Recognition: no theorem link
SDFlow: Similarity-Driven Flow Matching for Time Series Generation
Pith reviewed 2026-05-12 03:41 UTC · model grok-4.3
The pith
SDFlow replaces autoregressive token prediction with flow matching in a frozen VQ latent space to generate time series sequences in parallel.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SDFlow performs similarity-driven flow matching entirely inside a frozen vector-quantized latent space. A low-rank manifold decomposition together with a learned anchor prior reduces the effective dimensionality of the token space. A variational formulation then adds a categorical posterior over codebook indices so that discrete supervision is respected during the continuous transport. This combination produces entire sequences at once rather than token by token, eliminating the exposure bias that otherwise compounds across long horizons.
What carries the argument
Similarity-driven flow matching on a low-rank decomposed VQ manifold equipped with a learned anchor prior and a categorical posterior over codebook indices.
If this is right
- Generation becomes fully parallel, so error accumulation across time steps disappears for long sequences.
- Inference speed increases because no sequential token-by-token sampling is required.
- The same frozen VQ codebook can be reused, preserving any pre-trained reconstruction quality while changing only the generative dynamics.
- Discriminative scores improve because the global transport map better matches the joint distribution of the data.
- Context-FID drops most noticeably on long horizons where autoregressive drift is worst.
Where Pith is reading between the lines
- The same low-rank anchor construction could be applied to other discrete latent generators such as masked language models or diffusion on tokens.
- Because the flow operates after quantization, any future improvement to the VQ codebook automatically transfers to SDFlow without retraining the generator.
- Conditional generation tasks become simpler: one can condition the flow directly on the anchor prior rather than on previously generated tokens.
Load-bearing premise
A low-rank manifold plus learned anchors and a categorical posterior can fold discrete codebook constraints into continuous transport dynamics without losing the representational power of the original VQ space.
What would settle it
