Recognition: unknown
DICE: Enabling Efficient General-Purpose SIMT Execution with Statically Scheduled Coarse-Grained Reconfigurable Arrays
Pith reviewed 2026-05-08 15:25 UTC · model grok-4.3
The pith
A GPU design using statically scheduled coarse-grained reconfigurable arrays achieves 1.77 to 1.90 times better dynamic energy efficiency than conventional SIMD processors while maintaining comparable performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
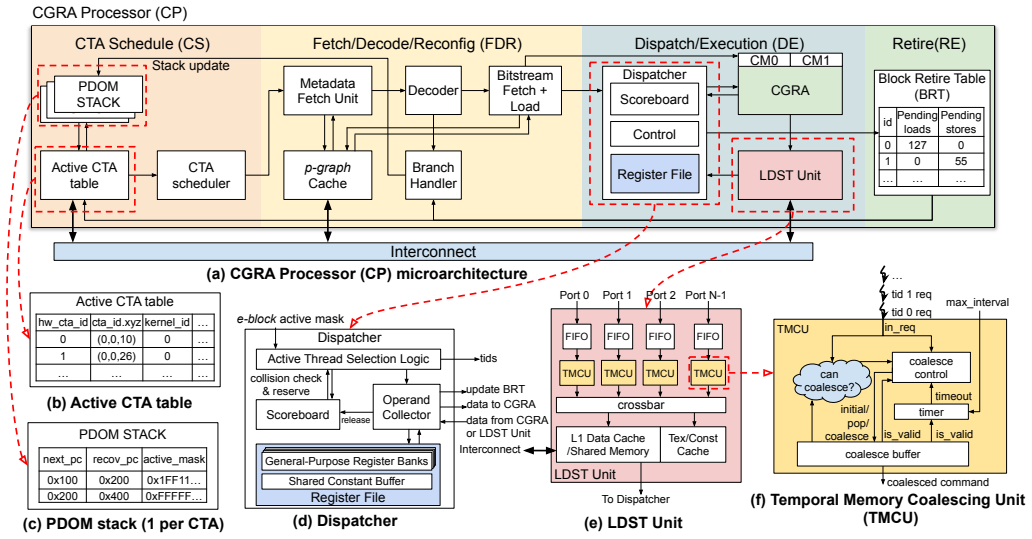
DICE replaces the SIMD backend of GPUs with minimal-overhead statically scheduled CGRAs. Active threads are dispatched in pipelined fashion onto the CGRA fabric where data flows directly between PEs to reduce RF accesses for intermediate values. Programs with runtime dynamism are compiled into p-graphs by partitioning dynamic dependence edges across separate configurations. Double-buffered configuration memory hides reconfiguration latency, compile-time unrolling boosts utilization, and a temporal memory coalescing unit merges requests from pipelined threads. On standard benchmarks this cuts register file accesses by 68 percent on average, delivering 1.77-1.90x dynamic energy efficiency and
What carries the argument
The p-graph, which partitions dynamic dependence edges across separate CGRA configurations to support static scheduling for operations with runtime variability such as memory loads and control flow.
If this is right
- Register file accesses decrease by 68 percent on average.
- CGRA-based processors reach a geometric mean of 1.77-1.90 times the dynamic energy efficiency of conventional streaming multiprocessors.
- Average power is reduced by 42.0 to 45.9 percent.
- The complete system delivers performance levels similar to those of traditional GPU designs.
- Spatial pipeline execution on reconfigurable hardware supports general-purpose SIMT workloads effectively.
Where Pith is reading between the lines
- The approach might be adapted to other many-core or accelerator designs facing similar energy bottlenecks from control and storage overhead.
- Future work could explore automatic compilation tools that better optimize p-graph partitioning for a wider range of applications.
- Physical implementation would allow verification of whether the simulated savings translate to real silicon under varying workloads.
