Recognition: unknown
From History to State: Constant-Context Skill Learning for LLM Agents
Pith reviewed 2026-05-08 16:45 UTC · model grok-4.3
The pith
LLM agents replace growing prompt histories with compact state blocks and learned task-family modules to cut context length while matching strong benchmark results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
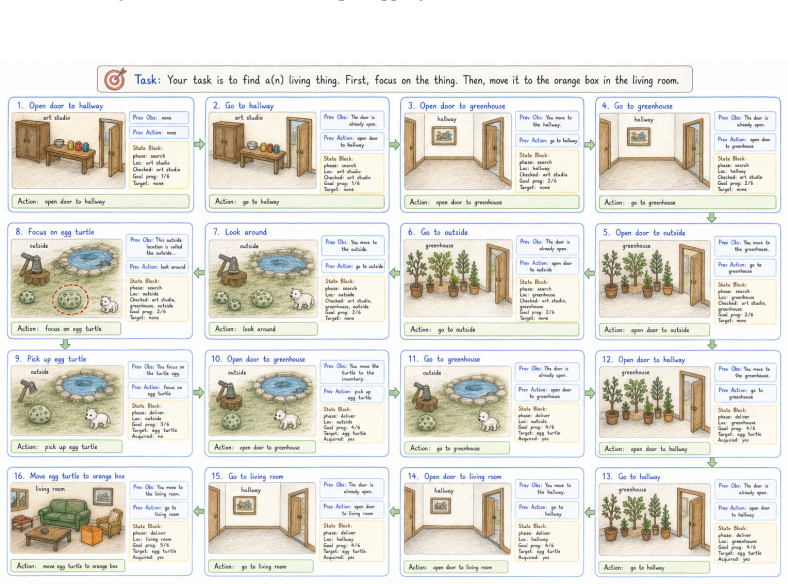
Reusable procedures for agent tasks are learned into lightweight task-family modules; inference uses only the current observation and a compact state block produced by a deterministic tracker that also supplies aligned subgoal rewards, so each module trains via step-level SFT and is refined by online RL. With this constant-context regime, Qwen3-8B reaches 89.6% unseen success on ALFWorld, 76.8% success on WebShop, and 66.4% unseen success on SciWorld while cutting prompt tokens per turn by 2-7x relative to controlled ReAct prompting.
What carries the argument
Constant-context skill learning via task-family modules conditioned on current observation and a compact state block rendered by a deterministic progress tracker.
If this is right
- Agents maintain high task success without accumulating full interaction histories in every prompt.
- SFT followed by RL using tracker-supplied subgoal rewards refines each module for the target task family.
- The same approach works across base models including Qwen3-4B, Qwen3-8B, and Llama-3.1-8B.
- Token usage per turn drops by factors of 2-7 relative to standard history-based prompting on the tested benchmarks.
Where Pith is reading between the lines
- Local deployment becomes more attractive because far less intermediate context leaves the device.
- Many everyday agent tasks appear to possess modular structure that can be pre-learned once and reused.
- The method may scale to domains where workflows are harder to partition if richer state representations are developed.
Load-bearing premise
Recurring agent workflows can be cleanly partitioned into task-family modules whose compact state block captures all necessary history and progress information without loss of critical context.
What would settle it
Replace the state block with an empty or randomly generated block on the same ALFWorld, WebShop, and SciWorld tasks and measure whether success rates fall substantially below the reported 89.6%, 76.8%, and 66.4% figures.
Figures





read the original abstract
Large language model (LLM) agents are increasingly used to operate browsers, files, code and tools, making personal assistants a natural deployment target. Yet personal agents face a privacy-cost-capability tension: cloud models execute multi-step workflows well but expose sensitive intermediate context to external APIs, while local models preserve privacy but remain less reliable. Both settings also pay repeatedly for long skill prompts and growing histories. We propose constant-context skill learning, a context-to-weights framework for recurring agent workflows: reusable procedures are learned in lightweight task-family modules, while inference conditions only on the current observation and a compact state block. A deterministic tracker renders this state block from task progress and supplies aligned subgoal rewards, so each module can be trained with step-level SFT and refined through online RL. Across ALFWorld, WebShop, and SciWorld, our agents achieve strong performance across Qwen3-4B, Qwen3-8B and Llama-3.1-8B. With Qwen3-8B, SFT+RL reaches 89.6\% unseen success on ALFWorld, 76.8\% success on WebShop, and 66.4\% unseen success on SciWorld. They match or exceed strong published agent-training results while reducing prompt tokens per turn by 2--7$\times$ relative to controlled ReAct prompting baselines, showing that procedural context can be moved from prompts into weights.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes constant-context skill learning for LLM agents: recurring workflows are partitioned into lightweight task-family modules whose procedural history is moved into weights via SFT+RL training; at inference only the current observation and a compact state block (produced by a deterministic tracker that also supplies subgoal rewards) are provided. On ALFWorld, WebShop and SciWorld the method reports 89.6% unseen success (Qwen3-8B), 76.8% success and 66.4% unseen success respectively, matching or exceeding prior agent-training results while cutting prompt tokens per turn by 2–7× versus controlled ReAct baselines.
