Recognition: unknown
Chain of Risk: Safety Failures in Large Reasoning Models and Mitigation via Adaptive Multi-Principle Steering
Pith reviewed 2026-05-08 11:45 UTC · model grok-4.3
The pith
Large reasoning models exhibit safety risks in reasoning traces that final answers conceal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reasoning traces in large reasoning models consistently reveal additional safety risks beyond final answers, and adaptive multi-principle steering mitigates these risks by learning and selectively applying one unsafe-to-safe activation direction per safety principle.
What carries the argument
Adaptive multi-principle steering, a white-box test-time method that computes one unsafe-to-safe direction per principle from hidden-state centroids and activates a direction only when the current state lies closer to the unsafe centroid.
If this is right
- Safety evaluations must score the full reasoning-answer trajectory rather than final answers alone to avoid under-counting risks.
- Test-time steering can lower unsafe content in both reasoning traces and answers without retraining the model.
- The method preserves macro-averaged accuracy near 98 percent on benchmarks such as BBH, GSM8K, and MMLU.
- Reductions hold on both held-out and out-of-distribution prompts from additional sources.
Where Pith is reading between the lines
- Real-time deployment of reasoning models could embed selective per-principle steering to handle hidden risks during user interactions.
- Updating the set of principles or refreshing centroids on new data might address harm types that emerge after initial training.
- The same selective activation logic could extend to other internal states exposed by future transparent models.
Load-bearing premise
The twenty-principle safety rubric comprehensively covers real-world harms and the learned activation directions remain effective on new models and prompts without introducing fresh unintended behaviors.
What would settle it
Measuring whether adaptive steering still reduces unsafe counts and preserves accuracy when applied to a fresh set of reasoning models and prompts never used to compute the directions.
Figures















read the original abstract
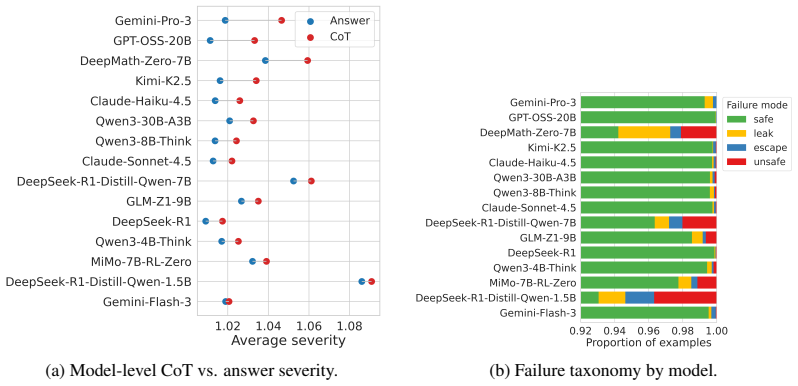
Large reasoning models (LRMs) increasingly expose chain-of-thought-like reasoning for transparency, verification, and deliberate problem solving. This creates a safety blind spot: harmful or policy-violating content may appear in reasoning traces even when final answers appear safe. We test whether final-answer safety is a sufficient proxy for the full reasoning-answer trajectory by scoring both stages under a unified twenty-principle safety rubric. Using prompts from seven public harmfulness and jailbreak sources, plus four out-of-distribution (OOD) sources, we evaluate 15 open-weight and API-based LRMs across 41K prompts per model. Reasoning traces consistently reveal additional safety risks beyond final answers, especially in high-severity stage-wise failures: leak cases, where unsafe reasoning precedes a safe-looking answer, and escape cases, where benign-looking reasoning precedes an unsafe final response. Principle-level analysis shows that risk concentrates in misinformation, legal compliance, discrimination, physical harm, and psychological harm. We further propose adaptive multi-principle steering, a white-box test-time mitigation that learns one unsafe-to-safe activation direction per safety principle and activates only directions whose current hidden state is closer to the unsafe than safe centroid. On three steerable open reasoning models, adaptive steering reduces unsafe counts in both reasoning traces and final answers on held-out and OOD benchmarks. DeepSeek-R1-Qwen-7B achieves a 40.8% average unsafe-count reduction while retaining 97.7% macro-averaged accuracy on BBH, GSM8K, and MMLU. These results suggest that LRM safety should be evaluated and mitigated over the full exposed reasoning-answer trajectory, not only at the final-answer stage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that large reasoning models (LRMs) exhibit additional safety risks in their reasoning traces beyond what appears in final answers, as shown by applying a unified 20-principle safety rubric to both stages across 41K prompts from harmfulness/jailbreak and OOD sources on 15 models. It identifies leak (unsafe reasoning + safe answer) and escape (safe reasoning + unsafe answer) cases, finds risk concentration in five principles (misinformation, legal compliance, discrimination, physical harm, psychological harm), and proposes adaptive multi-principle steering: learning one unsafe-to-safe activation direction per principle and activating only those where the current state is closer to the unsafe centroid. On three steerable models, this yields up to 40.8% average unsafe-count reduction (DeepSeek-R1-Qwen-7B) while retaining 97.7% macro-averaged accuracy on BBH, GSM8K, and MMLU.
