Recognition: unknown
CoMemNet: Contrastive Sampling with Memory Replay Network for Continual Traffic Prediction
Pith reviewed 2026-05-08 14:48 UTC · model grok-4.3
The pith
A dual-branch network with Wasserstein contrastive sampling and node-adaptive memory replay learns from streaming traffic data without forgetting earlier patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
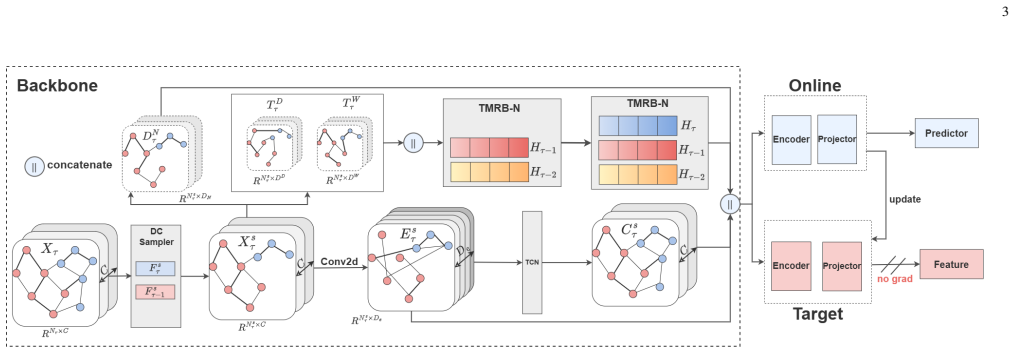
CoMemNet is a dual-branch continual learning framework in which the fast-converging Online branch performs primary prediction tasks while the momentum-updated Target branch extracts historical information through Wasserstein Distance features to build a Dynamic Contrastive Sampler; the sampler selects nodes showing significant dynamic network feature changes, thereby mitigating catastrophic forgetting, and the backbone adds a lightweight Node-Adaptive Temporal Memory Buffer that consolidates old knowledge via memory replay without causing memory explosion.
What carries the argument
The dual-branch continual learning setup in which the Target branch's Wasserstein Distance features power the Dynamic Contrastive Sampler for node selection, paired with the Node-Adaptive Temporal Memory Buffer for knowledge consolidation during streaming training.
If this is right
- Traffic prediction systems can maintain accuracy on expanding networks while processing new data in a streaming fashion.
- Contrastive sampling focused on large feature changes reduces the volume of historical data needed for training.
- Node-specific memory replay avoids both forgetting and unbounded memory growth as the network evolves.
- The framework reaches state-of-the-art performance on three large-scale real-world traffic datasets.
- Two new curated datasets become available for benchmarking continual learning methods in traffic forecasting.
Where Pith is reading between the lines
- The Wasserstein-based selection of changing nodes could be tested on other streaming graph tasks such as sensor networks or social interaction data.
- If the momentum branch reliably tracks long-term shifts, the method might lower the need for periodic full retraining in deployed forecasting systems.
- Evaluating the approach on networks that change at different speeds would show the range of conditions under which the sampler and buffer remain effective.
Load-bearing premise
That selecting nodes via Wasserstein distance on the momentum branch and replaying from the node-adaptive buffer together prevent catastrophic forgetting in real streaming traffic data without unacceptable overhead or bias.
What would settle it
After sequential training on successive segments of streaming traffic data, measure whether accuracy on held-out earlier segments drops substantially compared with a full-retraining baseline or with the reported state-of-the-art scores on the three datasets.
Figures




read the original abstract
In recent years, the integration of non-topological space modeling with temporal learning methods has emerged as an effective approach for capturing spatio-temporal information in non-Euclidean graphs. However, most existing methods rely on static underlying graph structures, which are inadequate for capturing the continuously expanding and evolving patterns in streaming traffic networks. To address this challenge, we propose a simple yet efficient dual-branch continual learning framework for traffic prediction, named CoMemNet. The fast-converging Online branch undertakes the primary prediction tasks, while the momentum-updated Target branch extracts historical information using Wasserstein Distance features to create a Dynamic Contrastive Sampler (DC Sampler). This sampler selects a node set with significant dynamic network feature changes for training, effectively mitigating the issue of catastrophic forgetting. Additionally, the backbone incorporates a lightweight Node-Adaptive Temporal Memory Buffer (TMRB-N) to consolidate old knowledge through memory replay and address the risk of memory explosion. Finally, we provide two newly curated open-source datasets. Experimental results demonstrate that CoMemNet achieves state-of-the-art (SOTA) performance across all three large-scale real-world datasets. The code is available at: https://github.com/meiwu5/CoMemNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoMemNet, a dual-branch continual learning framework for traffic prediction on evolving non-Euclidean graphs. An online branch handles primary prediction tasks while a momentum-updated target branch extracts historical features via Wasserstein distance to drive a Dynamic Contrastive Sampler (DC Sampler) that selects nodes with significant dynamic changes, thereby mitigating catastrophic forgetting. A lightweight Node-Adaptive Temporal Memory Buffer (TMRB-N) performs memory replay to consolidate old knowledge without memory explosion. Two new open-source datasets are introduced, and the method is reported to achieve SOTA performance on three large-scale real-world streaming traffic datasets.
