Recognition: unknown
Effective Knowledge Transfer for Multi-Task Recommendation Models
Pith reviewed 2026-05-08 06:14 UTC · model grok-4.3
The pith
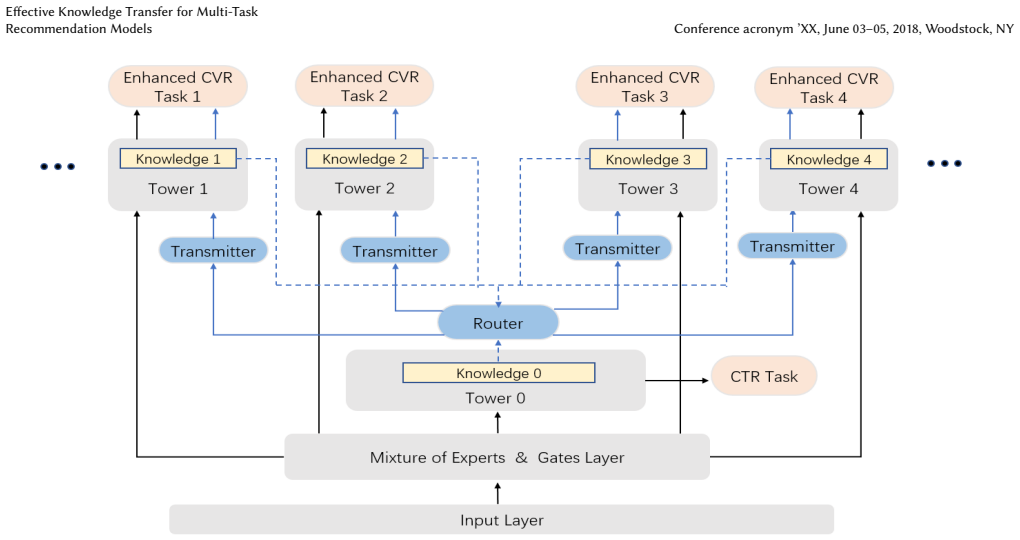
A router module pools knowledge from related user tasks, transmitters adapt it for each conversion task, and enhancement modules prevent signal dilution to improve CVR prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The EKTM method enables each specific CVR task to directly benefit from insights of other tasks through a router module that integrates knowledge across tasks, a transmitter module that transforms the knowledge for the target task, and an enhanced module that ensures the transferred knowledge benefits without diluting task-specific learning.
What carries the argument
Router module that integrates and disseminates knowledge across tasks, transmitter module that transforms routed knowledge for each CVR task, and enhanced module that preserves original task signals.
If this is right
- CVR models gain performance by drawing on data from related tasks instead of training in isolation on sparse conversion labels.
- The router-transmitter-enhancement design reduces negative transfer that commonly occurs when tasks are simply trained together.
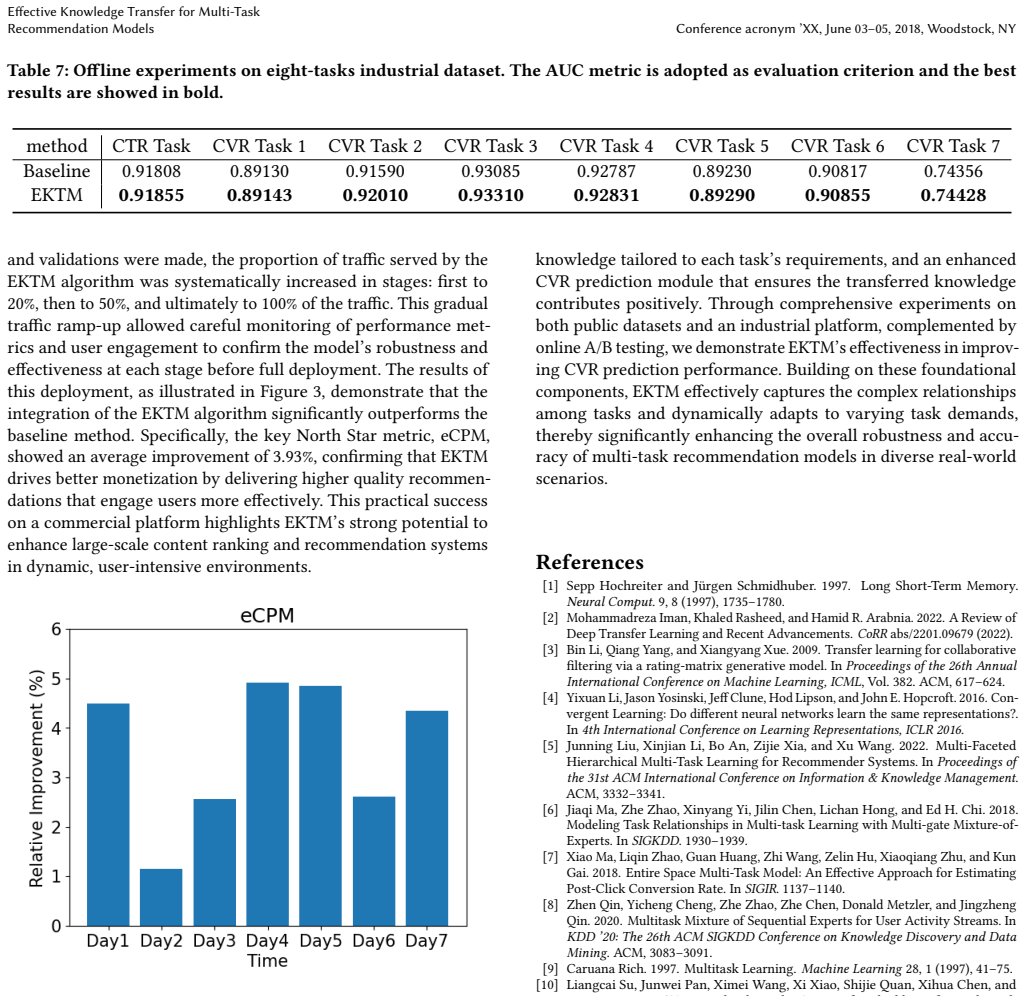
- Large-scale platforms can expect measurable business impact such as the reported 3.93 percent eCPM increase when the modules are deployed.
- Once validated offline, the same structure can be rolled out to multiple production scenarios without retraining every task from scratch.
Where Pith is reading between the lines
- The same three-part transfer pattern could be tested in other multi-task settings where one outcome is rarer than the others, such as fraud detection alongside normal transaction modeling.
- If the router were made to output task-similarity weights, practitioners could trace which source behaviors most help each conversion objective.
- Extending the transmitter to handle time-varying task relationships might further improve results on seasonal recommendation data.
Load-bearing premise
Knowledge from diverse yet related user behavior tasks can be integrated by the router and transformed by the transmitter and enhanced modules to reliably benefit each specific CVR task without negative transfer or dilution of task-specific signals.
