Recognition: 2 theorem links
· Lean TheoremZero-Shot Satellite Image Retrieval through Joint Embeddings: Application to Crisis Response
Pith reviewed 2026-05-11 01:54 UTC · model grok-4.3
The pith
GeoQuery retrieves satellite images matching natural language queries on disasters by aligning text embeddings from a small proxy set with frozen visual embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
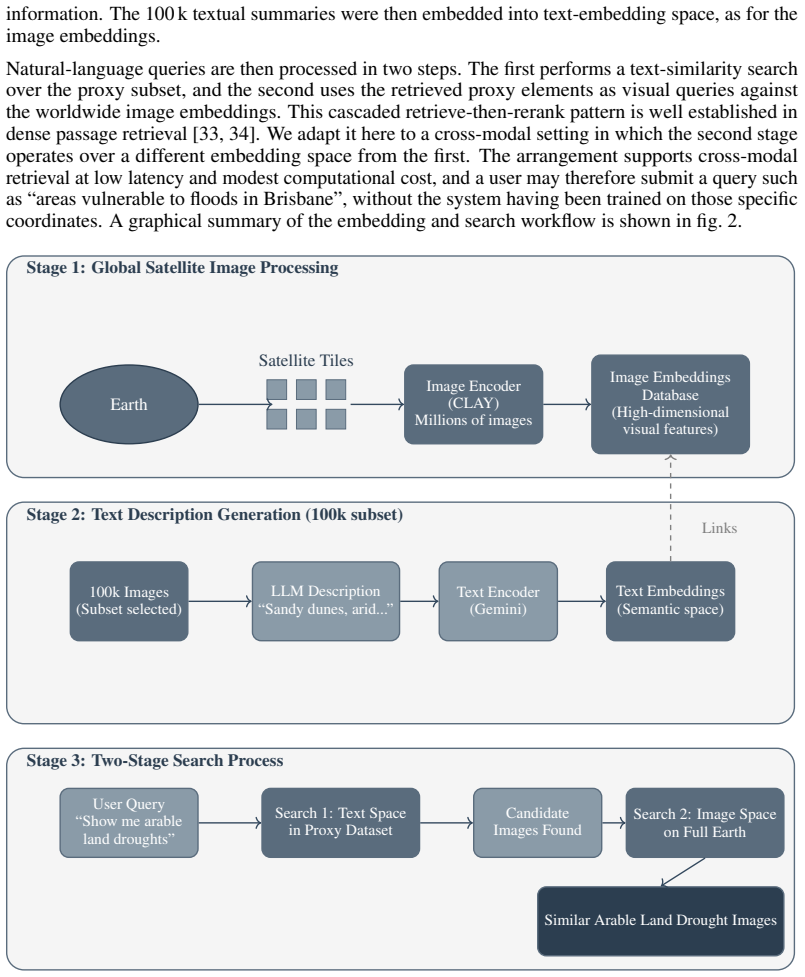
GeoQuery produces language descriptions for a 100k proxy subset of global Sentinel-2 tiles and tunes the generation prompt until distances among the resulting text embeddings correlate with distances among the corresponding frozen CLAY visual embeddings. A query is answered by first retrieving similar descriptions from the proxy via text similarity and then running visual nearest-neighbor search over the full worldwide CLAY collection. On 76 disaster-location queries the method returns a tile within 50 km of the true site 31.6 percent of the time, rising to 50 percent on flood queries where terrain features are captured by RGB imagery. The same system was used inside a crisis platform to map
What carries the argument
The prompt-optimized proxy subset that creates a text embedding space whose distances serve as a stand-in for the full visual embedding space in a two-stage retrieval pipeline.
If this is right
- Natural language queries become feasible over global-scale Earth observation archives without full contrastive training.
- The approach can be inserted into existing crisis-response platforms to surface vulnerable areas during events such as cyclones.
- Retrieval accuracy is highest for phenomena whose visual signatures are captured well by RGB imagery, such as floods.
- Prompt-aligned proxies supply a workable substitute for joint training whenever paired data or compute are unavailable.
Where Pith is reading between the lines
- The same proxy-alignment idea could be tested on queries about land-cover change or infrastructure rather than disasters.
- Selecting a still smaller or more diverse proxy might preserve performance while lowering the cost of prompt optimization.
- Adding temporal or multi-spectral information to the visual stage could improve results on queries that depend on time or non-RGB bands.
Load-bearing premise
Optimizing the description-generation prompt on the 100k proxy subset creates text-embedding distances that correlate closely enough with the frozen visual distances to make the two-stage search work reliably on new queries.
