Recognition: unknown
Chainwash: Multi-Step Rewriting Attacks on Diffusion Language Model Watermarks
Pith reviewed 2026-05-08 16:02 UTC · model grok-4.3
The pith
Chained rewrites reduce detection of diffusion language model watermarks from 88 percent to under 5 percent after five steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
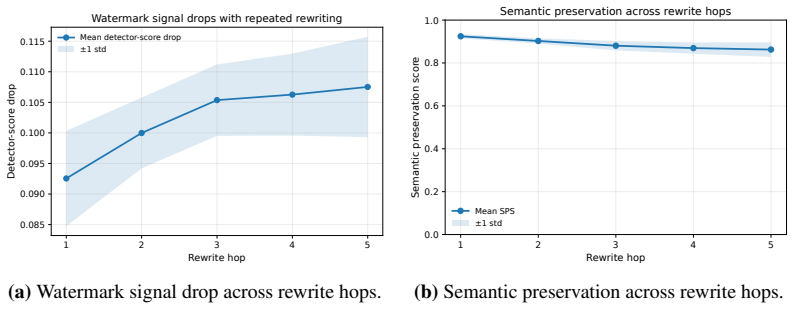
When watermarked text from the LLaDA diffusion language model is subjected to up to five chained rewrites by open-weight language models unaware of the watermark key, using styles such as paraphrase, humanize, simplify, academic, and summarize-expand, the watermark detection rate declines from 87.9 percent on originals to 4.86 percent after five rewrites, with the detector score moving 86 percent of the way toward the null distribution after only three rewrites.
What carries the argument
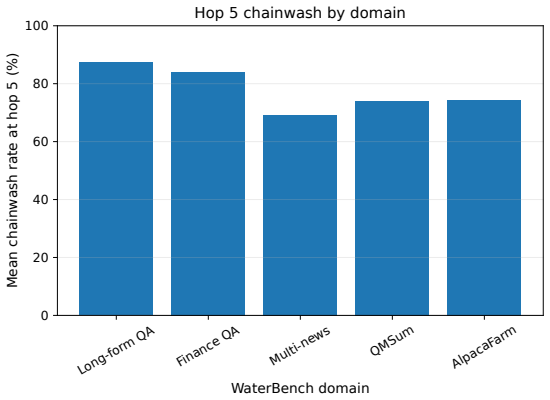
Chained multi-step rewriting attack performed by open-weight models without access to the watermark key, applied across five editing styles and up to five successive hops on 160,500 total texts.
If this is right
- A single rewrite lowers detection to between 14 and 41 percent depending on the rewriter and style.
- After three rewrites the detector score has already dropped 86 percent of the distance from the watermarked baseline to the null distribution.
- The attack succeeds uniformly across four different rewriters ranging from 1.5B to 8B parameters and all five tested styles.
- After five rewrites, 94.76 percent of the texts that were originally detected are no longer flagged.
Where Pith is reading between the lines
- Watermark designs for diffusion models may need explicit testing against sequences of ordinary editing steps rather than isolated modifications.
- Real-world deployment of these watermarks should anticipate users who chain multiple refinement tools before publishing or sharing the text.
- Detection thresholds or scoring methods could be recalibrated by measuring how quickly scores decay under repeated open-model rewrites.
- The same chained-rewrite approach may expose weaknesses in watermark schemes proposed for other non-autoregressive generation techniques.
Load-bearing premise
The open-weight rewriters have no knowledge of the watermark key and the tested styles and models represent realistic post-generation editing that would occur in practice.
What would settle it
Generate a fresh set of watermarked LLaDA outputs, rewrite each one five times in the same styles with comparable open models, and check whether the final detection rate stays near 4.86 percent or rises substantially above it.