- This highlights an opportunity to trade some flexibility in scheduling for lower power in parallel processors.
Load-bearing premise
The performance and energy model used in evaluation correctly captures the behavior of both the baseline SIMD processors and the CGRA-based design, including reconfiguration overheads and memory request merging.
What would settle it
Running the same set of parallel benchmarks on actual hardware built with both the conventional design and the new CGRA approach, using identical computation and memory resources, would falsify the claims if the energy efficiency improvement falls well below 1.5 times or if performance drops significantly.
Figures
















read the original abstract
While GPUs dominate massively parallel computing through the single-instruction, multiple-thread (SIMT) programming model, their underlying single-instruction, multiple-data (SIMD) execution incurs substantial energy overhead from frequent register file (RF) accesses and complex control logic. We present DICE, a novel architecture that addresses these inefficiencies by replacing the SIMD backend with minimal-overhead, statically scheduled coarse-grained reconfigurable arrays (CGRAs). Unlike SIMD units that execute warps of threads in lockstep, DICE dispatches active threads in a pipelined manner onto the CGRA fabric, where data flow directly between processing elements (PEs), reducing RF accesses for intermediate values. To handle operations with runtime dynamism, such as variable-latency memory loads and data-dependent control flow, while preserving static scheduling, DICE compiles programs into "p-graphs" by partitioning dynamic dependence edges across separate CGRA configurations. DICE further introduces several key optimizations: double-buffered configuration memory to hide reconfiguration latency, compile-time p-graph unrolling to enhance resource utilization, and a temporal memory coalescing unit (TMCU) to merge memory requests from consecutive, pipelined threads. Evaluations on Rodinia benchmarks in Accel-sim demonstrate that DICE reduces register file accesses by 68% on average. With equivalent computation and memory resources, DICE's CGRA Processors (CPs) achieve a geometric mean of 1.77-1.90x dynamic energy efficiency and 42.0%-45.9% average power reduction compared to the modeled NVIDIA Turing Streaming Multiprocessors (SMs), while the full DICE system achieves performance comparable to the modeled Turing GPU baselines. DICE demonstrates that spatial pipeline execution can deliver substantial energy savings without sacrificing performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DICE, which replaces SIMD execution in GPUs with statically scheduled CGRAs for SIMT workloads. It introduces p-graphs to partition dynamic dependence edges (e.g., from variable-latency loads and control flow) across configurations while preserving static scheduling, plus optimizations including double-buffered configuration memory, compile-time p-graph unrolling, and a temporal memory coalescing unit (TMCU). Cycle-accurate Accel-sim evaluations on Rodinia benchmarks report 68% average RF access reduction; with equivalent resources, DICE CGRA processors achieve 1.77-1.90x dynamic energy efficiency and 42.0-45.9% power reduction versus modeled NVIDIA Turing SMs, while the full system matches baseline performance.
Significance. If the Accel-sim results hold, DICE offers a concrete path to spatial dataflow execution for general-purpose SIMT codes, with substantial RF and power savings that could inform future GPU microarchitectures in energy-constrained settings. The evaluation uses external Rodinia benchmarks and a third-party simulator without fitted parameters or self-referential predictions, which strengthens credibility. However, the absence of hardware measurements or independent model validation limits immediate adoption.
major comments (2)
- [§5 (Evaluation)] §5 (Evaluation): The central quantitative claims (1.77-1.90x energy efficiency, 42-45.9% power reduction, 68% RF reduction) are derived solely from Accel-sim runs that extend the simulator to model p-graphs, double-buffered reconfiguration, and the TMCU. No description is given of how energy models for these novel components were constructed, no cross-validation against McPAT/CACTI or alternative simulators is reported, and no hardware prototype exists. This directly affects the reported gains and must be addressed with additional modeling details or sensitivity analysis.