Significance. If the central claim holds, the work offers a practical route to privacy-preserving and token-efficient local agents by embedding reusable procedures in model weights rather than long prompts. The reported numbers on three distinct environments and multiple base models constitute a concrete empirical contribution, though their interpretability depends on the missing controls noted below.
major comments (2)
- [Methods (tracker and state-block construction)] The central claim that the deterministic tracker’s compact state block is informationally complete for unseen tasks is load-bearing, yet no ablations are described that remove or corrupt individual elements (subgoal progress flags, observation summaries, etc.) and measure the resulting drop in success rate or change in failure modes on held-out tasks. Without such evidence it remains possible that the 89.6% ALFWorld figure relies on environment-specific tracker engineering rather than a general constant-context mechanism.
- [Results / Experiments] The abstract and results sections report concrete success rates and token reductions but supply no details on baselines, variance across seeds, data splits, or exact training procedures (hyper-parameters, number of RL steps, reward shaping). This absence prevents verification that the numbers support the stated claims.
minor comments (1)
- [Results] The token-reduction claim (2–7×) would be clearer if accompanied by per-environment tables showing exact token counts for the ReAct baselines versus the proposed method.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for identifying areas where additional evidence and transparency would strengthen the manuscript. We respond to each major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: The central claim that the deterministic tracker’s compact state block is informationally complete for unseen tasks is load-bearing, yet no ablations are described that remove or corrupt individual elements (subgoal progress flags, observation summaries, etc.) and measure the resulting drop in success rate or change in failure modes on held-out tasks. Without such evidence it remains possible that the 89.6% ALFWorld figure relies on environment-specific tracker engineering rather than a general constant-context mechanism.
Authors: We appreciate the referee highlighting the need to directly validate informational completeness. The tracker is deterministic by construction and encodes only task progress and subgoal information that is required for the current step, with no environment-specific heuristics beyond the task definition itself. The fact that the same framework yields strong unseen-task performance across three dissimilar environments (ALFWorld, WebShop, SciWorld) already indicates that the state block is not narrowly engineered. Nevertheless, we agree that targeted ablations would provide clearer evidence. In the revised manuscript we will add a dedicated ablation study that removes or perturbs individual state-block fields (subgoal flags, observation summaries, etc.) and reports the resulting success-rate drops and failure-mode shifts on held-out tasks. This will isolate the contribution of each element and further support the generality of the constant-context approach. revision: yes
-
Referee: The abstract and results sections report concrete success rates and token reductions but supply no details on baselines, variance across seeds, data splits, or exact training procedures (hyper-parameters, number of RL steps, reward shaping). This absence prevents verification that the numbers support the stated claims.
Authors: We agree that reproducibility requires explicit experimental details. While the manuscript already identifies the baselines as controlled ReAct prompting and describes the overall training pipeline (SFT followed by online RL with tracker-supplied rewards), we acknowledge that variance, split definitions, and hyper-parameter values are not reported at the level needed for verification. In the revision we will expand the Experiments and Results sections with: (i) success rates reported as mean ± standard deviation over multiple random seeds, (ii) precise descriptions of the seen/unseen data splits used for each environment, and (iii) a table listing all hyper-parameters, the number of RL steps, batch sizes, and the exact reward-shaping functions employed by the deterministic tracker. These additions will enable readers to fully reproduce and assess the reported success rates and token reductions. revision: yes
Circularity Check
No circularity: empirical training recipe with no derivations or self-referential reductions.
