Recognition: unknown
Privacy Without Losing Place: A Paradigm for Private Retrieval in Spatial RAGs
Pith reviewed 2026-05-08 16:13 UTC · model grok-4.3
The pith
PAS provides 370-400m location privacy in spatial RAG while keeping over half the retrieval performance and robust generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
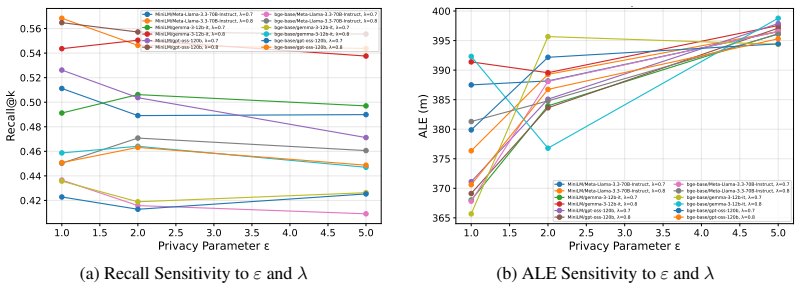
PAS represents locations through relative anchor encoding of an anchor, direction bin, and distance bin to enable private spatial retrieval in RAG. Evaluations on a synthetic urban dataset demonstrate approximately 370-400m adversarial location error with more than half of baseline retrieval performance retained. Downstream generation quality remains robust as LLMs compensate for imperfect retrieval. PAS shows a non-monotonic privacy-utility relationship due to geometric bias from anchor discretization, differing from continuous mechanisms like geo-indistinguishability. Structured spatial representations thus offer a practical path to privacy in location-based reasoning within RAG systems.
What carries the argument
Privacy Anchor Substitution (PAS) using relative anchor encoding with direction and distance bins to substitute direct location data in retrieval queries.
If this is right
- Approximately 370-400 meters of adversarial error is achieved for location privacy.
- More than half of the baseline retrieval performance is retained.
- Downstream LLM generation quality stays comparatively robust.
- Privacy and utility follow a non-monotonic relationship caused by discretization bias.
Where Pith is reading between the lines
- Structured encodings like PAS could extend privacy protections to other location-dependent AI tasks without full noise addition.
- The compensation by LLMs for approximate retrieval suggests that intentional approximation might improve efficiency in spatial systems.
- Further examination of the geometric bias may identify anchor and bin choices that optimize the privacy-utility balance.
Load-bearing premise
The synthetic urban dataset together with the adversarial error metric adequately capture real-world spatial queries and privacy threats.
What would settle it
An evaluation of PAS against real-world location traces where the measured adversarial inference error falls significantly below 300 meters or retrieval performance drops below 40 percent of baseline.
Figures





read the original abstract
This work introduces PAS -- Privacy Anchor Substitution, a structured mechanism for enabling user location privacy in spatial retrieval-augmented generation (RAG) systems. Unlike conventional differential privacy methods that directly perturb user locations, PAS represents location with relative anchor encoding consisting of an anchor, direction bin, and distance bin, allowing seamless integration with modern RAG pipelines. We evaluate PAS on a synthetic urban dataset and show that it achieves impressive coarse privacy guarantees, with approximately 370-400m adversarial location error, while retaining more than half of the baseline retrieval performance. Despite the slight drop in retrieval performance, the downstream generation quality under PAS remains comparatively robust, indicating that large language models can compensate for imperfect spatial retrieval. Furthermore, we provide empirical analysis showing that PAS exhibits non-monotonic privacy-utility relationship with respect to privacy parameters. We attribute this to geometric bias induced by anchor discretization, making it different from continuous noise mechanisms such as geo-indistinguishability. Our results show that structured spatial representations offer a practical approach to privacy in location based reasoning in RAG systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Privacy Anchor Substitution (PAS), a structured encoding for user locations in spatial RAG systems using an anchor point together with direction and distance bins. It claims this yields coarse privacy (approximately 370-400 m adversarial location error) while preserving more than half the baseline retrieval performance and maintaining robust downstream LLM generation quality on a synthetic urban dataset. The work also reports a non-monotonic privacy-utility tradeoff attributable to geometric bias from discretization, contrasting with continuous mechanisms such as geo-indistinguishability.
