Recognition: unknown
GazeMind: A Gaze-Guided LLM Agent for Personalized Cognitive Load Assessment
Pith reviewed 2026-05-08 07:28 UTC · model grok-4.3
The pith
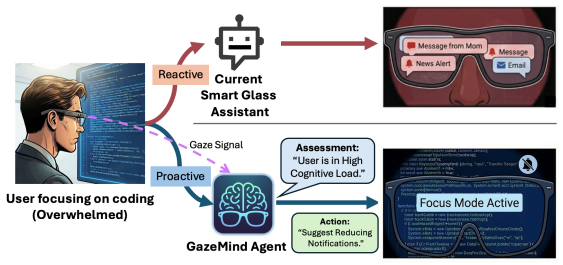
GazeMind lets an off-the-shelf LLM predict cognitive load from structured eye gaze data without fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
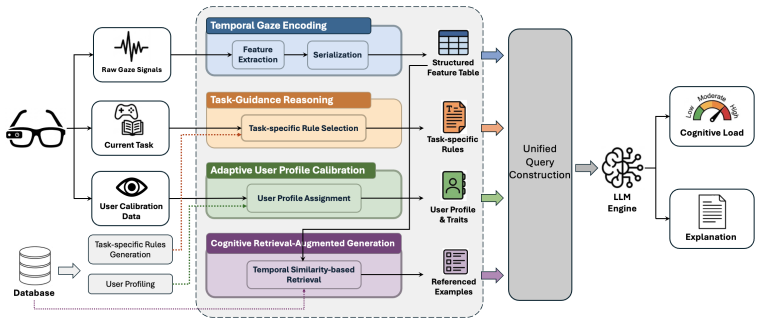
GazeMind encodes eye-tracking data into structured representations for LLM-based reasoning and provides interpretable cognitive load predictions. It generalizes across scenarios without LLM fine-tuning through a novel task-guidance reasoning approach and achieves personalized adaptation by incorporating user-specific characteristics and historical references.
What carries the argument
The structured encoding of eye-tracking data into text representations that an LLM agent processes together with task guidance and user history to output cognitive load estimates.
If this is right
- Cognitive load assessment becomes feasible on everyday smart glasses using only built-in eye tracking and no task-specific model training.
- Predictions can be personalized to each user by referencing their own history while still operating with a single shared LLM.
- The LLM produces human-readable explanations for its load estimates based on observed gaze patterns.
- The same pipeline applies to both controlled laboratory tasks and unstructured real-world activities without retraining.
Where Pith is reading between the lines
- Daily AI assistants on wearables could use the same gaze-to-LLM pipeline to slow down or simplify information when detected mental effort rises.
- Advances in general-purpose language models would immediately improve cognitive monitoring accuracy without requiring new labeled data for each domain.
- The approach might transfer to related internal states such as sustained attention or emotional arousal if their gaze signatures can be similarly structured for the LLM.
Load-bearing premise
That eye-tracking data can be encoded into structured representations that, together with task-guidance reasoning and user history, allow an off-the-shelf LLM to produce accurate and generalizable cognitive-load predictions without any task-specific fine-tuning.
What would settle it
A new experiment in which GazeMind loses its reported performance edge over baselines when tested on users or tasks completely outside the CogLoad-Bench collection would disprove the generalization claim.
