Recognition: unknown
Optimal Confidence Band for Kernel Gradient Flow Estimator
Pith reviewed 2026-05-08 04:34 UTC · model grok-4.3
The pith
Kernel gradient flow estimators attain minimax-optimal supremum-norm rates and support simultaneous confidence bands that shrink nearly as fast.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the capacity-source condition framework, convergence rates for the supremum-norm generalization error of both continuous and discrete kernel gradient flows are established when the source condition satisfies s > α0, where α0 denotes the embedding index; these rates match the minimax optimal rates. Simultaneous confidence bands are then constructed whose widths shrink at rates greater than but arbitrarily close to the same minimax rates.
What carries the argument
Kernel gradient flow estimator analyzed under the capacity-source condition with source parameter s strictly larger than the kernel embedding index α0.
If this is right
- The estimators achieve the best possible uniform convergence rates under the stated conditions.
- Simultaneous confidence bands become available with widths that approach the theoretical limit.
- Both the idealized continuous flow and its implementable discrete versions receive the same optimality guarantees.
- The results apply directly to nonparametric regression problems that require uniform inference.
Where Pith is reading between the lines
- Practitioners could prefer gradient-flow methods when uniform bands rather than pointwise intervals are needed.
- The same proof template may extend to other iterative kernel algorithms that admit a continuous-time limit.
- Numerical checks with known target functions could verify whether the predicted shrinkage rates appear in finite samples.
Load-bearing premise
The capacity-source condition framework must hold with the source parameter exceeding the embedding index of the kernel.