Significance. If the privacy metric reliably captures leakage in the full retrieval-augmented pipeline, PAS offers a practical, non-perturbative alternative to differential privacy for location-aware RAG. The empirical observation of non-monotonic behavior and the demonstration that LLM generation can tolerate imperfect spatial retrieval are useful contributions. The evaluation, however, rests on synthetic data and a direct-inversion adversary model whose relation to end-to-end security is not fully established.
major comments (2)
- Evaluation section: the reported 370-400 m adversarial location error is obtained by direct inversion of the (anchor, direction-bin, distance-bin) encoding alone. Because the RAG pipeline returns concrete spatial documents whose locations are known to the adversary, an intersection attack over the retrieved set could materially reduce the effective error; the current metric therefore does not establish the claimed privacy guarantee for the integrated system.
- Evaluation section: the performance claims (retrieval retention > 50 % of baseline, robust generation quality) are presented without explicit specification of the retrieval baseline, query distribution, bin-parameter selection procedure, or statistical significance testing, leaving the quantitative support for the central utility claim only partially substantiated.
minor comments (2)
- The abstract and evaluation would benefit from a concise statement of the exact bin widths and anchor-selection heuristic used in the reported experiments.
- Figure captions should explicitly label the axes and legend entries corresponding to the non-monotonic curves discussed in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major comment below, agreeing where the evaluation can be strengthened and proposing targeted revisions.
read point-by-point responses
-
Referee: Evaluation section: the reported 370-400 m adversarial location error is obtained by direct inversion of the (anchor, direction-bin, distance-bin) encoding alone. Because the RAG pipeline returns concrete spatial documents whose locations are known to the adversary, an intersection attack over the retrieved set could materially reduce the effective error; the current metric therefore does not establish the claimed privacy guarantee for the integrated system.
Authors: We agree that the current privacy metric evaluates inversion of the PAS encoding in isolation and does not account for an adversary who also observes the locations of the returned documents. This is a valid observation about the threat model. In the revised manuscript we will explicitly state that the reported adversarial error assumes an adversary with access only to the encoded query. We will also add a discussion of intersection attacks as a limitation of the end-to-end guarantee and, using the existing synthetic dataset, include a preliminary quantification of how much the effective error can be reduced by intersecting the retrieved document locations with the possible bins. revision: partial
-
Referee: Evaluation section: the performance claims (retrieval retention > 50 % of baseline, robust generation quality) are presented without explicit specification of the retrieval baseline, query distribution, bin-parameter selection procedure, or statistical significance testing, leaving the quantitative support for the central utility claim only partially substantiated.
Authors: We acknowledge that these experimental details are currently underspecified. In the revised manuscript we will add: (i) a precise description of the retrieval baseline (exact location matching versus embedding similarity without privacy), (ii) the query distribution used on the synthetic urban dataset, (iii) the procedure for choosing anchor locations and bin widths, and (iv) any variance or significance testing performed across runs. These additions will make the utility claims fully reproducible and statistically grounded. revision: yes
Circularity Check
