Recognition: unknown
Approximate Next Policy Sampling: Replacing Conservative Target Policy Updates in Deep RL
Pith reviewed 2026-05-08 16:53 UTC · model grok-4.3
The pith
Approximate Next Policy Sampling lets deep RL agents make larger policy updates safely by approximating the next policy's state distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that Approximate Next Policy Sampling addresses the chicken-and-egg problem by modifying the training distribution to approximate the next policy's state-visitation distribution rather than constraining the size of the policy update itself. SV-API holds the target policy fixed while an iteratively updated behavioral policy collects experience until a convergence criterion is reached, at which point the new policy is committed. When defined stability criteria hold, the update is guaranteed safe; otherwise the procedure remains no less safe than ordinary approximate policy iteration. SV-PPO realizes these ideas and produces larger target policy updates on high-dimensional
What carries the argument
Approximate Next Policy Sampling (ANPS), the requirement that the training data distribution approximates the state-visitation distribution of the next policy, which carries the argument by shifting focus from update size to data collection.
If this is right
- When stability criteria are satisfied the policy update is guaranteed safe.
- SV-PPO achieves comparable or better results than PPO on high-dimensional discrete and continuous control tasks.
- Target policy updates can be substantially larger than those permitted by conservative methods.
- Even without meeting the stability criteria the procedure is at least as safe as standard approximate policy iteration.
Where Pith is reading between the lines
- The method may permit faster overall learning in tasks where conservative step sizes cause prolonged plateaus.
- Similar distribution-matching ideas could be tested in other actor-critic algorithms to relax conservatism without losing stability.
- Reliable online checks for the stability criteria would make the approach easier to apply in new environments.
Load-bearing premise
The iteratively updated behavioral policy can generate training data whose state distribution sufficiently matches the distribution the next policy would visit, and that stability criteria can be defined and verified without creating new instabilities.
What would settle it
Running SV-PPO on the same Atari or continuous control benchmarks and observing either worse final performance or larger value-function errors than standard PPO with its smaller conservative updates would show the approach does not preserve safety or performance.
Figures










read the original abstract
We revisit a classic "chicken-and-egg" problem in reinforcement learning: to safely improve a policy, the value function must be accurate on the state-visitation distribution of the updated policy. That distribution over states is unknown and cannot be sampled for the purposes of training the value function. Conservative updates solve this problem, but at the cost of shrinking the policy update. This paper explores an alternative solution, Approximate Next Policy Sampling (ANPS), which addresses the problem by modifying the training distribution rather than constraining the policy update. ANPS is satisfied if the distribution of the training data approximates that of the next policy. To demonstrate the feasibility and efficacy of ANPS, we introduce Stable Value Approximate Policy Iteration (SV-API). SV-API modifies the standard approximate policy iteration loop to hold the target policy fixed while an iteratively updated behavioral policy gathers relevant experience. It only commits to a new policy once a convergence criterion has been met. If certain stability criteria are met, the update is guaranteed to be safe; otherwise, it remains no less safe than standard approximate policy iteration. Applying SV-API to PPO yields Stable Value PPO (SV-PPO), which matches or improves performance on high-dimensional discrete (Atari) and continuous control benchmarks while executing substantially larger target policy updates. These results demonstrate the viability of ANPS as a new solution to this classic challenge in RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses the classic chicken-and-egg problem in RL, where safe policy improvement requires an accurate value function on the unknown state-visitation distribution of the updated policy. It proposes Approximate Next Policy Sampling (ANPS) as an alternative to conservative updates, achieved by holding the target policy fixed while an iteratively updated behavioral policy collects data that approximates the next policy's distribution. The core method, Stable Value Approximate Policy Iteration (SV-API), commits to a new target only after a convergence criterion is satisfied. The paper claims that if certain stability criteria are met the update is guaranteed safe, otherwise it is no less safe than standard approximate policy iteration. Instantiating SV-API within PPO yields SV-PPO, which is reported to match or exceed performance on high-dimensional discrete (Atari) and continuous-control benchmarks while permitting substantially larger target-policy updates.
