Recognition: unknown
Weak-to-Strong Generalization is Nearly Inevitable (in Linear Models)
Pith reviewed 2026-05-08 14:46 UTC · model grok-4.3
The pith
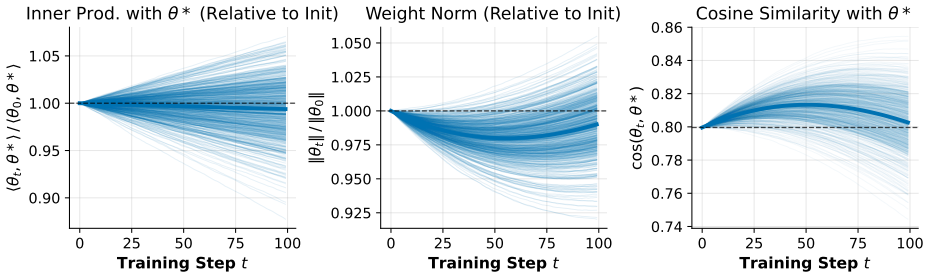
Weak-to-strong generalization occurs in linear logistic regression for most student-teacher pairs without any capacity mismatch between them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In linear logistic regression a student model finetuned using only labels or soft predictions from a weaker teacher model surpasses the teacher and also exceeds its own performance without that feedback; the improvement occurs for most random choices of student and teacher parameters whenever the data distribution satisfies mild conditions, and the student need not be more expressive or larger than the teacher.
What carries the argument
Linear logistic regression trained on teacher feedback under mild distributional assumptions on the data that make the performance gain hold for most student-teacher parameter pairs.
If this is right
- Capacity mismatch between student and teacher is not required for weak-to-strong generalization.
- The phenomenon appears in the simplest supervised linear setting and can therefore be analyzed with standard tools.
- The effect is expected to appear in many other linear predictor families under analogous mild conditions.
- Explanations of weak-to-strong generalization must now account for its occurrence even when student and teacher have identical capacity.
Where Pith is reading between the lines
- The same near-inevitability may hold in other linear models such as ordinary least squares or linear SVMs.
- Small-scale experiments on synthetic data could isolate exactly which distributional properties trigger the gain.
- If the effect is tied to the convexity of the logistic loss, then analogous behavior might appear in other convex linear problems.
- Training procedures could deliberately exploit the effect to boost performance of low-capacity models on real data.
Load-bearing premise
The input data must satisfy mild distributional assumptions that cause the improvement to appear for most random student and teacher parameter choices.
What would settle it
Finding a data distribution for which most student-teacher pairs in linear logistic regression fail to produce a student that outperforms the teacher after finetuning on the teacher's feedback would disprove the near-inevitability claim.
Figures


read the original abstract
Weak-to-strong generalization is a phenomenon in post-training whereby a strong student model, when finetuned solely with feedback from a weaker teacher, can not only surpass the teacher, but can improve upon its own capabilities. Recent work of Burns et al. (2023) demonstrated that this can occur in the setting of frontier language models, and subsequently there has been a flurry of both empirical work trying to exploit this phenomenon, as well as theoretical work attempting to understand it. In this work, we demonstrate that weak-to-strong generalization occurs in standard linear logistic regression, under mild distributional assumptions on the data. In fact, we show that this happens for most student-teacher pairs, suggesting that weak-to-strong generalization is in fact \emph{almost inevitable}, even in this basic setting. Notably, our setting does not require the student to be more expressive or have more model capacity in any way compared to the teacher, which runs contrary to the prevailing theoretical belief that a mismatch in model capacity is a central mechanism to weak-to-strong generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that weak-to-strong generalization occurs in standard linear logistic regression under mild distributional assumptions on the data. Specifically, a student model obtained as the empirical risk minimizer on finite samples whose labels are generated by a weaker teacher surpasses the teacher for most student-teacher pairs, even without any capacity or expressivity advantage for the student. This is presented as evidence that the phenomenon is nearly inevitable in this basic setting.
Significance. If the central claim is rigorously established, the result would be significant: it supplies an explicit, capacity-mismatch-free mechanism for weak-to-strong generalization inside a convex, well-understood model class. Such a baseline could help explain empirical observations in large language models and would shift theoretical discussion away from capacity gaps as a necessary ingredient.
major comments (2)
- [§3] §3, Theorem 1 (or equivalent main result): the assertion that weak-to-strong generalization occurs for 'most' student-teacher pairs requires an explicit quantification of P(risk(student) < risk(teacher)) > 1/2 under the stated mild assumptions. Because logistic loss is strictly convex, Jensen's inequality implies E[risk(student)] > risk(teacher) for any fixed teacher; the finite-sample bias induced by the assumptions must therefore overcome this effect. The current derivation does not supply a closed-form probability or a tight bound showing the bias is strong enough for the majority of pairs.