No circularity in empirical evaluation of PAS mechanism
full rationale
The paper introduces PAS as a relative anchor encoding (anchor, direction bin, distance bin) for location privacy in spatial RAGs and reports direct empirical measurements on a synthetic urban dataset: adversarial location error of 370-400m, retrieval performance retention above 50% of baseline, and robust downstream LLM generation quality. No equations, derivations, fitted parameters, or self-citations are shown that reduce these results to inputs defined by the claims themselves. The non-monotonic privacy-utility observation is presented as an empirical finding attributed to geometric bias from discretization, without any self-referential construction or load-bearing prior work by the authors. The evaluation uses held-out synthetic data, rendering the reported guarantees and trade-offs self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschelet al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,”Advances in Neural Information Processing Systems, vol. 33, pp. 9459–9474, 2020
2020
-
[2]
Large language models struggle to learn long-tail knowledge,
N. Kandpal, H. Deng, A. Roberts, E. Wallace, and C. Raffel, “Large language models struggle to learn long-tail knowledge,” inInternational conference on machine learning. PMLR, 2023, pp. 15 696–15 707
2023
-
[3]
Retrieval-Augmented Generation for Large Language Models: A Survey
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, H. Wang, and H. Wang, “Retrieval-augmented generation for large language models: A survey,”arXiv preprint arXiv:2312.10997, vol. 2, no. 1, 2023
work page internal anchor Pith review arXiv 2023
-
[4]
A. Roberts, C. Raffel, and N. Shazeer, “How much knowledge can you pack into the parameters of a language model?”arXiv preprint arXiv:2002.08910, 2020
-
[5]
F. Petroni, T. Rocktäschel, P. Lewis, A. Bakhtin, Y . Wu, A. H. Miller, and S. Riedel, “Language models as knowledge bases?”arXiv preprint arXiv:1909.01066, 2019
-
[6]
K. Zhu, Y . Luo, D. Xu, Y . Yan, Z. Liu, S. Yu, R. Wang, S. Wang, Y . Li, N. Zhanget al., “Rageval: Scenario specific rag evaluation dataset generation framework,”arXiv preprint arXiv:2408.01262, 2024
-
[7]
Leveraging passage retrieval with generative models for open domain question answering
G. Izacard and E. Grave, “Leveraging passage retrieval with generative models for open domain question answering,”arXiv preprint arXiv:2007.01282, 2020
-
[8]
Improving language models by retrieving from trillions of tokens,
S. Borgeaud, A. Mensch, J. Hoffmann, T. Cai, E. Rutherford, K. Millican, G. B. Van Den Driessche, J.-B. Lespiau, B. Damoc, A. Clarket al., “Improving language models by retrieving from trillions of tokens,” in International conference on machine learning. PMLR, 2022, pp. 2206–2240
2022
-
[9]
In-context retrieval-augmented language models,
O. Ram, Y . Levine, I. Dalmedigos, D. Muhlgay, A. Shashua, K. Leyton-Brown, and Y . Shoham, “In-context retrieval-augmented language models,”Transactions of the Association for Computational Linguistics, vol. 11, pp. 1316–1331, 2023
2023
-
[10]
Replug: Retrieval-augmented black-box lan- guage models,
W. Shi, S. Min, M. Yasunaga, M. Seo, R. James, M. Lewis, L. Zettlemoyer, and W.-t. Yih, “Replug: Retrieval-augmented black-box language models,”arXiv preprint arXiv:2301.12652, 2023
-
[11]
Spatial-rag: Spatial retrieval augmented generation for real-world spatial reasoning questions,
D. Yu, R. Bao, G. Mai, and L. Zhao, “Spatial-rag: Spatial retrieval augmented generation for real-world spatial reasoning questions,”arXiv preprint arXiv:2502.18470, 2025
-
[12]
B. Martins, P. Gramackiet al., “A vision for geo-temporal deep research systems: Towards comprehensive, transparent, and reproducible geo-temporal information synthesis,”arXiv preprint arXiv:2506.14345, 2025
-
[13]
An intelligent docent system with a small large language model (sllm) based on retrieval-augmented generation (rag),