On standard long-sequence benchmarks, measure Context-FID of SDFlow samples against the same VQ codebook used by a strong autoregressive baseline; if SDFlow Context-FID is not lower while inference latency is also not reduced, the central claim fails.
Figures









read the original abstract
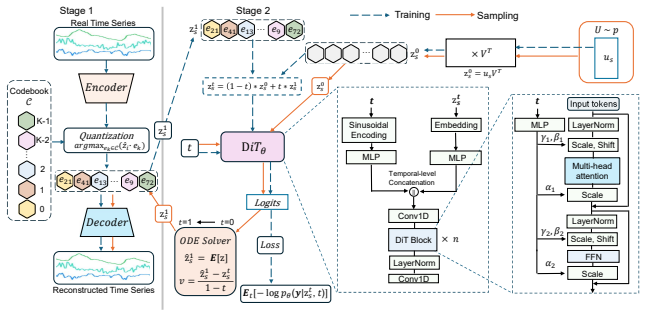
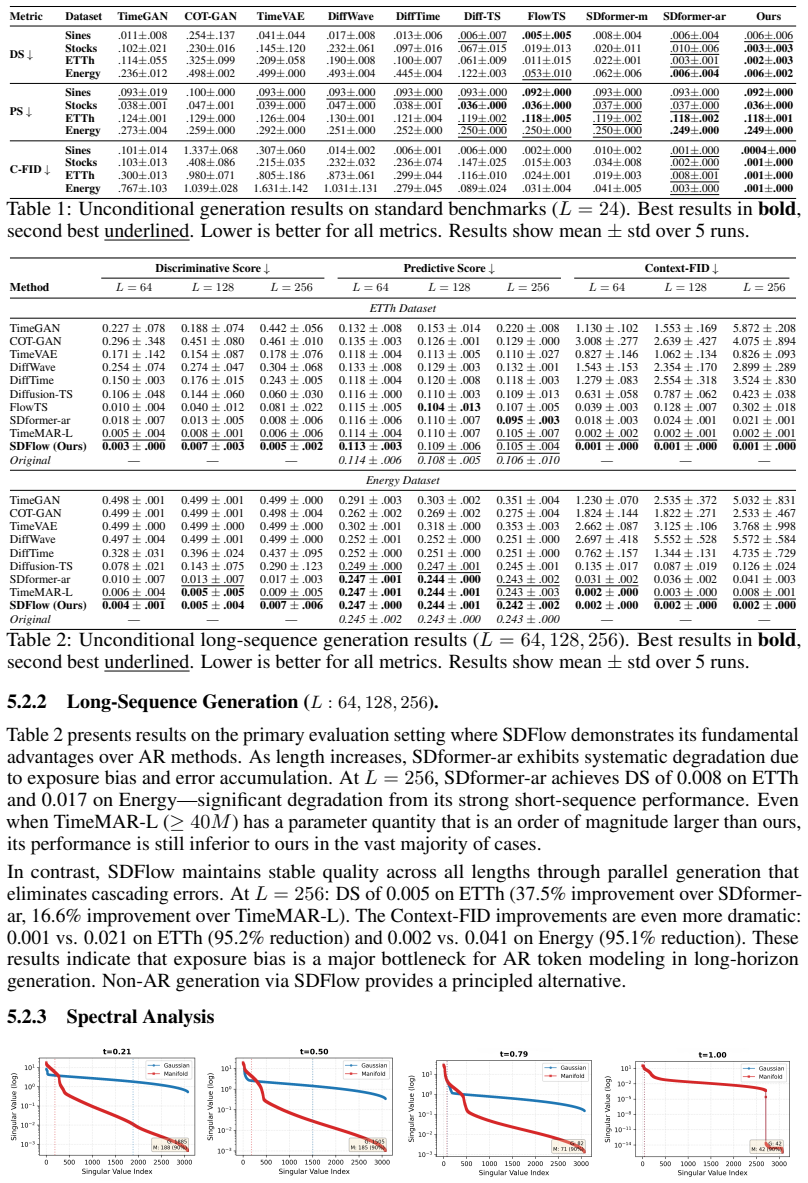
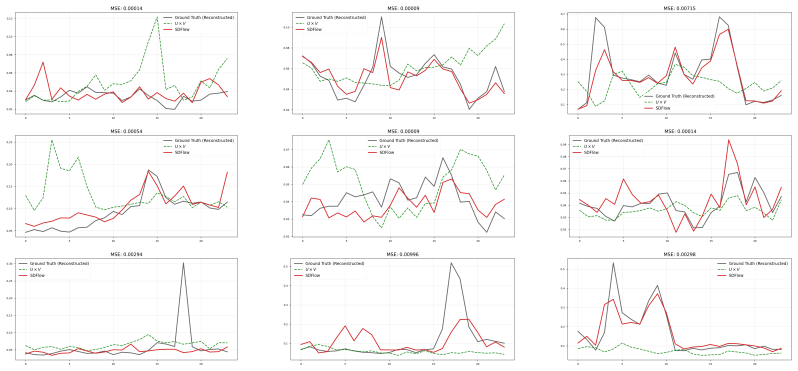
Vector quantization (VQ) with autoregressive (AR) token modeling is a widely adopted and highly competitive paradigm for time-series generation. However, such models are fundamentally limited by exposure bias: during inference, errors can accumulate across sequential predictions, leading to pronounced quality degradation in long-horizon generation. To address this, we propose SDFlow ($\textbf{S}$imilarity-$\textbf{D}$riven $\textbf{Flow}$ Matching), a non-autoregressive framework that operates entirely in the frozen VQ latent space and enables parallel sequence generation via flow matching. We tackle three key challenges in making this transition: (1) eliminating exposure bias by replacing step-wise token prediction with a global transport map; (2) mitigating the high-dimensionality of VQ token spaces via a low-rank manifold decomposition with a learned anchor prior over the latent manifold; and (3) incorporating discrete supervision into continuous transport dynamics by introducing a categorical posterior over codebook indices within a variational flow-matching formulation. Extensive experiments show that SDFlow achieves state-of-the-art performance, improving Discriminative Score and substantially reducing Context-FID, particularly for challenging long-sequence generation. Moreover, SDFlow provides significant inference speedups over autoregressive baselines, offering both high fidelity and computational efficiency. Code is available at https://anonymous.4open.science/r/SDFlow-D6F3/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SDFlow, a non-autoregressive framework for time series generation operating entirely in a frozen VQ latent space. It replaces autoregressive token prediction with global flow-matching transport to eliminate exposure bias, introduces low-rank manifold decomposition with a learned anchor prior to address high dimensionality, and incorporates a categorical posterior over codebook indices inside a variational flow-matching objective to handle discrete supervision. Experiments claim state-of-the-art Discriminative Score and reduced Context-FID (especially on long sequences) plus inference speedups over AR baselines.