- [§4 (Architecture/Design)] §4 (Architecture/Design, TMCU and p-graph sections): The paper states that the TMCU merges requests from pipelined threads and that p-graph partitioning handles dynamism without sacrificing static scheduling, yet no isolated measurements quantify reconfiguration overhead, coalescing latency, or the fraction of the 68% RF reduction attributable to dataflow versus TMCU. These are load-bearing for the claim that spatial pipelines deliver savings without performance loss.
minor comments (2)
- [Abstract] Abstract: The two values in the 1.77-1.90x range are not explained (e.g., different resource configurations or benchmark subsets).
- [Throughout] Throughout: Ensure first-use definitions for all acronyms (CGRA, SIMT, TMCU, p-graph) and consistent notation for energy versus power metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and will revise the paper to incorporate additional modeling details, experiments, and clarifications as outlined.
read point-by-point responses
-
Referee: [§5 (Evaluation)] §5 (Evaluation): The central quantitative claims (1.77-1.90x energy efficiency, 42-45.9% power reduction, 68% RF reduction) are derived solely from Accel-sim runs that extend the simulator to model p-graphs, double-buffered reconfiguration, and the TMCU. No description is given of how energy models for these novel components were constructed, no cross-validation against McPAT/CACTI or alternative simulators is reported, and no hardware prototype exists. This directly affects the reported gains and must be addressed with additional modeling details or sensitivity analysis.
Authors: We agree that expanded details on energy modeling are needed to fully support the reported gains. In the revised manuscript, we will add a dedicated subsection in §5 describing how the energy models for p-graphs, double-buffered configuration memory, and the TMCU were constructed as extensions to Accel-sim's existing power models (calibrated to NVIDIA Turing). We will also include sensitivity analysis on key parameters such as reconfiguration energy and memory access costs to demonstrate robustness of the 1.77-1.90x energy efficiency and 42.0-45.9% power reduction results. As this is a simulation-based architectural study using a third-party cycle-accurate simulator and external Rodinia benchmarks, a hardware prototype is beyond the current scope; however, the use of unmodified external benchmarks and a public simulator strengthens credibility of the evaluation. revision: yes
-
Referee: [§4 (Architecture/Design)] §4 (Architecture/Design, TMCU and p-graph sections): The paper states that the TMCU merges requests from pipelined threads and that p-graph partitioning handles dynamism without sacrificing static scheduling, yet no isolated measurements quantify reconfiguration overhead, coalescing latency, or the fraction of the 68% RF reduction attributable to dataflow versus TMCU. These are load-bearing for the claim that spatial pipelines deliver savings without performance loss.
Authors: We concur that isolating component contributions would strengthen the claims regarding spatial pipeline benefits. In the revision, we will augment §5 with new experiments that: (1) measure and report reconfiguration overhead (showing it is hidden by double-buffering), (2) quantify TMCU coalescing latency, and (3) present an ablation study decomposing the 68% average RF access reduction into portions attributable to CGRA dataflow versus TMCU coalescing. These additions will clarify that the primary savings stem from reduced register file accesses due to direct dataflow while maintaining performance parity with the baseline. revision: yes
- Absence of hardware prototype or silicon measurements to validate the Accel-sim energy models and reported gains.
Circularity Check
No circularity; results are empirical simulation outputs on external benchmarks
full rationale
The paper presents an architecture (p-graphs, double-buffered reconfiguration, TMCU) and reports quantitative claims exclusively from Accel-sim runs on Rodinia benchmarks. No equations, fitted parameters, or predictions are defined in terms of the target metrics; the energy-efficiency and power numbers are direct simulation outputs rather than reductions by construction. No self-citations are invoked to justify uniqueness or load-bearing premises, and the evaluation uses a third-party simulator plus standard external workloads. This is a conventional empirical comparison with no self-referential steps in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Accel-sim simulator accurately captures dynamic energy, power, and performance for both the baseline Turing SM and the proposed CGRA-based design.