What would settle it
Running the full EKTM architecture on a standard multi-task baseline and finding no lift or a drop in CVR metrics on held-out test data would show the transfer mechanism does not work as claimed.
Figures

read the original abstract
The conversion rate (CVR) is a crucial metric for evaluating the effectiveness of platforms, as it quantifies the alignment of content with audience preferences. However, the limited nature of customers' conversion actions presents a significant challenge for training ranking models effectively. In this paper, we propose an Effective Knowledge Transfer method for Multi-task Recommendation Models (EKTM). This method enables the ranking model to learn from diverse user behaviors, thereby enhancing performance through the transfer of knowledge across distinct yet related tasks. Each specific CVR task can directly benefit from the insights provided by other tasks. To achieve this, we first introduce a router module that integrates and disseminates knowledge across tasks. Subsequently, each CVR task is equipped with a transmitter module that facilitates the transformation of knowledge from the router. Additionally, we propose an enhanced module to ensure that the transferred knowledge benefit the original task learning. Extensive experiments on several benchmark datasets demonstrate that our proposed method outperforms existing state-of-the-art approaches. Online A/B testing on a commercial platform has validated the effectiveness of the EKTM algorithm in large-scale industrial settings, resulting in a 3.93% uplift in effective Cost Per Mille (eCPM). The algorithm has since been fully deployed across two of the platform's main-traffic scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EKTM, a multi-task recommendation architecture for improving CVR prediction. It introduces a router module to integrate and disseminate knowledge across related user-behavior tasks, per-task transmitter modules to transform the integrated knowledge, and enhanced modules to ensure the transferred knowledge benefits the original task without dilution. The central empirical claim is that this design yields consistent outperformance over SOTA baselines on multiple benchmark datasets and delivers a 3.93% eCPM uplift in live A/B tests on a commercial platform, resulting in full deployment.
