J. , title =. Psychological Bulletin , year =
-
[23]
Philosophy of Science , year =
Hitchcock, Christopher , title =. Philosophy of Science , year =
-
[24]
and Abel, David and Correa, Carlos G
Ho, Mark K. and Abel, David and Correa, Carlos G. and Littman, Michael L. and Cohen, Jonathan D. and Griffiths, Thomas L. , title =. Nature , year =
-
[25]
, title =
Jin, X. , title =. arXiv preprint , year =
-
[26]
, title =
Kahneman, Daniel and Varey, Carol A. , title =. Journal of Personality and Social Psychology , year =
-
[27]
A Survey of Algorithmic Recourse: Contrastive Explanations and Consequential Recommendations , journal =
Karimi, Amir-Hossein and Barthe, Gilles and Sch. A Survey of Algorithmic Recourse: Contrastive Explanations and Consequential Recommendations , journal =. 2022 , volume =
2022
-
[28]
Cognitive Science , year =
Keshmirian, Anita and Willig, Moritz and Hemmatian, Babak and Hahn, Ulrike and Kersting, Kristian and Gerstenberg, Tobias , title =. Cognitive Science , year =
-
[29]
Cognitive Science , year =
Kirfel, Lara and Harding, Jacqueline and Shin, Jeong and Xin, Cindy and Icard, Thomas and Gerstenberg, Tobias , title =. Cognitive Science , year =
-
[30]
Journal of Experimental Psychology: General , year =
Kirfel, Lara and Icard, Thomas and Gerstenberg, Tobias , title =. Journal of Experimental Psychology: General , year =
-
[31]
Cognitive Psychology , year =
Lombrozo, Tania , title =. Cognitive Psychology , year =
-
[32]
, title =
Poesia Reis e Silva, Gabriel and Goodman, Noah D. , title =. Proceedings of the 44th Annual Conference of the Cognitive Science Society , year =
-
[33]
and Josephson, Susan G
Josephson, John R. and Josephson, Susan G. , title =
-
[34]
and Erb, Hans-Peter , title =
Hilton, Denis J. and Erb, Hans-Peter , title =. Thinking & Reasoning , year =
-
[35]
Proceedings of the 30th ACM Conference on User Modeling, Adaptation and Personalization , year =
Riveiro, Maria and Thill, Serge , title =. Proceedings of the 30th ACM Conference on User Modeling, Adaptation and Personalization , year =
-
[36]
and Phillips, Jonathan , title =
Kominsky, Jonathan F. and Phillips, Jonathan , title =. Cognitive Science , year =
-
[37]
, title =
Krarup, Benjamin and Krivic, Senka and Magazzeni, Daniele and Long, Derek and Cashmore, Michael and Smith, David E. , title =. Journal of Artificial Intelligence Research , year =
-
[38]
Revisiting the Evaluation of Theory of Mind through Question Answering , booktitle =
Le, Matthew and Boureau, Y. Revisiting the Evaluation of Theory of Mind through Question Answering , booktitle =. 2019 , pages =
2019
-
[39]
IEEE Transactions on Knowledge and Data Engineering , year =
Malandri, Luca and Guidotti, Riccardo and Monreale, Anna and Turini, Franco and Pedreschi, Dino , title =. IEEE Transactions on Knowledge and Data Engineering , year =
-
[40]
and Klein, Jill Gabrielle , title =
McGill, Ann L. and Klein, Jill Gabrielle , title =. Journal of Personality and Social Psychology , year =
-
[41]
and Tenbrunsel, Ann E
McGill, Ann L. and Tenbrunsel, Ann E. , title =. Journal of Personality and Social Psychology , year =
-
[42]
Artificial Intelligence , year =
Miller, Tim , title =. Artificial Intelligence , year =
-
[43]
Journal of Artificial Intelligence Research , year =
Miller, Tim , title =. Journal of Artificial Intelligence Research , year =
-
[44]
Advances in Neural Information Processing Systems , year =
Nie, Allen and Zhang, Yuhui and Amdekar, Atharva and Piech, Chris and Hashimoto, Tatsunori and Gerstenberg, Tobias , title =. Advances in Neural Information Processing Systems , year =
-
[45]
Proceedings of the National Academy of Sciences , year =
Phillips, Jonathan and Cushman, Fiery , title =. Proceedings of the National Academy of Sciences , year =
-
[46]