What would settle it
A new collection of disaster queries on which the text proxy search repeatedly returns tiles that lie far from the ground-truth location when measured in CLAY visual space.
Figures












read the original abstract
Semantic search of Earth observation archives remains challenging. Visual foundation models such as CLAY produce rich embeddings of satellite imagery but lack the natural-language grounding needed for intuitive query, and full contrastive training of a remote-sensing CLIP-style model requires paired data and compute that are unavailable at global scale. To allow natural language querying at global scales, we present GeoQuery, a zero-shot retrieval system that sidesteps data and compute constraints through a two-stage semantic and visual search, leveraging a natural language embedding of a subset (proxy) of global data. Rather than training a joint encoder, we generate language descriptions for a 100k proxy subset of global Sentinel-2 tiles and optimise the description-generation prompt so that distances in the resulting text-embedding space correlate with distances in the frozen CLAY visual-embedding space. Queries are resolved in two stages, with a text-similarity search over the proxy subset followed by a visual nearest-neighbour search over worldwide CLAY embeddings On 76 disaster-location queries covering UK floods, US wildfires, and US droughts, GeoQuery achieves 31.6\% accuracy within 50\,km, with the strongest performance on floods (50\% within 50\,km) where terrain features are well captured by RGB embeddings. Deployed within a crisis response system called \ECHO{}, GeoQuery identified vulnerable areas during Brisbane's 2025 Cyclone Alfred, with downstream flood simulations reproducing historical patterns. Prompt-aligned proxies offer a practical bridge between EO foundation models and operational retrieval when full contrastive training is out of reach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GeoQuery, a zero-shot satellite image retrieval system for Earth observation archives. It generates natural-language descriptions for a 100k proxy subset of global Sentinel-2 tiles, optimizes the description-generation prompt to align text-embedding distances with frozen CLAY visual embeddings, performs text-similarity search over the proxy, and follows with visual nearest-neighbor search over worldwide CLAY embeddings. On 76 disaster-location queries (UK floods, US wildfires, US droughts) it reports 31.6% accuracy within 50 km (50% on floods), and demonstrates deployment in the ECHO crisis-response system for Cyclone Alfred in Brisbane.
Significance. If the prompt-optimization step produces a reliable correlation between text and visual distances, the method supplies a practical, low-compute route to natural-language querying of global EO archives when full contrastive training of a remote-sensing CLIP-style model is infeasible. The concrete accuracy numbers on disaster queries and the real-world deployment example indicate potential operational value for crisis response where RGB terrain features are discriminative.
major comments (2)
- [Abstract] Abstract: the claim that prompt optimization makes text-embedding distances a useful proxy for frozen CLAY visual distances is load-bearing for the two-stage retrieval, yet the manuscript provides no quantitative validation of this correlation (no Pearson/Spearman coefficient on distance matrices, no distance-matrix comparison, and no ablation that removes the optimization step). Consequently the reported 31.6% accuracy cannot be distinguished from query-set bias.
- [Abstract] Abstract: the evaluation reports 31.6% accuracy (50% on floods) within 50 km on 76 queries but supplies neither error bars, nor selection criteria or diversity statistics for the query set, nor any test of generalization beyond the proxy distribution used for prompt optimization. These omissions prevent assessment of whether the numbers support the zero-shot claim.
minor comments (1)
- [Abstract] Abstract: the acronym ECHO is introduced without prior expansion or definition.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our manuscript. We address each of the major comments point by point below. We have made revisions to the manuscript to incorporate additional analyses and clarifications as detailed in our responses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that prompt optimization makes text-embedding distances a useful proxy for frozen CLAY visual distances is load-bearing for the two-stage retrieval, yet the manuscript provides no quantitative validation of this correlation (no Pearson/Spearman coefficient on distance matrices, no distance-matrix comparison, and no ablation that removes the optimization step). Consequently the reported 31.6% accuracy cannot be distinguished from query-set bias.
Authors: We agree that explicit quantitative validation of the correlation between text-embedding and visual-embedding distances would strengthen the manuscript. Although the prompt optimization was performed to align the distances on the proxy subset, we did not report correlation coefficients or an ablation in the original submission. In the revised manuscript, we will include Pearson and Spearman correlation coefficients computed between the distance matrices on a held-out portion of the proxy data. We will also add an ablation study comparing retrieval performance with and without the prompt optimization step. These additions will help demonstrate that the optimization contributes meaningfully beyond any potential query-set bias. revision: yes
-
Referee: [Abstract] Abstract: the evaluation reports 31.6% accuracy (50% on floods) within 50 km on 76 queries but supplies neither error bars, nor selection criteria or diversity statistics for the query set, nor any test of generalization beyond the proxy distribution used for prompt optimization. These omissions prevent assessment of whether the numbers support the zero-shot claim.
