Recognition: unknown
Selective Rollout: Mid-Trajectory Termination for Multi-Sample Agent RL
Pith reviewed 2026-05-09 15:28 UTC · model grok-4.3
The pith
A gate on mean pairwise prefix edit distance stops redundant parallel rollouts early in group-relative agent RL, cutting wall-clock time while reducing zero-advantage gradient dilution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
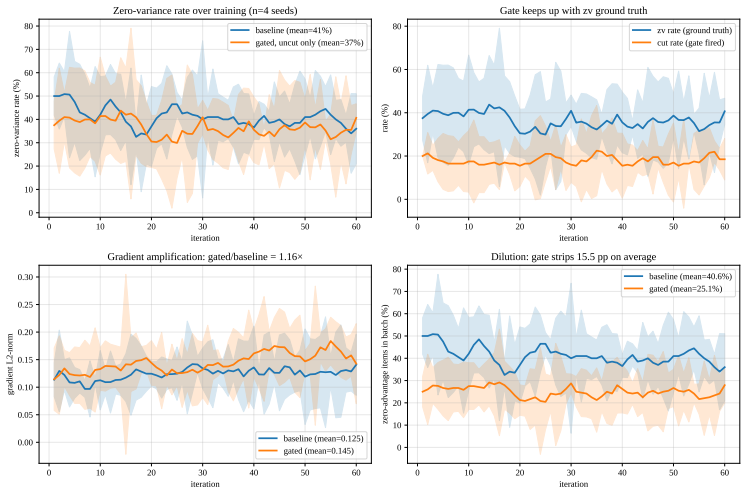
The central claim is that low mean pairwise prefix edit distance among partial trajectories at an intermediate step reliably signals that the group will produce identical final rewards, so the remaining rollout steps can be terminated without discarding useful gradient signal. The method implements this prediction with a one-parameter gate that halts the entire group once the distance falls below threshold. On a 60-iteration on-policy GRPO run the gated arm finishes faster and improves held-out success, the improvement attributed to measurable reduction in zero-advantage gradient-batch dilution.
What carries the argument
The one-parameter gate that terminates a rollout group once its mean pairwise prefix edit distance on partial action sequences falls below a fixed threshold.
If this is right
- Wall-clock training time decreases because groups that would have been zero-variance are not fully generated.
- The fraction of gradient batches that contain only zero-advantage examples shrinks, reducing dilution of the policy update.
- Held-out success on unseen tasks rises modestly because the optimizer sees a cleaner distribution of nonzero-advantage signals.
- The wasted-compute fraction that is typical in multi-sample agent RL (around 40 percent of groups) is trimmed at the trajectory level rather than only at the prompt level.
Where Pith is reading between the lines
- The same early-divergence check could be applied in other multi-sample RL regimes that currently pay for full trajectories before checking variance.
- Replacing edit distance with a cheaper or more predictive similarity measure might increase the fraction of groups stopped early without raising false-positive terminations.
- In environments whose horizon is longer than ALFWorld the absolute time saving per terminated group would be larger, scaling with the number of avoided LLM calls.
Load-bearing premise
Low mean pairwise prefix edit distance at an intermediate step means the remaining steps will not produce different final rewards across the group.
What would settle it
Run the full unterminated rollouts on a subset of groups that the gate would have stopped, then check whether any of those groups later exhibits nonzero reward variance.