invented entities (2)
-
p-graphs
no independent evidence
-
Temporal Memory Coalescing Unit (TMCU)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
T. M. Aamodt, W. W. L. Fung, and T. G. Rogers,General-Purpose Graphics Processor Architectures, 1st ed., ser. Synthesis Lectures on Computer Architecture. Cham: Springer, 2018
2018
-
[2]
Benchmark-driven models for energy analysis and attribution of GPU-accelerated supercomputing,
O. Antepara, Z. Zhao, B. Austin, N. Ding, L. Oliker, N. J. Wright, and S. Williams, “Benchmark-driven models for energy analysis and attribution of GPU-accelerated supercomputing,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’25. New York, NY , USA: Association for Computing Machi...
-
[3]
Executing a program on the MIT tagged-token dataflow architecture,
Arvind and R. Nikhil, “Executing a program on the MIT tagged-token dataflow architecture,”IEEE Transactions on Computers, vol. 39, no. 3, pp. 300–318, 1990
1990
-
[4]
Design of a fused multiply-add floating-point and integer datapath,
T. M. Bruintjes, “Design of a fused multiply-add floating-point and integer datapath,” Master’s thesis, University of Twente, Enschede, The Netherlands, 2011. [Online]. Available: https://essay.utwente.nl/ fileshare/file/61055/MSc TM Bruintjes CAES ASCI.pdf#page=121.00
2011
-
[5]
GeForce GTX 1660 Ti’s Advanced Shaders Accelerate Performance In The Latest Games,
A. Burnes, “GeForce GTX 1660 Ti’s Advanced Shaders Accelerate Performance In The Latest Games,”NVIDIA GeForce News, Feb. 2019, accessed March 28, 2026. [Online]. Avail- able: https://www.nvidia.com/en-us/geforce/news/geforce-gtx-1660-ti- advanced-shaders-streaming-multiprocessor/
2019
-
[6]
[Online]
Cadence Design Systems, Inc., 2025. [Online]. Avail- able: https://www.cadence.com/en US/home/tools/digital-design-and- signoff/power-analysis/joules-rtl-power-solution.html
2025
-
[7]
Rodinia: A benchmark suite for heterogeneous computing,
S. Che, M. Boyer, J. Meng, D. Tarjan, J. W. Sheaffer, S.-H. Lee, and K. Skadron, “Rodinia: A benchmark suite for heterogeneous computing,” in2009 IEEE International Symposium on Workload Characterization (IISWC), 2009, pp. 44–54
2009
-
[8]
CGRA-ME: A unified framework for CGRA modelling and exploration,
S. A. Chin, N. Sakamoto, A. Rui, J. Zhao, J. H. Kim, Y . Hara- Azumi, and J. Anderson, “CGRA-ME: A unified framework for CGRA modelling and exploration,” in2017 IEEE 28th International Conference on Application-specific Systems, Architectures and Processors (ASAP), 2017, pp. 184–189
2017
-
[9]
Amber: A 16-nm system-on-chip with a coarse-grained reconfigurable array for flexible acceleration of dense linear algebra,
K. Feng, T. Kong, K. Koul, J. Melchert, A. Carsello, Q. Liu, G. Nyen- gele, M. Strange, K. Zhang, A. Nayak, J. Setter, J. Thomas, K. Sreedhar, P.-H. Chen, N. Bhagdikar, Z. A. Myers, B. D’Agostino, P. Joshi, S. Richardson, C. Torng, M. Horowitz, and P. Raina, “Amber: A 16-nm system-on-chip with a coarse-grained reconfigurable array for flexible acceleratio...