Authors: We acknowledge the need for more rigorous statistical reporting and details on the evaluation setup. The 76 queries were chosen to cover a range of disaster types (floods, wildfires, droughts) and geographic regions (UK, US) to provide diversity. In the revised manuscript, we will add error bars using bootstrap resampling, explicit criteria for query selection, diversity statistics (e.g., geographic spread and event type distribution), and an additional experiment evaluating performance on a set of queries from regions or event types not represented in the proxy optimization set to better support the zero-shot generalization claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation proceeds by optimizing a description-generation prompt on a 100k proxy subset to encourage correlation between text-embedding distances and frozen CLAY visual distances, followed by two-stage retrieval (text NN on proxy then visual NN globally) and evaluation on 76 held-out disaster-location queries. The reported accuracy (31.6% within 50 km) is computed on these separate queries rather than the optimization set or any fitted parameter directly tied to the test metric. No equations, self-citations, or ansatzes are presented that reduce the central retrieval result to a tautological restatement of the proxy optimization inputs. The chain therefore contains independent content and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- prompt optimization objective
axioms (1)
- domain assumption CLAY embeddings are suitable for capturing terrain features relevant to floods, wildfires, and droughts
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
optimise the description-generation prompt so that distances in the resulting text-embedding space correlate with distances in the frozen CLAY visual-embedding space
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage semantic and visual search
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Clay foundation model: An open source AI model for earth
Clay Foundation. Clay foundation model: An open source AI model for earth. https: //github.com/Clay-foundation/model, 2024. Version 1.5. Pretrained Vision Transformer with masked autoencoder objective on approximately 70 million globally sampled chips from Sentinel-2, Landsat, Sentinel-1 SAR, LINZ, NAIP, and MODIS
work page 2024
-
[2]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision.CoRR, abs/2103.00020, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Le, Yunhsuan Sung, Zhen Li, and Tom Duerig
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V . Le, Yunhsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InProceedings of the 38th International Conference on Machine Learning (ICML), volume 139 ofProceedings of Machine Learning Research, pages 49...
work page 2021
-
[4]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InProceedings of the 39th International Conference on Machine Learning (ICML), volume 162 ofProceedings of Machine Learning Research, pages 12888–12900. PMLR, 2022
work page 2022
-
[5]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11975–11986, 2023
work page 2023
-
[6]
Prithvi-eo-2.0: A versatile multi-temporal foundation model for earth observation applications, 2025
Daniela Szwarcman, Sujit Roy, Paolo Fraccaro, Þorsteinn Elí Gíslason, Benedikt Blumenstiel, Rinki Ghosal, Pedro Henrique de Oliveira, Joao Lucas de Sousa Almeida, Rocco Sedona, Yanghui Kang, Srija Chakraborty, Sizhe Wang, Carlos Gomes, Ankur Kumar, Myscon Truong, Denys Godwin, Hyunho Lee, Chia-Yu Hsu, Ata Akbari Asanjan, Besart Mujeci, Disha Shid- ham, Tr...