What would settle it
A simulation or real-data example with known ground truth in which the observed supremum-norm error of the kernel gradient flow stays larger than the claimed minimax rate, or in which the constructed bands fail to shrink at the stated near-minimax speed.
Figures

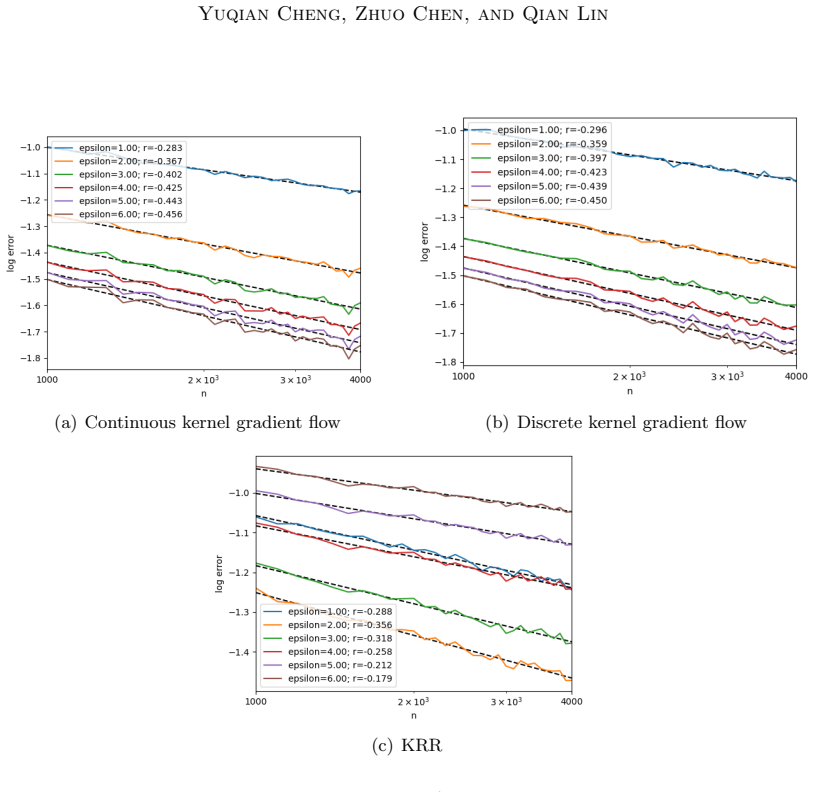
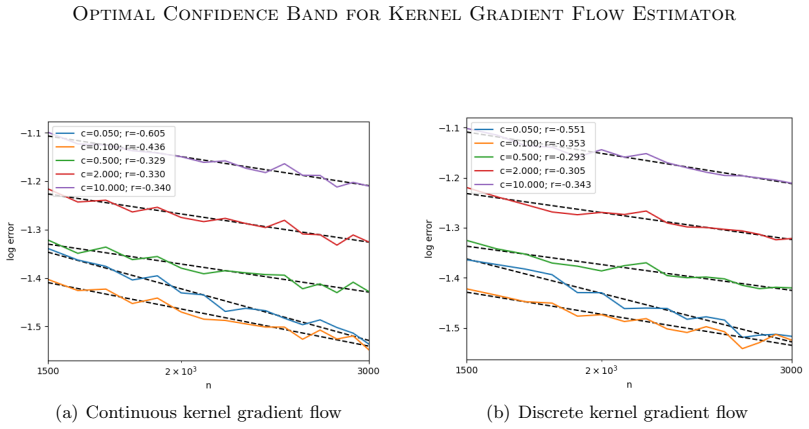

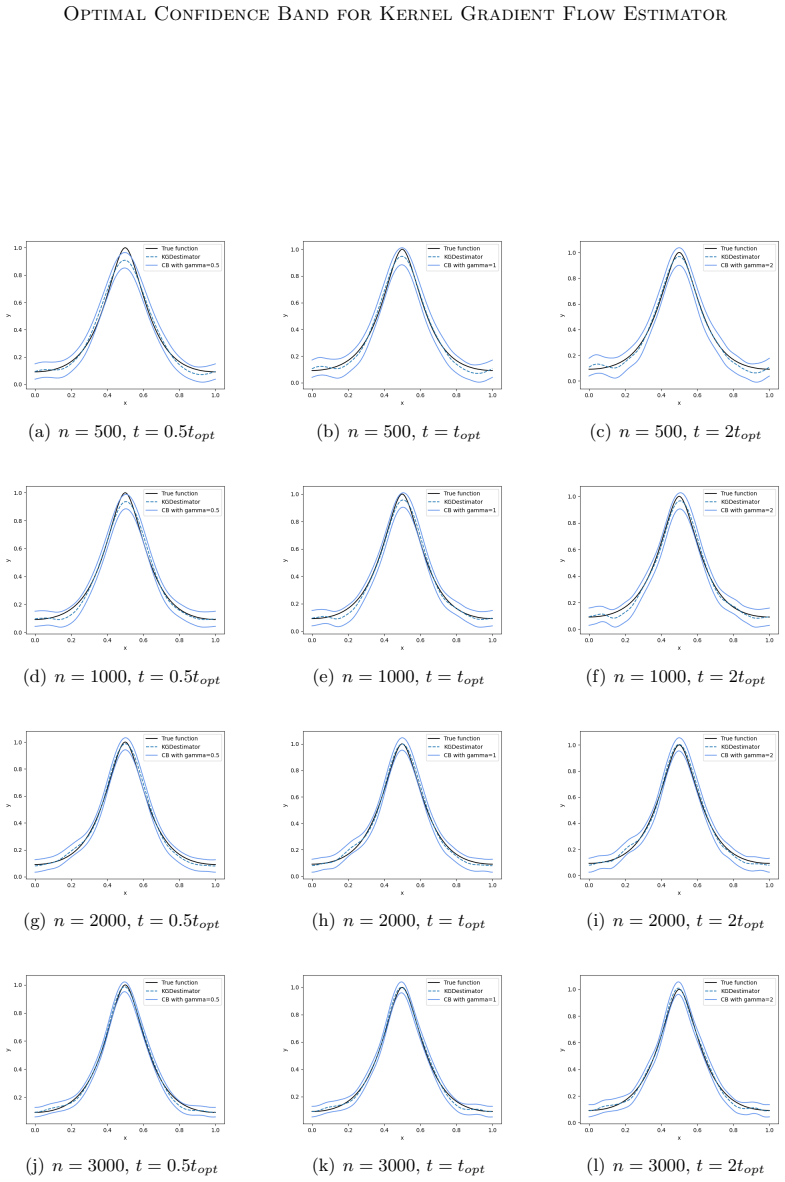
read the original abstract
In this paper, we investigate the supremum-norm generalization error and the uniform inference for a specific class of kernel regression methods, namely the kernel gradient flows. Under the widely adopted capacity-source condition framework in the kernel regression literature, we first establish convergence rates for the supremum norm generalization error of both continuous and discrete kernel gradient flows under the source condition $s>\alpha_0$, where $\alpha_0\in(0,1)$ denotes the embedding index of the kernel function. Moreover, we show that these rates match the minimax optimal rates. Building on this result, we then construct simultaneous confidence bands for both continuous and discrete kernel gradient flows. Notably, the widths of the proposed confidence bands are also optimal, in the sense that their shrinkage rates are greater than, while can be arbitrarily close to, the minimax optimal rates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript establishes supremum-norm convergence rates for both continuous and discrete kernel gradient flow estimators under the standard capacity-source condition with source parameter s > α0 (α0 the embedding index of the kernel). These rates are shown to match known minimax rates. The paper then constructs simultaneous confidence bands whose widths shrink at rates strictly faster than, yet arbitrarily close to, the minimax rate.