Significance. If the conditional safety guarantee can be made rigorous and the required distributional approximation can be verified in practice, the work would be significant as a new paradigm for safe, non-conservative policy updates in deep RL. It shifts the burden from shrinking the policy step to improving the training distribution, which could enable faster learning in complex environments. The reported empirical viability on standard benchmarks supports practical relevance, though the absence of explicit derivations, quantitative bounds, or detailed results in the manuscript limits the strength of this assessment.
major comments (2)
- [Abstract] Abstract: the central claim that 'if certain stability criteria are met, the update is guaranteed to be safe' is load-bearing for the contribution, yet the manuscript provides neither a formal definition of the stability criteria, a derivation of the safety guarantee, nor quantitative bounds (e.g., total-variation or Wasserstein distance) on how closely the behavioral policy's state-visitation distribution must approximate that of the fixed target policy before the convergence check fires. Without these, the conditional guarantee cannot be verified or falsified at training time.
- [Abstract] Abstract / Empirical section: the claim that SV-PPO 'matches or improves performance ... while executing substantially larger target policy updates' is unsupported by any reported metrics, tables, or specific benchmark numbers (e.g., Atari scores, MuJoCo returns, or measured update magnitudes). This absence prevents assessment of whether the larger updates are realized without instability or whether the gains are statistically meaningful.
minor comments (1)
- The abstract would benefit from a brief statement of the concrete convergence criterion and stability test used in SV-API to make the method reproducible from the high-level description alone.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We address each major point below and will incorporate revisions to strengthen the theoretical and empirical presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'if certain stability criteria are met, the update is guaranteed to be safe' is load-bearing for the contribution, yet the manuscript provides neither a formal definition of the stability criteria, a derivation of the safety guarantee, nor quantitative bounds (e.g., total-variation or Wasserstein distance) on how closely the behavioral policy's state-visitation distribution must approximate that of the fixed target policy before the convergence check fires. Without these, the conditional guarantee cannot be verified or falsified at training time.
Authors: The referee correctly notes that the abstract is high-level and does not contain the formal details. The manuscript currently states the conditional guarantee at a conceptual level without explicit definitions or derivations in the main text. We will add a dedicated subsection to the methods (new Section 3.3) that formally defines the stability criteria (convergence of the behavioral state distribution to the target within a total-variation threshold), provides the derivation of the safety guarantee, and states quantitative bounds on the required approximation quality. We will also describe a practical monitoring procedure using empirical distribution estimates so the criterion can be checked at training time. The abstract will be updated to reference this new material. revision: yes
-
Referee: [Abstract] Abstract / Empirical section: the claim that SV-PPO 'matches or improves performance ... while executing substantially larger target policy updates' is unsupported by any reported metrics, tables, or specific benchmark numbers (e.g., Atari scores, MuJoCo returns, or measured update magnitudes). This absence prevents assessment of whether the larger updates are realized without instability or whether the gains are statistically meaningful.
Authors: We agree that the abstract summarizes results without numerical values or tables. The empirical section contains learning curves and aggregate comparisons, but lacks a compact summary table of final scores, update magnitudes (e.g., average KL or parameter change), and statistical tests. We will revise the abstract to include two or three key quantitative results (e.g., average Atari score improvement and measured update size ratio) and add a main-text table in Section 5 reporting per-environment scores, update magnitudes, and significance indicators. This will allow direct assessment of the larger-update claim. revision: yes
Circularity Check
No circularity: safety claims are conditional on external criteria without self-referential reduction
full rationale
The paper's core argument modifies the API loop to hold the target policy fixed while updating the behavioral policy until a convergence criterion, then claims conditional safety if stability criteria hold (otherwise no worse than standard API). No equations, derivations, or fitted parameters are presented that reduce to their own inputs by construction. The ANPS definition and SV-API procedure are algorithmic modifications rather than self-definitional or fitted-input predictions. No load-bearing self-citations or uniqueness theorems from prior author work are invoked in the provided text. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existence of checkable stability criteria that ensure the update is at least as safe as standard approximate policy iteration
Reference graph
Works this paper leans on
-
[1]
Maximum a posteriori policy optimisation
URLhttps://arxiv.org/ abs/1806.06920. Alekh Agarwal, Nan Jiang, Sham M. Kakade, and Wen Sun.Reinforcement Learning: Theory and Algorithms
- [2]
- [3]
- [4]
- [6]
-
[7]
URLhttps://arxiv.org/ abs/2303.08774. Theodore Perkins and Doina Precup. A convergent form of approximate policy iteration. In S. Becker, S. Thrun, and K. Obermayer (eds.),Advances in Neural Information Processing Sys- tems, volume
work page internal anchor Pith review arXiv
-
[8]
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz
URLhttps://proceedings.neurips.cc/paper_ files/paper/2002/file/9f44e956e3a2b7b5598c625fcc802c36-Paper.pdf. John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. In Francis Bach and David Blei (eds.),Proceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of ...
