Recognition: unknown
Accelerating LMO-Based Optimization via Implicit Gradient Transport
Pith reviewed 2026-05-08 14:59 UTC · model grok-4.3
The pith
LMO-IGT uses implicit gradient transport to reach O(ε^{-3.5}) complexity in stochastic LMO optimization with one gradient per iteration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LMO-IGT achieves an iteration complexity of O(ε^{-3.5}) for finding approximate stationary points in nonconvex problems by leveraging implicit gradient transport, while using only one stochastic gradient evaluation per iteration. This improves on the O(ε^{-4}) rate of standard stochastic LMO methods and approaches the O(ε^{-3}) rate of variance-reduced LMO methods without their additional gradient costs. The analysis also provides a common stationarity measure, the regularized support function, that unifies gradient-norm and Frank-Wolfe-gap concepts.
What carries the argument
Implicit gradient transport (IGT), a technique that adjusts the point at which the stochastic gradient is evaluated to mimic variance reduction effects within the single-gradient-per-iteration constraint of LMO-based updates.
If this is right
- Stochastic LMO methods can achieve faster convergence rates without increasing the number of gradient evaluations per iteration.
- LMO-IGT provides a practical middle ground between basic stochastic methods and variance-reduced ones in terms of both theory and computation.
- The regularized support function allows consistent analysis across constrained and unconstrained LMO formulations.
- Instantiations such as Muon-IGT demonstrate improved empirical performance over standard counterparts with minimal added cost.
Where Pith is reading between the lines
- IGT could be applied to other first-order methods that use momentum or normalization to potentially improve their rates similarly.
- If the transport preserves the properties as claimed, it may reduce reliance on full variance reduction in large-scale training scenarios.
- Testing the method on problems with known convergence bottlenecks could reveal whether the 3.5 exponent holds in practice beyond the analyzed settings.
Load-bearing premise
The implicit gradient transport step introduces no bias or extra computational overhead that would change the effective per-iteration cost or invalidate the stochastic properties used in the convergence proofs.
What would settle it
An experiment on a simple nonconvex quadratic or logistic regression problem where the measured number of iterations to reach a target stationarity level for LMO-IGT does not fall between those of stochastic LMO and variance-reduced LMO, or where per-iteration time exceeds that of standard stochastic LMO.
Figures



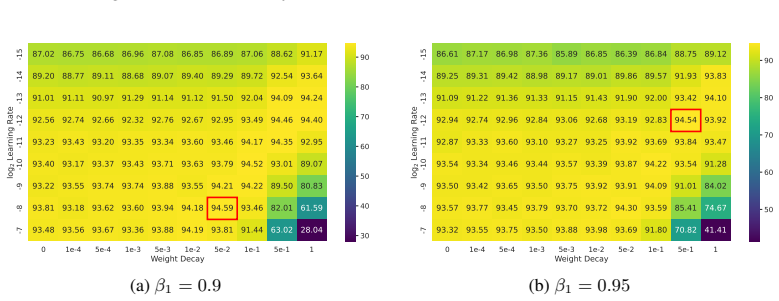
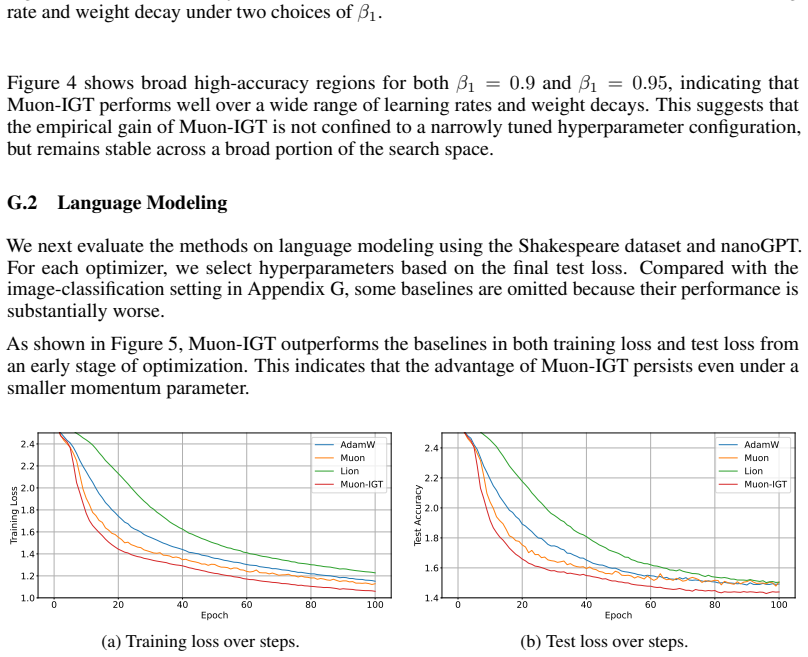

read the original abstract
Recent optimizers such as Lion and Muon have demonstrated strong empirical performance by normalizing gradient momentum via linear minimization oracles (LMOs). While variance reduction has been explored to accelerate LMO-based methods, it typically incurs substantial computational overhead due to additional gradient evaluations. At the same time, the theoretical understanding of LMO-based methods remains fragmented across unconstrained and constrained formulations. Motivated by these limitations, we propose \emph{LMO-IGT}, a new class of stochastic LMO-based methods leveraging implicit gradient transport (IGT). We further introduce a unified framework for stochastic LMO-based optimization together with a new stationarity measure, the \emph{regularized support function} (RSF), which bridges gradient-norm and Frank--Wolfe-gap notions within a common framework. By evaluating stochastic gradients at transported points, LMO-IGT accelerates convergence while retaining the single-gradient-per-iteration structure of standard stochastic LMO. Our analysis establishes that stochastic LMO achieves an iteration complexity of $\mathcal{O}(\varepsilon^{-4})$, variance-reduced LMO achieves $\mathcal{O}(\varepsilon^{-3})$ at the cost of