2024
-
[11]
Nvidia 12nm Turing TU116 GeForce GTX 1660 Ti Die Shot,
——, “Nvidia 12nm Turing TU116 GeForce GTX 1660 Ti Die Shot,” Flickr, 2019, cC0 1.0 / public domain. [Online]. Available: https://www.flickr.com/photos/130561288@N04/47220396142
-
[12]
Dynamic warp formation and scheduling for efficient GPU control flow,
W. W. Fung, I. Sham, G. Yuan, and T. M. Aamodt, “Dynamic warp formation and scheduling for efficient GPU control flow,” in40th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO 2007), 2007, pp. 407–420
2007
-
[13]
SNAFU: An ultra-low-power, energy-minimal CGRA-generation framework and architecture,
G. Gobieski, A. O. Atli, K. Mai, B. Lucia, and N. Beckmann, “SNAFU: An ultra-low-power, energy-minimal CGRA-generation framework and architecture,” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), 2021, pp. 1027–1040
2021
-
[14]
RipTide: A programmable, energy-minimal dataflow compiler and architecture,
G. Gobieski, S. Ghosh, M. Heule, T. Mowry, T. Nowatzki, N. Beckmann, and B. Lucia, “RipTide: A programmable, energy-minimal dataflow compiler and architecture,” in2022 55th IEEE/ACM International Sym- posium on Microarchitecture (MICRO), 2022, pp. 546–564
2022
-
[15]
DySER: Unifying functionality and parallelism specialization for energy-efficient computing,
V . Govindaraju, C.-H. Ho, T. Nowatzki, J. Chhugani, N. Satish, K. Sankaralingam, and C. Kim, “DySER: Unifying functionality and parallelism specialization for energy-efficient computing,”IEEE Micro, vol. 32, no. 5, pp. 38–51, 2012
2012
-
[16]
Understanding sources of inefficiency in general-purpose chips,
R. Hameed, W. Qadeer, M. Wachs, O. Azizi, A. Solomatnikov, B. C. Lee, S. Richardson, C. Kozyrakis, and M. Horowitz, “Understanding sources of inefficiency in general-purpose chips,” p. 37–47, 2010. [Online]. Available: https://doi.org/10.1145/1815961.1815968
-
[17]
Hauck and A
S. Hauck and A. DeHon, Eds.,Reconfigurable Computing: The Theory and Practice of FPGA-Based Computation, ser. Systems on Silicon Ser. San Francisco: Morgan Kaufmann, 2007
2007
-
[18]
An integrated GPU power and performance model,
S. Hong and H. Kim, “An integrated GPU power and performance model,” inProceedings of the 37th Annual International Symposium on Computer Architecture, ser. ISCA ’10. New York, NY , USA: Association for Computing Machinery, 2010, p. 280–289. [Online]. Available: https://doi.org/10.1145/1815961.1815998
-
[19]
AccelWattch: A power modeling framework for modern GPUs,
V . Kandiah, S. Peverelle, M. Khairy, J. Pan, A. Manjunath, T. G. Rogers, T. M. Aamodt, and N. Hardavellas, “AccelWattch: A power modeling framework for modern GPUs,” inMICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 738–753. [Online]. Available:...
-
[20]
HyCUBE: A CGRA with reconfigurable single-cycle multi-hop interconnect,
M. Karunaratne, A. K. Mohite, T. Mitra, and L.-S. Peh, “HyCUBE: A CGRA with reconfigurable single-cycle multi-hop interconnect,” in2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC), 2017, pp. 1–6
2017
-
[21]
Accel-Sim: An extensible simulation framework for validated GPU modeling,
M. Khairy, Z. Shen, T. M. Aamodt, and T. G. Rogers, “Accel-Sim: An extensible simulation framework for validated GPU modeling,” in 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), 2020, pp. 473–486
2020
-
[22]
Moonwalk: NRE optimization in ASIC clouds,
M. Khazraee, L. Zhang, L. Vega, and M. B. Taylor, “Moonwalk: NRE optimization in ASIC clouds,” inProceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS ’17. New York, NY , USA: Association for Computing Machinery, 2017, p. 511–526. [Online]. Available: https://doi.org...
