Recognition: unknown
Beyond Static Policies: Exploring Dynamic Policy Selection for Single-Thread Performance Optimization
Pith reviewed 2026-05-08 15:31 UTC · model grok-4.3
The pith
Dynamically switching between two policies for cache replacement and prefetching reduces mean IPC loss from 1.54% to 0.11% and matches oracle performance 52.65% of the time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
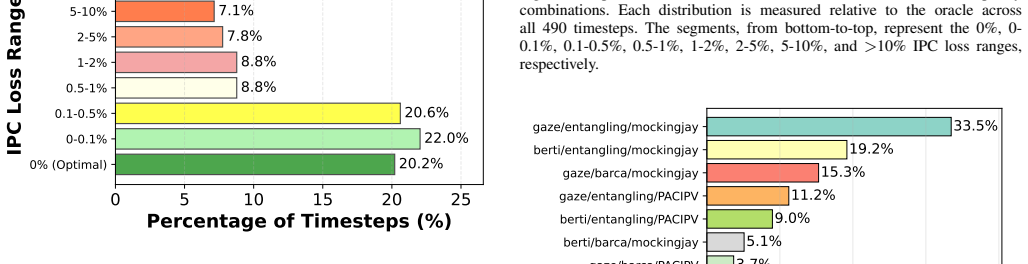
The study finds that the best static policy combination matches the oracle in only 19.18% of execution phases and incurs a mean IPC loss of 1.54%. A processor that can dynamically switch between two policies reduces this mean loss 13.6-fold to 0.11% and matches oracle performance in 52.65% of the 490 phases examined.
What carries the argument
Dynamic selection among combinations of cache replacement and prefetching policies, applied at the start of each 20-million-instruction execution phase.
If this is right
- The best static policy leaves 85 phases across 14 applications with more than 2.5% IPC loss relative to the oracle.
- Switching between only two policies recovers most of the headroom to oracle performance.
- The approach applies across a diverse set of 49 benchmarks in ChampSim simulations.
- Single-thread performance improvements may be possible by adapting existing mechanisms at runtime rather than inventing new static policies.
Where Pith is reading between the lines
- Hardware could add lightweight phase detectors to trigger policy switches at low cost.
- The same dynamic-selection idea might extend to other pipeline components such as branch predictors.
- Actual benefits would require confirming that switching energy does not offset the IPC gains in silicon.
- Testing with three or four policies or shorter phase intervals could reveal whether further gains are available.
Load-bearing premise
The performance gains from dynamic policy selection can be realized with negligible switching overhead and without extra hardware cost or complexity in a real processor.
What would settle it
A cycle-accurate simulation or hardware prototype that includes the latency and power cost of detecting phases and switching policies to check whether the reported IPC improvements remain after those costs are subtracted.
Figures


read the original abstract
For over a decade, processor design has focused on implementing sophisticated policies for various components of the out-of-order pipeline, including cache replacement and prefetching. The prevailing design philosophy has been to build processors with a single, static selection of policies across these different mechanisms. This paper investigates a fundamental question: do different workloads, or even different execution phases within the same workload, benefit from different policy combinations? We present a comprehensive analysis exploring whether a hypothetical processor capable of dynamically selecting from multiple policies could significantly outperform traditional static-policy processors. Using ChampSim-based simulation across 49 benchmarks segmented into 490 execution phases of 20M instructions each, we evaluate performance across multiple policy combinations for cache replacement and prefetching. Our findings reveal that significant performance headroom exists: the best static policy achieves optimal performance for only 19.18\% of execution phases and incurs a mean IPC loss of 1.54\% compared to an oracle. Moreover, 85 phases (17.35\%), spanning 14 of the 49 applications, exhibit more than 2.5\% IPC loss relative to the oracle. Furthermore, we demonstrate that a processor capable of dynamically switching between two carefully chosen policies can achieve a 13.6$\times$ reduction in mean IPC loss (from 1.54\% to 0.11\%) and match oracle performance 52.65\% of the time. These results suggest that dynamic policy selection represents a promising avenue for unlocking single-thread performance improvements that have become increasingly difficult to achieve.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that static policy combinations for cache replacement and prefetching in out-of-order processors leave substantial performance headroom, as shown by ChampSim simulations on 49 benchmarks segmented into 490 phases of 20M instructions: the best static policy is optimal in only 19.18% of phases and incurs a mean 1.54% IPC loss versus an oracle. It further claims that a hypothetical processor dynamically switching between two carefully chosen policies could reduce mean IPC loss by 13.6× to 0.11% and match oracle performance 52.65% of the time.