Significance. If the experimental results properly isolate the contribution of the DC Sampler and TMRB-N via standard continual-learning diagnostics and demonstrate reduced forgetting without unacceptable overhead, the work would be significant for spatio-temporal graph models operating on streaming data. The release of code and two new datasets is a clear strength that supports reproducibility and future benchmarking.
major comments (2)
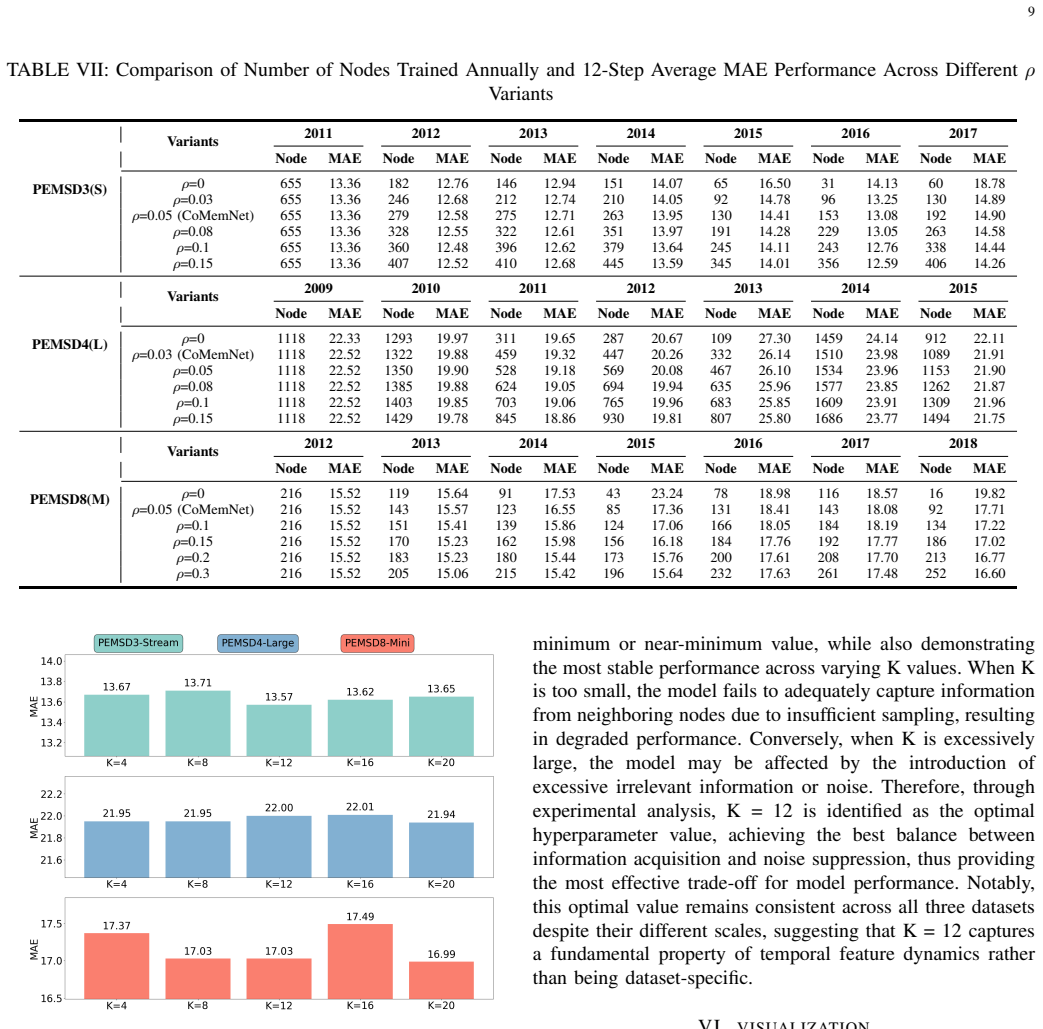
- [§4] §4 Experiments (and associated tables): the SOTA claim is asserted without reporting standard continual-learning metrics such as backward transfer, forgetting rate, or task-wise accuracy curves that would isolate the effect of the Wasserstein-selected DC Sampler and TMRB-N from simple increases in model capacity or regularization. This directly undermines the central claim that the proposed modules prevent catastrophic forgetting in real streaming traffic data.
