Recognition: unknown
BioTool: A Comprehensive Tool-Calling Dataset for Enhancing Biomedical Capabilities of Large Language Models
Pith reviewed 2026-05-08 11:02 UTC · model grok-4.3
The pith
BioTool dataset lets 4B-parameter LLMs outperform GPT-5.1 in calling biomedical tools
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
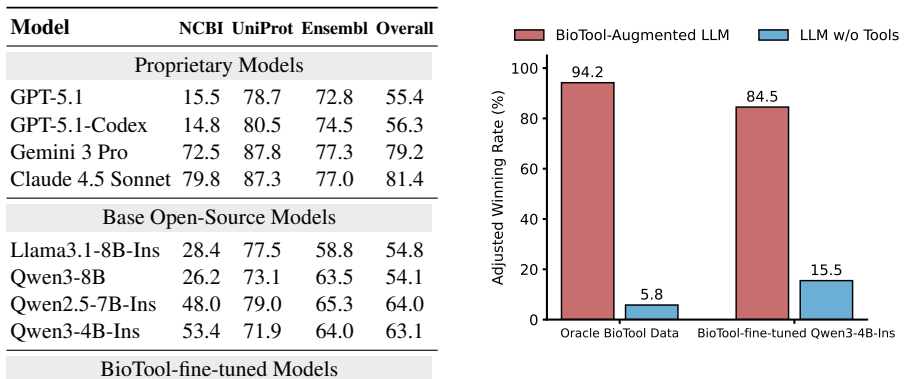
BioTool comprises 34 frequently used tools collected from the NCBI, Ensembl, and UniProt databases, along with 7,040 high-quality, human-verified query-API call pairs spanning variation, genomics, proteomics, evolution, and general biology. Fine-tuning a 4-billion-parameter LLM on BioTool yields substantial improvements in biomedical tool-calling performance, outperforming cutting-edge commercial LLMs such as GPT-5.1. Furthermore, human expert evaluations demonstrate that integrating a BioTool-fine-tuned tool caller significantly improves downstream answer quality compared to the same LLM without tool usage.
What carries the argument
BioTool dataset of 34 tools and 7,040 human-verified query-API pairs used to fine-tune LLMs for accurate biomedical tool calling
If this is right
- The fine-tuned model generates correct calls for tools across genomics, proteomics, evolution and variation tasks.
- Downstream answer quality rises when the model uses the learned tool caller versus answering without tools.
- A single small model can now handle 34 specific tools from major public databases with high reliability.
- The approach shows that targeted fine-tuning can close the gap between open small models and closed frontier models on domain tool use.
Where Pith is reading between the lines
- Similar verified query-tool datasets could be built for chemistry, physics or clinical medicine to extend the same gains.
- Smaller fine-tuned models may let research groups run reliable biomedical agents locally without sending queries to commercial APIs.
- The 7,040 pairs could serve as a public benchmark for measuring progress on biomedical tool-calling systems.
Load-bearing premise
The 7,040 verified query-API pairs represent the kinds of requests biomedical researchers actually make in practice.
What would settle it
Evaluating the fine-tuned model on a fresh collection of real biomedical questions collected from practicing researchers and measuring whether tool-call accuracy remains as high as reported.
Figures



read the original abstract
Despite the success of large language models (LLMs) on general-purpose tasks, their performance in highly specialized domains such as biomedicine remains unsatisfactory. A key limitation is the inability of LLMs to effectively leverage biomedical tools, which clinical experts and biomedical researchers rely on extensively in daily workflows. While recent general-domain tool-calling datasets have substantially improved the capabilities of LLM agents, existing efforts in the biomedical domain largely rely on in-context learning and restrict models to a small set of tools. To address this gap, we introduce BioTool, a comprehensive biomedical tool-calling dataset designed for fine-tuning LLMs. BioTool comprises 34 frequently used tools collected from the NCBI, Ensembl, and UniProt databases, along with 7,040 high-quality, human-verified query-API call pairs spanning variation, genomics, proteomics, evolution, and general biology. Fine-tuning a 4-billion-parameter LLM on BioTool yields substantial improvements in biomedical tool-calling performance, outperforming cutting-edge commercial LLMs such as GPT-5.1. Furthermore, human expert evaluations demonstrate that integrating a BioTool-fine-tuned tool caller significantly improves downstream answer quality compared to the same LLM without tool usage, highlighting the effectiveness of BioTool in enhancing the biomedical capabilities of LLMs. The full dataset and evaluation code are available at https://github.com/gxx27/BioTool
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BioTool, a dataset of 34 tools drawn from NCBI, Ensembl, and UniProt together with 7,040 human-verified query-API call pairs spanning variation, genomics, proteomics, evolution, and general biology. The central empirical claim is that fine-tuning a 4-billion-parameter LLM on BioTool produces substantial gains in biomedical tool-calling performance that exceed those of commercial models such as GPT-5.1; a secondary claim is that the resulting tool-calling model improves downstream answer quality according to human expert evaluation.