Figures


read the original abstract
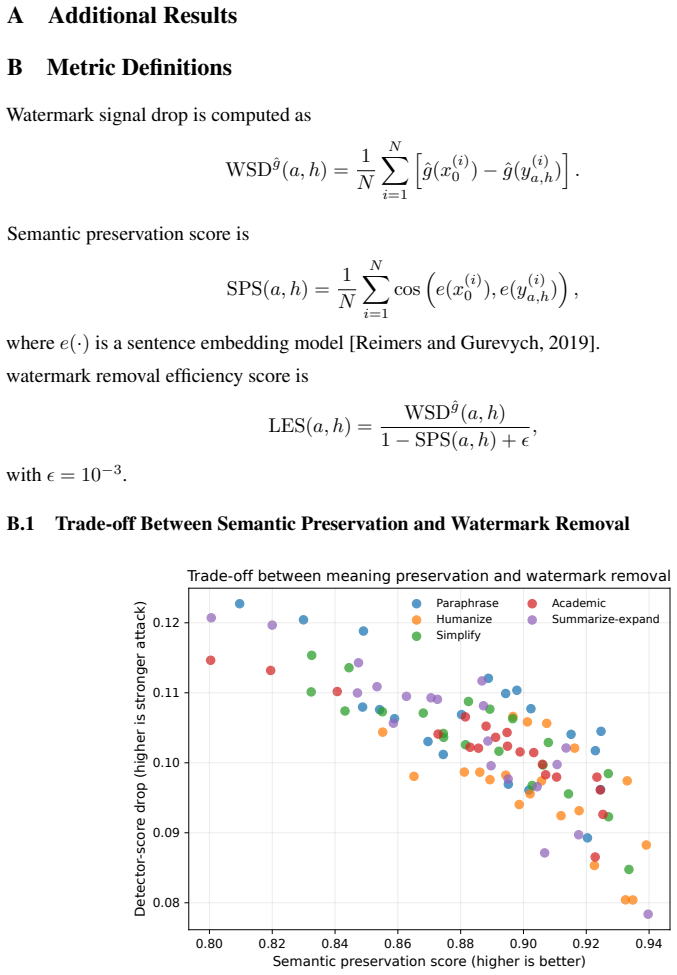
Statistical watermarking is a common approach for verifying whether text was written by a language model. Most existing schemes assume autoregressive generation, where tokens are produced left to right and contextual hashing is well defined. Diffusion language models generate text by denoising tokens in arbitrary order, so these schemes cannot be applied directly. A recent watermark by Gloaguen et al. addresses this gap for LLaDA 8B Instruct and reports true positive detection above 99%. This paper studies what happens when watermarked text is rewritten not once but several times. Using the same watermark configuration, 1,605 watermarked completions of about 300 tokens each are produced across five WaterBench domains. Each completion is rewritten by four open weight language models, from 1.5B to 8B parameters, none of which know the watermark key. Five rewrite styles are tested: paraphrase, humanize, simplify, academic, and summarize expand. Each style is chained for up to five hops, producing 160,500 rewritten texts in total. The watermark is detected on 87.9% of the original outputs at the standard significance threshold. After a single rewrite, detection falls to between 14% and 41% depending on the rewriter and style. After five chained rewrites, detection falls to 4.86%, meaning 94.76% of the originally detected texts are no longer flagged. After three rewrites, the detector score has dropped 86% of the way from its watermarked baseline toward the null distribution. Repeated rewriting is therefore a much stronger attack than a single rewrite, and the result holds across all four rewriters tested.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a statistical watermark for diffusion language models (LLaDA 8B Instruct) is vulnerable to multi-step rewriting attacks. Using 1,605 watermarked ~300-token completions across five WaterBench domains, each text is rewritten up to five times by four open-weight LLMs (1.5B–8B parameters) under five styles (paraphrase, humanize, simplify, academic, summarize-expand), yielding 160,500 texts. Original detection is 87.9% at the standard threshold; this falls to 14–41% after one rewrite and to 4.86% after five chained rewrites, with the detector score having moved 86% of the way from the watermarked baseline toward the null distribution after only three hops.
Significance. If the reported measurements hold, the work supplies large-scale empirical evidence that repeated rewriting constitutes a substantially stronger attack than single-pass editing against diffusion-model watermarks. The scale (160k+ texts, four rewriters, five styles, five hops) and the consistent aggregate drop across conditions provide a concrete benchmark for the robustness limits of current statistical watermarking schemes in non-autoregressive settings.
major comments (2)
- [Methods] Methods: The manuscript states that rewriters have no knowledge of the watermark key and that the same configuration is used, but does not specify the exact detection threshold, the scoring formula, or how the diffusion denoising order interacts with the hash-based watermark. Without these details it is impossible to verify that the observed score drop is not partly an artifact of threshold choice or normalization.