T. Jung and I. Joe, “An intelligent docent system with a small large language model (sllm) based on retrieval-augmented generation (rag),”Applied Sciences, vol. 15, no. 17, p. 9398, 2025
2025
-
[14]
H. Ni, F. Liu, X. Ma, L. Su, S. Wang, D. Yin, H. Xiong, and H. Liu, “Tp-rag: Benchmarking retrieval- augmented large language model agents for spatiotemporal-aware travel planning,”arXiv preprint arXiv:2504.08694, 2025
-
[15]
Unifying flood-risk communication: Empowering community leaders through ai-enhanced, contextualized storytelling,
M. Zajac, C. Kulawiak, S. Li, C. Erickson, N. Hubbell, and J. Gong, “Unifying flood-risk communication: Empowering community leaders through ai-enhanced, contextualized storytelling,”Hydrology, vol. 12, no. 8, p. 204, 2025
2025
-
[16]
Z. Liu, S. Wu, and L. Hurni, “Geospatial question answering on historical maps using spatio-temporal knowledge graphs and large language models,”arXiv preprint arXiv:2508.21491, 2025
-
[17]
Distrag: Towards distance-based spatial reasoning in llms,
N. R. Schneider, N. Ramachandran, K. O’Sullivan, and H. Samet, “Distrag: Towards distance-based spatial reasoning in llms,”arXiv preprint arXiv:2506.03424, 2025
-
[18]
A retrieval augmented spatio-temporal framework for traffic prediction,
W. Ruan, X. Dang, Z. Zhou, S. Lyu, and Y . Liang, “A retrieval augmented spatio-temporal framework for traffic prediction,”arXiv preprint arXiv:2508.16623, 2025
-
[19]
Privacy-preserving mechanisms for location privacy in mobile crowdsensing: A survey,
J. W. Kim, K. Edemacu, and B. Jang, “Privacy-preserving mechanisms for location privacy in mobile crowdsensing: A survey,”Journal of Network and Computer Applications, vol. 200, p. 103315, 2022. 10
2022
-
[20]
A survey of differential privacy-based techniques and their applicability to location-based services,
J. W. Kim, K. Edemacu, J. S. Kim, Y . D. Chung, and B. Jang, “A survey of differential privacy-based techniques and their applicability to location-based services,”Computers & Security, vol. 111, p. 102464, 2021
2021
-
[21]
Mechanism design via differential privacy,
F. McSherry and K. Talwar, “Mechanism design via differential privacy,” in48th Annual IEEE Symposium on Foundations of Computer Science (FOCS’07). IEEE, 2007, pp. 94–103
2007
-
[22]
The monte carlo method,
N. Metropolis and S. Ulam, “The monte carlo method,”Journal of the American statistical association, vol. 44, no. 247, pp. 335–341, 1949
1949
-
[23]
T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein,Introduction to algorithms. MIT press, 2022
2022
-
[24]
Geo-indistinguishability: Differential privacy for location-based systems,
M. E. Andrés, N. E. Bordenabe, K. Chatzikokolakis, and C. Palamidessi, “Geo-indistinguishability: Differential privacy for location-based systems,” inProceedings of the 2013 ACM SIGSAC conference on Computer & communications security, 2013, pp. 901–914
2013
-
[25]
Chatgpt,
OpenAI, “Chatgpt,” https://chat.openai.com, 2026, accessed: 2026-03-28
2026
-
[26]
A theoretical analysis of ndcg type ranking measures,
Y . Wang, L. Wang, Y . Li, D. He, and T.-Y . Liu, “A theoretical analysis of ndcg type ranking measures,” in Conference on learning theory. PMLR, 2013, pp. 25–54
2013
-
[27]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019. [Online]. Available: https://arxiv.org/abs/1908.10084
work page internal anchor Pith review arXiv 2019
-
[28]
C-pack: Packed resources for general chinese embeddings,
S. Xiao, Z. Liu, P. Zhang, N. Muennighoff, D. Lian, and J.-Y . Nie, “C-pack: Packed resources for general chinese embeddings,” 2023, model: BAAI/bge-base-en, available at https://huggingface.co/BAAI/bge- base-en
2023
-
[29]
The llama 3 herd of models,
M. L. Team, “The llama 3 herd of models,” 2024, technical Report. [Online]. Available: https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
2024
-
[30]
G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrinet al., “Gemma 3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2503.19786
work page internal anchor Pith review arXiv 2025