Significance. If the reported gains prove robust, the work supplies a publicly released, domain-specific tool-calling resource that directly addresses a recognized limitation of current LLMs in biomedicine. The open release of the full dataset and evaluation code is a concrete strength that supports reproducibility and follow-on research.
major comments (3)
- [Abstract] Abstract: the headline claim that the 4B fine-tuned model outperforms GPT-5.1 is presented without any description of the evaluation metrics (accuracy, exact match, API-call success rate, etc.), the size or composition of the held-out test set, the precise commercial baselines and prompting regimes used, or any statistical significance tests. These omissions make the performance comparison impossible to assess.
- [Dataset] Dataset construction (implied §3): the 7,040 query-API pairs are described only as “human-verified” and spanning several biological subfields; no information is given on query generation method (template-driven vs. expert-authored), inter-annotator agreement, per-tool coverage statistics, or the existence of an out-of-distribution test partition. Without these details the representativeness assumption required for the generalization claim cannot be evaluated.
- [Human Evaluation] Human evaluation section: the statement that tool-augmented answers are judged superior by experts lacks specification of evaluation criteria, number of annotators, blinding protocol, inter-rater reliability, or statistical analysis. These elements are load-bearing for the downstream-quality claim.
minor comments (2)
- [Abstract] Abstract: the phrase “cutting-edge commercial LLMs such as GPT-5.1” should list the exact models and versions compared.
- [Conclusion] The GitHub link is provided but the manuscript does not indicate whether the released code includes the exact fine-tuning scripts, evaluation harness, and data splits used in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important gaps in methodological transparency that we will address through targeted revisions. We provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that the 4B fine-tuned model outperforms GPT-5.1 is presented without any description of the evaluation metrics (accuracy, exact match, API-call success rate, etc.), the size or composition of the held-out test set, the precise commercial baselines and prompting regimes used, or any statistical significance tests. These omissions make the performance comparison impossible to assess.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to assess the central claim. In the revised manuscript we will expand the abstract to state the primary metric (API-call success rate defined as exact match on function name and parameters), the held-out test set size and split (1,408 examples, 20% of the corpus), the commercial baseline (GPT-5.1 under both zero-shot and 5-shot prompting), and that the reported gains are statistically significant (McNemar test, p < 0.01). Full experimental details will continue to appear in Section 4. revision: yes
-
Referee: [Dataset] Dataset construction (implied §3): the 7,040 query-API pairs are described only as “human-verified” and spanning several biological subfields; no information is given on query generation method (template-driven vs. expert-authored), inter-annotator agreement, per-tool coverage statistics, or the existence of an out-of-distribution test partition. Without these details the representativeness assumption required for the generalization claim cannot be evaluated.
Authors: The referee correctly notes that additional construction details are needed. We will revise Section 3 to describe the query generation process (hybrid template-driven synthesis from tool documentation followed by expert authoring for coverage and diversity), report inter-annotator agreement on the verification step, add a table of per-tool and per-subfield example counts, and explicitly document the out-of-distribution test partition (queries with novel phrasing and tool combinations). These additions will allow direct evaluation of representativeness. revision: yes
-
Referee: [Human Evaluation] Human evaluation section: the statement that tool-augmented answers are judged superior by experts lacks specification of evaluation criteria, number of annotators, blinding protocol, inter-rater reliability, or statistical analysis. These elements are load-bearing for the downstream-quality claim.
Authors: We accept that the human evaluation protocol requires fuller description. In the revised manuscript we will expand the relevant section to specify the evaluation criteria (relevance, factual accuracy, and completeness on a 5-point scale), the number and expertise of annotators, the blinding procedure, inter-rater reliability statistics, and the statistical test applied to the preference judgments. This will make the downstream-quality results fully interpretable. revision: yes
Circularity Check
No circularity in empirical dataset and fine-tuning claims
full rationale
The paper's core claims rest on constructing a new dataset (34 tools, 7,040 human-verified query-API pairs) and reporting standard empirical outcomes: fine-tuning a 4B LLM yields measurable gains versus external commercial models (GPT-5.1) plus improved downstream answer quality under human expert evaluation. No mathematical derivation chain, self-definitional relations, fitted parameters renamed as predictions, or load-bearing self-citations exist; all results are externally benchmarked and falsifiable outside the paper's own fitted values.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 34 selected tools from NCBI, Ensembl, and UniProt are representative of frequently used biomedical tools.