Figures









read the original abstract
Smart glasses with AI assistants are increasingly used in daily life. However, current systems lack awareness of the user's internal cognitive state, leaving them unable to proactively anticipate users' needs without access to cognitive load. Existing methods for assessing cognitive load either rely on impractical sensors for lightweight eyewear or utilize eye gaze-based models that suffer from poor interpretability, and require task-specific fine-tuning, often failing to generalize across individuals. We propose GazeMind, a gaze-guided LLM agent framework for cognitive load assessment on smart glasses. It encodes eye-tracking data into structured representations for LLM-based reasoning and provides interpretable cognitive load predictions. Importantly, GazeMind generalizes across scenarios without LLM fine-tuning through a novel task-guidance reasoning approach and achieves personalized adaptation by incorporating user-specific characteristics and historical references. To support evaluation, we introduce CogLoad-Bench, the largest gaze-based cognitive load dataset with 152 participants, 40+ hours of multimodal data, and 10K+ real-time annotations across controlled and real-world tasks. Experiments show that GazeMind achieves state-of-the-art performance, outperforming baselines by over 20% across all metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GazeMind, a gaze-guided LLM agent framework for cognitive load assessment on smart glasses. Eye-tracking data is encoded into structured representations that, together with task-guidance reasoning and user-specific history, enable an off-the-shelf LLM to produce interpretable predictions without any task-specific fine-tuning. A new dataset (CogLoad-Bench) containing 152 participants, >40 hours of multimodal recordings, and >10K real-time annotations is introduced to support evaluation across controlled and real-world tasks. Experiments are reported to show state-of-the-art performance, with >20% gains over baselines on all metrics.
Significance. If the central performance and generalization claims hold, the work would demonstrate a practical route to interpretable, personalized cognitive-load awareness for lightweight wearable AI without per-task retraining. The CogLoad-Bench dataset itself is a substantial resource for the community. The LLM-agent framing also offers a potential advantage in explainability over black-box gaze models, provided the reasoning steps can be inspected.
major comments (3)
- [Methods] Methods section: the gaze-encoding pipeline is described only at a high level. No concrete specification is given for the features extracted (fixation durations, saccade amplitudes/velocities, pupil-diameter statistics, blink rates, or temporal aggregation windows), the exact format of the structured representation passed to the LLM, or the zero-shot vs. few-shot prompting template used for task-guidance reasoning. These omissions are load-bearing because the central claim is that the combination of structured gaze + LLM reasoning generalizes without fine-tuning or implicit task-specific adaptation.
- [Experiments] Experiments section: the paper asserts SOTA results with >20% improvement across all metrics but supplies no list of baselines (including whether they received identical gaze features or user history), no definition of the metrics themselves, no statistical tests (paired t-tests, Wilcoxon, confidence intervals, or multiple-comparison correction), and no per-task or per-user error breakdown. Without these details it is impossible to determine whether the reported gains reflect genuine generalization or differences in information access or evaluation protocol.
- [Dataset and Evaluation] Dataset and Evaluation sections: the held-out protocol is not described (e.g., user-independent split, temporal split, or cross-task generalization). Given that the dataset mixes controlled and real-world tasks, the absence of this information leaves open the possibility that task-specific priors are embedded in the prompting or feature design, undermining the no-fine-tuning generalization claim.
minor comments (3)
- [Abstract] Abstract: the phrase 'outperforming baselines by over 20% across all metrics' should name the metrics (accuracy, F1, MAE, etc.) and the number of baselines.
- [Methods] The paper would benefit from an explicit diagram or pseudocode showing the end-to-end flow from raw gaze stream to final LLM output and explanation.
- [Introduction] Minor notation inconsistencies appear in the description of 'user history' versus 'historical references'; a single consistent term would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and details, thereby strengthening the reproducibility and support for our generalization claims.
read point-by-point responses
-
Referee: [Methods] Methods section: the gaze-encoding pipeline is described only at a high level. No concrete specification is given for the features extracted (fixation durations, saccade amplitudes/velocities, pupil-diameter statistics, blink rates, or temporal aggregation windows), the exact format of the structured representation passed to the LLM, or the zero-shot vs. few-shot prompting template used for task-guidance reasoning. These omissions are load-bearing because the central claim is that the combination of structured gaze + LLM reasoning generalizes without fine-tuning or implicit task-specific adaptation.