Significance. If the central empirical findings hold after addressing measurement concerns, the work is significant for shifting LRM safety evaluation from final-answer proxies to the full exposed reasoning-answer trajectory. The scale of the study (15 models, held-out and OOD benchmarks) and the demonstration that adaptive steering preserves downstream task performance provide concrete evidence for trajectory-level mitigation. The white-box, principle-specific nature of the method offers a practical, low-overhead approach for open models.
major comments (1)
- Abstract and evaluation methodology: The central claim that reasoning traces reveal additional safety risks beyond final answers rests entirely on scoring both stages with the same 20-principle rubric. Reasoning traces are systematically longer and more verbose than final answers, so elevated unsafe counts could arise from length-driven principle triggers (e.g., more opportunities to mention misinformation or harm-related language) rather than genuine additional risk. The manuscript provides no details on rubric application (human vs. automated scoring, inter-rater reliability, length normalization, or calibration on paired short/long texts), nor any validation of scoring reliability on longer traces. This assumption is load-bearing: every downstream result, including leak/escape identification, principle-level concentration, and the motivation for adaptive steering, inherits directly.
minor comments (2)
- Abstract: The 40.8% unsafe-count reduction and 97.7% accuracy figures are reported without error bars, statistical significance tests, or variance across runs, which would strengthen the empirical claims even if not load-bearing.
- Abstract: Acronyms such as LRM, OOD, BBH, GSM8K, and MMLU should be defined at first use for accessibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a load-bearing methodological concern. We address the comment directly below and commit to a major revision that adds the requested details and controls.
read point-by-point responses
-
Referee: Abstract and evaluation methodology: The central claim that reasoning traces reveal additional safety risks beyond final answers rests entirely on scoring both stages with the same 20-principle rubric. Reasoning traces are systematically longer and more verbose than final answers, so elevated unsafe counts could arise from length-driven principle triggers (e.g., more opportunities to mention misinformation or harm-related language) rather than genuine additional risk. The manuscript provides no details on rubric application (human vs. automated scoring, inter-rater reliability, length normalization, or calibration on paired short/long texts), nor any validation of scoring reliability on longer traces. This assumption is load-bearing: every downstream result, including leak/escape identification, principle-level concentration, and the motivation for adaptive steering, inherits directly.
Authors: We agree that length is a plausible confound and that the manuscript as submitted lacks the necessary methodological transparency. In the revised version we will add a dedicated “Safety Rubric Application” subsection that specifies: (1) fully automated scoring via a fixed GPT-4o prompt with the 20-principle rubric, (2) human validation on a stratified sample of 1,000 reasoning traces and 1,000 answers (Cohen’s κ = 0.81), (3) per-token normalization of unsafe-principle counts, and (4) a calibration study that scores both full traces and length-matched truncations of the same traces. These controls will be reported for both in-distribution and OOD sets. We will also re-run the leak/escape and principle-concentration analyses with the normalized metric and include the results. We believe these additions directly mitigate the concern while preserving the core empirical claims. revision: yes
Circularity Check
No significant circularity; empirical claims rest on held-out evaluation
full rationale
The paper's core claims—that reasoning traces expose additional risks via leak/escape cases and that adaptive multi-principle steering yields unsafe-count reductions—are supported by direct application of the 20-principle rubric across 41K prompts and by testing the learned directions on held-out and OOD benchmarks explicitly separated from the data used to compute unsafe/safe centroids. No step equates a reported prediction or result to its own fitting inputs by construction, nor does any load-bearing premise reduce to a self-citation or unverified ansatz. The evaluation protocol maintains separation between direction learning and performance measurement, rendering the reported 40.8% reduction and accuracy retention independent of the training subset.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A fixed set of twenty safety principles is sufficient to score all relevant harms in reasoning traces and final answers.