Figures

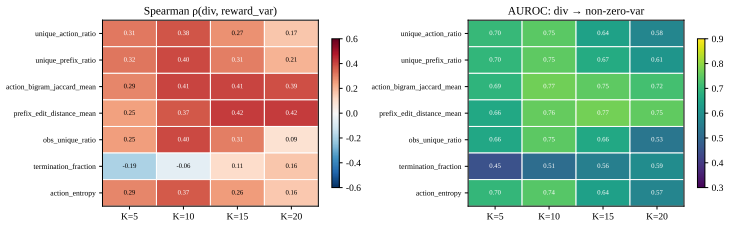
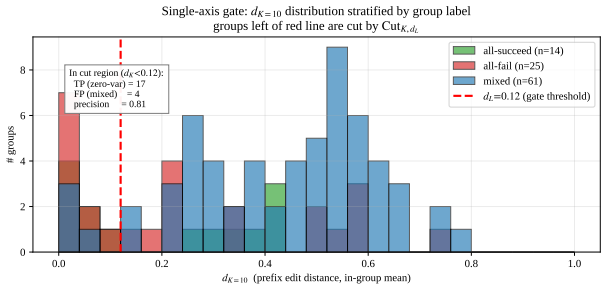
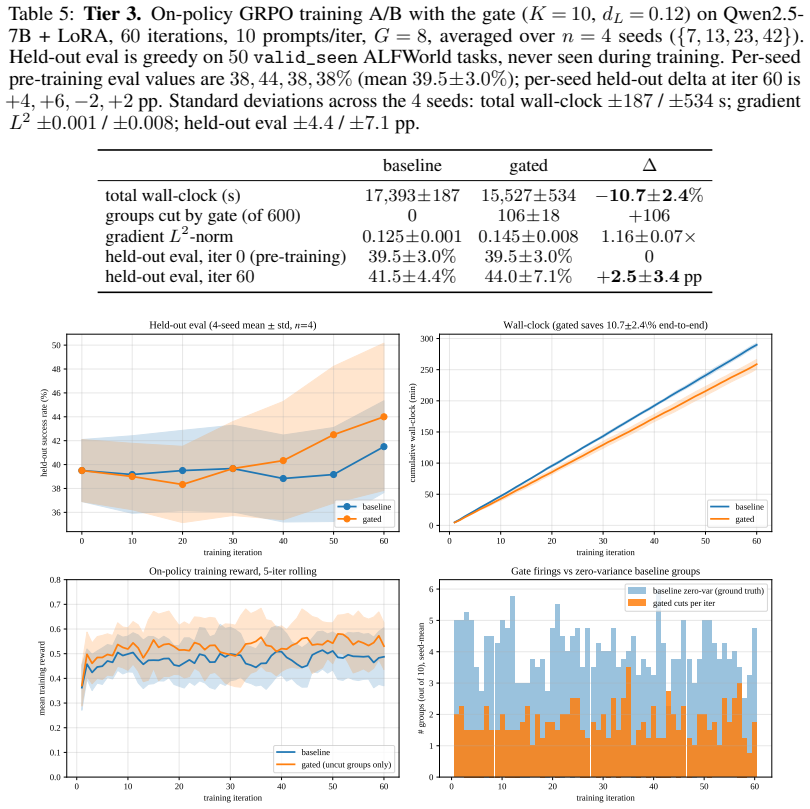

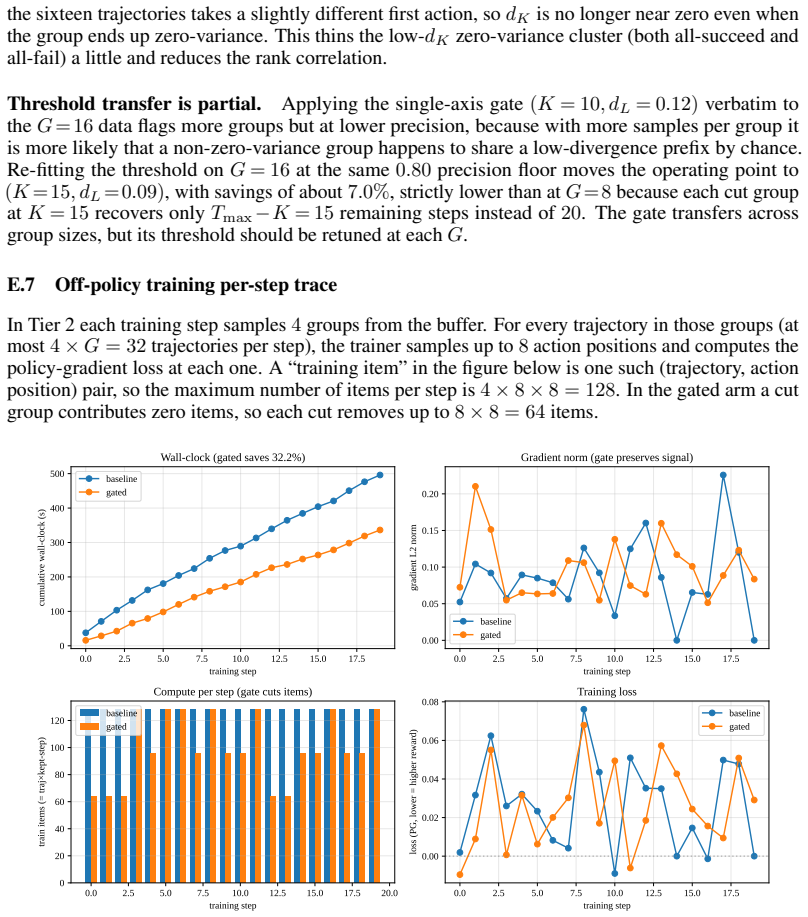
read the original abstract
Group-relative RL training (GRPO) samples a small group of parallel rollouts for every training prompt and uses their within-group reward spread to compute per-trajectory advantages. In agentic environments each rollout is a long multi-turn dialogue with one LLM call per step, so this multi-sample multiplier dominates the total training cost. When every rollout of a prompt ends with the same reward, the group has zero reward variance and contributes no gradient, so the extra rollouts add no information; such groups are common in practice (typically around 40% of all groups), so the wasted-compute fraction is substantial rather than marginal. Existing methods filter such groups at the prompt level, either after their rollouts are paid for or before any rollout begins, but both decide without using information that becomes available during the rollout itself. We instead ask whether the in-group divergence between the partial trajectories at an intermediate step can already predict that the group will be zero-variance: when the parallel rollouts have already converged on the same action prefix, the group is on track to produce a single reward, and we can stop early. We propose a one-parameter gate that stops a group when the mean pairwise prefix edit distance between its partial action sequences falls below a threshold. On a 60-iteration on-policy GRPO run on ALFWorld with Qwen2.5-7B, averaged over four random seeds, the gated arm finishes 10.7% faster in wall-clock (bootstrap 95% CI excludes 0) and shifts held-out success rate on 50 unseen tasks by +2.5 pp, with the held-out gain tracing to a measurable reduction in zero-advantage gradient-batch dilution. Code is available at https://github.com/zhiyuanZhai20/selective-rollout.