Authors: We agree that the current Methods section presents the gaze-encoding pipeline at a high level. In the revised version, we will expand this section with a concrete specification of all extracted features (fixation durations, saccade amplitudes/velocities, pupil-diameter statistics, blink rates, and temporal aggregation windows), the precise structured representation format (e.g., a JSON template with labeled fields) passed to the LLM, and the exact prompting template, including confirmation that task-guidance reasoning uses a zero-shot approach with no task-specific examples or implicit adaptation. These additions will directly support the no-fine-tuning generalization claim by enabling full reproducibility. revision: yes
-
Referee: [Experiments] Experiments section: the paper asserts SOTA results with >20% improvement across all metrics but supplies no list of baselines (including whether they received identical gaze features or user history), no definition of the metrics themselves, no statistical tests (paired t-tests, Wilcoxon, confidence intervals, or multiple-comparison correction), and no per-task or per-user error breakdown. Without these details it is impossible to determine whether the reported gains reflect genuine generalization or differences in information access or evaluation protocol.
Authors: We acknowledge the need for greater transparency in the Experiments section. The revision will include an exhaustive list of baselines with explicit details on the gaze features and user history provided to each; clear definitions of all metrics; results of appropriate statistical tests (paired t-tests with Bonferroni correction, confidence intervals); and per-task and per-user error breakdowns. These additions will confirm that the >20% gains arise from the structured gaze + LLM reasoning combination rather than protocol differences, while preserving the core claim of generalization without fine-tuning. revision: yes
-
Referee: [Dataset and Evaluation] Dataset and Evaluation sections: the held-out protocol is not described (e.g., user-independent split, temporal split, or cross-task generalization). Given that the dataset mixes controlled and real-world tasks, the absence of this information leaves open the possibility that task-specific priors are embedded in the prompting or feature design, undermining the no-fine-tuning generalization claim.
Authors: We appreciate this observation on evaluation protocol clarity. Our experiments employ a user-independent split (no user overlap between train and test) combined with explicit cross-task generalization testing (training on controlled tasks and evaluating on real-world tasks, and vice versa). In the revision, we will describe this protocol in detail, including how splits avoid task-specific leakage and confirm that prompting and features contain no task priors. This will rigorously substantiate the generalization without fine-tuning. revision: yes
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Eye-tracking signals can be converted into structured representations that preserve the information needed for cognitive-load inference.
- domain assumption An unmodified LLM can perform reliable cognitive-load reasoning when given task context and user history.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
Prithila Angkan, Behnam Behinaein, Zunayed Mahmud, Anubhav Bhatti, Dirk Rodenburg, Paul Hungler, and Ali Etemad. Multimodal brain–computer interface for in-vehicle driver cognitive load measurement: Dataset and baselines.IEEE Transactions on Intelligent Transportation Systems, 25(6):5949–5964, 2024
2024
-
[3]
Using electroencephalog- raphy to measure cognitive load.Educational psychology review, 22(4):425–438, 2010
Pavlo Antonenko, Fred Paas, Roland Grabner, and Tamara Van Gog. Using electroencephalog- raphy to measure cognitive load.Educational psychology review, 22(4):425–438, 2010
2010
-
[4]