Significance. If the low-rank projection and categorical posterior successfully preserve VQ codebook fidelity under continuous transport, the work would advance efficient long-horizon time series generation by combining flow matching's parallel sampling with VQ's discrete structure, addressing a core limitation of AR-VQ models while providing reproducible code.
major comments (3)
- [Section 3.2] Section 3.2 (low-rank manifold decomposition): the learned anchor prior is presented as mitigating high-dimensional VQ spaces, yet no bound or geometric analysis is given showing that the projection preserves the original codebook manifold geometry; any distortion would directly undermine the frozen-VQ fidelity claim that supports the long-sequence results.
- [Section 3.3] Section 3.3 (variational flow-matching formulation): the categorical posterior is introduced to embed discrete codebook supervision into continuous dynamics, but the derivation does not demonstrate that probability mass remains confined to valid codebook indices (rather than allowing drift to non-codebook points); this is load-bearing for the central claim that the method maintains modeling fidelity while eliminating exposure bias.
- [Experiments] Experiments section (long-sequence results): the SOTA claims on Context-FID and Discriminative Score rest on the above components working as intended; without ablations isolating the low-rank decomposition and categorical posterior, it is difficult to attribute gains specifically to the proposed mechanisms rather than the base flow-matching setup.
minor comments (2)
- [Abstract] Abstract: the term 'similarity-driven' is used in the title but not explicitly defined relative to the anchor prior; a one-sentence clarification would improve readability.
- [Notation] Notation: ensure the low-rank dimension and anchor prior parameters are consistently symbolized across the method equations and experimental tables.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (low-rank manifold decomposition): the learned anchor prior is presented as mitigating high-dimensional VQ spaces, yet no bound or geometric analysis is given showing that the projection preserves the original codebook manifold geometry; any distortion would directly undermine the frozen-VQ fidelity claim that supports the long-sequence results.
Authors: We agree that a formal geometric bound would provide stronger theoretical support. The current manuscript relies on the similarity-driven objective and empirical reconstruction fidelity to argue preservation. In the revision, we will add a geometric analysis subsection to Section 3.2 (with supporting derivations in the appendix) showing that the low-rank projection with the learned anchor prior is approximately distance-preserving on the codebook manifold under the flow-matching transport. We will also report additional metrics quantifying any distortion. revision: yes
-
Referee: [Section 3.3] Section 3.3 (variational flow-matching formulation): the categorical posterior is introduced to embed discrete codebook supervision into continuous dynamics, but the derivation does not demonstrate that probability mass remains confined to valid codebook indices (rather than allowing drift to non-codebook points); this is load-bearing for the central claim that the method maintains modeling fidelity while eliminating exposure bias.
Authors: The categorical posterior is defined exclusively over the finite codebook indices, and the variational objective is constructed so that the continuous flow is conditioned on these discrete variables. To make this explicit, we will expand the derivation in Section 3.3 and add a short proof in the appendix demonstrating that the support remains on valid indices by construction (no probability mass can leak outside the codebook). We will also include empirical measurements of invalid index rates during sampling, which are negligible in our experiments. revision: yes
-
Referee: [Experiments] Experiments section (long-sequence results): the SOTA claims on Context-FID and Discriminative Score rest on the above components working as intended; without ablations isolating the low-rank decomposition and categorical posterior, it is difficult to attribute gains specifically to the proposed mechanisms rather than the base flow-matching setup.
