Recognition: 2 theorem links
· Lean TheoremCRAFT: Forgetting-Aware Intervention-Based Adaptation for Continual Learning
Pith reviewed 2026-05-11 00:45 UTC · model grok-4.3
The pith
CRAFT adapts large language models to new tasks by applying low-rank interventions to hidden representations instead of updating weights, using output divergence to group tasks and KL divergence to limit forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CRAFT operates in three stages that share one KL-based objective: it routes incoming tasks to groups of similar prior tasks by measuring output-distribution divergence; it fine-tunes a low-rank intervention on hidden representations while penalizing deviation from the group's previous output distribution; and it merges the updated intervention into the shared representation using the same KL signal. By moving adaptation into representation space rather than weight space, the framework directly trades off new-task learning against retention of prior behavior without requiring weight modifications.
What carries the argument
Low-rank interventions on hidden representations, routed and regularized by output-distribution divergence and a shared KL objective that simultaneously controls forgetting and performs merging.
If this is right
- Performance improves and forgetting decreases relative to LoRA-based continual learning across benchmarks and model scales.
- The method stays effective regardless of the sequence in which tasks arrive.
- Adaptation occurs without any modification to the underlying model weights.
- Routing, regularization, and merging are handled by one consistent output-space signal.
Where Pith is reading between the lines
- If output divergence fails to capture deeper representational similarity, grouping quality could degrade on highly heterogeneous task collections.
- The same representation-intervention pattern might apply to continual learning in non-language domains where hidden states are accessible.
- Success would imply that many continual-learning problems can be solved by editing activations rather than parameters, reducing the need for storage of past weights or replay buffers.
Load-bearing premise
That output-distribution divergence provides a reliable measure of task similarity for grouping and that penalizing KL divergence to the group's prior state will sufficiently restrain forgetting while still permitting useful adaptation to the new task.
What would settle it
A sequence of tasks whose outputs diverge sharply yet share critical internal features, where CRAFT exhibits either higher forgetting rates or lower final accuracy than weight-updating baselines such as LoRA.
Figures

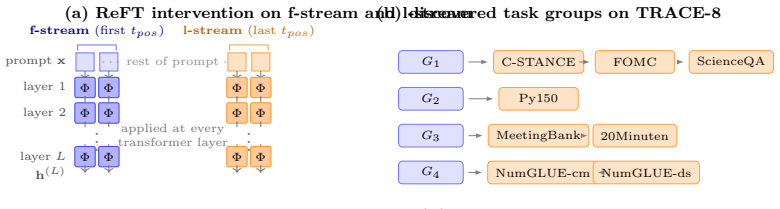




read the original abstract
Large language models (LLMs) can acquire new capabilities through fine-tuning, but continual adaptation often leads to catastrophic forgetting. We propose CRAFT, a continual learning framework that avoids updating model weights by instead learning low-rank interventions on hidden representations. CRAFT proceeds in three stages: it first routes each task to a group of similar tasks based on output-distribution divergence; it then fine-tunes the model using a Kullback-Leibler (KL) divergence against the group's prior state, which directly controls forgetting and determines convergence; finally, it merges interventions for the updated task into the shared representation using the same KL signal. This design unifies routing, regularization, and merging through a single KL-based objective. CRAFT improves overall performance and reduces forgetting compared to strong LoRA-based approaches across multiple benchmarks and model scales, while remaining robust to task ordering. These results suggest that controlling adaptation in representation space, guided by output-space divergence, provides a scalable and principled approach to continual learning in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CRAFT, a continual learning framework for LLMs that avoids direct weight updates by learning low-rank interventions on hidden representations. It routes each task to a group of similar tasks using output-distribution divergence, fine-tunes via a KL divergence loss against the group's prior state (to control forgetting and convergence), and merges the new interventions into the shared representation using the same KL signal. This unifies routing, regularization, and merging under one objective. The authors claim that CRAFT improves overall performance and reduces forgetting relative to strong LoRA-based baselines across multiple benchmarks and model scales while remaining robust to task ordering.