Mind & Language , year =
Phillips, Jonathan and Knobe, Joshua , title =. Mind & Language , year =
-
[47]
The Philosophical Review , year =
Schaffer, Jonathan , title =. The Philosophical Review , year =
-
[48]
Legal Theory , year =
Schaffer, Jonathan , title =. Legal Theory , year =
-
[49]
Journal for the Theory of Social Behaviour , volume=
Remote causes, bad explanations? , author=. Journal for the Theory of Social Behaviour , volume=. 2002 , url =
2002
-
[50]
1988 , pages=
The Pragmatic Theory of Explanation , author =. 1988 , pages=
1988
-
[51]
Trends in Cognitive Sciences , volume =
Pragmatic Language Interpretation as Probabilistic Inference , author =. Trends in Cognitive Sciences , volume =
-
[52]
Proceedings of the Annual Meeting of the Cognitive Science Society , year =
Cooperative Explanation as Rational Communication , author =. Proceedings of the Annual Meeting of the Cognitive Science Society , year =
-
[53]
Trends in Cognitive Sciences , volume =
The Structure and Function of Explanations , author =. Trends in Cognitive Sciences , volume =
-
[54]
The Oxford Handbook of Thinking and Reasoning , editor =
Explanation and Abductive Inference , author =. The Oxford Handbook of Thinking and Reasoning , editor =
-
[55]
Prompting Contrastive Explanations for Commonsense Reasoning Tasks
Paranjape, Bhargavi and Michael, Julian and Ghazvininejad, Marjan and Hajishirzi, Hannaneh and Zettlemoyer, Luke. Prompting Contrastive Explanations for Commonsense Reasoning Tasks. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.366
-
[56]
Large language models are contrastive reasoners , journal =. 2026 , issn =. doi:https://doi.org/10.1016/j.eswa.2025.130407 , url =
-
[57]
Toward Structured Knowledge Reasoning: Contrastive Retrieval-Augmented Generation on Experience
Gu, Jiawei and Xian, Ziting and Xie, Yuanzhen and Liu, Ye and Liu, Enjie and Zhong, Ruichao and Gao, Mochi and Tan, Yunzhi and Hu, Bo and Li, Zang. Toward Structured Knowledge Reasoning: Contrastive Retrieval-Augmented Generation on Experience. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1224
-
[58]
Eliciting Critical Reasoning in Retrieval-Augmented Generation via Contrastive Explanations
Ranaldi, Leonardo and Valentino, Marco and Freitas, Andre. Eliciting Critical Reasoning in Retrieval-Augmented Generation via Contrastive Explanations. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.n...
-
[59]
Proceedings of the Annual Meeting of the Cognitive Science Society , volume=
The shape of option generation in open-ended decision problems , author=. Proceedings of the Annual Meeting of the Cognitive Science Society , volume=
-
[60]
, author=
Reconciling truthfulness and relevance as epistemic and decision-theoretic utility. , author=. Psychological review , volume=. 2024 , publisher=
2024
-
[61]
arXiv preprint arXiv:2505.03732 , year=
A communication-first account of explanation , author=. arXiv preprint arXiv:2505.03732 , year=
-
[62]
Colombo, Matteo , title =. Cognitive Science , volume =. doi:https://doi.org/10.1111/cogs.12340 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1111/cogs.12340 , year =
-
[63]
Psychonomic Bulletin & Review , volume=
A contrastive account of explanation generation , author=. Psychonomic Bulletin & Review , volume=. 2017 , publisher=
2017
-
[64]
Cognitive processing , volume=
Background shifts affect explanatory style: How a pragmatic theory of explanation accounts for background effects in the generation of explanations , author=. Cognitive processing , volume=. 2010 , publisher=
2010
-
[65]
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , url=. 2024 , eprint=
work page internal anchor Pith review arXiv 2024
-
[66]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[67]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.