-
[23]
AHA: An agile approach to the design of coarse-grained reconfigurable accelerators and compilers,
K. Koul, J. Melchert, K. Sreedhar, L. Truong, G. Nyengele, K. Zhang, Q. Liu, J. Setter, P.-H. Chen, Y . Mei, M. Strange, R. Daly, C. Donovick, A. Carsello, T. Kong, K. Feng, D. Huff, A. Nayak, R. Setaluri, J. Thomas, N. Bhagdikar, D. Durst, Z. Myers, N. Tsiskaridze, S. Richardson, R. Bahr, K. Fatahalian, P. Hanrahan, C. Barrett, M. Horowitz, C. Torng, F. ...
-
[24]
Available: https://doi.org/10.1145/3534933
[Online]. Available: https://doi.org/10.1145/3534933
-
[25]
Lockup-free instruction fetch/prefetch cache organization,
D. Kroft, “Lockup-free instruction fetch/prefetch cache organization,” in Proceedings of the 8th Annual Symposium on Computer Architecture, ser. ISCA ’81. Washington, DC, USA: IEEE Computer Society Press, 1981, p. 81–87
1981
-
[26]
GPUWattch: enabling energy optimizations in GPGPUs,
J. Leng, T. Hetherington, A. ElTantawy, S. Gilani, N. S. Kim, T. M. Aamodt, and V . J. Reddi, “GPUWattch: enabling energy optimizations in GPGPUs,” inProceedings of the 40th Annual International Symposium on Computer Architecture, ser. ISCA ’13. New York, NY , USA: Association for Computing Machinery, 2013, p. 487–498. [Online]. Available: https://doi.org...
-
[27]
NVIDIA Tesla: A unified graphics and computing architecture,
E. Lindholm, J. Nickolls, S. Oberman, and J. Montrym, “NVIDIA Tesla: A unified graphics and computing architecture,”IEEE Micro, vol. 28, no. 2, pp. 39–55, 2008
2008
-
[28]
L. Liu, J. Zhu, Z. Li, Y . Lu, Y . Deng, J. Han, S. Yin, and S. Wei, “A survey of coarse-grained reconfigurable architecture and design: Taxonomy, challenges, and applications,”ACM Comput. Surv., vol. 52, no. 6, Oct. 2019. [Online]. Available: https://doi.org/10.1145/3357375
-
[29]
ADRES: An architecture with tightly coupled VLIW processor and coarse-grained reconfigurable matrix,
B. Mei, S. Vernalde, D. Verkest, H. De Man, and R. Lauwereins, “ADRES: An architecture with tightly coupled VLIW processor and coarse-grained reconfigurable matrix,” inField Programmable Logic and Application, P. Y . K. Cheung and G. A. Constantinides, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2003, pp. 61–70
2003
-
[30]
J. Melchert, K. Feng, C. Donovick, R. Daly, C. Barrett, M. Horowitz, P. Hanrahan, and P. Raina, “Automated design space exploration of CGRA processing element architectures using frequent subgraph analysis,” 2021. [Online]. Available: https://arxiv.org/abs/2104.14155
-
[31]
Optimizing NUCA organizations and wiring alternatives for large caches with CACTI 6.0,