Significance. If the central empirical claims hold under rigorous evaluation, the work would be significant for continual learning in LLMs: it offers a representation-space intervention approach that attempts to make forgetting control explicit via KL regularization while preserving parameter efficiency through low-rank updates. The unification of routing and merging under a single divergence objective is conceptually appealing and could scale better than separate mechanisms. Credit is due for emphasizing robustness to task ordering and for attempting a parameter-light design, though the absence of quantitative results in the abstract limits immediate assessment of impact.
major comments (3)
- [Method (abstract and routing/KL description)] The load-bearing assumption that output-distribution divergence for task grouping produces groups whose prior state, when used as a KL target, simultaneously limits representation-level forgetting and permits effective low-rank intervention learning is not derived or justified. If output-space similarity does not track the hidden-state changes that drive forgetting, the single KL objective cannot reliably serve both regularization and merging; new-task interventions could either overwrite prior group knowledge or fail to converge. This directly affects the routing stage and the claimed forgetting control.
- [Abstract and Experiments section] The abstract asserts performance gains and reduced forgetting versus LoRA baselines across benchmarks and scales but supplies no quantitative results, error bars, specific datasets, model sizes, or statistical tests. Without these, it is impossible to verify whether the data support the central claim that the KL-based unification outperforms strong baselines while remaining robust to task ordering.
- [KL divergence formulation] The definition of the 'group's prior state' and its independence from parameters fitted during the current adaptation must be clarified; if the prior depends on the same process, the KL term risks circularity and may not provide an external anchor for forgetting control.
minor comments (3)
- [Notation and implementation details] Add explicit notation for the low-rank intervention matrices, the KL scaling hyperparameter, and how the prior state is stored or recomputed for each group.
- [Ablation studies] Include ablation studies on the grouping threshold and KL weight to demonstrate that the claimed benefits are not artifacts of particular hyperparameter choices.
- [Results tables/figures] Ensure all result tables and figures report standard deviations across runs and include comparisons to additional continual-learning baselines beyond LoRA variants.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We address each major comment point by point below, offering clarifications based on the manuscript and indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Method (abstract and routing/KL description)] The load-bearing assumption that output-distribution divergence for task grouping produces groups whose prior state, when used as a KL target, simultaneously limits representation-level forgetting and permits effective low-rank intervention learning is not derived or justified. If output-space similarity does not track the hidden-state changes that drive forgetting, the single KL objective cannot reliably serve both regularization and merging; new-task interventions could either overwrite prior group knowledge or fail to converge. This directly affects the routing stage and the claimed forgetting control.
Authors: We acknowledge that the manuscript presents the unification of routing, regularization, and merging under a single KL objective primarily through its design and empirical results rather than a formal derivation. Output-distribution divergence is used for routing because it directly measures similarity in the final predictions, which are the observable outcome of hidden-state interventions; tasks routed together thus share a prior state that serves as a relevant anchor for the KL term. This prior is the output distribution from the model state before the current task's intervention is learned. Our experiments across benchmarks and model scales show consistent reductions in forgetting relative to LoRA baselines, indicating that the approach works in practice. To address the concern, we will add a short explanatory paragraph in the Method section elaborating on why output divergence is a suitable proxy for grouping in representation-space adaptation. revision: partial
-
Referee: [Abstract and Experiments section] The abstract asserts performance gains and reduced forgetting versus LoRA baselines across benchmarks and scales but supplies no quantitative results, error bars, specific datasets, model sizes, or statistical tests. Without these, it is impossible to verify whether the data support the central claim that the KL-based unification outperforms strong baselines while remaining robust to task ordering.
Authors: The referee correctly notes the absence of specific numbers in the abstract. While space constraints often limit abstracts, we agree that including key quantitative highlights would better support the claims. In the revised manuscript, we will update the abstract to incorporate concise results such as average accuracy improvements, forgetting metrics, the specific benchmarks and model scales evaluated, and a note on robustness to task ordering as demonstrated in our ordering experiments. Full tables with error bars and statistical details will remain in the Experiments section. revision: yes
-
Referee: [KL divergence formulation] The definition of the 'group's prior state' and its independence from parameters fitted during the current adaptation must be clarified; if the prior depends on the same process, the KL term risks circularity and may not provide an external anchor for forgetting control.