- [§4.3] §4.3 Ablation studies: no quantitative ablation is shown that removes the momentum branch or the TMRB-N while keeping total parameters fixed, leaving open the possibility that performance gains arise from architecture size rather than the contrastive sampling or replay mechanism.
minor comments (2)
- [Abstract] The abstract and introduction use the term 'parameter-free' for the DC Sampler; clarify whether the Wasserstein distance computation or momentum coefficient introduces any tunable hyperparameters.
- [Figure 3] Figure 3 (architecture diagram) would benefit from explicit annotation of the Wasserstein distance computation path between the online and target branches.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and have revised the paper to incorporate additional metrics and ablations as suggested.
read point-by-point responses
-
Referee: [§4] §4 Experiments (and associated tables): the SOTA claim is asserted without reporting standard continual-learning metrics such as backward transfer, forgetting rate, or task-wise accuracy curves that would isolate the effect of the Wasserstein-selected DC Sampler and TMRB-N from simple increases in model capacity or regularization. This directly undermines the central claim that the proposed modules prevent catastrophic forgetting in real streaming traffic data.
Authors: We agree that standard continual-learning metrics provide a more direct way to quantify forgetting and isolate module contributions. Our original experiments emphasized end-to-end accuracy on streaming traffic datasets and SOTA comparisons, which implicitly reflect sustained performance over time. To strengthen the evidence, the revised manuscript now includes backward transfer, forgetting rate, and task-wise accuracy curves in Section 4. These additions show that CoMemNet reduces forgetting relative to baselines, supporting the specific role of the DC Sampler and TMRB-N. revision: yes
-
Referee: [§4.3] §4.3 Ablation studies: no quantitative ablation is shown that removes the momentum branch or the TMRB-N while keeping total parameters fixed, leaving open the possibility that performance gains arise from architecture size rather than the contrastive sampling or replay mechanism.
Authors: We acknowledge the value of controlling for parameter count in ablations. In the revised Section 4.3 we add experiments that remove the momentum branch or TMRB-N while matching total parameter budgets by increasing capacity in the remaining components (e.g., larger hidden dimensions). The results continue to show gains attributable to contrastive sampling and replay. We also report explicit parameter counts in all tables for clarity. revision: yes
Circularity Check
No circularity: standard continual-learning components with experimental SOTA claim
full rationale
The paper describes a dual-branch architecture (online + momentum target) that uses Wasserstein distance for node selection and a lightweight memory buffer for replay. These are presented as combinations of established techniques (momentum updates, Wasserstein metric, memory replay) without any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. The central claim is empirical performance on three datasets; no derivation reduces to its own inputs by construction. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep learning on traffic prediction: Methods, analysis, and future directions,
X. Yin, G. Wu, J. Wei, Y . Shen, H. Qi, and B. Yin, “Deep learning on traffic prediction: Methods, analysis, and future directions,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 6, pp. 4927–4943, 2022
2022
-
[2]
Spatial-temporal identity: A simple yet effective baseline for multivariate time series fore- casting,
Z. Shao, Z. Zhang, F. Wang, W. Wei, and Y . Xu, “Spatial-temporal identity: A simple yet effective baseline for multivariate time series fore- casting,” inProceedings of the 31st ACM International Conference on Information and Knowledge Management, ser. CIKM ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 4454–4458
2022
-
[3]
Spatio-temporal self-supervised learning for traffic flow prediction,
J. Ji, J. Wang, C. Huang, J. Wu, B. Xu, Z. Wu, J. Zhang, and Y . Zheng, “Spatio-temporal self-supervised learning for traffic flow prediction,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 4, pp. 4356–4364, Jun. 2023