additional gradient evaluations, and LMO-IGT achieves $\mathcal{O}(\varepsilon^{-3.5})$ using only a single stochastic gradient per iteration. Empirically, LMO-IGT consistently improves over stochastic LMO counterparts with negligible overhead. Among its instantiations, Muon-IGT achieves the strongest overall performance across evaluated settings, demonstrating that IGT provides an effective and practical acceleration mechanism for modern LMO-based optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LMO-IGT, a family of stochastic LMO-based optimizers that incorporate implicit gradient transport (IGT) to accelerate convergence while preserving a single stochastic gradient evaluation per iteration. It introduces a unified analysis framework for stochastic LMO methods together with the regularized support function (RSF) as a new stationarity measure that interpolates between gradient-norm and Frank-Wolfe gap notions. The central theoretical claims are iteration complexities of O(ε^{-4}) for plain stochastic LMO, O(ε^{-3}) for variance-reduced LMO (at the price of extra gradient calls), and O(ε^{-3.5}) for LMO-IGT; empirical results on standard benchmarks show consistent gains with negligible overhead, with Muon-IGT performing best.
Significance. If the IGT bias/variance analysis holds, the work supplies a practical, low-overhead acceleration mechanism for popular LMO-based optimizers (Lion, Muon) that avoids the extra gradient cost of variance reduction while improving the iteration complexity. The RSF stationarity measure is a useful unifying device that could facilitate future comparisons across constrained and unconstrained LMO settings. The single-gradient-per-iteration property is a concrete strength relative to existing variance-reduced LMO analyses.
major comments (2)
- [Complexity analysis of LMO-IGT (Theorem on IGT rate)] The O(ε^{-3.5}) claim for LMO-IGT (stated in the abstract and proved in the complexity analysis) requires that the stochastic gradient evaluated at the implicitly transported point remains an unbiased or sufficiently low-bias estimator whose variance is controlled by the same Lipschitz/smoothness constants used for standard stochastic LMO. The manuscript does not supply an explicit bias bound or variance lemma for the transported point; without it the rate improvement cannot be verified and the comparison to the O(ε^{-4}) baseline collapses.
- [Definition and properties of RSF (Section 3)] The RSF stationarity measure is introduced to unify prior notions, yet the manuscript does not demonstrate that the IGT estimator's properties translate directly to an RSF-gap bound at the claimed rate. Any mismatch between the gradient-norm analysis and the RSF-gap analysis would render the stated complexities incomparable to prior LMO literature.
minor comments (2)
- [Abstract] The abstract asserts concrete complexity results without listing the key assumptions (e.g., smoothness, bounded variance, domain geometry) under which they hold; a one-sentence assumption summary would improve readability.
- [Preliminaries and notation] Notation for the transport map and the implicit point is introduced without a compact reference table; readers must hunt through the text to recall the definitions when following the proofs.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight opportunities to clarify key aspects of the analysis, which we will address in the revision.
read point-by-point responses
-
Referee: [Complexity analysis of LMO-IGT (Theorem on IGT rate)] The O(ε^{-3.5}) claim for LMO-IGT (stated in the abstract and proved in the complexity analysis) requires that the stochastic gradient evaluated at the implicitly transported point remains an unbiased or sufficiently low-bias estimator whose variance is controlled by the same Lipschitz/smoothness constants used for standard stochastic LMO. The manuscript does not supply an explicit bias bound or variance lemma for the transported point; without it the rate improvement cannot be verified and the comparison to the O(ε^{-4}) baseline collapses.