- domain assumption Human verification of the 7,040 query-API pairs ensures high quality and lack of bias.
Reference graph
Works this paper leans on
-
[1]
bioRxiv , pages=
Biomni: A General-Purpose Biomedical AI Agent , author=. bioRxiv , pages=. 2025 , publisher=
2025
-
[3]
2023 , eprint=
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , author=. 2023 , eprint=
2023
-
[4]
Advances in Neural Information Processing Systems , year=
Gorilla: Large Language Model Connected with Massive APIs , author=. Advances in Neural Information Processing Systems , year=
-
[5]
2023 , eprint=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. 2023 , eprint=
2023
-
[6]
Bioinformatics , volume=
Genegpt: Augmenting large language models with domain tools for improved access to biomedical information , author=. Bioinformatics , volume=. 2024 , publisher=
2024
-
[7]
2025 , eprint=
SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning , author=. 2025 , eprint=
2025
-
[8]
and Cox, Sean and Schilter, Oliver and others , title =
Bran, Andres M. and Cox, Sean and Schilter, Oliver and others , title =. Nature Machine Intelligence , volume =. 2024 , doi =
2024
-
[9]
Briefings in Bioinformatics , volume =
Shang, Xinyi and Liao, Xu and Ji, Zhicheng and Hou, Wenpin , title =. Briefings in Bioinformatics , volume =. 2025 , month =. doi:10.1093/bib/bbaf492 , url =
-
[10]
2023 , eprint=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. 2023 , eprint=
2023
-
[11]
2023 , url=
GPT-4 Technical Report , author=. 2023 , url=
2023
-
[12]
ArXiv , year=
Qwen Technical Report , author=. ArXiv , year=
-
[13]
Nature Communications , volume =
Benchmarking large language models for biomedical natural language processing applications and recommendations , author =. Nature Communications , volume =. 2025 , doi =
2025
-
[16]
and Gish, Warren and Miller, Webb and Myers, Eugene W
Altschul, Stephen F. and Gish, Warren and Miller, Webb and Myers, Eugene W. and Lipman, David J. , title =. Journal of Molecular Biology , volume =. 1990 , doi =
1990
-
[19]
Entrez Programming Utilities Help [Internet]
A General Introduction to the E-utilities , author=. Entrez Programming Utilities Help [Internet]. Bethesda (MD): National Center for Biotechnology Information (US) , year=
-
[20]
OpenAI o3 and o4-mini System Card , year =
-
[21]
System Card: Claude Haiku 4.5 , year =
-
[22]
Nucleic Acids Research , volume =
Hubbard, Tim and Barker, David and Birney, Ewan and Cameron, Graham and Chen, Yong and Clark, Lucy and Cox, Tony and Cuff, James and Curwen, Val and Down, Thomas and Durbin, Richard and Eyras, Eduardo and Gilbert, James and Hammond, Matthew and Huminiecki, Lukasz and Kasprzyk, Arek and Lehvaslaiho, Heikki and Lijnzaad, Peter and Melsopp, Chris and Mongin,...
