Recognition: unknown
LLM-Enhanced Deep Reinforcement Learning for Task Offloading in Collaborative Edge Computing
Pith reviewed 2026-05-08 05:30 UTC · model grok-4.3
The pith
LeDRL integrates a lightweight LLM to supply strategy priors that improve DRL-based task offloading decisions in collaborative edge networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
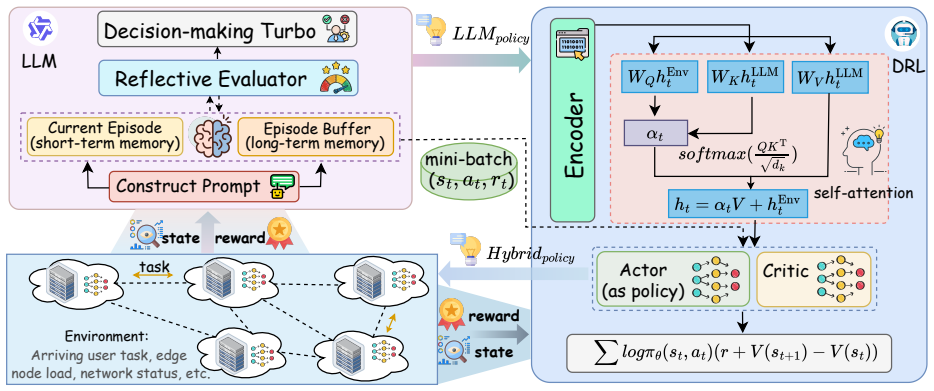
LeDRL constructs context-aware prompts from node status, task semantics, and link dynamics so a lightweight LLM can derive high-level strategy priors; a self-attention alignment module selectively incorporates those priors into DRL policy optimization; and a reflective evaluator distills semantic feedback from completed trajectories to make subsequent LLM queries more informative and temporally stable.
What carries the argument
The LeDRL hybrid framework that couples a lightweight LLM for generating strategy priors from structured prompts with a self-attention-enhanced DRL agent and a reflective evaluator that improves future prompts from execution history.
If this is right
- LeDRL raises task success rate by more than 17 percent over baselines across different network scales.
- The hybrid approach reaches policy convergence faster and maintains better responsiveness under changing conditions.
- The full system runs on Jetson-based edge hardware in the CoEdgeSys prototype without violating resource limits.
Where Pith is reading between the lines
- The same pattern of LLM-generated priors plus trajectory reflection could shorten learning time for DRL agents in other uncertain allocation settings such as wireless channel assignment.
- Reflective prompt improvement offers a concrete mechanism for making repeated LLM calls in sequential decision loops more efficient rather than treating each query in isolation.
- Successful edge-device deployment shows that hybrid LLM-DRL stacks need not require continuous cloud access to deliver usable performance.
Load-bearing premise
The lightweight LLM must reliably produce useful, context-appropriate strategy priors from the structured prompts in real time without adding unacceptable latency or unstable guidance.
What would settle it
Running identical experiments with the LLM component removed and checking whether the reported gains in task success rate and convergence speed disappear or reverse.