N. Muralimanohar, R. Balasubramonian, and N. Jouppi, “Optimizing NUCA organizations and wiring alternatives for large caches with CACTI 6.0,” in40th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO 2007), 2007, pp. 3–14
2007
-
[32]
J. Nickolls, I. Buck, M. Garland, and K. Skadron, “Scalable parallel programming with CUDA: Is CUDA the parallel programming model that application developers have been waiting for?”Queue, vol. 6, no. 2, pp. 40–53, Mar. 2008. [Online]. Available: https: //doi.org/10.1145/1365490.1365500
-
[33]
Stream-dataflow acceleration,
T. Nowatzki, V . Gangadhar, N. Ardalani, and K. Sankaralingam, “Stream-dataflow acceleration,” in2017 ACM/IEEE 44th Annual Inter- national Symposium on Computer Architecture (ISCA), 2017, pp. 416– 429
2017
-
[34]
NVIDIA Tesla P100,
NVIDIA Corporation, “NVIDIA Tesla P100,” https://images.nvidia. com/content/pdf/tesla/whitepaper/pascal-architecture-whitepaper.pdf, 2016, white paper
2016
-
[35]
NVIDIA TESLA V100 GPU ARCHITECTURE,
——, “NVIDIA TESLA V100 GPU ARCHITECTURE,” https://images.nvidia.com/content/volta-architecture/pdf/volta- architecture-whitepaper.pdf, 2017, white paper
2017
-
[36]
NVIDIA TURING GPU ARCHITECTURE,
——, “NVIDIA TURING GPU ARCHITECTURE,” Tech. Rep., NVIDIA, Santa Clara, CA, Tech. Rep., 2018, https://images.nvidia. com/aem-dam/en-zz/Solutions/design-visualization/technologies/turing- architecture/NVIDIA-Turing-Architecture-Whitepaper.pdf
2018
-
[37]
NVIDIA A100 Tensor Core GPU Architecture,
——, “NVIDIA A100 Tensor Core GPU Architecture,” https://images.nvidia.com/aem-dam/en-zz/Solutions/data-center/nvidia- ampere-architecture-whitepaper.pdf, 2020, white paper
2020
-
[38]
NVIDIA Ampere GA102 GPU Architecture,
——, “NVIDIA Ampere GA102 GPU Architecture,” https://www.nvidia.com/content/PDF/nvidia-ampere-ga-102-gpu- architecture-whitepaper-v2.pdf, 2020, white paper
2020
-
[39]
NVIDIA H100 Tensor Core GPU Architecture,
——, “NVIDIA H100 Tensor Core GPU Architecture,” https://resources. nvidia.com/en-us-hopper-architecture/nvidia-h100-tensor-c, 2022, white paper
2022
-
[40]
——,Parallel Thread Execution (PTX) ISA Version 8.8, 2024, https: //docs.nvidia.com/cuda/parallel-thread-execution/
2024
-
[41]
CUDA Toolkit Documentation: NVCC, the CUDA Compiler Driver,
——, “CUDA Toolkit Documentation: NVCC, the CUDA Compiler Driver,” https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index. html, June 2025, accessed: 2025-07-30
2025
-
[42]
Swizzle Inventor: Data movement synthesis for GPU kernels,
P. M. Phothilimthana, A. S. Elliott, A. Wang, A. Jangda, B. Hagedorn, H. Barthels, S. J. Kaufman, V . Grover, E. Torlak, and R. Bodik, “Swizzle Inventor: Data movement synthesis for GPU kernels,” inProceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS ’19. New York, ...