- [§2.2] §2.2, finite-sample ERM definition: the student is the minimizer of the empirical logistic loss on n samples labeled by the teacher. The 'most pairs' claim is sensitive to the regime relating n, dimension d, and the teacher's margin; the manuscript should state the precise scaling (e.g., n = ω(d) or n = Θ(d)) under which the probability exceeds 1/2 and verify that the mild distributional assumptions remain sufficient in that regime.
minor comments (2)
- [§2] Notation for the teacher parameter w_t and student parameter w_s is introduced without an explicit statement of the ambient dimension or the feature distribution; adding a short paragraph in §2 would improve readability.
- [Abstract] The abstract states the result holds 'under mild distributional assumptions' but does not list them; a one-sentence enumeration in the abstract or the first paragraph of §3 would help readers assess the scope immediately.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important points regarding the rigor of our probability claims and the precise scaling regimes. We address each major comment below and have revised the manuscript to strengthen the presentation and add the requested clarifications and bounds.
read point-by-point responses
-
Referee: [§3] §3, Theorem 1 (or equivalent main result): the assertion that weak-to-strong generalization occurs for 'most' student-teacher pairs requires an explicit quantification of P(risk(student) < risk(teacher)) > 1/2 under the stated mild assumptions. Because logistic loss is strictly convex, Jensen's inequality implies E[risk(student)] > risk(teacher) for any fixed teacher; the finite-sample bias induced by the assumptions must therefore overcome this effect. The current derivation does not supply a closed-form probability or a tight bound showing the bias is strong enough for the majority of pairs.
Authors: We agree that an explicit quantification would improve clarity. While the original proof of Theorem 1 shows via concentration that the finite-sample bias overcomes the Jensen gap with probability strictly greater than 1/2 for most pairs under the mild assumptions, it does not isolate a simple closed-form expression for this probability. In the revised manuscript we derive and state an explicit lower bound of the form P(risk(student) < risk(teacher)) ≥ 1/2 + Ω(1/√n) (with the hidden constant depending on the margin and sub-Gaussian parameters), which is strictly above 1/2 in the regimes of interest. This bound is obtained by combining the strict convexity of the logistic loss with a second-order Taylor expansion of the population risk around the teacher and standard empirical-process concentration for the ERM. revision: yes
-
Referee: [§2.2] §2.2, finite-sample ERM definition: the student is the minimizer of the empirical logistic loss on n samples labeled by the teacher. The 'most pairs' claim is sensitive to the regime relating n, dimension d, and the teacher's margin; the manuscript should state the precise scaling (e.g., n = ω(d) or n = Θ(d)) under which the probability exceeds 1/2 and verify that the mild distributional assumptions remain sufficient in that regime.
Authors: We thank the referee for emphasizing the need to specify the scaling. The original manuscript implicitly assumes the standard high-dimensional regime n = Ω(d log d) to guarantee uniform convergence of the empirical risk to the population risk while preserving the finite-sample bias effect. In the revision we explicitly state this scaling, prove that the mild distributional assumptions (sub-Gaussian covariates and bounded teacher margin) are sufficient for the concentration inequalities used in the proof to hold, and verify that the probability remains strictly above 1/2 throughout this regime. We also add a short remark clarifying that the result fails to hold with high probability when n = o(d), consistent with classical logistic-regression theory. revision: yes
Circularity Check
No circularity: derivation proceeds from linear logistic regression analysis and distributional assumptions without reducing to self-definition or fitted inputs
full rationale
The paper's central claim is that weak-to-strong generalization occurs for most student-teacher pairs in linear logistic regression under mild distributional assumptions, derived via analysis of the model without requiring capacity mismatch. No step reduces a prediction to a fitted parameter by construction, invokes a self-citation as the sole load-bearing justification for a uniqueness result, or renames an empirical pattern as a new derivation. The abstract and provided context frame the result as following from explicit model equations and assumptions on the data distribution, making the chain self-contained rather than tautological. The skeptic's convexity-based concern addresses proof strength but does not indicate circularity in the presented steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption mild distributional assumptions on the data
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Co-training and expansion: Towards bridging theory and practice , author=. Advances in neural information processing systems , volume=
-
[2]
Proceedings of the eleventh annual conference on Computational learning theory , pages=
Combining labeled and unlabeled data with co-training , author=. Proceedings of the eleventh annual conference on Computational learning theory , pages=
-
[3]
arXiv preprint arXiv:2410.04638 , year=