Authors: We appreciate the request for clarification. The group's prior state is explicitly the output distribution produced by the model equipped only with interventions from prior tasks in the group, evaluated on the new task's data before any new low-rank intervention parameters are optimized. The KL term is then computed against this fixed distribution while learning the new intervention, ensuring the anchor is external to the current adaptation step. We have revised the Method section to provide a precise definition, a step-by-step description of the computation sequence, and pseudocode to eliminate any ambiguity regarding independence and avoid potential misinterpretation of circularity. revision: yes
Circularity Check
No circularity: KL objective presented as design choice without self-referential reduction
full rationale
The abstract and description present CRAFT as a three-stage framework that routes tasks by output divergence, applies KL against a group's prior state for regularization, and merges via the same signal. No equations or self-citations are supplied that define the prior state in terms of the current KL target, fit a parameter to data then relabel it a prediction, or import a uniqueness result from the authors' prior work. The claim that a single KL objective unifies the stages is a stated design decision rather than a derivation that reduces to its own inputs by construction. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- rank of low-rank interventions
- KL divergence scaling or threshold
axioms (2)
- domain assumption Low-rank interventions on hidden representations can approximate the adaptations needed for new tasks without full weight updates.
- domain assumption Output-distribution divergence is a reliable proxy for determining task similarity for routing purposes.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearroutes each task to a group of similar tasks based on output-distribution divergence; fine-tunes using a Kullback-Leibler (KL) divergence against the group's prior state... unifies routing, regularization, and merging through a single KL-based objective
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearCRAFT improves overall performance and reduces forgetting compared to strong LoRA-based approaches
Reference graph
Works this paper leans on
-
[1]
(2020, June)
Farajtabar, M., Azizan, N., Mott, A., & Li, A. (2020, June). Orthogonal gradient descent for continual learning. In International conference on artificial intelligence and statistics (pp. 3762-3773). PMLR
2020
-
[2]
Efficient Lifelong Learning with A-GEM
Chaudhry, A., Ranzato, M. A., Rohrbach, M., & Elhoseiny, M. (2018). Efficient lifelong learning with a-gem. arXiv preprint arXiv:1812.00420
work page Pith review arXiv 2018
-
[3]
I., Grandvalet, Y., & Davoine, F
Xuhong, L. I., Grandvalet, Y., & Davoine, F. (2018, July). Explicit inductive bias for transfer learning with convolutional networks. In International conference on machine learning (pp. 2825-2834). PMLR
2018
- [4]
-
[5]
Ge, C., Wang, X., Zhang, Z., Chen, H., Fan, J., Huang, L., ... & Zhu, W. (2025). Dynamic mixture of curriculum lora experts for continual multimodal instruction tuning. arXiv preprint arXiv:2506.11672
-
[6]
J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S.,
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., ... & Chen, W. (2022). Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022 , 1(2), 3
2022
-
[7]
Huang, J., Cui, L., Wang, A., Yang, C., Liao, X., Song, L., ... & Su, J. (2024, August). Mitigating catastrophic forgetting in large language models with self-synthesized rehearsal. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 1416-1428)
2024
-
[8]
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., ... & Hadsell, R. (2017). Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences , 114(13), 3521-3526
2017
-
[9]
(2022, December)
Korbak, T., Perez, E., & Buckley, C. (2022, December). RL with KL penalties is better viewed as Bayesian inference. In Findings of the Association for Computational Linguistics: EMNLP 2022 (pp. 1083-1091)
2022
-
[10]
Reinforcement fine-tuning naturally mitigates forgetting in continual post-training, 2025
Lai, S., Zhao, H., Feng, R., Ma, C., Liu, W., Zhao, H., ... & Zhu, F. (2025). Reinforcement fine-tuning naturally mitigates forgetting in continual post-training. arXiv preprint arXiv:2507.05386
