Recognition: unknown
Causal Probing for Internal Visual Representations in Multimodal Large Language Models
Pith reviewed 2026-05-08 11:54 UTC · model grok-4.3
The pith
Multimodal LLMs store concrete visual entities in localized network spots but spread abstract concepts across many layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Activation steering interventions demonstrate that entities undergo localized memorization invariant to scale, whereas abstract concepts exhibit global distribution that requires increasing model depth; reverse steering reveals compensatory latent activation surges when outputs are blocked, and visual reasoning tasks expose a disconnect where recognized geometric relations remain static features without triggering procedural execution.
What carries the argument
Activation steering, the targeted modification of internal neuron activations to causally test effects on downstream behavior and representations.
If this is right
- Model depth primarily enables encoding of globally distributed abstract visual concepts.
- Entity localization stays stable across different model scales.
- Blocking explicit outputs produces compensatory increases in latent activations between perception and generation stages.
- Recognition of geometric relations does not activate the sequential steps required for abstract problem solving.
Where Pith is reading between the lines
- Architectures could allocate shallower layers to entity recognition and reserve deeper stacks for abstract reasoning tasks.
- Training objectives might be adjusted to strengthen the link between perceived relations and procedural execution.
- The same steering approach could be applied to non-visual concepts to test whether the localized-versus-distributed split is modality-specific.
Load-bearing premise
Steering activations cleanly affects only the intended visual concepts without side effects on unrelated processing, and the four chosen categories truly separate localized entities from distributed abstracts.
What would settle it
Finding that abstract concepts remain localized in shallow layers of larger models or that steering changes entity recognition performance more than abstract concept performance.
Figures


















read the original abstract
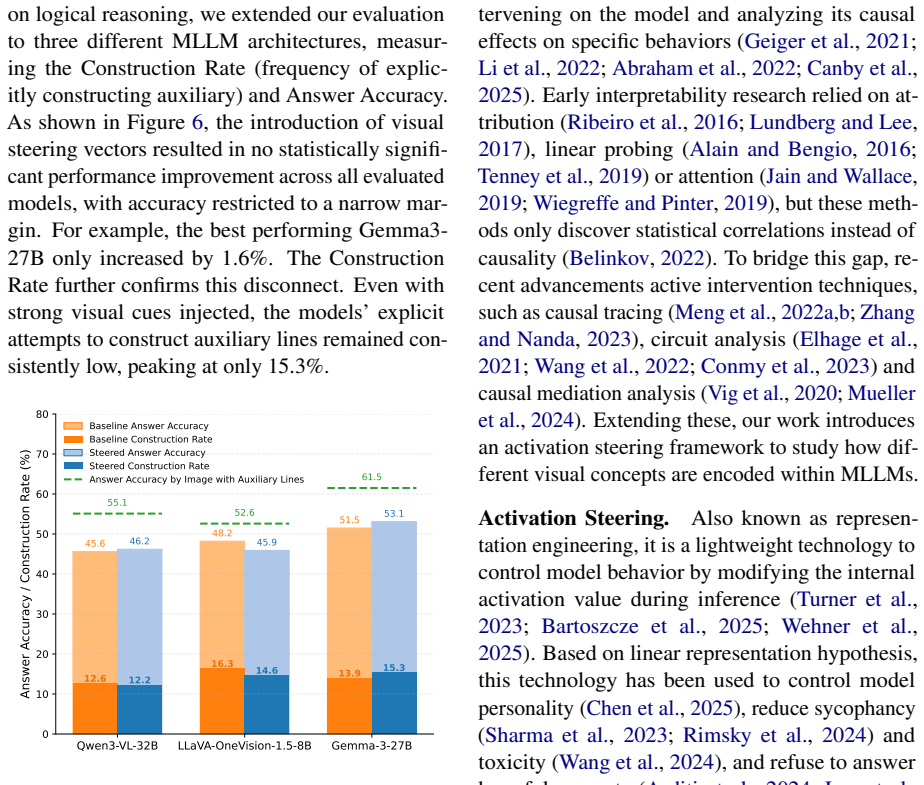
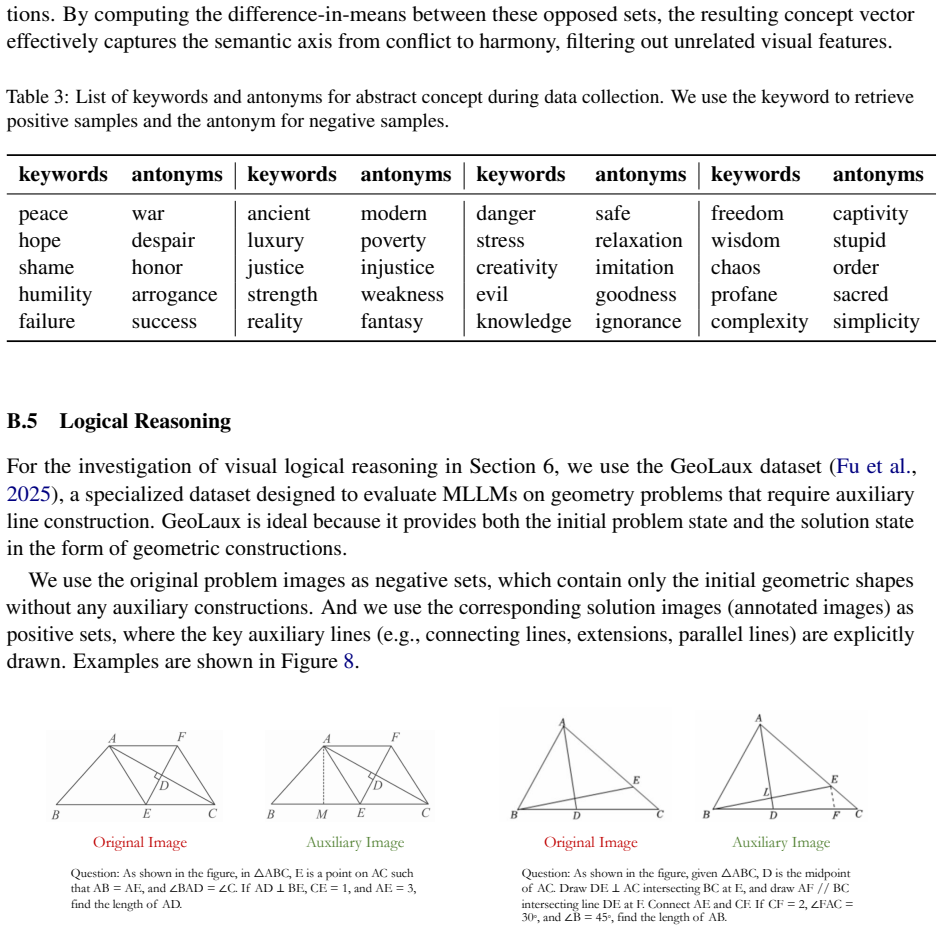
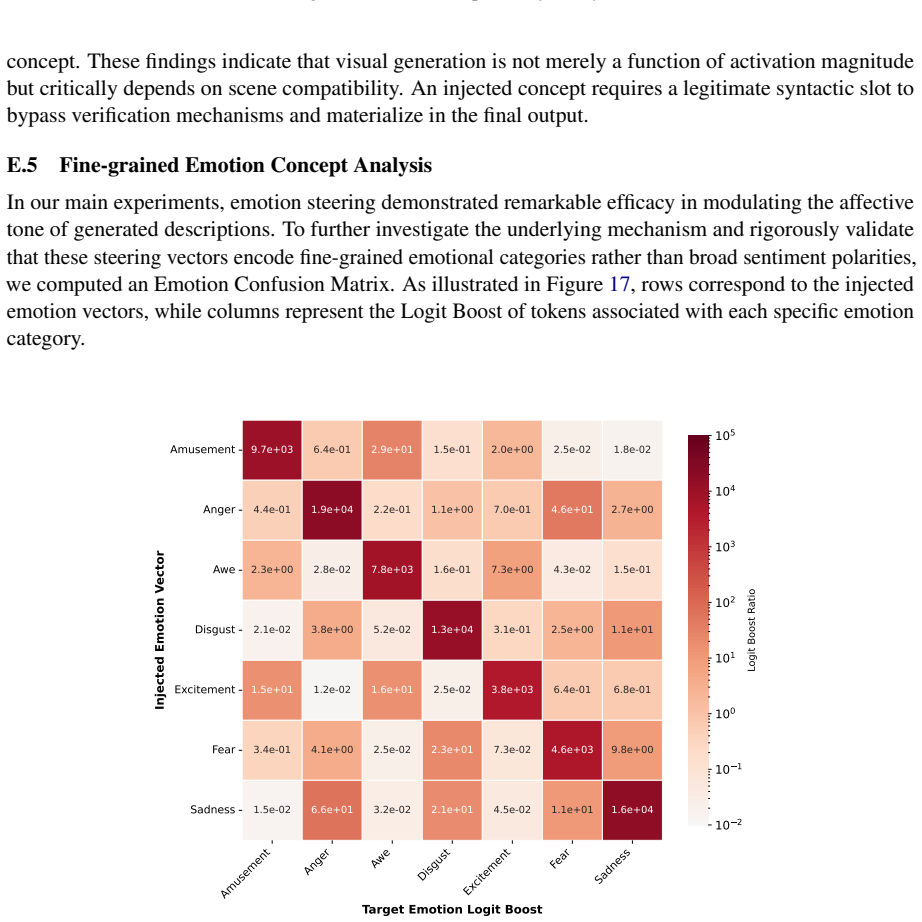