full rationale
The paper describes an empirical method for constant-context skill learning via task-family modules, deterministic trackers for state blocks, SFT, and RL. No equations, closed-form derivations, or load-bearing self-citations are present that reduce predictions to fitted inputs or prior author results by construction. Results are benchmarked externally on ALFWorld, WebShop, and SciWorld against published baselines, satisfying the self-contained criterion for score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agent skills
Anthropic. Agent skills. https://platform.claude.com/docs/en/agents-and-tools/ agent-skills/overview, 2026. Accessed: 2026-05-04
2026
-
[2]
Claude opus 4.7
Anthropic. Claude opus 4.7. https://www.anthropic.com/news/claude-opus-4-7 , 2026. Accessed: 2026-05-01
2026
-
[3]
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, et al. Lightmem: Lightweight and efficient memory-augmented generation. arXiv preprint arXiv:2510.18866, 2025
-
[4]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
Dayuan Fu, Keqing He, Yejie Wang, Wentao Hong, Zhuoma Gongque, Weihao Zeng, Wei Wang, Jingang Wang, Xunliang Cai, and Weiran Xu. Agentrefine: Enhancing agent generalization through refinement tuning.arXiv preprint arXiv:2501.01702, 2025
-
[6]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine-tuning for large models: A comprehensive survey.arXiv preprint arXiv:2403.14608, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
Word-based dialog state tracking with recurrent neural networks
Matthew Henderson, Blaise Thomson, and Steve Young. Word-based dialog state tracking with recurrent neural networks. InProceedings of the 15th annual meeting of the special interest group on discourse and dialogue (SIGDIAL), pages 292–299, 2014
2014
-
[8]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Ges- mundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
2019
-
[9]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[10]
Llmlingua: Compressing prompts for accelerated inference of large language models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compressing prompts for accelerated inference of large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 13358–13376, 2023
2023
-
[11]
Hierarchical deep reinforce- ment learning: Integrating temporal abstraction and intrinsic motivation.Advances in neural information processing systems, 29, 2016
Tejas D Kulkarni, Karthik Narasimhan, Ardavan Saeedi, and Josh Tenenbaum. Hierarchical deep reinforce- ment learning: Integrating temporal abstraction and intrinsic motivation.Advances in neural information processing systems, 29, 2016
2016
-
[12]
Beyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models
Yubo Li, Xiaobin Shen, Xinyu Yao, Xueying Ding, Yidi Miao, Ramayya Krishnan, and Rema Padman. Beyond single-turn: A survey on multi-turn interactions with large language models.arXiv preprint arXiv:2504.04717, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Sage: Self-evolving agents with reflective and memory-augmented abilities.Neurocomputing, 647:130470, 2025
Xuechen Liang, Meiling Tao, Yinghui Xia, Jianhui Wang, Kun Li, Yijin Wang, Yangfan He, Jingsong Yang, Tianyu Shi, Yuantao Wang, et al. Sage: Self-evolving agents with reflective and memory-augmented abilities.Neurocomputing, 647:130470, 2025
2025
-
[14]
Prompt compression with context-aware sentence encoding for fast and improved llm inference
Barys Liskavets, Maxim Ushakov, Shuvendu Roy, Mark Klibanov, Ali Etemad, and Shane K Luke. Prompt compression with context-aware sentence encoding for fast and improved llm inference. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24595–24604, 2025
2025
-
[15]
Large language model-based planning agent with generative memory strengthens performance in textualized world.Engineering Applications of Artificial Intelligence, 148:110319, 2025
Junyang Liu, Wenning Hao, Kai Cheng, and Dawei Jin. Large language model-based planning agent with generative memory strengthens performance in textualized world.Engineering Applications of Artificial Intelligence, 148:110319, 2025
2025
-
[16]
Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
2024
-
[17]
Odyssey: Empowering minecraft agents with open-world skills.arXiv preprint arXiv:2407.15325, 2024
Shunyu Liu, Yaoru Li, Kongcheng Zhang, Zhenyu Cui, Wenkai Fang, Yuxuan Zheng, Tongya Zheng, and Mingli Song. Odyssey: Empowering minecraft agents with open-world skills.arXiv preprint arXiv:2407.15325, 2024
-
[18]
Agentic critical training.arXiv preprint arXiv:2603.08706, 2026
Weize Liu, Minghui Liu, Sy-Tuyen Ho, Souradip Chakraborty, Xiyao Wang, and Furong Huang. Agentic critical training.arXiv preprint arXiv:2603.08706, 2026
-
[19]
Zeyuan Liu, Jeonghye Kim, Xufang Luo, Dongsheng Li, and Yuqing Yang. Exploratory memory- augmented llm agent via hybrid on-and off-policy optimization.arXiv preprint arXiv:2602.23008, 2026. 10
-
[20]