Significance. If the technical derivations hold, the results extend optimal uniform-norm estimation and inference to the kernel gradient flow setting, which is a natural and widely studied class of estimators. The use of the capacity-source framework permits direct comparison with existing minimax results in kernel regression, and the near-optimal band widths address a practically relevant gap between estimation rates and simultaneous inference.
minor comments (3)
- The abstract and introduction should explicitly recall the precise form of the capacity-source condition (eigenvalue decay and source smoothness) rather than referring only to the regime s > α0; this would make the optimality statements immediately verifiable without consulting external literature.
- Clarify the precise meaning of 'shrinkage rates are greater than' the minimax rate in the confidence-band construction; a short remark relating the band width to the estimation rate plus a logarithmic factor would remove ambiguity.
- Add a brief comparison table or paragraph contrasting the obtained sup-norm rates with the corresponding L2 rates under the same assumptions; this would highlight the technical contribution of the uniform-norm analysis.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work on supremum-norm rates and near-optimal simultaneous confidence bands for kernel gradient flows under the capacity-source condition. We appreciate the recommendation for minor revision and the recognition that these results extend existing minimax theory to this estimator class.
Circularity Check
No significant circularity detected
full rationale
The paper derives sup-norm convergence rates for kernel gradient flows under the standard external capacity-source condition framework (with s > α0) and shows these match known minimax rates before constructing simultaneous confidence bands whose widths shrink at rates arbitrarily close to but strictly better than the minimax rate. No step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the assumptions and minimax benchmarks are imported from the broader kernel regression literature rather than generated internally. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Combettes, Patrick L
Bauschke, Heinz H. and Combettes, Patrick L. , date-added =. Convex Analysis and Monotone Operator Theory , year =
-
[2]
Local and global asymptotic inference in smoothing spline models , volume =
Shang, Zuofeng and Cheng, Guang , date-added =. Local and global asymptotic inference in smoothing spline models , volume =. The Annals of Statistics , number =
-
[3]
arXiv preprint arXiv:2405.09362 , title =
Li, Yicheng and Zhang, Haobo and Lin, Qian , date-added =. arXiv preprint arXiv:2405.09362 , title =
-
[4]
Statistical optimality of deep wide neural networks , year =
Li, Yicheng and Yu, Zixiong and Chen, Guhan and Lin, Qian , date-added =. Statistical optimality of deep wide neural networks , year =
-
[5]
Sobolev spaces, kernels and discrepancies over hyperspheres , year =
Hubbert, Simon and Porcu, Emilio and Oates, Chris and Girolami, Mark and others , date-added =. Sobolev spaces, kernels and discrepancies over hyperspheres , year =
-
[6]
High-dimensional statistics: A non-asymptotic viewpoint , volume =
Wainwright, Martin J , date-added =. High-dimensional statistics: A non-asymptotic viewpoint , volume =
-
[7]
Nearly optimal central limit theorem and bootstrap approximations in high dimensions , volume =
Chernozhukov, Victor and Chetverikov, Denis and Koike, Yuta , date-added =. Nearly optimal central limit theorem and bootstrap approximations in high dimensions , volume =. The Annals of Applied Probability , number =
-
[8]
Improved central limit theorem and bootstrap approximations in high dimensions , volume =
Chernozhuokov, Victor and Chetverikov, Denis and Kato, Kengo and Koike, Yuta , date-added =. Improved central limit theorem and bootstrap approximations in high dimensions , volume =. The Annals of Statistics , number =
-
[9]
Central limit theorems and bootstrap in high dimensions , volume =