- [11]
-
[12]
& Lowe, R
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., ... & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in neural information processing systems , 35, 27730-27744
2022
- [13]
- [14]
-
[15]
& Christiano, P
Stiennon, N., Ouyang, L., Wu, J., Ziegler, D., Lowe, R., Voss, C., ... & Christiano, P. F. (2020). Learning to summarize with human feedback. Advances in neural information processing systems , 33, 3008-3021
2020
-
[16]
Vieillard, N., Kozuno, T., Scherrer, B., Pietquin, O., Munos, R., & Geist, M. (2020). Leverage the average: an analysis of kl regularization in reinforcement learning. Advances in Neural Information Processing Systems , 33, 12163-12174
2020
-
[17]
& Huang, X
Wang, X., Chen, T., Ge, Q., Xia, H., Bao, R., Zheng, R., ... & Huang, X. J. (2023, December). Orthogonal subspace learning for language model continual learning. In Findings of the Association for Computational Linguistics: EMNLP 2023 (pp. 10658-10671), 2023a
2023
-
[18]
Y., Zhang, H., Sun, R., Ren, X.,
Wang, Z., Zhang, Z., Lee, C. Y., Zhang, H., Sun, R., Ren, X., ... & Pfister, T. (2022). Learning to prompt for continual learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 139-149)
2022
-
[19]
arXiv preprint arXiv:2310.06762 , year=
Wang, X., Zhang, Y., Chen, T., Gao, S., Jin, S., Yang, X., ... & Huang, X. (2023). Trace: A comprehensive benchmark for continual learning in large language models. arXiv preprint arXiv:2310.06762, 2023b
-
[20]
D., & Potts, C
Wu, Z., Arora, A., Wang, Z., Geiger, A., Jurafsky, D., Manning, C. D., & Potts, C. (2024). Reft: Representation finetuning for language models. Advances in Neural Information Processing Systems , 37, 63908-63962
2024
-
[21]
A., & Bansal, M
Yadav, P., Tam, D., Choshen, L., Raffel, C. A., & Bansal, M. (2023). Ties-merging: Resolving interference when merging models. Advances in neural information processing systems , 36, 7093-7115
2023
-
[22]
Moral: Moe augmented lora for llms’ lifelong learning.arXiv preprint arXiv:2402.11260, 2024
Yang, S., Ali, M. A., Wang, C. L., Hu, L., & Wang, D. (2024). MoRAL: MoE augmented LoRA for LLMs' lifelong learning. arXiv preprint arXiv:2402.11260
-
[23]
(2024, July)
Yu, L., Yu, B., Yu, H., Huang, F., & Li, Y. (2024, July). Language models are Super Mario: Absorbing abilities from homologous models as a free lunch. In Forty-first International Conference on Machine Learning
2024
-
[24]
(2017, July)
Zenke, F., Poole, B., & Ganguli, S. (2017, July). Continual learning through synaptic intelligence. In International conference on machine learning (pp. 3987-3995). PMLR
2017
-
[25]
Wang, Z., Zhang, Z., Ebrahimi, S., Sun, R., Zhang, H., Lee, C. Y., ... & Pfister, T. (2022, October). Dualprompt: Complementary prompting for rehearsal-free continual learning. In European conference on computer vision (pp. 631-648). Cham: Springer Nature Switzerland
2022
-
[26]
Lopez-Paz, D., & Ranzato, M. A. (2017). Gradient episodic memory for continual learning. Advances in neural information processing systems , 30
2017
-
[27]
Wang, L., Xie, J., Zhang, X., Huang, M., Su, H., & Zhu, J. (2023). Hierarchical decomposition of prompt-based continual learning: Rethinking obscured sub-optimality. Advances in Neural Information Processing Systems , 36, 69054-69076, 2023b
2023
-
[28]
Wang, L., Xie, J., Zhang, X., Su, H., & Zhu, J. (2025). Hide-pet: continual learning via hierarchical decomposition of parameter-efficient tuning. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2025a
2025
-
[29]
K., Kim, J., & Kim, J
Shin, H., Lee, J. K., Kim, J., & Kim, J. (2017). Continual learning with deep generative replay. Advances in neural information processing systems, 30
2017
-
[30]
Vela, D., Sharp, A., Zhang, R., Nguyen, T., Hoang, A., & Pianykh, O. S. (2022). Temporal quality degradation in AI models. Scientific reports, 12(1), 11654
2022
-
[31]
& Che, W
Zhao, W., Wang, S., Hu, Y., Zhao, Y., Qin, B., Zhang, X., ... & Che, W. (2024, August). Sapt: A shared attention framework for parameter-efficient continual learning of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 11641-11661)
2024
-
[32]
Feng, Y., Chu, X., Xu, Y., Shi, G., Liu, B., & Wu, X. M. (2024, August). Tasl: Continual dialog state tracking via task skill localization and consolidation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 1266-1279)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.