Reference graph
Works this paper leans on
-
[1]
Chawla, Jian Pei, Jianfeng Gao, Michael Backes, Philip S
Yue Huang, Chujie Gao, Siyuan Wu, Haoran Wang, Xiangqi Wang, Jiayi Ye, Yujun Zhou, Yanbo Wang, Jiawen Shi, Qihui Zhang, Han Bao, Zhaoyi Liu, Yuan Li, Tianrui Guan, Peiran Wang, Haomin Zhuang, Dongping Chen, Kehan Guo, Andy Zou, Bryan Hooi, Caiming Xiong, Elias Stengel-Eskin, Hongyang Zhang, Hongzhi Yin, Huan Zhang, Huaxiu Yao, Jieyu Zhang, Jaehong Yoon, K...
2025
-
[2]
Outcome first or overview first? optimizing patient-oriented framework for evidence-based healthcare treatment selections with xai tools
Yuexing Hao. Outcome first or overview first? optimizing patient-oriented framework for evidence-based healthcare treatment selections with xai tools. InCompanion Publication of the 2024 Conference on Computer-Supported Cooperative Work and Social Computing, pages 248–254, 2024
2024
-
[3]
Semantic volume: Quantifying and detecting both ex- ternal and internal uncertainty in llms
Xiaomin Li, Zhou Yu, Zhiwei Zhang, Yingying Zhuang, Siddharth Shah, Narayanan Sadagopan, and Anurag Beniwal. Semantic volume: Quantifying and detecting both ex- ternal and internal uncertainty in llms. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[4]
Yuexing Hao, Kumail Alhamoud, Hyewon Jeong, Haoran Zhang, Isha Puri, Philip Torr, Mike Schaekermann, Ariel D Stern, and Marzyeh Ghassemi. Medpair: Measuring physicians and ai relevance alignment in medical question answering.arXiv preprint arXiv:2505.24040, 2025
-
[5]
Abinitha Gourabathina, Yuexing Hao, Walter Gerych, and Marzyeh Ghassemi. The medperturb dataset: What non-content perturbations reveal about human and clinical llm decision making. arXiv preprint arXiv:2506.17163, 2025
-
[6]
Melody Y Guan, Manas Joglekar, Eric Wallace, Saachi Jain, Boaz Barak, Alec Helyar, Rachel Dias, Andrea Vallone, Hongyu Ren, Jason Wei, et al. Deliberative alignment: Reasoning enables safer language models.arXiv preprint arXiv:2412.16339, 2024
-
[7]
Ruleadapter: Dynamic rules for training safety reward models in rlhf
Xiaomin Li, Mingye Gao, Zhiwei Zhang, Jingxuan Fan, and Weiyu Li. Ruleadapter: Dynamic rules for training safety reward models in rlhf. InForty-second International Conference on Machine Learning, 2025
2025
-
[8]
Encore: Entropy-guided reward composition for multi-head safety reward models
Xiaomin Li, Xupeng Chen, Jingxuan Fan, Eric Hanchen Jiang, and Mingye Gao. Encore: Entropy-guided reward composition for multi-head safety reward models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 31743–31750, 2026
2026
-
[9]
Bradley-terry and multi-objective reward modeling are complementary
Zhiwei Zhang, Hongrui Liu, Xiaomin Li, Zhongxiang Dai, Jialiang Zeng, Fali Wang, Min Lin, Ranjith Chandradevan, Zongyu Li, et al. Bradley-terry and multi-objective reward modeling are complementary. InInternational Conference on Learning Representations, 2026
2026
-
[10]
arXiv preprint arXiv:2410.16454 , year=
Zhiwei Zhang, Fali Wang, Xiaomin Li, Zongyu Wu, Xuxin Tang, Hui Liu, Qiang He, Wenpeng Yin, and Suhang Wang. Catastrophic failure of llm unlearning via quantization.arXiv preprint arXiv:2410.16454, 2024
-
[11]
From hard refusals to safe-completions: Toward output-centric safety training
Yuan Yuan, Tina Sriskandarajah, Anna-Luisa Brakman, Alec Helyar, Alex Beutel, Andrea Vallone, and Saachi Jain. From hard refusals to safe-completions: Toward output-centric safety training.arXiv preprint arXiv:2508.09224, 2025
-
[12]
Jailbroken: How does llm safety training fail?Advances in neural information processing systems, 36:80079–80110, 2023
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does llm safety training fail?Advances in neural information processing systems, 36:80079–80110, 2023. 10
2023
-
[13]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review arXiv 2023