Chernozhukov, Victor and Chetverikov, Denis and Kato, Kengo , date-added =. Central limit theorems and bootstrap in high dimensions , volume =. The Annals of Probability , number =
-
[10]
Gaussian approximations and multiplier bootstrap for maxima of sums of high-dimensional random vectors , volume =
Chernozhukov, Victor and Chetverikov, Denis and Kato, Kengo , date-added =. Gaussian approximations and multiplier bootstrap for maxima of sums of high-dimensional random vectors , volume =. The Annals of Statistics , number =
-
[11]
Kernel ridge regression inference , year =
Singh, Rahul and Vijaykumar, Suhas , date-added =. Kernel ridge regression inference , year =
-
[12]
Function Spaces, Entropy Numbers, Differential Operators , volume =
Edmunds, David Eric and Triebel, Hans , date-added =. Function Spaces, Entropy Numbers, Differential Operators , volume =
-
[13]
Minimax estimation of smooth densities in Wasserstein distance , volume =
Niles-Weed, Jonathan and Berthet, Quentin , date-added =. Minimax estimation of smooth densities in Wasserstein distance , volume =. The Annals of Statistics , number =
-
[14]
Optimal global rates of convergence for nonparametric regression , year =
Stone, Charles J , date-added =. Optimal global rates of convergence for nonparametric regression , year =. The Annals of Statistics , volume=
-
[15]
Exact adaptive pointwise estimation on Sobolev classes of densities , volume =
Butucea, Cristina , date-added =. Exact adaptive pointwise estimation on Sobolev classes of densities , volume =. ESAIM: Probability and Statistics , pages =
-
[16]
A constrained risk inequality with applications to nonparametric functional estimation , volume =
Brown, Lawrence D and Low, Mark G , date-added =. A constrained risk inequality with applications to nonparametric functional estimation , volume =. The Annals of Statistics , number =
-
[17]
The L^ Learnability of Reproducing Kernel Hilbert Spaces , year =
Chen, Hongrui and Long, Jihao and Wu, Lei , date-added =. The L^ Learnability of Reproducing Kernel Hilbert Spaces , year =
-
[18]
Toward L^ Recovery of Nonlinear Functions: A Polynomial Sample Complexity Bound for Gaussian Random Fields , year =
Dong, Kefan and Ma, Tengyu , booktitle =. Toward L^ Recovery of Nonlinear Functions: A Polynomial Sample Complexity Bound for Gaussian Random Fields , year =
-
[19]
Multivariate L^ approximation in the worst case setting over reproducing kernel Hilbert spaces , volume =
Kuo, Frances Y and Wasilkowski, Grzegorz W and Wo. Multivariate L^ approximation in the worst case setting over reproducing kernel Hilbert spaces , volume =. Journal of approximation theory , number =
-
[20]
Tuo, Rui and Zou, Lu , date-added =. arXiv preprint. arXiv:2403.04248 , title =
-
[21]
Liu, Meimei and Shang, Zuofeng and Yang, Yun , date-added =. arXiv preprint. arXiv:2310.00881 , title =
-
[22]
Yang, Yun and Bhattacharya, Anirban and Pati, Debdeep , date-added =. arXiv preprint. arXiv:1708.04753 , title =
-
[23]
Optimal rates for the regularized learning algorithms under general source condition , volume =
Rastogi, Abhishake and Sampath, Sivananthan , date-added =. Optimal rates for the regularized learning algorithms under general source condition , volume =. Frontiers in Applied Mathematics and Statistics , pages =
-
[24]
Optimal rates for regularization of statistical inverse learning problems , volume =
Blanchard, Gilles and M. Optimal rates for regularization of statistical inverse learning problems , volume =. Foundations of Computational Mathematics , number =
-
[25]
Advances in Neural Information Processing Systems , title =
Pillaud-Vivien, Loucas and Rudi, Alessandro and Bach, Francis , date-added =. Advances in Neural Information Processing Systems , title =
-
[26]
Spectral algorithms for supervised learning , volume =
Gerfo, L Lo and Rosasco, Lorenzo and Odone, Francesca and Vito, E De and Verri, Alessandro , date-added =. Spectral algorithms for supervised learning , volume =. Neural Computation , number =
-
[27]
On regularization algorithms in learning theory , volume =
Bauer, Frank and Pereverzev, Sergei and Rosasco, Lorenzo , date-added =. On regularization algorithms in learning theory , volume =. Journal of Complexity , number =