Authors: We acknowledge that clearer isolation of each component would improve attribution. The manuscript already contains ablations on the overall framework and the anchor prior, but these are not fully separated. In the revision we will add targeted experiments that ablate the low-rank decomposition and the categorical posterior independently against a plain flow-matching baseline in VQ space, reporting the incremental gains on Context-FID and Discriminative Score for long horizons. These new results will be placed in the main experiments section. revision: yes
Circularity Check
No circularity in SDFlow derivation chain
full rationale
The paper presents SDFlow as an explicit architectural proposal: a non-autoregressive flow-matching model operating inside a frozen VQ latent space, augmented by a low-rank manifold decomposition with learned anchor prior and a categorical posterior inside a variational flow-matching objective. These elements are introduced as new components to address exposure bias and high dimensionality; none are obtained by fitting a parameter to data and then relabeling the fit as a prediction, nor do they reduce to self-definitional equations or load-bearing self-citations. The central claims rest on empirical results (Discriminative Score, Context-FID, inference speed) rather than any first-principles derivation that collapses to the inputs by construction. The method therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- anchor prior parameters
- low-rank dimension
axioms (2)
- domain assumption The frozen VQ latent space contains sufficient information to support high-fidelity generation via continuous transport
- domain assumption A variational categorical posterior can inject discrete codebook supervision into continuous flow-matching dynamics without distorting the learned transport map
invented entities (3)
-
low-rank manifold decomposition
no independent evidence
-
learned anchor prior
no independent evidence
-
categorical posterior over codebook indices
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Building Normalizing Flows with Stochastic Interpolants
Michael S Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. arXiv preprint arXiv:2209.15571, 2022
work page internal anchor Pith review arXiv 2022
-
[2]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.arXiv preprint arXiv:2303.08797, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Juan Miguel Lopez Alcaraz and Nils Strodthoff. Diffusion-based time series imputation and forecasting with structured state space models.arXiv preprint arXiv:2208.09399, 2022
-
[4]
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks.Advances in neural information processing systems, 28, 2015
work page 2015
-
[5]
Maskgit: Masked generative image transformer
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11315–11325, 2022
work page 2022
-
[6]
Flow matching on general geometries.arXiv preprint arXiv:2302.03660, 2023
Ricky TQ Chen and Yaron Lipman. Flow matching on general geometries.arXiv preprint arXiv:2302.03660, 2023
-
[7]
Zhicheng Chen, FENG SHIBO, Zhong Zhang, Xi Xiao, Xingyu Gao, and Peilin Zhao. Sdformer: Similarity- driven discrete transformer for time series generation.Advances in Neural Information Processing Systems, 37:132179–132207, 2024
work page 2024
-
[8]
Andrea Coletta, Sriram Gopalakrishnan, Daniel Borrajo, and Svitlana Vyetrenko. On the constrained time-series generation problem.Advances in Neural Information Processing Systems, 36:61048–61059, 2023
work page 2023
-
[9]
Abhyuday Desai, Cynthia Freeman, Zuhui Wang, and Ian Beaver. Timevae: A variational auto-encoder for multivariate time series generation (2021).arXiv preprint arXiv:2111.08095, 2021
-
[10]
Hierarchical multi-scale gaussian transformer for stock movement prediction
Qianggang Ding, Sifan Wu, Hao Sun, Jiadong Guo, and Jian Guo. Hierarchical multi-scale gaussian transformer for stock movement prediction. InIjcai, pages 4640–4646, 2020
work page 2020
-
[11]
Floor Eijkelboom, Grigory Bartosh, Christian Andersson Naesseth, Max Welling, and Jan-Willem van de Meent. Variational flow matching for graph generation.Advances in Neural Information Processing Systems, 37:11735–11764, 2024