Authors: We agree that an explicit bias and variance lemma for the IGT estimator would improve clarity. The proof of the LMO-IGT complexity theorem already controls the bias via the smoothness assumption and the contraction of the implicit transport operator, with the resulting bias term absorbed into the O(ε^{-3.5}) rate without additional gradient evaluations. The variance bound follows from the same Lipschitz constants as the baseline stochastic LMO analysis. In the revision we will insert a dedicated lemma immediately preceding the main theorem that states and proves these bounds explicitly, making the rate derivation self-contained and directly comparable to the O(ε^{-4}) baseline. revision: yes
-
Referee: [Definition and properties of RSF (Section 3)] The RSF stationarity measure is introduced to unify prior notions, yet the manuscript does not demonstrate that the IGT estimator's properties translate directly to an RSF-gap bound at the claimed rate. Any mismatch between the gradient-norm analysis and the RSF-gap analysis would render the stated complexities incomparable to prior LMO literature.
Authors: Section 3 defines the RSF as a convex combination of the squared gradient norm and the Frank-Wolfe gap, with the interpolation parameter chosen so that the RSF is Lipschitz-equivalent to the gradient norm (with constants independent of the domain). Because the IGT analysis bounds the gradient norm at the transported point, the same rate transfers to the RSF gap. We will add a short proposition in Section 3 that records this equivalence explicitly and confirms that the LMO-IGT convergence in gradient norm implies the stated RSF rate, ensuring direct comparability with both unconstrained and constrained LMO results in the literature. revision: yes
Circularity Check
No circularity: analysis derives bounds from IGT estimator properties without self-referential reduction
full rationale
The paper introduces LMO-IGT and the RSF stationarity measure as new constructs to unify gradient-norm and Frank-Wolfe gap notions, then states complexity results as outcomes of its analysis (O(ε^{-4}) for stochastic LMO, O(ε^{-3}) for variance-reduced, O(ε^{-3.5}) for LMO-IGT). No equations or definitions in the abstract reduce the target rates or RSF gap to fitted parameters, prior self-citations, or tautological renamings; the single-gradient-per-iteration structure and IGT transport are presented as independent mechanisms whose bias/variance properties are analyzed to obtain the improved rate. The derivation chain remains self-contained against external benchmarks and does not invoke load-bearing self-citations or ansatzes smuggled from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stochastic gradients are unbiased with bounded variance
invented entities (2)
-
Implicit Gradient Transport (IGT)
no independent evidence
-
Regularized Support Function (RSF)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Old optimizer, new norm: An anthology
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology. InOPT 2024: Optimization for Machine Learning,
2024
-
[2]
Generalized Spectral Statistics in the Kicked Ising model
arXiv:2506.15816. Lizhang Chen, Bo Liu, Kaizhao Liang, and qiang liu. Lion secretly solves a constrained optimization: As lyapunov predicts. InThe Twelfth International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Lizhang Chen, Jonathan Li, and qiang liu
URLhttps://openreview.net/forum?id=e4xS9ZarDr. Lizhang Chen, Jonathan Li, and qiang liu. Muon optimizes under spectral norm constraints. InOPT 2025: Optimization for Machine Learning,
2025
-
[4]
X Chen, M Hong, S Liu, and R Sun
URL https://openreview.net/forum?id= bBSq533vFH. X Chen, M Hong, S Liu, and R Sun. On the convergence of a class of adam-type algorithms for non-convex optimization. In7th International Conference on Learning Representations, ICLR 2019,
2019
-
[5]
Yiming Dong, Huan Li, and Zhouchen Lin. Convergence rate analysis of lion.arXiv preprint arXiv:2411.07724,
-
[6]
Gower, Mark Schmidt, Francis Bach, and Peter Richtarik