work page 2025
-
[7]
Yezhen Cong, Samar Khanna, Chenlin Meng, Patrick Liu, Erik Rozi, Yutong He, Marshall Burke, David B. Lobell, and Stefano Ermon. Satmae: Pre-training transformers for temporal and multi-spectral satellite imagery, 2023
work page 2023
-
[8]
Colorado J. Reed, Ritwik Gupta, Shufan Li, Sarah Brockman, Christopher Funk, Brian Clipp, Kurt Keutzer, Salvatore Candido, Matt Uyttendaele, and Trevor Darrell. Scale-MAE: A scale- aware masked autoencoder for multiscale geospatial representation learning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4088–4099, 2023
work page 2023
-
[9]
SatlasPretrain: A large-scale dataset for remote sensing image understanding
Favyen Bastani, Piper Wolters, Ritwik Gupta, Joe Ferdinando, and Aniruddha Kembhavi. SatlasPretrain: A large-scale dataset for remote sensing image understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 16772–16782, 2023. 6
work page 2023
-
[10]
Danfeng Hong, Bing Zhang, Xuyang Li, Yuxuan Li, Chenyu Li, Jing Yao, Naoto Yokoya, Hao Li, Pedram Ghamisi, Xiuping Jia, Antonio Plaza, Paolo Gamba, Jon Atli Benediktsson, and Jocelyn Chanussot. SpectralGPT: Spectral remote sensing foundation model.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5227–5244, 2024
work page 2024
-
[11]
Zhitong Xiong, Yi Wang, Fahong Zhang, Adam J. Stewart, Joëlle Hanna, Damian Borth, Ioannis Papoutsis, Bertrand Le Saux, Gustau Camps-Valls, and Xiao Xiang Zhu. Neural plasticity-inspired multimodal foundation model for earth observation, 2024
work page 2024
-
[12]
Aoran Xiao, Weihao Xuan, Junjue Wang, Jiaxing Huang, Dacheng Tao, Shijian Lu, and Naoto Yokoya. Foundation models for remote sensing and earth observation: A survey.IEEE Geoscience and Remote Sensing Magazine, 2025. In press
work page 2025
-
[13]
GEO-Bench: Toward foundation models for earth monitoring
Alexandre Lacoste, Nils Lehmann, Pau Rodriguez, Evan David Sherwin, Hannah Kerner, Björn Lütjens, Jeremy Andrew Irvin, David Dao, Hamed Alemohammad, Alexandre Drouin, Mehmet Gunturkun, Gabriel Huang, David Vazquez, Dava Newman, Yoshua Bengio, Stefano Ermon, and Xiao Xiang Zhu. GEO-Bench: Toward foundation models for earth monitoring. InAdvances in Neural ...
work page 2023
-
[14]
Zilun Zhang, Tiancheng Zhao, Yulong Guo, and Jianwei Yin. Rs5m and georsclip: A large- scale vision- language dataset and a large vision-language model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, 62:1–23, 2024
work page 2024
-
[15]
Remoteclip: A vision language foundation model for remote sensing, 2024
Fan Liu, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Qiaolin Ye, Liyong Fu, and Jun Zhou. Remoteclip: A vision language foundation model for remote sensing, 2024
work page 2024
-
[16]
SkyScript: A large and semantically diverse vision-language dataset for remote sensing
Zhecheng Wang, Rajanie Prabha, Tianyuan Huang, Jiajun Wu, and Ram Rajagopal. SkyScript: A large and semantically diverse vision-language dataset for remote sensing. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 5805–5813, 2024
work page 2024
-
[17]
Stewart, Jie Zhao, Nils Lehmann, Thomas Dujardin, Zhenghang Yuan, Pedram Ghamisi, and Xiao Xiang Zhu
Zhitong Xiong, Yi Wang, Weikang Yu, Adam J. Stewart, Jie Zhao, Nils Lehmann, Thomas Dujardin, Zhenghang Yuan, Pedram Ghamisi, and Xiao Xiang Zhu. DOFA-CLIP: Multimodal vision-language foundation models for earth observation, 2025
work page 2025
-
[18]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), 2023
work page 2023
-
[19]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InProceedings of the 11th International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[20]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation. InProceedings of the 1st Conference on Language Modeling (COLM), 2024
work page 2024
-
[21]
Chemcrow: Augmenting large-language models with chemistry tools, 2023
Andres M Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D White, and Philippe Schwaller. Chemcrow: Augmenting large-language models with chemistry tools, 2023
work page 2023
-
[22]
Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624(7992):570–578, December 2023
work page 2023
-
[23]
Alireza Ghafarollahi and Markus J. Buehler. ProtAgents: Protein discoveryvialarge language model multi-agent collaborations combining physics and machine learning.Digital Discovery, 3(7):1389–1409, 2024
work page 2024
-
[24]
Yifan Zhang, Cheng Wei, Zhengting He, and Wenhao Yu. Geogpt: An assistant for understand- ing and processing geospatial tasks.International Journal of Applied Earth Observation and Geoinformation, 131:103976, 2024. 7
work page 2024
-
[25]
Derrick Bonafilia, Beth Tellman, Tyler Anderson, and Erica Issenberg. Sen1Floods11: A georeferenced dataset to train and test deep learning flood algorithms for Sentinel-1. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 210–211, 2020
work page 2020
-
[26]
Gonzalo Mateo-Garcia, Joshua Veitch-Michaelis, Lewis Smith, Silviu Vlad Oprea, Guy Schu- mann, Yarin Gal, Atılım Güne¸ s Baydin, and Dietmar Backes. Towards global flood mapping onboard low cost satellites with machine learning.Scientific Reports, 11(1):7249, 2021
work page 2021
-
[27]
xBD: A dataset for assessing building damage from satellite imagery, 2019
Ritwik Gupta, Richard Hosfelt, Sandra Sajeev, Nirav Patel, Bryce Goodman, Jigar Doshi, Eric Heim, Howie Choset, and Matthew Gaston. xBD: A dataset for assessing building damage from satellite imagery, 2019
work page 2019
- [28]
-
[29]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, 2024
Gemini Team Google. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, 2024
work page 2024
-
[30]
Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with “gradient descent” and beam search. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7957–7968, Singapore, December 2023. Association for Computati...