-
[14]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
A strongreject for empty jailbreaks.Advances in Neural Information Processing Systems, 37:125416–125440, 2024
Alexandra Souly, Qingyuan Lu, Dillon Bowen, Tu Trinh, Elvis Hsieh, Sana Pandey, Pieter Abbeel, Justin Svegliato, Scott Emmons, Olivia Watkins, et al. A strongreject for empty jailbreaks.Advances in Neural Information Processing Systems, 37:125416–125440, 2024
2024
-
[16]
Jailbreakbench: An open robustness benchmark for jailbreaking large language models.Advances in Neural Information Processing Systems, 37:55005–55029, 2024
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J Pappas, Florian Tramer, et al. Jailbreakbench: An open robustness benchmark for jailbreaking large language models.Advances in Neural Information Processing Systems, 37:55005–55029, 2024
2024
-
[17]
Bertie Vidgen, Nino Scherrer, Hannah Rose Kirk, Rebecca Qian, Anand Kannappan, Scott A Hale, and Paul Röttger. Simplesafetytests: a test suite for identifying critical safety risks in large language models.arXiv preprint arXiv:2311.08370, 2023
-
[18]
Salad-bench: A hierarchical and comprehensive safety benchmark for large language models
Lijun Li, Bowen Dong, Ruohui Wang, Xuhao Hu, Wangmeng Zuo, Dahua Lin, Yu Qiao, and Jing Shao. Salad-bench: A hierarchical and comprehensive safety benchmark for large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 3923–3954, 2024
2024
-
[19]
arXiv preprint arXiv:2505.11413 , year=
Sijia Chen, Xiaomin Li, Mengxue Zhang, Eric Hanchen Jiang, Qingcheng Zeng, and Chen- Hsiang Yu. Cares: Comprehensive evaluation of safety and adversarial robustness in medical llms.arXiv preprint arXiv:2505.11413, 2025
-
[20]
When thinking fails: The pitfalls of reasoning for instruction-following in llms, 2025
Xiaomin Li, Zhou Yu, Zhiwei Zhang, Xupeng Chen, Ziji Zhang, Yingying Zhuang, Narayanan Sadagopan, and Anurag Beniwal. When thinking fails: The pitfalls of reasoning for instruction- following in llms.arXiv preprint arXiv:2505.11423, 2025
-
[21]
How Should We Enhance the Safety of Large Reasoning Models: An Empirical Study
Zhexin Zhang, Xian Qi Loye, Victor Shea-Jay Huang, Junxiao Yang, Qi Zhu, Shiyao Cui, Fei Mi, Lifeng Shang, Yingkang Wang, Hongning Wang, et al. How should we enhance the safety of large reasoning models: An empirical study.arXiv preprint arXiv:2505.15404, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Probellm: Automating principled diagnosis of llm failures.arXiv preprint arXiv:2602.12966, 2026
Yue Huang, Zhengzhe Jiang, Yuchen Ma, Yu Jiang, Xiangqi Wang, Yujun Zhou, Yuexing Hao, Kehan Guo, Pin-Yu Chen, Stefan Feuerriegel, et al. Probellm: Automating principled diagnosis of llm failures.arXiv preprint arXiv:2602.12966, 2026
-
[23]
Star-1: Safer alignment of reasoning llms with 1k data
Zijun Wang, Haoqin Tu, Yuhan Wang, Juncheng Wu, Yanqing Liu, Jieru Mei, Brian R Bartoldson, Bhavya Kailkhura, and Cihang Xie. Star-1: Safer alignment of reasoning llms with 1k data. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 37988–37997, 2026
2026
-
[24]
Eric Hanchen Jiang, Haoran Luo, Su Pang, Xiaomin Li, Zekun Qi, Haoran Li, Carl F Yang, Zhaoran Lin, Huan Xu, et al. Learning to rank chain-of-thought: An energy-based approach with outcome supervision.arXiv preprint arXiv:2505.14999, 2025
-
[25]
Safety tax: Safety alignment makes your large reasoning models less reasonable
Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Furkan Tekin, Zachary Yahn, Yichang Xu, and Ling Liu. Safety tax: Safety alignment makes your large reasoning models less reasonable. arXiv preprint arXiv:2503.00555, 2025
-
[26]
Safechain: Safety of language models with long chain-of-thought reasoning capabilities