2002
-
[23]
2017 , doi =
UniProt: the universal protein knowledgebase , journal =. 2017 , doi =
2017
-
[24]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[25]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[26]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[27]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[28]
2025 , month=
System Card: Claude Sonnet 4.5 , author=. 2025 , month=
2025
-
[29]
2025 , month=
Gemini 3 Pro Model Card , author=. 2025 , month=
2025
-
[30]
2025 , month=
GPT-5.1 Instant and GPT-5.1 Thinking System Card Addendum , author=. 2025 , month=
2025
-
[31]
2025 , month=
GPT-5.1-Codex-Max System Card , author=. 2025 , month=
2025
-
[32]
Psychometrika , volume=
Note on the sampling error of the difference between correlated proportions or percentages , author=. Psychometrika , volume=. 1947 , publisher=
1947
-
[33]
2020 , eprint=
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers , author=. 2020 , eprint=
2020
-
[34]
Bioinformatics , volume=
MedCPT: Contrastive Pre-trained Transformers with large-scale PubMed search logs for zero-shot biomedical information retrieval , author=. Bioinformatics , volume=. 2023 , publisher=
2023
-
[35]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[36]
Annual Meeting of the Association for Computational Linguistics , year=
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[37]
Gonzalez , booktitle=
Shishir G Patil and Huanzhi Mao and Fanjia Yan and Charlie Cheng-Jie Ji and Vishnu Suresh and Ion Stoica and Joseph E. Gonzalez , booktitle=. The Berkeley Function Calling Leaderboard (. 2025 , url=
2025
-
[38]
Computing Krippendorff's alpha-reliability , author=
-
[39]
biometrics , pages=
The measurement of observer agreement for categorical data , author=. biometrics , pages=. 1977 , publisher=
1977
-
[40]
Shadab Ahmad, Leonardo Jose da Costa Gonzales, Emily H Bowler-Barnett, Daniel L Rice, Minjoon Kim, Supun Wijerathne, Aurélien Luciani, Swaathi Kandasaamy, Jie Luo, Xavier Watkins, Edd Turner, Maria J Martin, and the UniProt Consortium. 2025. https://doi.org/10.1093/nar/gkaf394 The uniprot website api: facilitating programmatic access to protein knowledge ...
-
[41]
Altschul, Warren Gish, Webb Miller, Eugene W
Stephen F. Altschul, Warren Gish, Webb Miller, Eugene W. Myers, and David J. Lipman. 1990. https://doi.org/10.1016/S0022-2836(05)80360-2 Basic local alignment search tool . Journal of Molecular Biology, 215(3):403--410
-
[42]
Anthropic . 2025. https://assets.anthropic.com/m/99128ddd009bdcb/Claude-Haiku-4-5-System-Card.pdf System card: Claude haiku 4.5 . System Card
2025
-
[43]
Anthropic. 2025. https://assets.anthropic.com/m/12f214efcc2f457a/original/Claude-Sonnet-4-5-System-Card.pdf System card: Claude sonnet 4.5
2025
-
[44]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenhang Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, K. Lu, and 31 others. 2023. https://api.semanticscholar.org/CorpusID:263134555 Qwen technical report . ArXiv, abs/2309.16609
work page internal anchor Pith review arXiv 2023
-
[45]
Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D
Andres M. Bran, Sean Cox, Oliver Schilter, and 1 others. 2024. https://doi.org/10.1038/s42256-024-00832-8 Augmenting large language models with chemistry tools . Nature Machine Intelligence, 6:525--535
-
[46]
Qiang Chen, Yifan Hu, Xiaohan Peng, and 1 others. 2025. https://doi.org/10.1038/s41467-025-56989-2 Benchmarking large language models for biomedical natural language processing applications and recommendations . Nature Communications, 16:3280
-
[47]
Google. 2025. https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf Gemini 3 pro model card
2025
-
[48]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review arXiv 2024
-
[49]
Kexin Huang, Serena Zhang, Hanchen Wang, Yuanhao Qu, Yingzhou Lu, Yusuf Roohani, Ryan Li, Lin Qiu, Junze Zhang, Yin Di, and 1 others. 2025. Biomni: A general-purpose biomedical ai agent. bioRxiv, pages 2025--05
2025
-
[50]
Tim Hubbard, David Barker, Ewan Birney, Graham Cameron, Yong Chen, Lucy Clark, Tony Cox, James Cuff, Val Curwen, Thomas Down, Richard Durbin, Eduardo Eyras, James Gilbert, Matthew Hammond, Lukasz Huminiecki, Arek Kasprzyk, Heikki Lehvaslaiho, Peter Lijnzaad, Chris Melsopp, and 16 others. 2002. https://doi.org/10.1093/nar/30.1.38 The ensembl genome databas...