2023
-
[4]
Graph wavenet for deep spatial-temporal graph modeling,
Z. Wu, S. Pan, G. Long, J. Jiang, and C. Zhang, “Graph wavenet for deep spatial-temporal graph modeling,” inProceedings of the 28th International Joint Conference on Artificial Intelligence, ser. IJCAI’19. AAAI Press, 2019, pp. 1907–1913
2019
-
[5]
Diffusion convolutional recurrent neural network: Data-driven traffic forecasting,
Y . Li, R. Yu, C. Shahabi, and Y . Liu, “Diffusion convolutional recurrent neural network: Data-driven traffic forecasting,” inInternational Con- ference on Learning Representations, 2018
2018
-
[6]
Attention based spatial- temporal graph convolutional networks for traffic flow forecasting,
S. Guo, Y . Lin, N. Feng, C. Song, and H. Wan, “Attention based spatial- temporal graph convolutional networks for traffic flow forecasting,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, pp. 922–929, Jul. 2019
2019
-
[7]
Dsanet: Dual self-attention network for multivariate time series forecasting,
S. Huang, D. Wang, X. Wu, and A. Tang, “Dsanet: Dual self-attention network for multivariate time series forecasting,” inProceedings of the 28th ACM International Conference on Information and Knowledge Management, ser. CIKM ’19. New York, NY , USA: Association for Computing Machinery, 2019, pp. 2129–2132
2019
-
[8]
Expand and compress: Exploring tuning princi- ples for continual spatio-temporal graph forecasting,
W. Chen and Y . Liang, “Expand and compress: Exploring tuning princi- ples for continual spatio-temporal graph forecasting,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[9]
Trafficstream: A streaming traffic flow forecasting framework based on graph neural networks and continual learning,
X. Chen, J. Wang, and K. Xie, “Trafficstream: A streaming traffic flow forecasting framework based on graph neural networks and continual learning,” inProceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Z.-H. Zhou, Ed. International Joint 11 Conferences on Artificial Intelligence Organization, 8 2021, pp. 3620...
2021
-
[10]
Spatial- temporal cellular traffic prediction for 5g and beyond: A graph neural networks-based approach,
Z. Wang, J. Hu, G. Min, Z. Zhao, Z. Chang, and Z. Wang, “Spatial- temporal cellular traffic prediction for 5g and beyond: A graph neural networks-based approach,”IEEE Transactions on Industrial Informatics, vol. 19, no. 4, pp. 5722–5731, 2023
2023
-
[11]
Deep learning for traffic prediction in intelligent transportation systems: A survey,
J. Ye, J. Zhao, K. Ye, and C. Xu, “Deep learning for traffic prediction in intelligent transportation systems: A survey,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 9, pp. 11 868–11 880, 2022
2022
-
[12]
A unified spatio-temporal model for short-term traffic flow prediction,
J. Zhang, Y . Zheng, and D. Qi, “A unified spatio-temporal model for short-term traffic flow prediction,”IEEE Transactions on Intelligent Transportation Systems, vol. 20, no. 10, pp. 3212–3223, 2019
2019
-
[13]
Spatiotemporal recurrent convolutional networks for traffic prediction in transportation networks,
B. Yu, H. Yin, and Z. Zhu, “Spatiotemporal recurrent convolutional networks for traffic prediction in transportation networks,”Sensors, vol. 17, no. 7, p. 1501, 2017
2017
-
[14]
Pattern expansion and consolidation on evolving graphs for continual traffic prediction,
B. Wang, Y . Zhang, X. Wang, P. Wang, Z. Zhou, L. Bai, and Y . Wang, “Pattern expansion and consolidation on evolving graphs for continual traffic prediction,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, ser. KDD ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 2223–2232
2023
-
[15]
Knowledge expansion and consolidation for continual traffic prediction with expanding graphs,
B. Wang, Y . Zhang, J. Shi, P. Wang, X. Wang, L. Bai, and Y . Wang, “Knowledge expansion and consolidation for continual traffic prediction with expanding graphs,”IEEE Transactions on Intelligent Transporta- tion Systems, vol. 24, no. 7, pp. 7190–7201, 2023
2023
-
[16]
Spectrum-aided traffic decomposition and deep learning method for network traffic prediction in internet of things,
J. Gao, Y . He, D. Han, Y . Lu, and Y . Qiao, “Spectrum-aided traffic decomposition and deep learning method for network traffic prediction in internet of things,”IEEE Transactions on Industrial Informatics, pp. 1–11, 2025