- [Results] Results: The central claim that five hops reduce detection to 4.86% (94.76% of originally detected texts lost) is reported only in aggregate. No per-rewriter, per-style, or per-domain tables with confidence intervals or paired statistical tests (e.g., McNemar) are referenced, making it difficult to assess whether the drop is uniformly load-bearing or driven by a subset of conditions.
minor comments (2)
- [Abstract] The abstract lists four rewriters but does not name the specific models or their parameter counts; adding these identifiers would improve reproducibility.
- [Results] A plot of detector-score distributions at each hop (0–5) would make the 86% movement toward the null distribution visually immediate and would complement the aggregate percentages.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation for minor revision. The comments highlight opportunities to improve reproducibility and transparency, which we address below by committing to specific additions in the revised manuscript.
read point-by-point responses
-
Referee: [Methods] Methods: The manuscript states that rewriters have no knowledge of the watermark key and that the same configuration is used, but does not specify the exact detection threshold, the scoring formula, or how the diffusion denoising order interacts with the hash-based watermark. Without these details it is impossible to verify that the observed score drop is not partly an artifact of threshold choice or normalization.
Authors: We agree that explicit specification is necessary for full reproducibility. In the revised manuscript we will add a new subsection in Methods that states the exact detection threshold (p < 0.01, matching the standard configuration in Gloaguen et al.), reproduces the scoring formula (normalized hash-match proportion), and explains that the watermark biases token logits at every denoising step via a key-dependent hash of prior tokens, independent of the random denoising order. Because the rewriters never receive the key, this setup ensures the observed score drop cannot be an artifact of threshold choice or normalization. revision: yes
-
Referee: [Results] Results: The central claim that five hops reduce detection to 4.86% (94.76% of originally detected texts lost) is reported only in aggregate. No per-rewriter, per-style, or per-domain tables with confidence intervals or paired statistical tests (e.g., McNemar) are referenced, making it difficult to assess whether the drop is uniformly load-bearing or driven by a subset of conditions.
Authors: We acknowledge that aggregate reporting alone limits assessment of uniformity. In the revision we will add supplementary tables that break down detection rates by rewriter, style, and domain, each with 95% bootstrap confidence intervals. We will also report McNemar’s test p-values for paired original-vs-rewritten comparisons within each condition and reference these tables from the main Results section. The aggregate figures will remain as the primary summary statistic. revision: yes
Circularity Check
No significant circularity; purely empirical measurements
full rationale
The paper reports direct empirical measurements of watermark detection rates on 1605 base completions before and after 1-5 chained rewrites by four open-weight models across five styles. No derivations, equations, fitted parameters, or predictions are present. The central result (detection dropping from 87.9% to 4.86% after five hops) is a straightforward before/after count under fixed threshold and black-box rewriters that lack the key. No self-citations, ansatzes, or uniqueness claims are load-bearing; the setup is self-contained and externally verifiable by replication.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
cc/paper/2021/hash/958c530554f78bcd8e97125b70e6973d-Abstract.html
URLhttps://proceedings.neurips. cc/paper/2021/hash/958c530554f78bcd8e97125b70e6973d-Abstract.html. Avi Bagchi, Akhil Bhimaraju, Moulik Choraria, Daniel Alabi, and Lav R. Varshney. Watermarking discrete diffusion language models,
2021
-
[2]
Ruibo Chen, Yihan Wu, Yanshuo Chen, Chenxi Liu, Junfeng Guo, and Heng Huang