2002
-
[9]
Proximal Policy Optimization Algorithms
URLhttps://arxiv.org/abs/1707.06347. John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation,
work page internal anchor Pith review arXiv
-
[10]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
URLhttps: //arxiv.org/abs/1506.02438. Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback,
work page internal anchor Pith review arXiv
-
[11]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano
URL http://arxiv.org/abs/2009.01325. cite arxiv:2009.01325Comment: NeurIPS
-
[12]
URLhttps://arxiv.org/abs/2409.04792. Kenny Young and Tian Tian. Minatar: An atari-inspired testbed for thorough and reproducible reinforcement learning experiments.arXiv preprint arXiv:1903.03176,
-
[13]
12 Supplementary Materials The following content was not necessarily subject to peer review. 7 Proof of Theorem 3.3 Proof of Theorem 3.3.Start with the PDL, and introduceq π through addition and subtraction: (1−γ)(V π′ (s0)−V π(s0)) =E s,a∼dπ′ Aπ(s, a)(PDL) =E s,a∼dπ′ [qπ(s, a)−V π(s) +Q π(s, a)−q π(s, a)] =A π π′ +E s,a∼dπ′ [Qπ(s, a)−q π(s, a)] SubtractA...
2021
-
[14]
Hugging the walls mitigates the negative effect of an erroneous move