Figures






read the original abstract
Collaborative edge computing uses edge nodes in different locations to execute tasks, necessitating dynamic task offloading decisions to maintain low latency and high reliability, especially under unpredictable node failures. Although deep reinforcement learning (DRL) and large language models (LLMs) have shown promise for task offloading, DRL often suffers from high sample inefficiency and local optima, whereas LLMs struggle with real-time decision-making. To address these limitations, we propose \textbf{LeDRL}, a hybrid decision framework that couples a \emph{lightweight LLM} with self-attention-enhanced DRL for real-time task offloading. LeDRL constructs structured, context-aware prompts capturing node status, task semantics, and link dynamics to derive high-level strategy priors. These are selectively processed by a self-attention-based alignment module for context-aware policy optimization. A reflective evaluator distills semantic feedback from past trajectories to guide future prompts, enabling more informative and temporally generalizable LLM queries. Extensive experiments show that LeDRL outperforms baselines in task success rate, convergence speed, and real-time responsiveness across diverse network scales, achieving over 17\% improvement in success rate. Furthermore, we deploy LeDRL on Jetson-based edge devices using our prototype system \textit{CoEdgeSys}, demonstrating its robustness and feasibility under resource constraints. Our code is available at:https://github.com/GalleyG5/LeDRL.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LeDRL, a hybrid framework coupling a lightweight LLM with self-attention-enhanced DRL for real-time task offloading in collaborative edge computing. Structured prompts capture node status, task semantics, and link dynamics to produce strategy priors; a self-attention alignment module and reflective evaluator distill semantic feedback from trajectories to improve policy optimization. The central claims are that LeDRL outperforms baselines in task success rate (by over 17%), convergence speed, and responsiveness across network scales, with a Jetson-based deployment via the CoEdgeSys prototype demonstrating feasibility under resource constraints. Code is released at the cited GitHub repository.
Significance. If the empirical gains prove robust, the work offers a concrete demonstration of how lightweight LLMs can supply temporally generalizable priors to mitigate DRL sample inefficiency in latency-sensitive edge settings. The open-source release and hardware prototype are clear strengths that aid reproducibility and practical assessment.
major comments (2)
- [Experimental evaluation] The experimental results (described in the abstract and presumably §5) report >17% success-rate improvement and faster convergence without stating the number of independent trials, baseline configurations, statistical significance tests, or controls for overfitting/hyperparameter sensitivity. This leaves the central performance claim weakly supported.
- [Architecture and system deployment] No ablation removing the reflective evaluator, no per-component latency breakdown on Jetson hardware, and no measurement of how often LLM priors are used versus overridden by the DRL policy are provided. Without these, the attribution of convergence-speed and real-time responsiveness gains specifically to the hybrid mechanism cannot be verified, directly affecting the deployment claims.
minor comments (1)
- [Abstract] The abstract states 'over 17% improvement in success rate' without naming the precise baseline or metric variant in the summary paragraph.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and outline the revisions we will implement to improve experimental rigor and clarify component contributions.
read point-by-point responses
-
Referee: [Experimental evaluation] The experimental results (described in the abstract and presumably §5) report >17% success-rate improvement and faster convergence without stating the number of independent trials, baseline configurations, statistical significance tests, or controls for overfitting/hyperparameter sensitivity. This leaves the central performance claim weakly supported.
Authors: We acknowledge that the manuscript does not explicitly report the number of independent trials or include statistical significance testing. In the revised version, Section 5 will be updated to state that all results are averaged over 10 independent runs using different random seeds, with means and standard deviations provided. A table will be added detailing baseline configurations and hyperparameter settings. We will also include paired t-test results to establish statistical significance of the performance gains (p < 0.05). A hyperparameter sensitivity analysis will be incorporated to address overfitting concerns. These additions will strengthen the empirical claims. revision: yes
-
Referee: [Architecture and system deployment] No ablation removing the reflective evaluator, no per-component latency breakdown on Jetson hardware, and no measurement of how often LLM priors are used versus overridden by the DRL policy are provided. Without these, the attribution of convergence-speed and real-time responsiveness gains specifically to the hybrid mechanism cannot be verified, directly affecting the deployment claims.
Authors: We agree that these details are needed to verify the hybrid mechanism's contributions. The revision will include an ablation study removing the reflective evaluator, with quantitative comparison of its effect on convergence and success rates. For the Jetson-based CoEdgeSys deployment, we will add per-component latency measurements for LLM inference, self-attention alignment, and DRL policy execution. We will also instrument and report the frequency of LLM prior adoption versus DRL overrides based on alignment module outputs. These will be added to the experimental and deployment sections. revision: yes
Circularity Check
No circularity: empirical claims rest on experiments without self-referential derivations or fitted predictions
full rationale
The paper proposes the LeDRL hybrid framework (lightweight LLM for strategy priors + self-attention DRL + reflective evaluator) and supports its performance claims solely through experimental comparisons to baselines plus a Jetson deployment. No equations, parameter-fitting procedures, or derivation chains are present in the abstract or described architecture that could reduce a 'prediction' to an input by construction. Self-citations, if any, are not load-bearing for the central empirical results, which remain externally falsifiable via the reported success-rate gains and latency measurements.