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Selective Rollout, a one-parameter heuristic for early termination of parallel rollout groups during on-policy GRPO training of LLM agents. The gate stops a group when the mean pairwise prefix edit distance among its partial action sequences falls below a threshold, under the claim that this predicts zero within-group reward variance and thus no useful gradient. On a 60-iteration GRPO run on ALFWorld with Qwen2.5-7B (4 seeds), the method yields 10.7% wall-clock speedup (bootstrap 95% CI excludes zero) and +2.5 pp held-out success rate on 50 unseen tasks, attributed to reduced zero-advantage batch dilution. Code is released.
Significance. If the core predictor is reliable, the technique offers a practical reduction in the dominant multi-sample cost of long-horizon agent RL without performance degradation. The released code, use of held-out tasks, and bootstrap CI on the primary efficiency metric are strengths that support reproducibility and allow direct follow-up. The result would be of moderate interest to the RL-for-LLMs community if the assumption that low prefix divergence implies identical final rewards is shown to hold with low false-positive rate.
major comments (2)
- [Experiments] Abstract and Experiments section: the central attribution of the +2.5 pp held-out gain to 'reduced zero-advantage gradient-batch dilution' presupposes that the edit-distance gate introduces negligible false positives. No result quantifies the reward variance or success-rate difference that would have been observed had terminated groups continued, so it remains possible that informative trajectories were discarded and the on-policy update operated on a biased subset.