-
[31]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, :, S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaumet al., “gpt-oss-120b & gpt-oss-20b model card,” 2025. [Online]. Available: https://arxiv.org/abs/2508.10925
work page internal anchor Pith review arXiv 2025
-
[32]
Inman,Navigation and Nautical Astronomy: For the Use of British Seamen
J. Inman,Navigation and Nautical Astronomy: For the Use of British Seamen. Portsea, England: W. Woodward, 1835
-
[33]
Dense passage retrieval for open-domain question answering,
V . Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W.-t. Yih, “Dense passage retrieval for open-domain question answering,” inProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), 2020, pp. 6769–6781
2020
-
[34]
Colbert: Efficient and effective passage search via contextualized late interaction over bert,
O. Khattab and M. Zaharia, “Colbert: Efficient and effective passage search via contextualized late interaction over bert,” inProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, 2020, pp. 39–48
2020
-
[35]
Retrieval augmented language model pre-training,
K. Guu, K. Lee, Z. Tung, P. Pasupat, and M. Chang, “Retrieval augmented language model pre-training,” inInternational conference on machine learning. PMLR, 2020, pp. 3929–3938
2020
-
[36]
Leveraging passage retrieval with generative models for open domain ques- tion answering,
G. Izacard and E. Grave, “Leveraging passage retrieval with generative models for open domain ques- tion answering,” inProceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume, 2021, pp. 874–880
2021
-
[37]
Retrieval augmented generation for large language models in healthcare: A systematic review,
L. M. Amugongo, P. Mascheroni, S. Brooks, S. Doering, and J. Seidel, “Retrieval augmented generation for large language models in healthcare: A systematic review,”PLOS Digital Health, vol. 4, no. 6, p. e0000877, 2025
2025
-
[38]
Overcoming llm challenges using rag-driven precision in coffee leaf disease remediation,
S. S. Kumar, A. K. M. A. Khan, I. A. Banday, M. Gada, and V . V . Shanbhag, “Overcoming llm challenges using rag-driven precision in coffee leaf disease remediation,” in2024 International Conference on Emerging Technologies in Computer Science for Interdisciplinary Applications (ICETCS). IEEE, 2024, pp. 1–6
2024
-
[39]
everyone wants to do the model work, not the data work
S. Setty, H. Thakkar, A. Lee, E. Chung, and N. Vidra, “Improving retrieval for rag based question answering models on financial documents,”arXiv preprint arXiv:2404.07221, 2024
-
[40]
Calibrating noise to sensitivity in private data analysis,
C. Dwork, F. McSherry, K. Nissim, and A. Smith, “Calibrating noise to sensitivity in private data analysis,” inTheory of cryptography conference. Springer, 2006, pp. 265–284. 11
2006
-
[41]
The algorithmic foundations of differential privacy,
C. Dwork and A. Roth, “The algorithmic foundations of differential privacy,”Foundations and trends® in theoretical computer science, vol. 9, no. 3-4, pp. 211–487, 2014
2014
-
[42]
Spatial cloaking for anonymous location-based services in mobile peer-to-peer environments,
C.-Y . Chow, M. F. Mokbel, and X. Liu, “Spatial cloaking for anonymous location-based services in mobile peer-to-peer environments,”GeoInformatica, vol. 15, no. 2, pp. 351–380, 2011
2011
-
[43]
Anonymous usage of location-based services through spatial and temporal cloaking,
M. Gruteser and D. Grunwald, “Anonymous usage of location-based services through spatial and temporal cloaking,” inProceedings of the 1st international conference on Mobile systems, applications and services, 2003, pp. 31–42
2003
-
[44]
Location privacy in mobile systems: A personalized anonymization model,
B. Gedik and L. Liu, “Location privacy in mobile systems: A personalized anonymization model,” in 25th IEEE International Conference on Distributed Computing Systems (ICDCS’05). IEEE, 2005, pp. 620–629
2005
-
[45]
Trajectory-differential privacy-protection method with interest region,