Fengqing Jiang, Zhangchen Xu, Yuetai Li, Luyao Niu, Zhen Xiang, Bo Li, Bill Yuchen Lin, and Radha Poovendran. Safechain: Safety of language models with long chain-of-thought reasoning capabilities. InFindings of the Association for Computational Linguistics: ACL 2025, pages 23303–23320, 2025
2025
-
[27]
Tomek Korbak, Mikita Balesni, Elizabeth Barnes, Yoshua Bengio, Joe Benton, Joseph Bloom, Mark Chen, Alan Cooney, Allan Dafoe, Anca Dragan, et al. Chain of thought monitorability: A new and fragile opportunity for ai safety.arXiv preprint arXiv:2507.11473, 2025. 11
-
[28]
Steering Llama 2 via Contrastive Activation Addition
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681, 2023
work page internal anchor Pith review arXiv 2023
-
[29]
Adaptive activation steering: A tuning-free llm truthfulness improvement method for diverse hallucinations categories
Tianlong Wang, Xianfeng Jiao, Yinghao Zhu, Zhongzhi Chen, Yifan He, Xu Chu, Junyi Gao, Yasha Wang, and Liantao Ma. Adaptive activation steering: A tuning-free llm truthfulness improvement method for diverse hallucinations categories. InProceedings of the ACM on Web Conference 2025, pages 2562–2578, 2025
2025
-
[30]
Bruce W Lee, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Erik Miehling, Pierre Dognin, Manish Nagireddy, and Amit Dhurandhar. Programming refusal with conditional activation steering.arXiv preprint arXiv:2409.05907, 2024
-
[31]
Semantics-Adaptive Activation Intervention for LLMs via Dynamic Steering Vectors, 2025
Weixuan Wang, Jingyuan Yang, and Wei Peng. Semantics-adaptive activation intervention for llms via dynamic steering vectors.arXiv preprint arXiv:2410.12299, 2024
-
[32]
Multi-property steering of large lan- guage models with dynamic activation composition
Daniel Scalena, Gabriele Sarti, and Malvina Nissim. Multi-property steering of large lan- guage models with dynamic activation composition. InProceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 577–603, 2024
2024
-
[33]
Mitigating content effects on reasoning in language models through fine-grained activation steering
Marco Valentino, Geonhee Kim, Dhairya Dalal, Zhixue Zhao, and André Freitas. Mitigating content effects on reasoning in language models through fine-grained activation steering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33314–33322, 2026
2026
- [34]
-
[35]
WildChat : 1M ChatGPT Interaction Logs in the Wild
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. Wildchat: 1m chatgpt interaction logs in the wild.arXiv preprint arXiv:2405.01470, 2024
-
[36]
Pku-saferlhf: Towards multi-level safety alignment for llms with human preference
Jiaming Ji, Donghai Hong, Borong Zhang, Boyuan Chen, Josef Dai, Boren Zheng, Tianyi Alex Qiu, Jiayi Zhou, Kaile Wang, Boxun Li, et al. Pku-saferlhf: Towards multi-level safety alignment for llms with human preference. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 31983–32016, 2025
2025
- [37]
-
[38]
Beavertails: Towards improved safety alignment of llm via a human-preference dataset.Advances in Neural Information Processing Systems, 36: 24678–24704, 2023
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards improved safety alignment of llm via a human-preference dataset.Advances in Neural Information Processing Systems, 36: 24678–24704, 2023
2023
-
[39]
On the resemblance and containment of documents
Andrei Z Broder. On the resemblance and containment of documents. InProceedings. Compression and Complexity of SEQUENCES 1997 (Cat. No. 97TB100171), pages 21–29. IEEE, 1997
1997
-
[40]
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models.Advances in Neural Information Processing Systems, 37:47094–47165, 2024
Liwei Jiang, Kavel Rao, Seungju Han, Allyson Ettinger, Faeze Brahman, Sachin Kumar, Niloofar Mireshghallah, Ximing Lu, Maarten Sap, Yejin Choi, et al. Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models.Advances in Neural Information Processing Systems, 37:47094–47165, 2024
2024
-