Multiple levels of mental attentional demand modulate peak saccade velocity and blink rate.Heliyon, 8(1), 2022
Valentina Bachurina and Marie Arsalidou. Multiple levels of mental attentional demand modulate peak saccade velocity and blink rate.Heliyon, 8(1), 2022
2022
-
[5]
Clare: Cognitive load assessment in real-time with multimodal data.IEEE Transactions on Cognitive and Developmental Systems, 2025
Anubhav Bhatti, Prithila Angkan, Behnam Behinaein, Zunayed Mahmud, Dirk Rodenburg, Heather Braund, P James Mclellan, Aaron Ruberto, Geoffery Harrison, Daryl Wilson, et al. Clare: Cognitive load assessment in real-time with multimodal data.IEEE Transactions on Cognitive and Developmental Systems, 2025
2025
-
[6]
Using cognitive psychology to understand gpt-3.Proceedings of the National Academy of Sciences, 120(6):e2218523120, 2023
Marcel Binz and Eric Schulz. Using cognitive psychology to understand gpt-3.Proceedings of the National Academy of Sciences, 120(6):e2218523120, 2023
2023
-
[7]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. InInternational conference on machine learning, pages 2206–2240. PMLR, 2022
2022
-
[8]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[9]
Real-world scanpaths exhibit long-term temporal dependencies: Considerations for contextual ai for ar applications
Charlie S Burlingham, Naveen Sendhilnathan, Xiuyun Wu, T Scott Murdison, and Michael J Proulx. Real-world scanpaths exhibit long-term temporal dependencies: Considerations for contextual ai for ar applications. InProceedings of the 2024 Symposium on Eye Tracking Research and Applications, pages 1–7, 2024
2024
-
[10]
Wenli Chen, Zirou Lin, Lishan Zheng, Mei-Yee Mavis Ho, Farhan Ali, and Wei Peng Teo. Ma- chine learning models to predict individual cognitive load in collaborative learning: Combining fnirs and eye-tracking data.Machine Learning and Knowledge Extraction, 7(2):51, 2025
2025
-
[11]
Francesco Chiossi, Uwe Gruenefeld, Baosheng James Hou, Joshua Newn, Changkun Ou, Rulu Liao, Robin Welsch, and Sven Mayer. Understanding the impact of the reality-virtuality contin- uum on visual search using fixation-related potentials and eye tracking features.Proceedings of the ACM on Human-Computer Interaction, 8(MHCI):1–33, 2024
2024
-
[12]
Hybrid methodology: combining ethnography, cognitive science, and machine learning to inform the development of context-aware personal computing and assistive technol- ogy
Maria Cury, Eryn Whitworth, Sebastian Barfort, Séréna Bochereau, Jonathan Browder, Tanya R Jonker, Kahyun Sophie Kim, Mikkel Krenchel, MORGAN RAMSEY-ELLIOT, Friederike Schüür, et al. Hybrid methodology: combining ethnography, cognitive science, and machine learning to inform the development of context-aware personal computing and assistive technol- ogy. I...
2019
-
[13]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. A survey on in-context learning. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 1107–1128, 2024
2024
-
[14]
Sage, 1989
George H Dunteman.Principal components analysis, volume 69. Sage, 1989
1989
-
[15]
Prediction of intrinsic and extraneous cognitive load with oculometric and biometric indicators
Merve Ekin, Krzysztof Krejtz, Carlos Duarte, Andrew T Duchowski, and Izabela Krejtz. Prediction of intrinsic and extraneous cognitive load with oculometric and biometric indicators. Scientific Reports, 15(1):5213, 2025. 10
2025
-
[16]
Project Aria: A New Tool for Egocentric Multi-Modal AI Research
Jakob Engel, Kiran Somasundaram, Michael Goesele, Albert Sun, Alexander Gamino, Andrew Turner, Arjang Talattof, Arnie Yuan, Bilal Souti, Brighid Meredith, et al. Project aria: A new tool for egocentric multi-modal ai research.arXiv preprint arXiv:2308.13561, 2023
work page internal anchor Pith review arXiv 2023
-
[17]
Cognitive load estimation in the wild
Lex Fridman, Bryan Reimer, Bruce Mehler, and William T Freeman. Cognitive load estimation in the wild. InProceedings of the 2018 chi conference on human factors in computing systems, pages 1–9, 2018
2018
-