work page 2023
-
[31]
Le, Denny Zhou, and Xinyun Chen
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V . Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. InProceedings of the 12th International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[32]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. DSPy: Compiling declarative language model calls into state-of-the-art pipelines. InProceedings of the 12th International Conference on Learning...
work page 2024
-
[33]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas O ˘guz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781. Association for Computational Linguistics, 2020
work page 2020
-
[34]
ColBERT: Efficient and effective passage search via con- textualized late interaction over BERT
Omar Khattab and Matei Zaharia. ColBERT: Efficient and effective passage search via con- textualized late interaction over BERT. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), pages 39–48, 2020
work page 2020
-
[35]
PlaNet - photo geolocation with convolu- tional neural networks
Tobias Weyand, Ilya Kostrikov, and James Philbin. PlaNet - photo geolocation with convolu- tional neural networks. InComputer Vision – ECCV 2016, volume 9912 ofLecture Notes in Computer Science, pages 37–55. Springer, 2016
work page 2016
-
[36]
Open Source Geospatial Foundation, 2025
GDAL/OGR contributors.GDAL/OGR Geospatial Data Abstraction software Library. Open Source Geospatial Foundation, 2025
work page 2025
-
[37]
Kelsey Jordahl et al. geopandas/geopandas: v0.6.1, October 2019. A GeoQuery Ablation Study A.1 Experimental Setup We evaluated GeoQuery’s disaster location identification capability using 76 queries across three categories: 40 UK flood queries (testing 10 major 2024 flooding locations including Stratford-upon- Avon, Birmingham, and Portsmouth), 20 US wild...
work page 2019
-
[38]
Risk identification via external monitoring (e.g., meteorological alerts for severe rainfall)
-
[39]
The risk is developed into a “project” defined spatially and temporally. These extents permit the bounds for digital twinning of infrastructure and topography, a core foundation for downstream simulation and scenario building. For example, a possible flood event triggered by 48 hours of intense rainfall in Australia, as alerted by a national meteorological agency
-
[40]
Once enough information is collected on a given project, experts may begin to define the nature of the inquiry. ECHO supports requests to specify which real-time data streams must be monitored first, simulate crisis events, and finally define alerting procedures as information is ingested. For example, five-meter digital elevation maps are downloaded alon...
-
[41]
These highly granular assets are then accessible to an expert to rapidly define the line of geospatial inquiry and identify risks unknown to the automated system. For example, requesting a flood model and evaluation of which buildings may be suitable for sheltering at-risk individuals in place
-
[42]
A crisis responder or member of the public may then request hyper-localised information from the contextually aware agent. For example: identifying a safe route for a specific vehicle type such as determining which roads are likely to be inaccessible to an ambulance or family car. For any of the steps above to be possible, we require a means to construct ...
work page 2025
-
[43]
Disaster Risk Analysis For requests about assessing disaster risks (fire, floods, earthquakes, etc.), ensure the query includes: - Location of interest - Time horizon - Type of disaster Example 1: Previous context: Take me to valencia Current state variables available: {"data": bbox"} User Input: Can you determine if this area is flood prone over the next...
-
[44]
Show me images of oceans near deserts
Satellite Image Search For general satellite image queries that don’t involve disaster risk (e.g., "Show me images of oceans near deserts"). These queries do not require a time horizon, nor a specific location. Feel confident to pass on such queries to the planner as long as no disasters are mentioned. Example 1: User input: show me forests Output: {’stat...
-
[45]
Start with OSM_Geocode for location queries
-
[46]
Use ’after’ for dependencies
-
[47]
Empty ’after’ means step can start immediately
-
[48]
Input/output must match tool definitions exactly
-
[49]
Use only listed tools
-
[50]
OSM Points of Interest should only be used when looking for specific physical infrastructure tags **{examples}** Return only valid JSON matching this format using listed tools. B.5 Planner User Prompt Create a logical tool sequence plan for: ‘‘‘{query}‘‘‘ Here are all previous messages between the user and the planner: **{conversation_history}** Here are ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.