-
[51]
Qiao Jin, Won Kim, Qingyu Chen, Donald C Comeau, Lana Yeganova, W John Wilbur, and Zhiyong Lu. 2023. Medcpt: Contrastive pre-trained transformers with large-scale pubmed search logs for zero-shot biomedical information retrieval. Bioinformatics, 39(11):btad651
2023
-
[52]
Qiao Jin, Yifan Yang, Qingyu Chen, and Zhiyong Lu. 2024. Genegpt: Augmenting large language models with domain tools for improved access to biomedical information. Bioinformatics, 40(2):btae075
2024
-
[53]
Klaus Krippendorff. 2011. Computing krippendorff's alpha-reliability
2011
-
[54]
J Richard Landis and Gary G Koch. 1977. The measurement of observer agreement for categorical data. biometrics, pages 159--174
1977
-
[55]
Mingchen Li, Zaifu Zhan, Han Yang, Yongkang Xiao, Huixue Zhou, Jiatan Huang, and Rui Zhang. 2025 a . https://doi.org/10.1126/sciadv.adr1443 Benchmarking retrieval-augmented large language models in biomedical nlp: Application, robustness, and self-awareness . Science Advances, 11(47):eadr1443
-
[56]
Xuchen Li, Ruitao Wu, Xuanbo Liu, Xukai Wang, Jinbo Hu, Zhixin Bai, Bohan Zeng, Hao Liang, Leheng Chen, Mingrui Chen, Haitian Zhong, Xuanlin Yang, Xu-Yao Zhang, Liu Liu, Jia Li, Kaiqi Huang, Jiahao Xu, Haitao Mi, Wentao Zhang, and Bin Dong. 2025 b . https://arxiv.org/abs/2511.08151 Sciagent: A unified multi-agent system for generalistic scientific reasoni...
- [57]
-
[58]
Quinn McNemar. 1947. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika, 12(2):153--157
1947
-
[59]
NCBI. 2017. https://doi.org/10.1093/nar/gkx1095 Database resources of the national center for biotechnology information . Nucleic Acids Research, 46(D1):D8--D13
-
[60]
OpenAI. 2023. https://api.semanticscholar.org/CorpusID:257532815 Gpt-4 technical report
2023
-
[61]
OpenAI. 2025 a . https://cdn.openai.com/pdf/2a7d98b1-57e5-4147-8d0e-683894d782ae/5p1_codex_max_card_03.pdf Gpt-5.1-codex-max system card
2025
-
[62]
OpenAI. 2025 b . https://cdn.openai.com/pdf/4173ec8d-1229-47db-96de-06d87147e07e/5_1_system_card.pdf Gpt-5.1 instant and gpt-5.1 thinking system card addendum
2025
-
[63]
OpenAI . 2025. https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf Openai o3 and o4-mini system card . System Card
2025
-
[64]
Gonzalez
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. 2025. https://openreview.net/forum?id=2GmDdhBdDk The berkeley function calling leaderboard ( BFCL ): From tool use to agentic evaluation of large language models . In Forty-second International Conference on Machine Learning
2025
-
[65]
Patil, Tianjun Zhang, Xin Wang, and Joseph E
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. 2024. Gorilla: Large language model connected with massive apis
2024
-
[66]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2023. https://arxiv.org/abs/2307.16789 Toolllm: Facilitating large language models to master 16000+ real-world apis . Preprint, arXiv:2307.16789
work page internal anchor Pith review arXiv 2023
-
[67]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, and 25 others. 2025. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . Preprint, arXiv:2412.15115
work page internal anchor Pith review arXiv 2025
-
[68]
Eric Sayers. 2010. A general introduction to the e-utilities. Entrez Programming Utilities Help [Internet]. Bethesda (MD): National Center for Biotechnology Information (US)
2010
-
[69]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. https://arxiv.org/abs/2302.04761 Toolformer: Language models can teach themselves to use tools . Preprint, arXiv:2302.04761
work page internal anchor Pith review arXiv 2023
-
[70]
The UniProt Consortium . 2017. https://doi.org/10.1093/nar/gkw1099 Uniprot: the universal protein knowledgebase . Nucleic Acids Research, 45(D1):D158--D169
-
[71]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022. https://api.semanticscholar.org/CorpusID:254877310 Self-instruct: Aligning language models with self-generated instructions . In Annual Meeting of the Association for Computational Linguistics
2022
-
[72]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. https://arxiv.org/abs/2201.11903 Chain-of-thought prompting elicits reasoning in large language models . Preprint, arXiv:2201.11903
work page internal anchor Pith review arXiv 2023
-
[73]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review arXiv 2025
-
[74]
Andrew Yates, Kathryn Beal, Stephen Keenan, William McLaren, Miguel Pignatelli, Graham R. S. Ritchie, Magali Ruffier, Kieron Taylor, Alessandro Vullo, and Paul Flicek. 2014. https://doi.org/10.1093/bioinformatics/btu613 The ensembl rest api: Ensembl data for any language . Bioinformatics, 31(1):143--145
-
[75]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. https://arxiv.org/abs/2306.05685 Judging llm-as-a-judge with mt-bench and chatbot arena . Preprint, arXiv:2306.05685
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.