Provable weak-to-strong generalization via benign overfitting , author=. arXiv preprint arXiv:2410.04638 , year=
-
[4]
Advances in Neural Information Processing Systems , volume=
Self-distillation amplifies regularization in hilbert space , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
arXiv preprint arXiv:2506.03109 , year=
On Weak-to-Strong Generalization and f-Divergence , author=. arXiv preprint arXiv:2506.03109 , year=
-
[6]
Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
Predicting Weak-to-Strong Generalization from Latent Representations , author=. Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
2025
-
[7]
arXiv preprint arXiv:2502.01458 , year=
The Capabilities and Limitations of Weak-to-Strong Generalization: Generalization and Calibration , author=. arXiv preprint arXiv:2502.01458 , year=
-
[8]
arXiv preprint arXiv:2510.24812 , year=
From linear to nonlinear: Provable weak-to-strong generalization through feature learning , author=. arXiv preprint arXiv:2510.24812 , year=
-
[9]
arXiv preprint arXiv:2501.19105 , year=
Relating misfit to gain in weak-to-strong generalization beyond the squared loss , author=. arXiv preprint arXiv:2501.19105 , year=
-
[10]
arXiv preprint arXiv:2503.02877 , year=
Weak-to-strong generalization even in random feature networks, provably , author=. arXiv preprint arXiv:2503.02877 , year=
-
[11]
Advances in neural information processing systems , volume=
Theoretical analysis of weak-to-strong generalization , author=. Advances in neural information processing systems , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
Transcendence: Generative models can outperform the experts that train them , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
arXiv preprint arXiv:2507.18858 , year=
Weak-to-strong generalization with failure trajectories: A tree-based approach to elicit optimal policy in strong models , author=. arXiv preprint arXiv:2507.18858 , year=
-
[14]
arXiv preprint arXiv:2504.04785 , year=
Weak-for-Strong: Training Weak Meta-Agent to Harness Strong Executors , author=. arXiv preprint arXiv:2504.04785 , year=
-
[15]
arXiv preprint arXiv:2406.19032 , year=
Improving weak-to-strong generalization with reliability-aware alignment , author=. arXiv preprint arXiv:2406.19032 , year=
-
[16]
Debate Helps Weak-to-Strong Generalization , booktitle =
Hao Lang and Fei Huang and Yongbin Li , editor =. Debate Helps Weak-to-Strong Generalization , booktitle =. 2025 , url =. doi:10.1609/AAAI.V39I26.34952 , timestamp =
-
[17]
Advances in neural information processing systems , volume=
Quantifying the gain in weak-to-strong generalization , author=. Advances in neural information processing systems , volume=
-
[18]
arXiv preprint arXiv:2406.11431 , year=
Super (ficial)-alignment: Strong models may deceive weak models in weak-to-strong generalization , author=. arXiv preprint arXiv:2406.11431 , year=
-
[19]
arXiv preprint arXiv:2409.08813 , year=
Your weak llm is secretly a strong teacher for alignment , author=. arXiv preprint arXiv:2409.08813 , year=
-
[20]
Advances in Neural Information Processing Systems , volume=
Aligner: Efficient alignment by learning to correct , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Advances in Neural Information Processing Systems , volume=
Easy-to-hard generalization: Scalable alignment beyond human supervision , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Smaller, weaker, yet better: Training llm reasoners via compute-optimal sampling , author=. arXiv preprint arXiv:2408.16737 , year=
-
[23]
arXiv preprint arXiv:2407.13647 , year=
Weak-to-strong reasoning , author=. arXiv preprint arXiv:2407.13647 , year=
-
[24]
The Thirteenth International Conference on Learning Representations,
Seamus Somerstep and Felipe Maia Polo and Moulinath Banerjee and Yaacov Ritov and Mikhail Yurochkin and Yuekai Sun , title =. The Thirteenth International Conference on Learning Representations,. 2025 , timestamp =
2025
-
[25]
The Thirteenth International Conference on Learning Representations,
Changho Shin and John Cooper and Frederic Sala , title =. The Thirteenth International Conference on Learning Representations,. 2025 , timestamp =
2025
-
[26]
Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning , booktitle =
Ming Li and Yong Zhang and Shwai He and Zhitao Li and Hongyu Zhao and Jianzong Wang and Ning Cheng and Tianyi Zhou , editor =. Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning , booktitle =. 2024 , timestamp =
2024
-
[27]
arXiv preprint arXiv:2502.21321
Komal Kumar and Tajamul Ashraf and Omkar Thawakar and Rao Muhammad Anwer and Hisham Cholakkal and Mubarak Shah and Ming. CoRR , volume =. 2025 , eprinttype =. 2502.21321 , timestamp =
-
[28]
Proximal Policy Optimization Algorithms
John Schulman and Filip Wolski and Prafulla Dhariwal and Alec Radford and Oleg Klimov , title =. CoRR , volume =. 2017 , eprinttype =. 1707.06347 , timestamp =
work page internal anchor Pith review arXiv 2017
-
[29]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[30]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[31]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai and Andy Jones and Kamal Ndousse and Amanda Askell and Anna Chen and Nova DasSarma and Dawn Drain and Stanislav Fort and Deep Ganguli and Tom Henighan and Nicholas Joseph and Saurav Kadavath and Jackson Kernion and Tom Conerly and Sheer El Showk and Nelson Elhage and Zac Hatfield. Training a Helpful and Harmless Assistant with Reinforcement Lea...