[18]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[19]
Algorithm as 136: A k-means clustering algorithm
John A Hartigan and Manchek A Wong. Algorithm as 136: A k-means clustering algorithm. Journal of the royal statistical society. series c (applied statistics), 28(1):100–108, 1979
1979
-
[20]
oup Oxford, 2011
Kenneth Holmqvist, Marcus Nyström, Richard Andersson, Richard Dewhurst, Halszka Jarodzka, and Joost Van de Weijer.Eye tracking: A comprehensive guide to methods and measures. oup Oxford, 2011
2011
-
[21]
arXiv preprint arXiv:2310.01728 , year=
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, et al. Time-llm: Time series forecasting by reprogramming large language models.arXiv preprint arXiv:2310.01728, 2023
-
[22]
Applications of smart glasses in applied sciences: A systematic review.Applied Sciences, 11(11):4956, 2021
Dawon Kim and Yosoon Choi. Applications of smart glasses in applied sciences: A systematic review.Applied Sciences, 11(11):4956, 2021
2021
-
[23]
A survey on measuring cognitive workload in human-computer interaction
Thomas Kosch, Jakob Karolus, Johannes Zagermann, Harald Reiterer, Albrecht Schmidt, and Paweł W Wo´ zniak. A survey on measuring cognitive workload in human-computer interaction. ACM Computing Surveys, 55(13s):1–39, 2023
2023
-
[24]
Colet: A dataset for cognitive workload estimation based on eye-tracking.Computer Methods and Programs in Biomedicine, 224: 106989, 2022
Emmanouil Ktistakis, Vasileios Skaramagkas, Dimitris Manousos, Nikolaos S Tachos, Evanthia Tripoliti, Dimitrios I Fotiadis, and Manolis Tsiknakis. Colet: A dataset for cognitive workload estimation based on eye-tracking.Computer Methods and Programs in Biomedicine, 224: 106989, 2022
2022
-
[25]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[26]
Qingchuan Li, Yan Luximon, Jiaxin Zhang, and Yao Song. Measuring and classifying students’ cognitive load in pen-based mobile learning using handwriting, touch gestural and eye-tracking data.British Journal of Educational Technology, 55(2):625–653, 2024
2024
-
[27]
Enabling eye tracking for crowd- sourced data collection with project aria.IEEE Access, 2025
Yusuf Mansour, Ajoy Savio Fernandes, Kiran Somasundaram, Tarek Hefny, Mahsa Shakeri, Oleg Komogortsev, Abhishek Sharma, and Michael J Proulx. Enabling eye tracking for crowd- sourced data collection with project aria.IEEE Access, 2025
2025
-
[28]
Em-cogload: An investigation into age and cognitive load detection using eye tracking and deep learning.Computational and Structural Biotechnology Journal, 24:264–280, 2024
Gabriella Miles, Melvyn Smith, Nancy Zook, and Wenhao Zhang. Em-cogload: An investigation into age and cognitive load detection using eye tracking and deep learning.Computational and Structural Biotechnology Journal, 24:264–280, 2024
2024
-
[29]
Gaze-language alignment for zero-shot prediction of visual search targets from human gaze scanpaths
Sounak Mondal, Naveen Sendhilnathan, Ting Zhang, Yue Liu, Michael Proulx, Michael Louis Iuzzolino, Chuan Qin, and Tanya R Jonker. Gaze-language alignment for zero-shot prediction of visual search targets from human gaze scanpaths. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2738–2749, 2025
2025
-
[30]
Eye-cog: Eye tracking-based deep learning model for the detection of cognitive impairments in college students
U Nishitha, Revanth Kandimalla, C Jyotsna, Tripty Singh, et al. Eye-cog: Eye tracking-based deep learning model for the detection of cognitive impairments in college students. In2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), pages 1–7. IEEE, 2023
2023
-
[31]
Training strategies for attaining transfer of problem-solving skill in statistics: a cognitive-load approach.Journal of educational psychology, 84(4):429, 1992
Fred GWC Paas. Training strategies for attaining transfer of problem-solving skill in statistics: a cognitive-load approach.Journal of educational psychology, 84(4):429, 1992. 11
1992
-
[32]