Despite the remarkable success of Multimodal Large Language Models (MLLMs) across diverse tasks, the internal mechanisms governing how they encode and ground distinct visual concepts remain poorly understood. To bridge this gap, we propose a causal framework based on activation steering to actively probe and manipulate internal visual representations. Through systematic intervention across four visual concept categories, our results reveal a divergence in concept encoding: entities exhibit distinct localized memorization, whereas abstract concepts are globally distributed across the network. Critically, this divergence uncovers a mechanistic driver of scaling laws: increasing model depth is indispensable for encoding distributed and complex abstract concepts, whereas entity localization remains remarkably invariant to scale. Furthermore, reverse steering uncovers that blocking explicit output triggers a surge in latent activations, exposing a compensatory mechanism between perception and generation. Finally, extending our analysis to visual reasoning, we expose a disconnect between perception and reasoning although MLLMs successfully recognize geometric relations, they treat them merely as static visual features, failing to trigger the procedural execution necessary for abstract problem-solving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a causal framework based on activation steering to probe and manipulate internal visual representations in multimodal large language models (MLLMs). Through systematic interventions across four visual concept categories, it claims a divergence in encoding: entities exhibit localized memorization while abstract concepts are globally distributed. This is presented as a mechanistic driver of scaling laws, with model depth required for distributed abstract concepts but entity localization invariant to scale. Additional findings include compensatory latent activation surges under reverse steering and a disconnect between successful perception of geometric relations and failure to trigger procedural reasoning.
Significance. If the empirical results are robustly supported by controls, quantitative metrics, and statistical validation, the work would offer valuable mechanistic insights into concept encoding in MLLMs and a potential explanation for depth-dependent scaling behaviors. The causal intervention approach, if cleanly implemented, could help distinguish memorization from distributed representation and highlight limitations in visual reasoning.
major comments (3)
- [Abstract] Abstract: The central claims of localized entity memorization versus globally distributed abstract concepts, along with the scaling-law mechanism, are stated as outcomes of interventions but are unsupported by any quantitative metrics (e.g., activation change magnitudes, layer-wise effect sizes), controls, statistical tests, or methodology details. This is load-bearing because the divergence and invariance claims cannot be evaluated without evidence that the observed patterns exceed intervention artifacts.