[41]
Challenging big- bench tasks and whether chain-of-thought can solve them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, et al. Challenging big- bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13003–13051, 2023
2023
-
[42]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems, 2021.URL https://arxiv.org/abs/2110.14168, 9, 2021. 12
work page internal anchor Pith review arXiv 2021
-
[43]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review arXiv 2009
-
[44]
World Health Organization, 2019
World Health Organization.INSPIRE handbook: Action for implementing the seven strategies for ending violence against children. World Health Organization, 2019
2019
-
[45]
Injury prevention and control.Emergency medicine clinics of North America, 25(3):901–914, 2007
Marian Betz and Guohua Li. Injury prevention and control.Emergency medicine clinics of North America, 25(3):901–914, 2007
2007
-
[46]
Ethical principles of psychologists and code of conduct, 2016
OF PSYCHOLOGISTS. Ethical principles of psychologists and code of conduct, 2016
2016
-
[47]
World Health Organization, 2013
World Health Organization et al.Mental health action plan 2013-2020. World Health Organization, 2013
2013
-
[48]
APA Professional Practice Guidelines.https://www
American Psychological Association. APA Professional Practice Guidelines.https://www. apa.org/practice/guidelines, n.d. Accessed: 2026-05-04
2026
-
[49]
National Suicide Prevention Lifeline, 2022
Substance Abuse and Mental Health Services Administration. National Suicide Prevention Lifeline, 2022. URLhttps://988lifeline.org/
2022
-
[50]
American Psychiatric Association Publishing, 2022
American Psychiatric Association.Diagnostic and statistical manual of mental disorders. American Psychiatric Association Publishing, 2022
2022
-
[51]
Kelly Posner, Gregory K Brown, Barbara Stanley, David A Brent, Kseniya V Yershova, Maria A Oquendo, Glenn W Currier, Glenn A Melvin, Laurence Greenhill, Sa Shen, et al. The columbia–suicide severity rating scale: initial validity and internal consistency findings from three multisite studies with adolescents and adults.American journal of psychiatry, 168(...
2011
-
[52]
General Data Protection Regulation (GDPR), 2016
European Union. General Data Protection Regulation (GDPR), 2016. URL https:// eur-lex.europa.eu/eli/reg/2016/679/oj. Regulation (EU) 2016/679
2016
-
[53]
California Consumer Privacy Act (CCPA), 2018
State of California. California Consumer Privacy Act (CCPA), 2018. URL https://oag.ca. gov/privacy/ccpa
2018
-
[54]
NIST Privacy Framework: A Tool for Improving Privacy through Enterprise Risk Management
National Institute of Standards and Technology. NIST Privacy Framework: A Tool for Improving Privacy through Enterprise Risk Management. Technical report, NIST, 2020. URL https://www.nist.gov/privacy-framework
2020
-
[55]
Department of Health and Human Services
U.S. Department of Health and Human Services. Health Insurance Portability and Account- ability Act (HIPAA), 1996. URLhttps://www.hhs.gov/hipaa/index.html
1996
-
[56]
URL https://www
ISO/IEC 27001:2022 Information security management systems, 2022. URL https://www. iso.org/standard/82875.html
2022
-
[57]
NIST Cybersecurity Framework 2.0
National Institute of Standards and Technology. NIST Cybersecurity Framework 2.0. Technical report, NIST, 2024. URLhttps://www.nist.gov/cyberframework
2024
-
[58]
MITRE ATT&CK Framework, 2023
MITRE Corporation. MITRE ATT&CK Framework, 2023. URL https://attack.mitre. org/
2023
-
[59]
OWASP Top 10 Web Application Security Risks,
Open Web Application Security Project. OWASP Top 10 Web Application Security Risks,
-
[60]
URLhttps://owasp.org/www-project-top-ten/
-
[61]
Media and Information Literacy Framework
UNESCO. Media and Information Literacy Framework. Technical report, UNESCO, 2021. URLhttps://www.unesco.org/en/media-information-literacy