Significance. If the experimental evidence can be strengthened to isolate the contribution of the proposed modules, the work would offer a concrete, deployable architecture for positive knowledge transfer in multi-task ranking models. The reported online uplift and subsequent deployment indicate immediate industrial relevance for large-scale recommendation systems facing sparse conversion data.
major comments (2)
- [Abstract and experimental results] Abstract and experimental results: the claim of outperforming SOTA and achieving 3.93% online uplift is presented without any description of the baselines, dataset statistics, statistical significance tests, or ablation studies that isolate the router, transmitter, and enhanced modules. This is load-bearing for the central claim, because aggregate gains could arise from added capacity rather than the asserted knowledge-transfer mechanism.
- [Method] Method description: the router-transmitter-enhanced design is asserted to integrate knowledge from diverse tasks and deliver net-positive signal to each CVR task without negative transfer or dilution, yet no per-task ablation (router-only, transmitter-only, enhanced-only), task-similarity analysis, or negative-transfer controls are reported. Without these, the weakest assumption—that the modules reliably prevent interference—remains untested.
minor comments (1)
- [Abstract] The abstract would be clearer if it stated the number of benchmark datasets and the traffic volume of the A/B test.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the empirical support for EKTM. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and experimental results] Abstract and experimental results: the claim of outperforming SOTA and achieving 3.93% online uplift is presented without any description of the baselines, dataset statistics, statistical significance tests, or ablation studies that isolate the router, transmitter, and enhanced modules. This is load-bearing for the central claim, because aggregate gains could arise from added capacity rather than the asserted knowledge-transfer mechanism.
Authors: We agree that the abstract is high-level and that the experimental presentation would be strengthened by explicit details on baselines, dataset statistics, statistical significance testing, and module-isolating ablations. The current results demonstrate consistent outperformance and a live uplift, but to rule out capacity effects we will expand the Experiments section in revision with these elements, including controlled ablations that compare full EKTM against capacity-matched variants lacking individual modules. revision: yes
-
Referee: [Method] Method description: the router-transmitter-enhanced design is asserted to integrate knowledge from diverse tasks and deliver net-positive signal to each CVR task without negative transfer or dilution, yet no per-task ablation (router-only, transmitter-only, enhanced-only), task-similarity analysis, or negative-transfer controls are reported. Without these, the weakest assumption—that the modules reliably prevent interference—remains untested.
Authors: We acknowledge that the manuscript does not currently include the requested per-module ablations, task-similarity analysis, or explicit negative-transfer controls. While the overall multi-task gains and online deployment suggest the design avoids interference, these additional experiments are needed to directly validate the claim. In the revised version we will add router-only, transmitter-only, and enhanced-only ablations, task similarity metrics, and interference controls to test the no-dilution assumption. revision: yes
Circularity Check
No significant circularity; empirical architecture validated externally
full rationale
The paper proposes the EKTM architecture (router for knowledge integration, transmitter for transformation, enhanced module for task-specific benefit) as a method to enable positive transfer across CVR tasks without negative transfer. All load-bearing claims are supported by external empirical results: experiments on benchmark datasets showing outperformance versus SOTA, plus online A/B testing with 3.93% eCPM uplift and full deployment. No equations, fitted parameters, self-citations, or uniqueness theorems are invoked that reduce the central result to a definition or input by construction. The derivation chain consists of architectural description followed by independent validation on held-out data and live traffic, satisfying the criteria for a non-circular empirical contribution.