- [Abstract and causal framework description] The validity of activation steering as a clean causal intervention is assumed without reported specificity metrics, null-intervention controls, or analysis of side effects (noted in the abstract for reverse steering). This undermines the localization-versus-distribution distinction and the mechanistic link to scaling, as broad or compensatory changes could produce the reported patterns without reflecting intrinsic encoding properties.
- [Scaling analysis section] The scaling-laws analysis claims depth is indispensable for abstract concepts while entity localization is scale-invariant, yet no cross-model-size comparisons, layer-specific intervention results, or falsifiable predictions are quantified to establish this as mechanistic rather than observational.
minor comments (2)
- [Abstract] The four visual concept categories used for interventions are not enumerated or justified, making it difficult to assess whether they cleanly separate entity-like from abstract-like items.
- [Visual reasoning analysis] The visual reasoning experiments claim a disconnect between perception and procedural execution, but the specific tasks, success criteria, and how 'static visual features' were distinguished from reasoning steps are not detailed.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications from the manuscript and indicating where revisions will strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of localized entity memorization versus globally distributed abstract concepts, along with the scaling-law mechanism, are stated as outcomes of interventions but are unsupported by any quantitative metrics (e.g., activation change magnitudes, layer-wise effect sizes), controls, statistical tests, or methodology details. This is load-bearing because the divergence and invariance claims cannot be evaluated without evidence that the observed patterns exceed intervention artifacts.
Authors: We agree that the abstract would benefit from more explicit quantitative support. The full manuscript reports activation change magnitudes, layer-wise effect sizes, and statistical tests (including p-values from paired interventions) in Sections 3.2 and 4, with methodology details in Section 2. To address the concern directly, we will revise the abstract to incorporate key quantitative metrics and reference the controls, ensuring the claims are evaluable from the summary alone. revision: yes
-
Referee: [Abstract and causal framework description] The validity of activation steering as a clean causal intervention is assumed without reported specificity metrics, null-intervention controls, or analysis of side effects (noted in the abstract for reverse steering). This undermines the localization-versus-distribution distinction and the mechanistic link to scaling, as broad or compensatory changes could produce the reported patterns without reflecting intrinsic encoding properties.