2025
-
[17]
Overcoming catastrophic forgetting in graph neural networks with experience replay,
F. Zhou and C. Cao, “Overcoming catastrophic forgetting in graph neural networks with experience replay,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 5, pp. 4714–4722, May 2021
2021
-
[18]
Streaming graph neural networks,
Y . Ma, Z. Guo, Z. Ren, J. Tang, and D. Yin, “Streaming graph neural networks,” inProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, ser. SIGIR ’20. New York, NY , USA: Association for Computing Machinery, 2020, p. 719–728
2020
-
[19]
Topology-aware embedding memory for continual learning on expanding networks,
X. Zhang, D. Song, Y . Chen, and D. Tao, “Topology-aware embedding memory for continual learning on expanding networks,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, ser. KDD ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 4326–4337
2024
-
[20]
Pattern- matching dynamic memory network for dual-mode traffic prediction,
W. Weng, M. Wu, H. Jiang, W. Kong, X. Kong, and F. Xia, “Pattern- matching dynamic memory network for dual-mode traffic prediction,” IEEE Transactions on Intelligent Transportation Systems, pp. 1–15, 2025
2025
-
[21]
Tshdnet: Temporal-spatial het- erogeneity decoupling network for multi-mode traffic flow prediction,
M. Wu, W. Weng, X. Wanget al., “Tshdnet: Temporal-spatial het- erogeneity decoupling network for multi-mode traffic flow prediction,” Applied Intelligence, vol. 55, no. 320, p. 320, 2025
2025
-
[22]
Decoupled dynamic spatial-temporal graph neural network for traffic forecasting,
Z. Shao, Z. Zhang, W. Wei, F. Wang, Y . Xu, X. Cao, and C. S. Jensen, “Decoupled dynamic spatial-temporal graph neural network for traffic forecasting,”Proc. VLDB Endow., vol. 15, no. 11, p. 2733–2746, Jul. 2022
2022
-
[23]
Spatial- temporal-decoupled masked pre-training for spatiotemporal forecasting,
H. Gao, R. Jiang, Z. Dong, J. Deng, Y . Ma, and X. Song, “Spatial- temporal-decoupled masked pre-training for spatiotemporal forecasting,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, ser. IJCAI ’24, 2024
2024
-
[24]
Stwave ++: A multi- scale efficient spectral graph attention network with long-term trends for disentangled traffic flow forecasting,
Y . Fang, Y . Qin, H. Luo, F. Zhao, and K. Zheng, “Stwave ++: A multi- scale efficient spectral graph attention network with long-term trends for disentangled traffic flow forecasting,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 6, pp. 2671–2685, 2024
2024
-
[25]
Pdformer: propagation delay-aware dynamic long-range transformer for traffic flow prediction,
J. Jiang, C. Han, W. X. Zhao, and J. Wang, “Pdformer: propagation delay-aware dynamic long-range transformer for traffic flow prediction,” inProceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artif...
2023
-
[26]
Promptcast: A new prompt-based learning paradigm for time series forecasting,
H. Xue and F. D. Salim, “Promptcast: A new prompt-based learning paradigm for time series forecasting,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 11, pp. 6851–6864, 2024
2024
-
[27]
St-llm: Large language models are effective temporal learners,
R. Liu, C. Li, H. Tang, Y . Ge, Y . Shan, and G. Li, “St-llm: Large language models are effective temporal learners,” inComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part LVII. Berlin, Heidelberg: Springer-Verlag, 2024, p. 1–18
2024
-
[28]
Gatgpt: A pre-trained large language model with graph attention network for spatiotemporal imputation,
Y . Chen, X. Wang, and G. Xu, “Gatgpt: A pre-trained large language model with graph attention network for spatiotemporal imputation,” 2023
2023
-
[29]
Spatial-temporal identity: A simple yet effective baseline for multivariate time series forecasting,
Z. Shao, Z. Zhang, F. Wang, W. Wei, and Y . Xu, “Spatial-temporal identity: A simple yet effective baseline for multivariate time series forecasting,” inProceedings of the 31st ACM International Conference on Information & Knowledge Management, ser. CIKM ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 4454–4458
2022
-
[30]
A comprehensive survey of continual learning: Theory, method and application,