Learning to compress prompts with gist tokens.Advances in Neural Information Processing Systems, 36:19327–19352, 2023
Jesse Mu, Xiang Li, and Noah Goodman. Learning to compress prompts with gist tokens.Advances in Neural Information Processing Systems, 36:19327–19352, 2023
2023
-
[21]
Policy invariance under reward transformations: Theory and application to reward shaping
Andrew Y Ng, Daishi Harada, and Stuart Russell. Policy invariance under reward transformations: Theory and application to reward shaping. InIcml, volume 99, pages 278–287. Citeseer, 1999
1999
-
[22]
Introducing gpt-5.5
OpenAI. Introducing gpt-5.5. https://openai.com/index/introducing-gpt-5-5/ , 2026. Accessed: 2026-05-01
2026
-
[23]
Openclaw — personal ai assistant
OpenClaw. Openclaw — personal ai assistant. https://openclaw.ai/, 2026. Accessed: 2026-05- 01
2026
-
[24]
Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems, 37:126544–126565, 2024
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems, 37:126544–126565, 2024
2024
-
[25]
Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539–68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539–68551, 2023
2023
-
[26]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review arXiv 2024
-
[27]
Direct multi-turn preference optimization for language agents
Wentao Shi, Mengqi Yuan, Junkang Wu, Qifan Wang, and Fuli Feng. Direct multi-turn preference optimization for language agents. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2312–2324, 2024
2024
-
[28]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[29]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2020
work page internal anchor Pith review arXiv 2010
-
[30]
Remem: Reasoning with episodic memory in language agent.arXiv preprint arXiv:2602.13530, 2026
Yiheng Shu, Saisri Padmaja Jonnalagedda, Xiang Gao, Bernal Jiménez Gutiérrez, Weijian Qi, Kamalika Das, Huan Sun, and Yu Su. Remem: Reasoning with episodic memory in language agent.arXiv preprint arXiv:2602.13530, 2026
-
[31]
Trial and error: Exploration- based trajectory optimization of llm agents
Yifan Song, Da Yin, Xiang Yue, Jie Huang, Sujian Li, and Bill Yuchen Lin. Trial and error: Exploration- based trajectory optimization of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7584–7600, 2024
2024
-
[32]
Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2):181–211, 1999
Richard S Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2):181–211, 1999
1999
-
[33]
Qwen Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review arXiv 2023
-
[35]
Scienceworld: Is your agent smarter than a 5th grader? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11279–11298, 2022
Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, and Prithviraj Ammanabrolu. Scienceworld: Is your agent smarter than a 5th grader? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11279–11298, 2022
2022
-
[36]
Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
Lingling Xu, Haoran Xie, S Joe Qin, Xiaohui Tao, and Fu Lee Wang. Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[37]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review arXiv 2025
-
[38]
Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024. 11
2024
-
[39]
Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35: 20744–20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35: 20744–20757, 2022
2022
-
[40]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[41]
Guibin Zhang, Muxin Fu, and Shuicheng Yan. Memgen: Weaving generative latent memory for self- evolving agents.arXiv preprint arXiv:2509.24704, 2025
-
[42]
Agent learning via early experience.arXiv preprint arXiv:2510.08558, 2025
Kai Zhang, Xiangchao Chen, Bo Liu, Tianci Xue, Zeyi Liao, Zhihan Liu, Xiyao Wang, Yuting Ning, Zhaorun Chen, Xiaohan Fu, et al. Agent learning via early experience.arXiv preprint arXiv:2510.08558, 2025
-
[43]
A probabilistic end-to-end task-oriented dialog model with latent belief states towards semi-supervised learning
Yichi Zhang, Zhijian Ou, Min Hu, and Junlan Feng. A probabilistic end-to-end task-oriented dialog model with latent belief states towards semi-supervised learning. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9207–9219, 2020
2020
-
[44]
A survey on the memory mechanism of large language model-based agents.ACM Transactions on Information Systems, 43(6):1–47, 2025
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji- Rong Wen. A survey on the memory mechanism of large language model-based agents.ACM Transactions on Information Systems, 43(6):1–47, 2025
2025
-
[45]
arXiv preprint arXiv:2402.19446 , year=
Yifei Zhou, Andrea Zanette, Jiayi Pan, Sergey Levine, and Aviral Kumar. Archer: Training language model agents via hierarchical multi-turn rl.arXiv preprint arXiv:2402.19446, 2024. 12 7 Technical appendices and supplementary material 7.1 Training Details and Hyperparameters All three benchmarks provide expert trajectories, which we use directly to constru...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.