Authors: The manuscript includes specificity metrics (e.g., intervention success rates versus random baselines) and null-intervention controls in Section 2.3, with side-effect analysis of compensatory surges presented in the reverse-steering results. We will add a dedicated paragraph in the causal framework section explicitly summarizing these controls and specificity checks to rule out artifacts and reinforce the localization-versus-distribution distinction. revision: partial
-
Referee: [Scaling analysis section] The scaling-laws analysis claims depth is indispensable for abstract concepts while entity localization is scale-invariant, yet no cross-model-size comparisons, layer-specific intervention results, or falsifiable predictions are quantified to establish this as mechanistic rather than observational.
Authors: Our scaling analysis compares interventions across model depths and reports invariance for entity localization with increasing depth requirements for abstract concepts. We will expand the section with additional cross-model-size tables, layer-specific intervention plots, and explicit falsifiable predictions (e.g., that abstract-concept steering fails below a depth threshold) along with the quantitative results that test them. revision: yes
Circularity Check
No circularity: empirical results from activation interventions
full rationale
The paper advances an empirical causal probing framework that applies activation steering interventions across four visual concept categories in MLLMs, then reports observed divergences in layer-wise localization (entities) versus distribution (abstracts) and their invariance or dependence on model depth. These outcomes are presented as direct measurements from the interventions themselves, with no mathematical derivations, parameter fits renamed as predictions, self-referential definitions, or load-bearing self-citations that reduce the central claims to their own inputs by construction. The analysis of scaling laws and compensatory mechanisms follows from the same experimental manipulations rather than any tautological renaming or imported uniqueness theorem.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation steering can causally intervene on and reveal internal visual representations in MLLMs
Reference graph
Works this paper leans on
-
[1]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
Llava-onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661. Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda
work page internal anchor Pith review arXiv
-
[2]
The internal state of an llm knows when it’s lying.arXiv preprint arXiv:2304.13734,
Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083. Amos Azaria and Tom Mitchell. 2023. The internal state of an llm knows when it’s lying.arXiv preprint arXiv:2304.13734. Seyedarmin Azizi, Erfan Baghaei Potraghloo, and Massoud Pedram. 2025. Activation steering for chain-of-thou...
-
[3]
Towards automated circuit discovery for mech- anistic interpretability.Advances in Neural Informa- tion Processing Systems, 36:16318–16352. Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. 2022. Knowledge neurons in pretrained transformers. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Vol...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
arXiv preprint arXiv:2210.13382 , year=
Emergent world representations: Exploring a sequence model trained on a synthetic task.arXiv preprint arXiv:2210.13382. Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. 2023. Inference- time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530. She...
-
[5]
Reducing hallucinations in vision-language models via latent space steering.arXiv preprint arXiv:2410.15778. Scott M Lundberg and Su-In Lee. 2017. A unified ap- proach to interpreting model predictions.Advances in neural information processing systems, 30. Samuel Marks and Max Tegmark. 2023. The geometry of truth: Emergent linear structure in large langua...
-
[6]
Haiyan Zhao, Heng Zhao, Bo Shen, Ali Payani, Fan Yang, and Mengnan Du
Igniting language intelligence: The hitch- hiker’s guide from chain-of-thought reasoning to lan- guage agents.ACM Computing Surveys, 57(8):1–39. Haiyan Zhao, Heng Zhao, Bo Shen, Ali Payani, Fan Yang, and Mengnan Du. 2024. Beyond single concept vector: Modeling concept subspace in llms with gaussian distribution.arXiv preprint arXiv:2410.00153. Andy Zou, L...
-
[7]
If the instruction is purely about removing objects, extract the object name
-
[8]
add", "place
If the instruction contains other actions like "add", "place", "change", "replace", or implies adding something new (e.g., "remove X and add Y"), output exactly "SKIP"
-
[9]
SKIP". Examples: Input:
Do not output a full sentence. Output ONLY the object name or "SKIP". Examples: Input: "Remove the candles." Output: candle Input: "Remove the horses that are on the bridge." Output: horse Input: "Remove the vegetables and add candies to the bowl." Output: SKIP Input: "Remove all the food and place a laptop on the table." Output: SKIP We finally construct...
2025
-
[10]
Does the Steered Text explicitly mention the Target Concept or words highly related to it?
-
[11]
Does the Steered Text describe the image in the style of the Target Concept compared to the Base Text?
-
[12]
strength
If the Base Text already contained the concept, answer 1 only if the Steered Text maintains or emphasizes it. Task: Output ’1’ if the injection is SUCCESSFUL (the concept is clearly present). Output ’0’ if the injection is FAILED (the concept is missing or the text is nonsense). Output Format: Only output a single digit: 0 or 1. Do not output any other te...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.