Axiom & Free-Parameter Ledger
free parameters (2)
- router integration weights
- transmitter transformation parameters
axioms (1)
- domain assumption Knowledge from related auxiliary tasks can be transferred to improve performance on the primary sparse CVR task
invented entities (3)
-
router module
no independent evidence
-
transmitter module
no independent evidence
-
enhanced module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long Short-Term Memory. Neural Comput.9, 8 (1997), 1735–1780
1997
- [2]
-
[3]
Bin Li, Qiang Yang, and Xiangyang Xue. 2009. Transfer learning for collaborative filtering via a rating-matrix generative model. InProceedings of the 26th Annual International Conference on Machine Learning, ICML, Vol. 382. ACM, 617–624
2009
-
[4]
Hopcroft
Yixuan Li, Jason Yosinski, Jeff Clune, Hod Lipson, and John E. Hopcroft. 2016. Con- vergent Learning: Do different neural networks learn the same representations?. In4th International Conference on Learning Representations, ICLR 2016
2016
-
[5]
Junning Liu, Xinjian Li, Bo An, Zijie Xia, and Xu Wang. 2022. Multi-Faceted Hierarchical Multi-Task Learning for Recommender Systems. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. ACM, 3332–3341
2022
-
[6]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H. Chi. 2018. Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of- Experts. InSIGKDD. 1930–1939
2018
-
[7]
Xiao Ma, Liqin Zhao, Guan Huang, Zhi Wang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. 2018. Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate. InSIGIR. 1137–1140
2018
-
[8]
Zhen Qin, Yicheng Cheng, Zhe Zhao, Zhe Chen, Donald Metzler, and Jingzheng Qin. 2020. Multitask Mixture of Sequential Experts for User Activity Streams. In KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, 3083–3091
2020
-
[9]
Caruana Rich. 1997. Multitask Learning.Machine Learning28, 1 (1997), 41–75
1997
-
[10]
Liangcai Su, Junwei Pan, Ximei Wang, Xi Xiao, Shijie Quan, Xihua Chen, and Jie Jiang. 2024. STEM: Unleashing the Power of Embeddings for Multi-task Recommendation.AAAI 2024(2024)
2024
-
[11]
Hongyan Tang, Junning Liu, Ming Zhao, and Xudong Gong. 2020. Progres- sive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations. InRecSys. 269–278
2020
-
[12]
Shavlik, Trevor Walker, and Richard Maclin
Lisa Torrey, Jude W. Shavlik, Trevor Walker, and Richard Maclin. 2010. Transfer Learning via Advice Taking. InAdvances in Machine Learning I: Dedicated to the Memory of Professor Ryszard S. Michalski. Vol. 262. Springer, 147–170
2010
-
[13]
Eric Tzeng, Judy Hoffman, Ning Zhang, Kate Saenko, and Trevor Darrell. 2014. Deep Domain Confusion: Maximizing for Domain Invariance.CoRRabs/1412.3474 (2014)
work page Pith review arXiv 2014
-
[14]
Walker, Eszter Vértes, Yazhe Li, Gabriel Dulac-Arnold, Ankesh Anand, Theophane Weber, and Jessica B
Jacob C. Walker, Eszter Vértes, Yazhe Li, Gabriel Dulac-Arnold, Ankesh Anand, Theophane Weber, and Jessica B. Hamrick. 2023. Investigating the Role of Model-Based Learning in Exploration and Transfer. InInternational Conference on Machine Learning, ICML, Vol. 202. PMLR, 35368–35383
2023
-
[15]
Hao Wang, Tai-Wei Chang, Tianqiao Liu, Jianmin Huang, Zhichao Chen, Chao Yu, Ruopeng Li, and Wei Chu. 2022. ESCM2: Entire Space Counterfactual Multi-Task Model for Post-Click Conversion Rate Estimation. InThe 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 363–372. Conference acronym ’XX, June 03–05, 2018...
2022
-
[16]
Hong Wen, Jing Zhang, Yuan Wang, Fuyu Lv, Wentian Bao, Quan Lin, and Keping Yang. 2020. Entire Space Multi-Task Modeling via Post-Click Behavior Decom- position for Conversion Rate Prediction. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR
2020
-
[17]
Yuewei Wu, Ruiling Fu, Tongtong Xing, Zhenyu Yu, and Fulian Yin. 2025. A user behavior-aware multi-task learning model for enhanced short video recommen- dation.Neurocomputing617 (2025), 129076
2025
-
[18]
Dongbo Xi, Zhen Chen, Peng Yan, Yinger Zhang, Yongchun Zhu, Fuzhen Zhuang, and Yu Chen. 2021. Modeling the Sequential Dependence among Audience Multi- step Conversions with Multi-task Learning in Targeted Display Advertising. In The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, 3745–3755
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.