Axiom & Free-Parameter Ledger
invented entities (1)
-
LeDRL hybrid framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Decentralized task offloading in edge computing: an offline-to-online reinforcement learning approach.IEEE Transactions on Computers, 2024
Hongcai Lin, Lei Yang, Hao Guo, and Jiannong Cao. Decentralized task offloading in edge computing: an offline-to-online reinforcement learning approach.IEEE Transactions on Computers, 2024
2024
-
[2]
Online dis- tributed waveform-synchronization for acoustic sensor networks with dynamic topology.EURASIP Journal on Audio, Speech, and Music Processing, 2023(1):55, 2023
Aleksej Chinaev, Niklas Knaepper, and Gerald Enzner. Online dis- tributed waveform-synchronization for acoustic sensor networks with dynamic topology.EURASIP Journal on Audio, Speech, and Music Processing, 2023(1):55, 2023
2023
-
[3]
Definition of multi-objective deep reinforcement learning reward functions for self-driving vehicles in the urban environment
Kaya Kuru. Definition of multi-objective deep reinforcement learning reward functions for self-driving vehicles in the urban environment. IEEE Transactions on Intelligent Transportation Systems, 2023
2023
-
[4]
Imitation learning enabled fast and adaptive task scheduling in cloud.Future Generation Computer Systems, 154:160–172, 2024
KaiXuan Kang, Ding Ding, HuaMao Xie, et al. Imitation learning enabled fast and adaptive task scheduling in cloud.Future Generation Computer Systems, 154:160–172, 2024
2024
-
[5]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
Task offloading with llm-enhanced multi-agent reinforcement learning in uav-assisted edge computing.Sensors, 25(1):175, 2024
Feifan Zhu, Fei Huang, Yantao Yu, Guojin Liu, and Tiancong Huang. Task offloading with llm-enhanced multi-agent reinforcement learning in uav-assisted edge computing.Sensors, 25(1):175, 2024
2024
-
[7]
Task offloading with large language models in mobile edge computing
Youngjin Song, Wookjin Lee, and Sang Hyun Lee. Task offloading with large language models in mobile edge computing. In2024 15th International Conference on Information and Communication Technology Convergence (ICTC), pages 917–921. IEEE, 2024
2024
-
[8]
Task offloading strategies for mobile edge computing: A survey.Computer Networks, page 110791, 2024
Shi Dong, Junxiao Tang, Khushnood Abbas, Ruizhe Hou, Joarder Kam- ruzzaman, Leszek Rutkowski, and Rajkumar Buyya. Task offloading strategies for mobile edge computing: A survey.Computer Networks, page 110791, 2024
2024
-
[9]
Dependent task offloading for edge computing based on deep reinforcement learning
Jin Wang, Jia Hu, Geyong Min, and Wenhan Zhan. Dependent task offloading for edge computing based on deep reinforcement learning. IEEE Transactions on Computers, 71(10):2449–2461, 2021
2021
-
[10]
Dependency tasks offloading and communication resource allocation in collaborative uav networks: A metaheuristic approach
Loc X Nguyen, Yan Kyaw Tun, Tri Nguyen Dang, Yu Min Park, and Han. Dependency tasks offloading and communication resource allocation in collaborative uav networks: A metaheuristic approach. IEEE Internet of Things Journal, 10(10):9062–9076, 2023
2023
-
[11]
Meson: A mobility-aware dependent task offloading scheme for urban vehicular edge computing.IEEE Transactions on Mobile Computing, 23(5):4259–4272, 2023
Liang Zhao, Enchao Zhang, Shaohua Wan, Ammar Hawbani, Al-Dubai, et al. Meson: A mobility-aware dependent task offloading scheme for urban vehicular edge computing.IEEE Transactions on Mobile Computing, 23(5):4259–4272, 2023
2023
-
[12]
WirelessAgent: Large language model agents for intelligent wireless networks,
Jingwen Tong, Wei Guo, Jiawei Shao, Qiong Wu, Zijian Li, Zehong Lin, and Jun Zhang. Wirelessagent: Large language model agents for intelligent wireless networks.arXiv preprint arXiv:2505.01074, 2025