- [Method] Method section: the threshold is a single free parameter whose value is not accompanied by a sensitivity analysis or false-positive characterization on the training distribution. Because the reported gains are measured after threshold selection, an ablation showing how performance and speedup vary with the threshold (and whether the held-out improvement remains when the threshold is fixed before seeing any training data) is needed to establish that the result is not an artifact of post-hoc tuning.
minor comments (2)
- The abstract reports a bootstrap CI only for wall-clock time; adding the corresponding interval or a paired statistical test for the +2.5 pp success-rate shift would make the performance claim easier to interpret.
- [Method] Notation for the mean pairwise prefix edit distance is introduced without an explicit equation or pseudocode; a short formal definition would improve clarity for readers implementing the gate.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, acknowledging where the manuscript is currently limited and outlining targeted revisions that will strengthen the claims without altering the core results.
read point-by-point responses
-
Referee: [Experiments] Abstract and Experiments section: the central attribution of the +2.5 pp held-out gain to 'reduced zero-advantage gradient-batch dilution' presupposes that the edit-distance gate introduces negligible false positives. No result quantifies the reward variance or success-rate difference that would have been observed had terminated groups continued, so it remains possible that informative trajectories were discarded and the on-policy update operated on a biased subset.
Authors: We agree that the current attribution would be more robust with explicit evidence that the gate does not systematically discard groups with non-zero reward variance. The manuscript reports the observed reduction in zero-advantage batches and the corresponding held-out improvement, but does not include a direct counterfactual or false-positive characterization. In the revised manuscript we will add a new analysis (in the Experiments section or appendix) that quantifies the empirical false-positive rate: we will either continue a modest number of terminated groups in follow-up runs or post-hoc compute within-group reward variance for all low-divergence prefixes observed during the original training. We will report the fraction of terminated groups that would have produced non-zero variance and update the abstract and discussion to qualify the causal attribution accordingly. revision: yes
-
Referee: [Method] Method section: the threshold is a single free parameter whose value is not accompanied by a sensitivity analysis or false-positive characterization on the training distribution. Because the reported gains are measured after threshold selection, an ablation showing how performance and speedup vary with the threshold (and whether the held-out improvement remains when the threshold is fixed before seeing any training data) is needed to establish that the result is not an artifact of post-hoc tuning.
Authors: We acknowledge that the reported results use a threshold chosen after inspecting the training runs, and that a sensitivity study is required to rule out overfitting to the particular value. In the revision we will add a sensitivity plot (new figure in Experiments) showing wall-clock speedup and held-out success rate across a range of threshold values. We will also include results from an additional experiment in which the threshold is fixed a priori (e.g., from a small pilot set collected before the main 60-iteration runs) and confirm that the efficiency and accuracy gains remain statistically significant. This will demonstrate robustness and address the post-hoc selection concern. revision: yes
Circularity Check
No circularity; heuristic gate with empirical held-out validation
full rationale
The paper defines a one-parameter heuristic early-termination rule for GRPO rollout groups using mean pairwise prefix edit distance, then reports wall-clock and held-out success improvements from direct experiments on ALFWorld with Qwen2.5-7B across random seeds. No derivation, equation, or self-citation reduces the claimed gains or the zero-variance prediction to a fitted quantity by construction; the core assumption is presented as an empirical observation rather than a tautology, and results are measured on unseen tasks with traceable attribution to reduced zero-advantage batches.
Axiom & Free-Parameter Ledger
free parameters (1)
- edit distance threshold
axioms (1)
- domain assumption Low mean pairwise prefix edit distance at an intermediate step implies that the remaining rollouts will converge to the same final reward.