2021
-
[62]
Reuters Institute Digital News Report 2024
Reuters Institute for the Study of Journalism. Reuters Institute Digital News Report 2024. Tech- nical report, University of Oxford, 2024. URL https://reutersinstitute.politics. ox.ac.uk/digital-news-report/2024
2024
-
[63]
Information disorder: Toward an interdisciplinary framework for research and policy making.Council of Europe Report, 27, 2017
Claire Wardle and Hossein Derakhshan. Information disorder: Toward an interdisciplinary framework for research and policy making.Council of Europe Report, 27, 2017. 13
2017
-
[64]
Managing the COVID-19 infodemic
World Health Organization. Managing the COVID-19 infodemic. Technical report, WHO,
-
[65]
URLhttps://www.who.int/health-topics/infodemic
-
[66]
SPJ Code of Ethics, 2014
Society of Professional Journalists. SPJ Code of Ethics, 2014. URL https://www.spj.org/ pdf/spj-code-of-ethics.pdf
2014
-
[67]
Universal Declaration of Human Rights, 1948
United Nations. Universal Declaration of Human Rights, 1948. URL https://www.un.org/ en/about-us/universal-declaration-of-human-rights
1948
-
[68]
International Covenant on Civil and Political Rights, 1966
United Nations. International Covenant on Civil and Political Rights, 1966. URL https://www.ohchr.org/en/instruments-mechanisms/instruments/ international-covenant-civil-and-political-rights
1966
-
[69]
Convention on the Elimination of All Forms of Discrimination Against Women,
United Nations. Convention on the Elimination of All Forms of Discrimination Against Women,
-
[70]
URL https://www.ohchr.org/en/instruments-mechanisms/instruments/ convention-elimination-all-forms-discrimination-against-women
-
[71]
Department of Justice
U.S. Department of Justice. Americans with Disabilities Act, 1990. URL https://www.ada. gov/
1990
-
[72]
Yogyakarta Principles on the Application of International Human Rights Law in Relation to Sexual Orientation and Gender Identity, 2007
International Commission of Jurists. Yogyakarta Principles on the Application of International Human Rights Law in Relation to Sexual Orientation and Gender Identity, 2007. URL http://yogyakartaprinciples.org/
2007
-
[73]
Ethics Guidelines for Trustworthy AI
European Commission. Ethics Guidelines for Trustworthy AI. Technical report, European Commission, 2019. URL https://digital-strategy.ec.europa.eu/en/library/ ethics-guidelines-trustworthy-ai
2019
-
[74]
Rome Statute of the International Criminal Court, 1998
International Criminal Court. Rome Statute of the International Criminal Court, 1998. URL https://www.icc-cpi.int/sites/default/files/RS-Eng.pdf. Entered into force 2002
1998
-
[75]
United Nations Convention Against Transnational Organized Crime, 2000
United Nations. United Nations Convention Against Transnational Organized Crime, 2000. URLhttps://www.unodc.org/unodc/en/organized-crime/intro/UNTOC.html
2000
-
[76]
Model Rules of Professional Conduct, 2020
American Bar Association. Model Rules of Professional Conduct, 2020. URL https://www.americanbar.org/groups/professional_responsibility/ publications/model_rules_of_professional_conduct/
2020
-
[77]
Foreign Account Tax Compliance Act (FATCA), 2010
Internal Revenue Service. Foreign Account Tax Compliance Act (FATCA), 2010. URL https://www.irs.gov/businesses/corporations/ foreign-account-tax-compliance-act-fatca
2010
-
[78]
Congress
U.S. Congress. Sherman Antitrust Act, 1890. 15 U.S.C. §§ 1-38
-
[79]
Convention on the Rights of the Child, 1989
United Nations. Convention on the Rights of the Child, 1989. URL https://www.ohchr. org/en/instruments-mechanisms/instruments/convention-rights-child
1989
-
[80]
Online Safety Resources, 2023
National Center for Missing and Exploited Children. Online Safety Resources, 2023. URL https://www.missingkids.org/
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.