Significance. If the simulation results hold, this work provides a thorough, reproducible analysis using standard ChampSim infrastructure across a broad benchmark set, quantifying untapped single-thread performance potential from moving beyond static policies. The oracle-based headroom measurements could usefully motivate follow-on research into practical dynamic selection mechanisms.
major comments (1)
- The headline quantitative claims for dynamic policy selection—a 13.6× reduction in mean IPC loss to 0.11% and 52.65% oracle match rate—are obtained by reporting the per-phase best-of-two outcome under perfect oracle selection, without any modeled decision logic, switching latency, or hardware overhead in the ChampSim pipeline model. This assumption is load-bearing for the central claim that such a processor 'can achieve' the reported gains, as the experiments evaluate an ideal upper bound rather than a realizable mechanism.
minor comments (1)
- The manuscript would benefit from additional detail on the criteria used to select the specific two-policy pairs evaluated in the dynamic case, beyond the exhaustive enumeration of static combinations.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the value of our analysis in quantifying untapped single-thread performance headroom. We address the major comment below, clarifying the scope and intent of our oracle-based evaluation.
read point-by-point responses
-
Referee: The headline quantitative claims for dynamic policy selection—a 13.6× reduction in mean IPC loss to 0.11% and 52.65% oracle match rate—are obtained by reporting the per-phase best-of-two outcome under perfect oracle selection, without any modeled decision logic, switching latency, or hardware overhead in the ChampSim pipeline model. This assumption is load-bearing for the central claim that such a processor 'can achieve' the reported gains, as the experiments evaluate an ideal upper bound rather than a realizable mechanism.
Authors: We agree that the reported dynamic selection results are obtained via per-phase oracle selection of the best-of-two policies and do not incorporate any decision logic, switching latency, or hardware overhead in the ChampSim model. This is by design: the manuscript frames these outcomes as the performance achievable by a hypothetical processor under perfect dynamic selection (see abstract: 'a hypothetical processor capable of dynamically switching between two carefully chosen policies' and the corresponding analysis in Section 4.3). The core contribution is to quantify the headroom that exists beyond static policies, which the best static policy leaves on the table in 80.82% of phases. Such oracle upper-bound analyses are standard in architecture research to establish potential before investing in concrete mechanisms. The paper does not claim these gains are achievable in current hardware without additional support. To strengthen clarity, we will revise the abstract and introduction to explicitly label these figures as 'oracle upper bounds assuming zero-overhead perfect selection' and add a short discussion of the gap to practical implementations. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's central quantitative results (13.6× IPC loss reduction, 0.11% mean loss, 52.65% oracle match rate) are obtained directly from ChampSim simulations that enumerate all policy combinations and compute per-phase minima against an oracle baseline. These are empirical measurements across 490 phases with no intervening equations, fitted parameters, predictive models, or self-citations that the numbers depend upon. The derivation chain consists solely of running the simulator under different static configurations and reporting the resulting statistics; nothing reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ChampSim simulator faithfully reproduces the performance effects of cache replacement and prefetch policies on real hardware
Reference graph
Works this paper leans on
-
[1]
The championship simulator: Architectural simulation for education and competition,
The championship simulator: Architectural simulation for education and competition , author=. arXiv preprint arXiv:2210.14324 , year=
-
[2]
2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO) , pages=
Berti: an accurate local-delta data prefetcher , author=. 2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO) , pages=. 2022 , organization=
2022
-
[3]
2025 IEEE International Symposium on High Performance Computer Architecture (HPCA) , pages=
Gaze into the pattern: characterizing spatial patterns with internal temporal correlations for hardware prefetching , author=. 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA) , pages=. 2025 , organization=
2025
-
[4]
2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA) , pages=
A cost-effective entangling prefetcher for instructions , author=. 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA) , pages=. 2021 , organization=
2021
-
[5]
The First Instruction Prefetching Championship , year=
Barca: Branch agnostic region searching algorithm , author=. The First Instruction Prefetching Championship , year=
-
[6]
2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA) , pages=
Effective mimicry of belady’s min policy , author=. 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA) , pages=. 2022 , organization=
2022
-
[7]
Proceedings of the 52nd Annual International Symposium on Computer Architecture , pages=
Light-weight Cache Replacement for Instruction Heavy Workloads , author=. Proceedings of the 52nd Annual International Symposium on Computer Architecture , pages=
-
[8]
IEEE Computer Architecture Letters , volume=
Characterizing Machine Learning-Based Runtime Prefetcher Selection , author=. IEEE Computer Architecture Letters , volume=. 2024 , publisher=
2024
-
[9]
arXiv preprint arXiv:2509.22405 , year=
SAHM: State-Aware Heterogeneous Multicore for Single-Thread Performance , author=. arXiv preprint arXiv:2509.22405 , year=
-
[10]
ACM SIGARCH computer architecture news , volume=
High performance cache replacement using re-reference interval prediction (RRIP) , author=. ACM SIGARCH computer architecture news , volume=. 2010 , publisher=
2010
-
[11]
IEEE Transactions on Computers , volume=
Intelligent adaptation of hardware knobs for improving performance and power consumption , author=. IEEE Transactions on Computers , volume=. 2020 , publisher=
2020
-
[12]
Concurrency and Computation: Practice and Experience , volume=
A survey of techniques for dynamic branch prediction , author=. Concurrency and Computation: Practice and Experience , volume=. 2019 , publisher=
2019
-
[13]
ACM transactions on design automation of electronic systems , volume=
Learning-based phase-aware multi-core CPU workload forecasting , author=. ACM transactions on design automation of electronic systems , volume=. 2022 , publisher=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.