is a grid world with fixed starting state (top left room) and goal state (bottom right room) The action is the intended direction of movement, and is executed noisily, with a20%chance of success. Hugging the walls mitigates the negative effect of an erroneous move. The optimal policy, shown in Figure (8a), visits all four rooms: generally going through th...
2022
-
[15]
Around iterationk= 50, PPO’s CNN critic over-estimates the value along the left wall
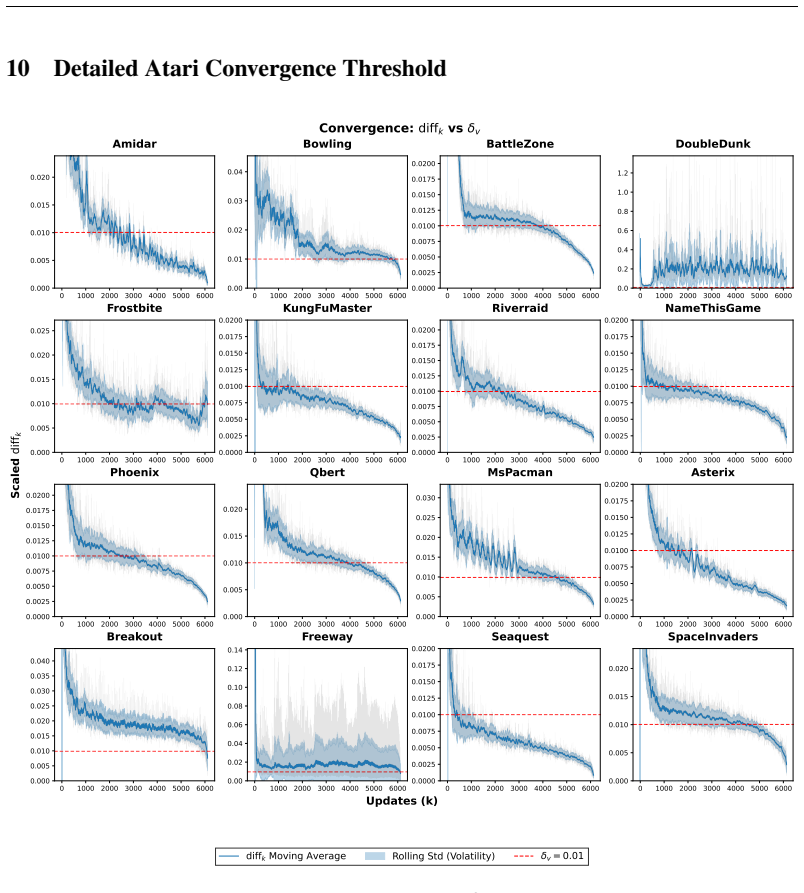
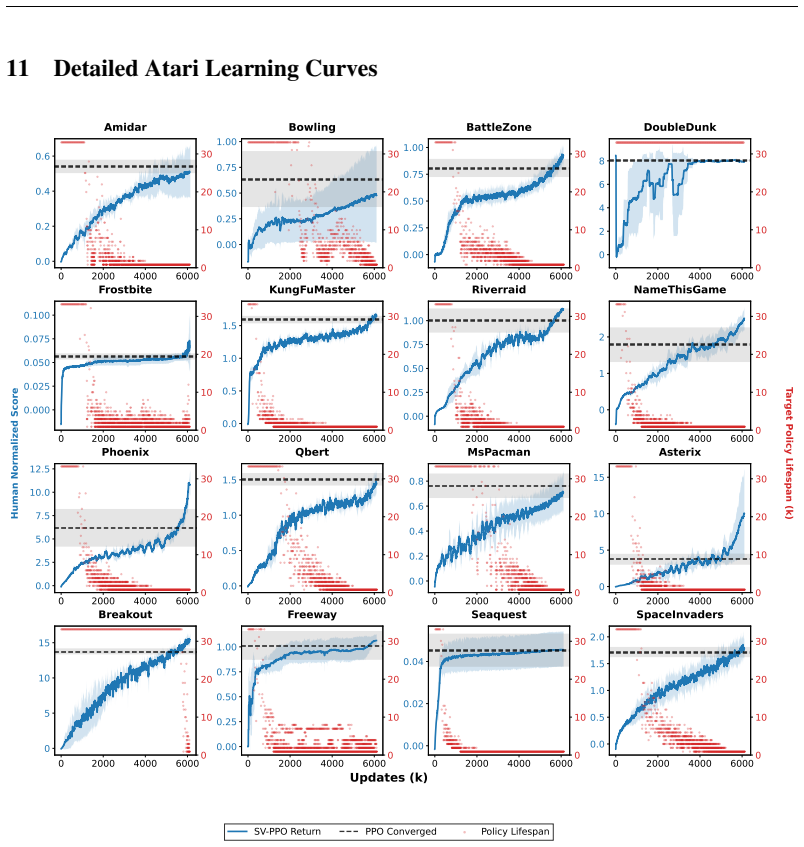
This is due to mis- generalization of the value network, sometimes called value churn (Tang & Berseth, 2024). Around iterationk= 50, PPO’s CNN critic over-estimates the value along the left wall. Byk= 60, the PPO policy network learns to avoid the bottom room. Insufficient sampling and poor generalization leads to catastrophic forgetting occurring at iterationk=
2024
-
[16]
This leads the agent to avoid the room altogether. 20 0 5 10 0 2 4 6 8 10 12 Iteration k=35 (i) True Target Value V 0.0 0.2 0.4 0.6 0.8 1.0 0 5 10 0 2 4 6 8 10 12 (ii) EMA of Empirical Visit Count 0 20 40 60 80 100 0 5 10 0 2 4 6 8 10 12 (iii) Value Prediction Vk 0.0 0.2 0.4 0.6 0.8 1.0 0 5 10 0 2 4 6 8 10 12 (iv) Over-estimation ((c) - (a)) 0.4 0.2 0.0 0...