10 Robert M. Gower, Mark Schmidt, Francis Bach, and Peter Richtarik. Variance-reduced methods for machine learning, 2020.arXiv:2010.00892. Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimiza- tion. InInternational Conference on Machine Learning, pages 1842–1850. PMLR,
-
[7]
Stochastic conditional gradient++, 2020.arXiv:1902.06992
Hamed Hassani, Amin Karbasi, Aryan Mokhtari, and Zebang Shen. Stochastic conditional gradient++, 2020.arXiv:1902.06992. Elad Hazan, Kfir Y Levy, and Shai Shalev-Shwartz. Beyond convexity: stochastic quasi-convex opti- mization. InProceedings of the 29th International Conference on Neural Information Processing Systems-Volume 1, pages 1594–1602,
-
[8]
Wei Jiang and Lijun Zhang. Convergence analysis of the lion optimizer in centralized and distributed settings.arXiv preprint arXiv:2508.12327,
-
[9]
Adam: A Method for Stochastic Optimization
arXiv:1412.6980. Alex Krizhevsky et al. Learning multiple layers of features from tiny images,
work page internal anchor Pith review arXiv
-
[10]
Convergence rate of frank-wolfe for non-convex objectives.arXiv preprint arXiv:1607.00345, 2016
arXiv:1607.00345. Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019.arXiv:1711.05101. Shuntaro Nagashima and Hideaki Iiduka. Improved convergence rates of muon optimizer for nonconvex optimization, 2026.arXiv:2601.19400. Yurii Nesterov.Introductory lectures on convex optimization: A basic course, volume
-
[11]
arXiv preprint arXiv:2507.01598 , year =
Naoki Sato, Hiroki Naganuma, and Hideaki Iiduka. Convergence bound and critical batch size of muon optimizer, 2025.arXiv:2507.01598. 11 Rolf Schneider.Convex bodies: the Brunn–Minkowski theory, volume
-
[12]
Lions and muons: Optimization via stochastic frank- wolfe.arXiv preprint arXiv:2506.04192, 2025
Maria-Eleni Sfyraki and Jun-Kun Wang. Lions and muons: Optimization via stochastic frank-wolfe, 2025.arXiv:2506.04192. Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the convergence analysis of muon, 2025.arXiv:2505.23737. Chongjie Si, Debing Zhang, and Wei Shen. Adamuon: Adaptive muon optimizer,
-
[13]
Adamuon: Adaptive muon optimizer.arXiv preprint arXiv:2507.11005, 2025
arXiv:2507.11005. Tijmen Tieleman and Geoffrey Hinton. Lecture 6.5—rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning,
-
[14]
A central challenge in comparing these lines is that they adopt different notions of stationarity
12 A Related Works Viewed historically, the literature leading to our setting has evolved along three largely independent directions: improved local scaling via adaptive moments, improved geometry via normalization, sign-based, or matrix-aware updates, and improved stochastic efficiency via recursive estimators or extrapolation-based mechanisms, including...
2011
-
[15]
Moreover, LR2η β1 + β1β2√1−β 2 + 1 2 ≤LR 2 · 1 RT 2/3 1 +T 1/3 + 1 2 =O RL T 1/3
= 1 T 1/3 , 1 T ≤ 1 T 1/3 . Moreover, LR2η β1 + β1β2√1−β 2 + 1 2 ≤LR 2 · 1 RT 2/3 1 +T 1/3 + 1 2 =O RL T 1/3 . Substituting these bounds into (A30) yields 1 T T−1X t=0 E ΨC,λ(wt) ≤O R(∆F +σ+L) T 1/3 =O T −1/3 , which proves Corollary 3.4. F Detailed Experimental Settings All experiments were conducted in a Python 3.11.9 environment on a machine with a 64-...
2024
-
[16]
Empirically, we observe no significant difference in performance between the two implementations. F.1 Multiclass Image Classification For the image classification experiments in Section 4 and Appendix G.1, we follow the experimental setup of Sfyraki and Wang (2025) and train ResNet-18 on CIFAR-10 for 200 epochs. A single training run takes 1 to 2 hours on...
2025
-
[17]
F.2 Language Modeling For the language modeling experiments in Appendix G.2, we follow the setup of Sfyraki and Wang (2025) and train nanoGPT (Karpathy,
2025
-
[18]
Table 4: Hyperparameter search space for language modeling on Shakespeare. learning rate weight decay Muon 1e-1, 5e-2, 1e-2, 5e-3, 1e-3, 5e-4, 1e-4 0, 1e-4, 5e-4, 1e-3, 5e-3, 1e-2, 5e-2, 1e-1, 5e-1, 1.0 Muon-IGT 1e-3, 5e-4, 1e-4, 5e-5, 1e-5, 5e-6, 1e-6 Lion AdamW Lion-IGT 1e-5, 5e-6, 1e-6, 5e-7, 1e-7, 5e-8 Table 5: Final hyperparameter settings for langua...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.