-
[28]
Kernel interpolation in sobolev spaces is not consistent in low dimensions , year =
Buchholz, Simon , booktitle =. Kernel interpolation in sobolev spaces is not consistent in low dimensions , year =
-
[29]
Kernel interpolation generalizes poorly , volume =
Li, Yichen and Zhang, Haobo and Lin, Qian , date-added =. Kernel interpolation generalizes poorly , volume =. Biometrika , number =
-
[30]
Optimal rates for regularized least squares regression , year =
Steinwart, Ingo and Hush, Don and Scovel, Clint , date-added =. Optimal rates for regularized least squares regression , year =. COLT , pages =
-
[31]
Learning theory estimates via integral operators and their approximations , volume =
Smale, Steve and Zhou, Ding-Xuan , date-added =. Learning theory estimates via integral operators and their approximations , volume =. Constructive Approximation , number =
-
[32]
Convex Optimization , year =
Boyd, Stephen and Vandenberghe, Lieven , date-added =. Convex Optimization , year =
-
[33]
Advances in neural information processing systems , title =
Jacot, Arthur and Franck Gabriel and Cl\'ement Hongler , date-added =. Advances in neural information processing systems , title =
-
[34]
, date-added =
Stein, Michael L. , date-added =. Interpolation of spatial data: some theory for kriging , year =
-
[35]
Rasmussen, Carl Edward and Williams, Christopher K. I. , date-added =. Gaussian Processes for Machine Learning , year =
-
[36]
On early stopping in gradient descent learning , volume =
Yao, Yuan and Rosasco, Lorenzo and Caponnetto, Andrea , date-added =. On early stopping in gradient descent learning , volume =. Constructive Approximation , number =
-
[37]
, date-added =
Simon, James B. , date-added =. On kernel regression with data-dependent kernels , year =
-
[38]
Empirical and multiplier bootstraps for suprema of empirical processes of increasing complexity, and related gaussian couplings , volume =
Chernozhukov, Victor and Chetverikov, Denis and Kato, Kengo , date-added =. Empirical and multiplier bootstraps for suprema of empirical processes of increasing complexity, and related gaussian couplings , volume =. Stochastic Processes and their Applications , number =
-
[39]
Anti-concentration and honest, adaptive confidence bands , volume =
Chernozhukov, Victor and Chetverikov, Denis and Kato, Kengo , date-added =. Anti-concentration and honest, adaptive confidence bands , volume =. Annals of Statistics , pages =
-
[40]
Supplement to ``gaussian approximation of suprema of empirical processes'' , year =
Chernozhukov, Victor and Chetverikov, Denis and Kato, Kengo , date-added =. Supplement to ``gaussian approximation of suprema of empirical processes'' , year =
-
[41]
Generalization error curves for analytic spectral algorithms under power-law decay , year =
Li, Yichen and Gan, Weiye and Shi, Zuoqiang and Lin, Qian , date-added =. Generalization error curves for analytic spectral algorithms under power-law decay , year =
-
[42]
Operator Theory , year =
Simon, Barry , date-added =. Operator Theory , year =
-
[43]
Cross-validation based adaptation for regularization operators in learning theory , volume =
Caponnetto, Andrea and Yao, Yuan , date-added =. Cross-validation based adaptation for regularization operators in learning theory , volume =. Analysis and Applications , number =
-
[44]
Optimal convergence for distributed learning with stochastic gradient methods and spectral algorithms , volume =
Lin, Junhong and Cevher, Volkan , date-added =. Optimal convergence for distributed learning with stochastic gradient methods and spectral algorithms , volume =. Journal of Machine Learning Research , pages =
-
[45]
Sobolev norm learning rates for regularized least-squares algorithms , volume =
Fisher, Simon and Steinwart, Ingo , date-added =. Sobolev norm learning rates for regularized least-squares algorithms , volume =. Journal of Machine Learning Research , pages =
-
[46]
Concentration Inequalities: A Nonasymptotic Theory of Independence , year =