2011
-
[17]
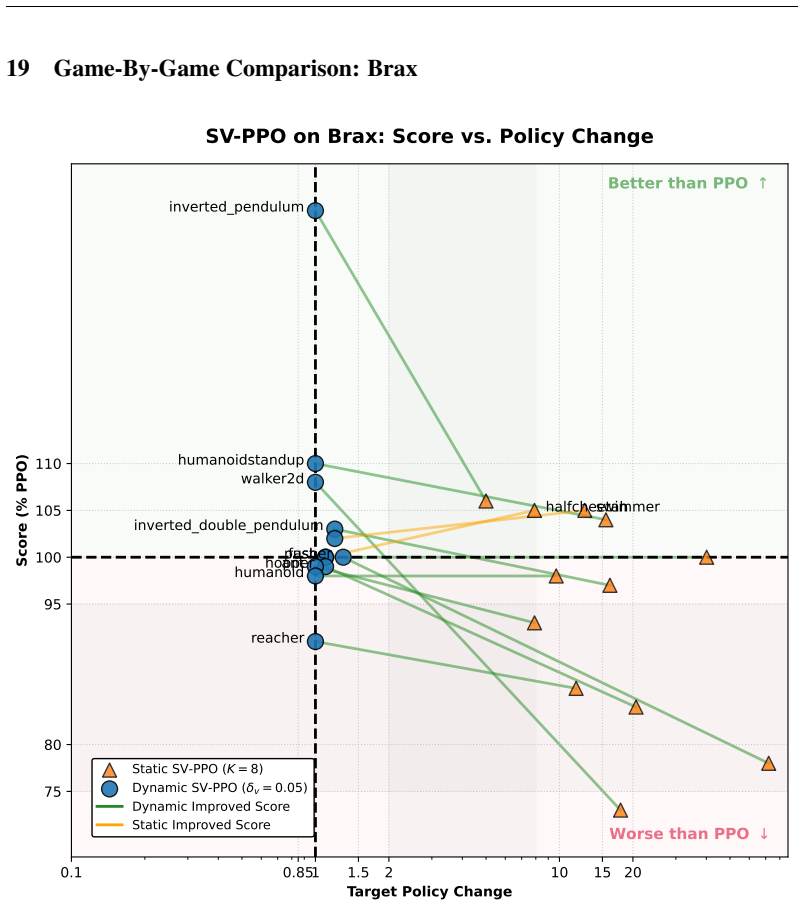
Each game is placed on the plot twice: a blue circle denotes the dynamic variant, and a triangle denotes the static variant
Dynamic SV-PPO ( v = 0.05) Dynamic Improved Score Static Improved Score Figure 12: Game by Game comparison of Static and Dynamic SV-PPO on Brax. Each game is placed on the plot twice: a blue circle denotes the dynamic variant, and a triangle denotes the static variant. A colored line connects the same game for the two variants. The vertical axis is conver...
2000
-
[18]
28 21 SV-PPO Brax Hyperparameters Table 6:Hyperparameters for Brax Continuous Control.Shared parameters (due to the Pure- JAXRL repository Lu et al
Figure 13: Learning Curves for PPO, Dynamic SV-PPO, and Static SV-PPO for Brax. 28 21 SV-PPO Brax Hyperparameters Table 6:Hyperparameters for Brax Continuous Control.Shared parameters (due to the Pure- JAXRL repository Lu et al. (2022)) are applied across all baselines and variants. SV-PPO specific parameters apply only to the dynamic and static gated alg...
2022
-
[19]
ˆAt =δ t +γc t ˆAt+1, ˆAT+1 = 0(23) Finally, we normalize the estimates ˆAt by dividing by the batch standard deviation, but we do not center them, to avoid flipping the sign
used by PPO by incorporating the importance sampling weights from Equation (21), which are originally due to Retrace(λ) (Munos et al., 2016). ˆAt =δ t +γc t ˆAt+1, ˆAT+1 = 0(23) Finally, we normalize the estimates ˆAt by dividing by the batch standard deviation, but we do not center them, to avoid flipping the sign. 31
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.