-
[13]
Resource allocation for stable llm training in mobile edge computing
Chang Liu and Jun Zhao. Resource allocation for stable llm training in mobile edge computing. InProceedings of the Twenty-fifth International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, pages 81–90, 2024
2024
-
[14]
Industrial internet of things with large language models (llms): an intelligence-based reinforcement learning approach.IEEE Transactions on Mobile Computing, 2024
Yuzheng Ren, Haijun Zhang, F Richard Yu, Wei Li, Pincan Zhao, and Ying He. Industrial internet of things with large language models (llms): an intelligence-based reinforcement learning approach.IEEE Transactions on Mobile Computing, 2024
2024
-
[15]
Deep reinforcement learning for task offloading in mobile edge computing systems.IEEE Transactions on Mobile Computing, 21(6):1985–1997, 2020
Ming Tang and Vincent WS Wong. Deep reinforcement learning for task offloading in mobile edge computing systems.IEEE Transactions on Mobile Computing, 21(6):1985–1997, 2020
1985
-
[16]
Hybrid redundancy for reliable task offloading in collaborative edge computing
Hao Guo, Lei Yang, Qingfeng Zhang, and Jiannong Cao. Hybrid redundancy for reliable task offloading in collaborative edge computing. IEEE Transactions on Computers, 2025
2025
-
[17]
Ieee 802.11 mac- level fec scheme with retransmission combining.IEEE Transactions on Wireless Communications, 5(1):203–211, 2006
Sunghyun Choi, Youngkyu Choi, and Inkyu Lee. Ieee 802.11 mac- level fec scheme with retransmission combining.IEEE Transactions on Wireless Communications, 5(1):203–211, 2006
2006
-
[18]
Joint optimization of computing offloading and service caching in edge computing-based smart grid
Huan Zhou and Zhenyu Zhang. Joint optimization of computing offloading and service caching in edge computing-based smart grid. IEEE Transactions on Cloud Computing, 11(2):1122–1132, 2022
2022
-
[19]
The surprising effectiveness of ppo in cooperative multi-agent games.Advances in Neural Information Processing Systems, 35:24611–24624, 2022
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games.Advances in Neural Information Processing Systems, 35:24611–24624, 2022
2022
-
[20]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, et al. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[21]
The internet topology zoo.IEEE Journal on Selected Areas in Communications, 29(9):1765–1775, 2011
Simon Knight, Hung X Nguyen, Nickolas Falkner, Rhys Bowden, and Matthew Roughan. The internet topology zoo.IEEE Journal on Selected Areas in Communications, 29(9):1765–1775, 2011
2011
-
[22]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czar- necki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, et al. Value- decomposition networks for cooperative multi-agent learning.arXiv preprint arXiv:1706.05296, 2017
work page Pith review arXiv 2017
-
[23]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
2018
-
[24]
Power of random choices made efficient for fog computing.IEEE Transactions on Cloud Computing, 10(2):1130–1141, 2021
Roberto Beraldi and Gabriele Proietti Mattia. Power of random choices made efficient for fog computing.IEEE Transactions on Cloud Computing, 10(2):1130–1141, 2021
2021
-
[25]
Cost-efficient task offloading in mobile edge computing with layered unmanned aerial vehicles.IEEE Internet of Things Journal, 11(19):30496–30509, 2024
Haitao Yuan, Meijia Wang, Bi, et al. Cost-efficient task offloading in mobile edge computing with layered unmanned aerial vehicles.IEEE Internet of Things Journal, 11(19):30496–30509, 2024
2024
-
[26]
Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, et al. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.