L. Wang, X. Zhang, H. Su, and J. Zhu, “A comprehensive survey of continual learning: Theory, method and application,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 8, pp. 5362– 5383, 2024
2024
-
[31]
Continual learning for robotics: Definition, framework, learning strategies, opportunities and challenges,
T. Lesort, V . Lomonaco, A. Stoian, D. Maltoni, D. Filliat, and N. D ´ıaz- Rodr´ıguez, “Continual learning for robotics: Definition, framework, learning strategies, opportunities and challenges,”Information Fusion, vol. 58, pp. 52–68, 2020
2020
-
[32]
Task-free continual learning,
R. Aljundi, K. Kelchtermans, and T. Tuytelaars, “Task-free continual learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
2019
-
[33]
Continual learning through synaptic intelligence,
F. Zenke, B. Poole, and S. Ganguli, “Continual learning through synaptic intelligence,” inProceedings of the 34th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, D. Precup and Y . W. Teh, Eds., vol. 70. PMLR, 06–11 Aug 2017, pp. 3987–3995
2017
-
[34]
A continual learning survey: Defying forgetting in classification tasks,
M. De Lange, R. Aljundi, M. Masana, S. Parisot, X. Jia, A. Leonardis, G. Slabaugh, and T. Tuytelaars, “A continual learning survey: Defying forgetting in classification tasks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 7, pp. 3366–3385, 2022
2022
-
[35]
Continual learning through synaptic intelligence,
F. Zenke, B. Poole, and S. Ganguli, “Continual learning through synaptic intelligence,” inInternational Conference on Machine Learning (ICML). PMLR, 2017, pp. 3987–3995
2017
-
[36]
Memory aware synapses: Learning what (not) to forget,
R. Aljundi, F. Babiloni, M. Elhoseiny, M. Rohrbach, and T. Tuytelaars, “Memory aware synapses: Learning what (not) to forget,” inEuropean Conference on Computer Vision (ECCV). Springer, 2018, pp. 139–154
2018
-
[37]
Progress & compress: A scalable framework for continual learning,
J. Schwarz, W. Czarnecki, J. Luketina, A. Grabska-Barwinska, Y . W. Teh, R. Pascanu, and R. Hadsell, “Progress & compress: A scalable framework for continual learning,” inProceedings of the 35th Interna- tional Conference on Machine Learning, ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 4528–4537
2018
-
[38]
Packnet: Adding multiple tasks to a single network by iterative pruning,
A. Mallya and S. Lazebnik, “Packnet: Adding multiple tasks to a single network by iterative pruning,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 7765– 7773
2018
-
[39]
Compacting, picking and growing for unforgetting contin- ual learning,
C.-Y . Hung, C.-H. Tu, C.-E. Wu, C.-H. Chen, Y .-M. Chan, and C.- S. Chen, “Compacting, picking and growing for unforgetting contin- ual learning,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019
2019
-
[40]
Expe- rience replay for continual learning,
D. Rolnick, A. Ahuja, J. Schwarz, T. Lillicrap, and G. Wayne, “Expe- rience replay for continual learning,” inAdvances in Neural Informa- tion Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch ´e-Buc, E. Fox, and R. Garnett, Eds., vol. 32. Curran Associates, Inc., 2019
2019
-
[41]
On Tiny Episodic Memories in Continual Learning
A. Chaudhry, M. Rohrbach, M. Elhoseiny, T. Ajanthan, P. K. Dokania, P. H. Torr, and M. Ranzato, “Continual learning with tiny episodic memories,”arXiv preprint arXiv:1902.10486, 2019
work page Pith review arXiv 1902
-
[42]
icarl: Incremental classifier and representation learning,
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “icarl: Incremental classifier and representation learning,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 2001–2010
2017
-
[43]
Continual learning with deep generative replay,
H. Shin, J. K. Lee, J. Kim, and J. Kim, “Continual learning with deep generative replay,”Advances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017
2017
-
[44]
Spatio-temporal knowledge expansion and consolidation framework for continual traffic prediction,
B. Liu, Y . Wang, X. Li, P. Wang, Z. Wang, J. Guo, and Y . Yang, “Spatio-temporal knowledge expansion and consolidation framework for continual traffic prediction,”Information Fusion, vol. 102, p. 102038, 2024. 12 Mei Wureceived her Bachelor’s degree from Shandong University, China in 2022. She obtained her Master’s degree from Hangzhou Dianzi Univer- sit...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.