URLhttps://arxiv.org/abs/2511.02083. Ruibo Chen, Yihan Wu, Yanshuo Chen, Chenxi Liu, Junfeng Guo, and Heng Huang. A watermark for order-agnostic language models. InInternational Conference on Learning Representations,
-
[3]
Scalable watermarking for identifying large language model outputs
doi: 10.1038/s41586-024-08025-4. URLhttps://doi.org/10. 1038/s41586-024-08025-4. Thibaud Gloaguen, Robin Staab, Nikola Jovanovi ´c, and Martin Vechev. Watermarking diffusion language models. InInternational Conference on Learning Representations,
-
[4]
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein
URLhttps://arxiv.org/abs/2601.22985. John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. InProceedings of the 40th International Conference on Machine Learning,
-
[5]
A watermark for large language models.arXiv preprint arXiv:2301.10226, 2023a
URLhttps://arxiv.org/abs/2301.10226. John Kirchenbauer, Jonas Geiping, Yuxin Wen, Manli Shu, Khalid Saifullah, Kezhi Kong, Kasun Fernando, Aniruddha Saha, Micah Goldblum, and Tom Goldstein. On the reliability of water- marks for large language models. InInternational Conference on Learning Representations,
-
[6]
Rohith Kuditipudi, John Thickstun, Tatsunori Hashimoto, and Percy Liang
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/hash/ 575c450013d0e99e4b0ecf82bd1afaa4-Abstract-Conference.html. Rohith Kuditipudi, John Thickstun, Tatsunori Hashimoto, and Percy Liang. Robust distortion-free watermarks for language models.Transactions on Machine Learning Research,
2023
-
[7]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
URLhttps://arxiv.org/abs/2310.16834. Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji- Rong Wen, and Chongxuan Li. LLaDA: Large language diffusion models,
work page internal anchor Pith review arXiv
-
[8]
Large Language Diffusion Models
URLhttps: //arxiv.org/abs/2502.09992. 10 Julien Piet, Chawin Sitawarin, Vivian Fang, Norman Mu, and David Wagner. Mark my words: Analyzing and evaluating language model watermarks,
work page internal anchor Pith review arXiv
-
[9]
Mark my words: Analyzing and evaluating language model watermarks.arXiv preprint arXiv:2312.00273,
URLhttps://arxiv.org/abs/ 2312.00273. Qwen Team. Qwen2.5 technical report,
-
[10]
URLhttps://arxiv.org/abs/2412.15115. Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pages 3982–3992. Association for Computational Linguistics,
work page internal anchor Pith review arXiv 2019
-
[11]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
URLhttps: //arxiv.org/abs/1908.10084. Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil Feizi. Can AI-generated text be reliably detected?,
work page internal anchor Pith review arXiv 1908
-
[12]
S., Kumar, A., Balasubramanian, S., Wang, W., and Feizi, S
URLhttps://arxiv.org/abs/ 2303.11156. Ruixiang Tang, Yu-Neng Chuang, and Xia Hu. The science of detecting LLM-generated text.Com- munications of the ACM, 67(4):50–59,
-
[13]
Shangqing Tu, Yuliang Sun, Yushi Bai, Jifan Yu, Lei Hou, and Juanzi Li
URLhttps://arxiv.org/abs/2303.07205. Shangqing Tu, Yuliang Sun, Yushi Bai, Jifan Yu, Lei Hou, and Juanzi Li. WaterBench: Towards holistic evaluation of watermarks for large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 1517– 1542, Bangkok, Thailand,
-
[14]
The lessons of developing process reward models in mathematical reasoning
Association for Computational Linguistics. doi: 10.18653/v1/ 2024.acl-long.83. URLhttps://aclanthology.org/2024.acl-long.83/. Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Derek F. Wong, and Lidia S. Chao. A survey on LLM-generated text detection: Necessity, methods, and fu- ture directions.Computational Linguistics, 51(1):275–338,
-
[15]
11 A Additional Results B Metric Definitions Watermark signal drop is computed as WSDˆg(a, h) = 1 N NX i=1 h ˆg(x(i) 0 )−ˆg(y(i) a,h) i
URL https://openreview.net/forum?id=SsmT8aO45L. 11 A Additional Results B Metric Definitions Watermark signal drop is computed as WSDˆg(a, h) = 1 N NX i=1 h ˆg(x(i) 0 )−ˆg(y(i) a,h) i . Semantic preservation score is SPS(a, h) = 1 N NX i=1 cos e(x(i) 0 ), e(y(i) a,h) , wheree(·)is a sentence embedding model [Reimers and Gurevych, 2019]. watermark removal ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.