invented entities (1)
-
selective rollout gate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems, 2022
2022
-
[4]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
Alfworld: Aligning text and embodied environments for interactive learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning. In International Conference on Learning Representations (ICLR), 2021
2021
-
[6]
Webshop: Towards scalable real-world web interaction with grounded language agents
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents. InAdvances in Neural Information Processing Systems, 2022
2022
-
[7]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[8]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen
Haizhong Zheng, Yang Zhou, Brian R. Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen. Act only when it pays: Efficient reinforcement learning for llm reasoning via selective rollouts.arXiv preprint arXiv:2506.02177, 2025
-
[10]
Williams
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8:229–256, 1992
1992
-
[11]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Levenshtein
Vladimir I. Levenshtein. Binary codes capable of correcting deletions, insertions, and reversals. Soviet Physics Doklady, 10(8):707–710, 1966
1966
-
[13]
Bootstrap methods: Another look at the jackknife.The Annals of Statistics, 7(1):1–26, 1979
Bradley Efron. Bootstrap methods: Another look at the jackknife.The Annals of Statistics, 7(1):1–26, 1979
1979
-
[14]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[15]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational Conference on Machine Learning (ICML), pages 1889–1897, 2015
2015
-
[16]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement learning: An introduction. MIT Press, second edition, 2018
2018
-
[17]
Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 12248–12267, 2024
2024
-
[18]
Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models
Ziniu Li, Tian Xu, Yushun Zhang, Zhihang Lin, Yang Yu, Ruoyu Sun, and Zhi-Quan Luo. Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models. InInternational Conference on Machine Learning (ICML), 2024. 10
2024
-
[19]
Understanding r1-zero-like training: A critical perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. InConference on Language Modeling (COLM), 2025
2025
-
[20]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu. Reinforce++: A simple and efficient approach for aligning large language models. arXiv preprint arXiv:2501.03262, 2025
work page internal anchor Pith review arXiv 2025
-
[21]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, 2017
2017
-
[22]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F. Christiano. Learning to summarize with human feedback. In Advances in Neural Information Processing Systems, 2020
2020
-
[23]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, 2023
2023
-
[24]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, John Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Rlaif vs
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, et al. Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[26]
Curriculum learning
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the 26th Annual International Conference on Machine Learning (ICML), pages 41–48, 2009
2009
-
[27]
Bellemare, Jacob Menick, Rémi Munos, and Koray Kavukcuoglu
Alex Graves, Marc G. Bellemare, Jacob Menick, Rémi Munos, and Koray Kavukcuoglu. Automated curriculum learning for neural networks. InInternational Conference on Machine Learning (ICML), pages 1311–1320, 2017
2017
-
[28]
Tran, Yi Tay, and Donald Metzler
Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Q. Tran, Yi Tay, and Donald Metzler. Confident adaptive language modeling. InAdvances in Neural Information Processing Systems, 2022
2022
-
[29]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning (ICML), pages 19274– 19286, 2023
2023
-
[30]
Accelerating Large Language Model Decoding with Speculative Sampling
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review arXiv 2023
-
[31]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[32]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review arXiv 2021
-
[33]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[34]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[35]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Systems, 2023. 11
2023
-
[36]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, 2023
2023
-
[37]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems, 2023
2023
-
[38]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[39]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. Transactions on Machine Learning Research, 2024
2024
-
[40]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[41]
Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, 2022
2022
-
[42]
arXiv preprint arXiv:2207.00747 , year=
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. Rationale- augmented ensembles in language models.arXiv preprint arXiv:2207.00747, 2022
-
[43]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[44]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[45]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[46]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. Star: Bootstrapping reasoning with reasoning. InAdvances in Neural Information Processing Systems, 2022
2022
-
[47]
Reinforced Self-Training (ReST) for Language Modeling
Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, et al. Reinforced self-training (rest) for language modeling.arXiv preprint arXiv:2308.08998, 2023
work page Pith review arXiv 2023
-
[48]
Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J
Avi Singh, John D. Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J. Liu, James Harrison, Jaehoon Lee, Kelvin Xu, et al. Beyond human data: Scaling self-training for problem-solving with language models.Transactions on Machine Learning Research, 2024
2024
-
[49]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[50]
Qlora: Efficient finetuning of quantized llms
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. InAdvances in Neural Information Processing Systems, 2023
2023
-
[51]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP), pages 611–626, 2023
2023
-
[52]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. InAdvances in Neural Information Processing Systems, 2022
2022
-
[53]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. In International Conference on Learning Representations (ICLR), 2024. 12
2024
-
[54]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads. In International Conference on Machine Learning (ICML), 2024
2024
-
[55]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, 2020
2020
-
[56]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Transformers: State-of-the-art natural language processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, 2020. 13 A Related...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.