work page internal anchor Pith review arXiv 2022
-
[32]
Hanze Dong and Wei Xiong and Deepanshu Goyal and Yihan Zhang and Winnie Chow and Rui Pan and Shizhe Diao and Jipeng Zhang and Kashun Shum and Tong Zhang , title =. Trans. Mach. Learn. Res. , volume =. 2023 , timestamp =
2023
-
[33]
Lee and Qi Lei , editor =
Yijun Dong and Yicheng Li and Yunai Li and Jason D. Lee and Qi Lei , editor =. Discrepancies are Virtue: Weak-to-Strong Generalization through Lens of Intrinsic Dimension , booktitle =. 2025 , timestamp =
2025
-
[34]
Forty-first International Conference on Machine Learning,
Collin Burns and Pavel Izmailov and Jan Hendrik Kirchner and Bowen Baker and Leo Gao and Leopold Aschenbrenner and Yining Chen and Adrien Ecoffet and Manas Joglekar and Jan Leike and Ilya Sutskever and Jeffrey Wu , title =. Forty-first International Conference on Machine Learning,. 2024 , timestamp =
2024
-
[35]
IBM Journal of research and development , volume=
Some studies in machine learning using the game of checkers , author=. IBM Journal of research and development , volume=. 1959 , publisher=
1959
-
[36]
The Delta Learning Hypothesis: Preference Tuning on Weak Data can Yield Strong Gains , journal =
Scott Geng and Hamish Ivison and Chun. The Delta Learning Hypothesis: Preference Tuning on Weak Data can Yield Strong Gains , journal =. 2025 , eprinttype =. 2507.06187 , timestamp =
-
[37]
On almost Linearity of Low Dimensional Projections from High Dimensional Data , urldate =
Peter Hall and Ker-Chau Li , journal =. On almost Linearity of Low Dimensional Projections from High Dimensional Data , urldate =
-
[38]
Freedman's inequality for matrix martingales , volume =
Tropp, Joel , journal =. Freedman's inequality for matrix martingales , volume =
-
[39]
1986 , author =
A characterization of spherical distributions , journal =. 1986 , author =
1986
-
[40]
On conditional moments of high-dimensional random vectors given lower-dimensional projections , urldate =
Lukas Steinberger and Hannes Leeb , journal =. On conditional moments of high-dimensional random vectors given lower-dimensional projections , urldate =
-
[41]
On the conditional distributions of low-dimensional projections from high-dimensional data , urldate =
Hannes Leeb , journal =. On the conditional distributions of low-dimensional projections from high-dimensional data , urldate =
-
[42]
Samworth , journal =
Richard J. Samworth , journal =. PETER HALL'S WORK ON HIGH-DIMENSIONAL DATA AND CLASSIFICATION , urldate =
-
[43]
Asymptotics of Graphical Projection Pursuit , urldate =
Persi Diaconis and David Freedman , journal =. Asymptotics of Graphical Projection Pursuit , urldate =
-
[44]
On Low-Dimensional Projections of High-Dimensional Distributions , year =
Duembgen, Lutz and Zerial, Perla , address =. On Low-Dimensional Projections of High-Dimensional Distributions , year =. arXiv.org , keywords =
-
[45]
Süli, Endre and Mayers, D. F. , address =. An introduction to numerical analysis , year =. An introduction to numerical analysis , edition =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.