-
[43]
A survey on coarse-grained reconfigurable architectures from a performance perspective,
A. Podobas, K. Sano, and S. Matsuoka, “A survey on coarse-grained reconfigurable architectures from a performance perspective,”IEEE Access, vol. 8, pp. 146 719–146 743, 2020
2020
-
[44]
Plasticine: A reconfigurable architecture for parallel patterns,
R. Prabhakar, Y . Zhang, D. Koeplinger, M. Feldman, T. Zhao, S. Hadjis, A. Pedram, C. Kozyrakis, and K. Olukotun, “Plasticine: A reconfigurable architecture for parallel patterns,” in2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), 2017, pp. 389–402
2017
-
[45]
SCALE-Sim V3: a modular cycle-accurate systolic accelerator simulator for end-to-end system analysis,
R. Raj, S. Banerjee, N. Chandra, Z. Wan, J. Tong, A. Samajdhar, and T. Krishna, “SCALE-Sim V3: a modular cycle-accurate systolic accelerator simulator for end-to-end system analysis,” in2025 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2025, pp. 186–200
2025
-
[46]
Exploiting ILP, TLP, and DLP with the polymorphous TRIPS architecture,
K. Sankaralingam, R. Nagarajan, H. Liu, C. Kim, J. Huh, D. Burger, S. Keckler, and C. Moore, “Exploiting ILP, TLP, and DLP with the polymorphous TRIPS architecture,” in30th Annual International Symposium on Computer Architecture, 2003. Proceedings., 2003, pp. 422–433
2003
-
[47]
Scaling equations for the accurate prediction of CMOS device performance from 180 nm to 7 nm,
A. Stillmaker and B. Baas, “Scaling equations for the accurate prediction of CMOS device performance from 180 nm to 7 nm,”Integration, vol. 58, pp. 74–81, 2017. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0167926017300755
2017
-
[48]
FreePDK: An open-source variation-aware design kit,
J. E. Stine, I. Castellanos, M. Wood, J. Henson, F. Love, W. R. Davis, P. D. Franzon, M. Bucher, S. Basavarajaiah, J. Oh, and R. Jenkal, “FreePDK: An open-source variation-aware design kit,” in2007 IEEE International Conference on Microelectronic Systems Education (MSE’07), 2007, pp. 173–174
2007
-
[49]
WaveScalar,
S. Swanson, K. Michelson, A. Schwerin, and M. Oskin, “WaveScalar,” inProceedings. 36th Annual IEEE/ACM International Symposium on Microarchitecture, 2003. MICRO-36., 2003, pp. 291–302
2003
-
[50]
Vec- PAC: A vectorizable and precision-aware CGRA,
C. Tan, D. Patil, A. Tumeo, G. Weisz, S. Reinhardt, and J. Zhang, “Vec- PAC: A vectorizable and precision-aware CGRA,” in2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), 2023, pp. 1–9
2023
-
[51]
OpenCGRA: An open-source unified framework for modeling, testing, and evaluating CGRAs,
C. Tan, C. Xie, A. Li, K. J. Barker, and A. Tumeo, “OpenCGRA: An open-source unified framework for modeling, testing, and evaluating CGRAs,” in2020 IEEE 38th International Conference on Computer Design (ICCD), 2020, pp. 381–388
2020
-
[52]
The end of Moore’s law: A new begin- ning for information technology,
T. N. Theis and H.-S. P. Wong, “The end of Moore’s law: A new begin- ning for information technology,”Computing in Science & Engineering, vol. 19, no. 2, pp. 41–50, 2017
2017
-
[53]
Single-graph multiple flows: energy efficient design alternative for GPGPUs,
D. V oitsechov and Y . Etsion, “Single-graph multiple flows: energy efficient design alternative for GPGPUs,” p. 205–216, 2014
2014
-
[54]
Control flow coalescing on a hybrid dataflow/von Neumann GPGPU,
——, “Control flow coalescing on a hybrid dataflow/von Neumann GPGPU,” in2015 48th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2015, pp. 216–227
2015
-
[55]
Inter-Thread Communication in Multithreaded, Reconfigurable Coarse-Grain Arrays,
D. V oitsechov, O. Port, and Y . Etsion, “Inter-Thread Communication in Multithreaded, Reconfigurable Coarse-Grain Arrays,” in2018 51st Annual IEEE/ACM International Symposium on Microarchitecture (MI- CRO), 2018, pp. 42–54
2018
-
[56]
A prototype data flow computer with token labelling,
I. Watson and J. Gurd, “A prototype data flow computer with token labelling,” in1979 International Workshop on Managing Requirements Knowledge (MARK), 1979, pp. 623–628
1979
-
[57]
A hybrid systolic- dataflow architecture for inductive matrix algorithms,
J. Weng, S. Liu, Z. Wang, V . Dadu, and T. Nowatzki, “A hybrid systolic- dataflow architecture for inductive matrix algorithms,” in2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2020, pp. 703–716
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.