Response time and eye tracking datasets for activities demanding varying cognitive load.Data in brief, 33:106389, 2020
Prarthana Pillai, Prathamesh Ayare, Balakumar Balasingam, Kevin Milne, and Francesco Biondi. Response time and eye tracking datasets for activities demanding varying cognitive load.Data in brief, 33:106389, 2020
2020
-
[33]
Cognitive load theory
Jan L Plass, Roxana Moreno, and Roland Brünken. Cognitive load theory. 2010
2010
-
[34]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning, pages 28492–28518. PMLR, 2023
2023
-
[35]
Vision-based driver’s cognitive load classification considering eye movement using machine learning and deep learning.Sensors, 21(23):8019, 2021
Hamidur Rahman, Mobyen Uddin Ahmed, Shaibal Barua, Peter Funk, and Shahina Begum. Vision-based driver’s cognitive load classification considering eye movement using machine learning and deep learning.Sensors, 21(23):8019, 2021
2021
-
[36]
Mehedi Hasan Raju and Oleg V Komogortsev. Real-time lightweight gaze privacy- preservation techniques validated via offline gaze-based interaction simulation.arXiv preprint arXiv:2511.09846, 2025
-
[37]
Augmented reality smart glasses: An investigation of technology acceptance drivers.International Journal of Technology Marketing, 11(2):123–148, 2016
Philipp A Rauschnabel and Young K Ro. Augmented reality smart glasses: An investigation of technology acceptance drivers.International Journal of Technology Marketing, 11(2):123–148, 2016
2016
-
[38]
Eye movements in reading and information processing: 20 years of research
Keith Rayner. Eye movements in reading and information processing: 20 years of research. Psychological bulletin, 124(3):372, 1998
1998
-
[39]
A machine learning approach for detecting cognitive interference based on eye-tracking data.Frontiers in Human Neuroscience, 16:806330, 2022
Antonio Rizzo, Sara Ermini, Dario Zanca, Dario Bernabini, and Alessandro Rossi. A machine learning approach for detecting cognitive interference based on eye-tracking data.Frontiers in Human Neuroscience, 16:806330, 2022
2022
-
[40]
Lamp: When large language models meet personalization
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. Lamp: When large language models meet personalization. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7370–7392, 2024
2024
-
[41]
Identifying fixations and saccades in eye-tracking protocols
Dario D Salvucci and Joseph H Goldberg. Identifying fixations and saccades in eye-tracking protocols. InProceedings of the 2000 symposium on Eye tracking research & applications, pages 71–78, 2000
2000
-
[42]
Implicit gaze research for xr systems.arXiv preprint arXiv:2405.13878, 2024
Naveen Sendhilnathan, Ajoy S Fernandes, Michael J Proulx, and Tanya R Jonker. Implicit gaze research for xr systems.arXiv preprint arXiv:2405.13878, 2024
-
[43]
Natalia Sevcenko, Tobias Appel, Manuel Ninaus, Korbinian Moeller, and Peter Gerjets. Theory- based approach for assessing cognitive load during time-critical resource-managing human– computer interactions: an eye-tracking study.Journal on Multimodal User Interfaces, 17(1): 1–19, 2023
2023
-
[44]
Cognitive workload level estimation based on eye tracking: A machine learning approach
Vasileios Skaramagkas, Emmanouil Ktistakis, Dimitris Manousos, Nikolaos S Tachos, Eleni Kazantzaki, Evanthia E Tripoliti, Dimitrios I Fotiadis, and Manolis Tsiknakis. Cognitive workload level estimation based on eye tracking: A machine learning approach. In2021 IEEE 21st International Conference on Bioinformatics and Bioengineering (BIBE), pages 1–5. IEEE, 2021
2021
-
[45]
Ben Steichen, Cristina Conati, and Giuseppe Carenini. Inferring visualization task properties, user performance, and user cognitive abilities from eye gaze data.ACM Transactions on Interactive Intelligent Systems (TiiS), 4(2):1–29, 2014
2014
-
[46]
Pupil dilation as an index of effort in cognitive control tasks: A review.Psychonomic bulletin & review, 25(6):2005–2015, 2018