Boucheron, St\'ephane and Lugosi, G\'abor and Massart, Pascal , date-added =. Concentration Inequalities: A Nonasymptotic Theory of Independence , year =
-
[47]
and Wellner, Jon A
Van Der Vaart, Aad W. and Wellner, Jon A. , date-added =. Weak Convergence and Empirical Processes: With Applications to Statistics. Springer , year =
-
[48]
Comparison and anti-concentration bounds for maxima of gaussian random vectors , volume =
Chernozhukov, Victor and Chetverikov, Denis and Kato, Kengo , date-added =. Comparison and anti-concentration bounds for maxima of gaussian random vectors , volume =. Probability Theory and Related Fields , pages =
-
[49]
Gaussian approximation of suprema of empirical processes , volume =
Chernozhukov, Victor and Chetverikov, Denis and Kato, Kengo , date-added =. Gaussian approximation of suprema of empirical processes , volume =. Annals of Statistics , pages =
-
[50]
and Fournier, John J
Adams, Robert A. and Fournier, John J. F. , date-added =. Sobolev Spaces , year =
-
[51]
Theory of Besov Spaces , year =
Sawano, Yoshihiro , date-added =. Theory of Besov Spaces , year =
-
[52]
, date-added =
Tsybakov, Alexandre B. , date-added =. Introduction to Nonparametric Estimation , year =
-
[53]
On the optimality of misspecified kernel ridge regression , year =
Zhang, Haobo and Li, Yichen and Lu, Weihao and Lin, Qian , booktitle =. On the optimality of misspecified kernel ridge regression , year =
-
[54]
High-Dimensional Probability: An Introduction with Applications in Data Science , year =
Vershynin, Roman , date-added =. High-Dimensional Probability: An Introduction with Applications in Data Science , year =
-
[55]
On the optimality of misspecified spectral algorithms , volume =
Zhang, Haobo and Li, Yichen and Lin, Qian , date-added =. On the optimality of misspecified spectral algorithms , volume =. Journal of Machine Learning Research , number =
-
[56]
Generalization ability of wide neural networks on R , year =
Lai, Jianfa and Chen, Rui and Xu, Manyun and Lin, Qian , date-added =. Generalization ability of wide neural networks on R , year =
-
[57]
Optimal rates for spectral algorithms with least-squares regression over Hilbert spaces , volume =
Lin, Junhong and Rudi, Alessandro and Rosasco, Lorenzo and Cevher, Volkan , date-added =. Optimal rates for spectral algorithms with least-squares regression over Hilbert spaces , volume =. Applied and Computational Harmonic Analysis , number =
-
[58]
Optimal rates for the regularized least-squares algorithm , volume =
Caponnetto, Andrea and De Vito, Ernesto , date-added =. Optimal rates for the regularized least-squares algorithm , volume =. Foundations of Computational Mathematics , pages =
-
[59]
On the mathematical foundations of learning , volume =
Cucker, Felipe and Smale, Steve , date-added =. On the mathematical foundations of learning , volume =. Bulletin of the American mathematical society , number =
-
[60]
Mercer's theorem on General domains: On the interaction between measures, kernels, and RKHSs , volume =
Steinwart, Ingo and Scove, Clint , date-added =. Mercer's theorem on General domains: On the interaction between measures, kernels, and RKHSs , volume =. Constructive Approximation , pages =
-
[61]
The Annals of Statistics , volume=
A duality framework for analyzing random feature and two-layer neural networks , author=. The Annals of Statistics , volume=. 2025 , publisher=
2025
-
[62]
Encyclopedia of Computer Science , pages=
Information-based complexity , author=. Encyclopedia of Computer Science , pages=
-
[63]
A non-asymptotic theory of kernel ridge regression: deterministic equivalents, test error, and gcv estimator , author=
-
[64]
Gaussian processes and kernel methods: A review on connections and equivalences , author=
-
[65]
Constructive Approximation , volume=
A characterization of Sobolev spaces on the sphere and an extension of Stolarsky’s invariance principle to arbitrary smoothness , author=. Constructive Approximation , volume=. 2013 , publisher=
2013
-
[66]
2013 , publisher=
Approximation theory and harmonic analysis on spheres and balls , author=. 2013 , publisher=
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.