W. LAN, Y . LIN, L. BAO, T. LI, M. CHEN, and J. SHAN, “Trajectory-differential privacy-protection method with interest region,”Journal of Frontiers of Computer Science and Technology, vol. 14, no. 1, pp. 59–72, 2020
2020
-
[46]
The good and the bad: Exploring privacy issues in retrieval-augmented generation (rag),
S. Zeng, J. Zhang, P. He, Y . Liu, Y . Xing, H. Xu, J. Ren, Y . Chang, S. Wang, D. Yinet al., “The good and the bad: Exploring privacy issues in retrieval-augmented generation (rag),” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 4505–4524
2024
-
[47]
Privacy preserving prompt engineering: A survey,
K. Edemacu and X. Wu, “Privacy preserving prompt engineering: A survey,”ACM Computing Surveys, vol. 57, no. 10, pp. 1–36, 2025
2025
-
[48]
Privacy protection in rag: A novel method and evaluation framework,
Y . Zhang, J. Wu, R. Li, T. Zhang, Y . Song, C. Li, S. Wang, H. Shen, J. Yin, J. Geet al., “Privacy protection in rag: A novel method and evaluation framework,”Information Processing & Management, vol. 63, no. 3, p. 104505, 2026
2026
-
[49]
Mitigating the privacy issues in retrieval-augmented generation (rag) via pure synthetic data,
S. Zeng, J. Zhang, P. He, J. Ren, T. Zheng, H. Lu, H. Xu, H. Liu, Y . Xing, and J. Tang, “Mitigating the privacy issues in retrieval-augmented generation (rag) via pure synthetic data,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 24 538–24 569
2025
-
[50]
On the privacy risk of in-context learning,
H. Duan, A. Dziedzic, M. Yaghini, N. Papernot, and F. Boenisch, “On the privacy risk of in-context learning,”arXiv preprint arXiv:2411.10512, 2024
-
[51]
Dp-tabicl: In-context learning with differentially private tabular data,
A. N. Carey, K. Bhaila, K. Edemacu, and X. Wu, “Dp-tabicl: In-context learning with differentially private tabular data,” in2024 IEEE International Conference on Big Data (BigData). IEEE, 2024, pp. 1552–1557
2024
-
[52]
Risk-aware privacy preservation for llm inference,
Z. Liu, Z. Wang, T. Zhou, Y . Tang, Y . Luo, and Z. Cai, “Risk-aware privacy preservation for llm inference,” IEEE Transactions on Information Forensics and Security, 2026
2026
-
[53]
Protecting users from themselves: Safeguarding contextual privacy in interactions with conversational agents,
I. C. Ngong, S. R. Kadhe, H. Wang, K. Murugesan, J. D. Weisz, A. Dhurandhar, and K. N. Ramamurthy, “Protecting users from themselves: Safeguarding contextual privacy in interactions with conversational agents,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 26 196–26 220
2025
-
[54]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019
2019
-
[55]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review arXiv 2023
-
[56]
Gemma: Open Models Based on Gemini Research and Technology
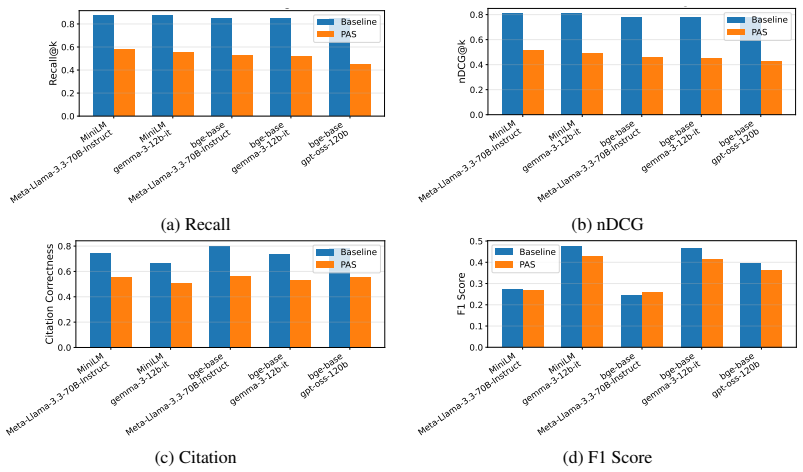
G. Team, “Gemma: Open models based on gemini research and technology,”arXiv preprint arXiv:2403.08295, 2024. Appendices A PAS vs Baseline Graphical Comparison We also provide a graphical retrieval and generation performance comparison between the baseline and PAS mechanism as presented in 5. We observe that PAS induces drop in retrieval and generation per...
work page internal anchor Pith review arXiv 2024
-
[57]
Write a grounded answer that directly answers the user query
-
[58]
Mention strongest matching places first
-
[59]
Exclude unsupported claims
-
[60]
Mention uncertainty for weak spatial matches
-
[61]
Cite only docs used in the answer
-
[62]
Limitations
Output STRICT JSON only. Figure 7: Our prompt template used for grounded generation. C.4 LLM-Based Generation For answer generation, we use multiple large language models (LLMs), namely gpt-oss-120b, Meta-Llama-3.3-70B-Instruct [55], and gemma-3-12b-it [56]. Generation is guided by a structured prompt template shown in Figure 7, in which a system prompt e...
-
[63]
Thus, there are no participant risks to disclose and IRB approval is not required
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.