Pauline Van der Wel and Henk Van Steenbergen. Pupil dilation as an index of effort in cognitive control tasks: A review.Psychonomic bulletin & review, 25(6):2005–2015, 2018
2005
-
[47]
Tuning down the emotional brain: an fmri study of the effects of cognitive load on the processing of affective images.Neuroimage, 45(4):1212–1219, 2009
Lotte F Van Dillen, Dirk J Heslenfeld, and Sander L Koole. Tuning down the emotional brain: an fmri study of the effects of cognitive load on the processing of affective images.Neuroimage, 45(4):1212–1219, 2009
2009
-
[48]
Timing and frequency of mental effort measurement: Evidence in favour of repeated measures.Applied cognitive psychology, 26(6):833–839, 2012
Tamara Van Gog, Femke Kirschner, Liesbeth Kester, and Fred Paas. Timing and frequency of mental effort measurement: Evidence in favour of repeated measures.Applied cognitive psychology, 26(6):833–839, 2012. 12
2012
-
[49]
Gazesam: Interac- tive image segmentation with eye gaze and segment anything model
Bin Wang, Armstrong Aboah, Zheyuan Zhang, Hongyi Pan, and Ulas Bagci. Gazesam: Interac- tive image segmentation with eye gaze and segment anything model. InGaze Meets Machine Learning Workshop, pages 254–265. PMLR, 2024
2024
-
[50]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[51]
Classification of cognitive load using deep learning based on eye movement indices.IEEE Access, 2025
Sunu Wibirama, Syukron Abu Ishaq Alfarozi, Ahmad Riznandi Suhari, Ayuningtyas Hari Fristiana, Hafzatin Nurlatifa, and Paulus Insap Santosa. Classification of cognitive load using deep learning based on eye movement indices.IEEE Access, 2025
2025
-
[52]
Multiple resources and mental workload.Human factors, 50(3): 449–455, 2008
Christopher D Wickens. Multiple resources and mental workload.Human factors, 50(3): 449–455, 2008
2008
-
[53]
Ethan Wilson, Azim Ibragimov, Michael J Proulx, Sai Deep Tetali, Kevin Butler, and Eakta Jain. Privacy-preserving gaze data streaming in immersive interactive virtual reality: Robustness and user experience.IEEE Transactions on Visualization and Computer Graphics, 30(5):2257–2268, 2024
2024
-
[54]
Eye gaze as a signal for conveying user attention in contextual ai systems
Ethan Wilson, Naveen Sendhilnathan, Charlie S Burlingham, Yusuf Mansour, Robert Cavin, Sai Deep Tetali, Ajoy Savio Fernandes, and Michael J Proulx. Eye gaze as a signal for conveying user attention in contextual ai systems. InProceedings of the 2025 Symposium on Eye Tracking Research and Applications, pages 1–7, 2025
2025
-
[55]
cross-task generalization
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, et al. A survey on large language models for recommendation. World Wide Web, 27(5):60, 2024. 13 Appendix The appendix of this paper includes: Appendix A: Analysis of source of performance gain, fairness comparison with LLM and non-LLM methods...
2024
-
[56]
Normal state
Magnitude: * Near 0.0 (-0.5 to +0.5): Baseline behavior. Normal state. * Significant Deviation (> +1.0 or < -1.0): A strong physiological signal. * Extreme Deviation (> +2.5 or < -2.5): Very intense event
-
[57]
Low Load
Direction: * Positive (+): Value is Higher/Longer/More Frequent than usual. * Negative (-): Value is Lower/Shorter/Suppressed compared to usual. * WARNING: A Negative Z-Score does NOT automatically mean "Low Load". In some tasks, "Shorter" fixations (Negative Z) often indicate High Load. ## Feature Definitions * fix_dur: Duration of fixations. (Pos=Long S...
-
[58]
Standard Rules are concluded based on the global population
-
[59]
What day is two days after the day before Thursday?
User Profile & Calibration Instructions give guidance to adjust some specific guidance in the Standard Rules. ## Reference Data Verification Protocol You will receive Reference Data containing REAL historical examples from similar users. These examples are retrieved based on mathematical similarity to the current session feature. You must qualitatively va...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.