work page 2024
-
[12]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021
work page 2021
-
[13]
Latent diffusion transformer for probabilistic time series forecasting
Shibo Feng, Chunyan Miao, Zhong Zhang, and Peilin Zhao. Latent diffusion transformer for probabilistic time series forecasting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 11979–11987, 2024
work page 2024
-
[14]
Flowts: Time series generation via rectified flow.arXiv preprint arXiv:2411.07506, 2024
Yang Hu, Xiao Wang, Zezhen Ding, Lirong Wu, Huatian Zhang, Stan Z Li, Sheng Wang, Jiheng Zhang, Ziyun Li, and Tianlong Chen. Flowts: Time series generation via rectified flow.arXiv preprint arXiv:2411.07506, 2024
-
[15]
Diffwave: A versatile diffusion model for audio synthesis.arXiv preprint arXiv:2009.09761, 2020
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis.arXiv preprint arXiv:2009.09761, 2020
-
[16]
Bryan Lim and Stefan Zohren. Time-series forecasting with deep learning: a survey.Philosophical transactions of the royal society a: mathematical, physical and engineering sciences, 379(2194), 2021
work page 2021
-
[17]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
R˘azvan-Andrei Mati¸ san, Vincent Tao Hu, Grigory Bartosh, Björn Ommer, Cees G. M. Snoek, Max Welling, Jan-Willem van de Meent, Mohammad Mahdi Derakhshani, and Floor Eijkelboom. Purrception: Categorical flow matching for vq-vae latent spaces.arXiv preprint arXiv:2510.01478, 2025
-
[20]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[21]
Robert B Penfold and Fang Zhang. Use of interrupted time series analysis in evaluating health care quality improvements.Academic pediatrics, 13(6):S38–S44, 2013
work page 2013
-
[22]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InInternational conference on machine learning, pages 8821–8831. Pmlr, 2021
work page 2021
-
[23]
Generalization in generation: A closer look at exposure bias.arXiv preprint arXiv:1910.00292, 2019
Florian Schmidt. Generalization in generation: A closer look at exposure bias.arXiv preprint arXiv:1910.00292, 2019
-
[24]
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. Csdi: Conditional score-based diffusion models for probabilistic time series imputation.Advances in neural information processing systems, 34: 24804–24816, 2021
work page 2021
-
[25]
Improving and generalizing flow-based generative models with minibatch optimal transport
Alexander Tong, Kilian Fatras, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector-Brooks, Guy Wolf, and Yoshua Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport.arXiv preprint arXiv:2302.00482, 2023
work page internal anchor Pith review arXiv 2023
-
[26]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
work page 2017
-
[27]
Tianlin Xu, Li Kevin Wenliang, Michael Munn, and Beatrice Acciaio. Cot-gan: Generating sequential data via causal optimal transport.Advances in neural information processing systems, 33:8798–8809, 2020
work page 2020
-
[28]
Timemar: Multi-scale autoregressive modeling for uncon- ditional time series generation
Xiangyu Xu, Qingsong Zhong, and Jilin Hu. Timemar: Multi-scale autoregressive modeling for uncon- ditional time series generation. InProceedings of the ACM Web Conference 2026, pages 5132–5143, 2026
work page 2026
-
[29]
Time-series generative adversarial networks
Jinsung Yoon, Daniel Jarrett, and Mihaela Van der Schaar. Time-series generative adversarial networks. Advances in neural information processing systems, 32, 2019
work page 2019
-
[30]
Xinyu Yuan and Yan Qiao. Diffusion-ts: Interpretable diffusion for general time series generation.arXiv preprint arXiv:2403.01742, 2024
-
[31]
arXiv preprint arXiv:2301.06052 (2023) 2, 3, 10, 12, 18
J Zhang, Y Zhang, X Cun, S Huang, Y Zhang, H Zhao, H Lu, and X Shen. T2m-gpt: Generating human motion from textual descriptions with discrete representations.arXiv preprint arXiv:2301.06052, 2023. 11 Appendices for SDFlow A Proof of Theorem 4.1 We prove the two claims in Theorem 4.1. Part (i): Gaussian Initialization Letz∼ Dandz 0 ∼ N(0,I D)be independent...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.