Recognition: unknown
Unified Value Alignment for Generative Recommendation in Industrial Advertising
Pith reviewed 2026-05-08 06:02 UTC · model grok-4.3
The pith
A unified framework embeds commercial value into every stage of generative advertising recommendation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that value signals can be injected into SID tokenization, fused into next-token generation via joint supervised and eCPM-aware RL training, and reused as guidance in personalized beam search, thereby aligning user interest and commercial value inside one generative recommendation pipeline.
What carries the argument
The Commercial SID tokenizer that injects value-related attributes into SID construction together with the Generation-as-Ranking SID Decoder that is jointly optimized by supervised learning and eCPM-aware reinforcement learning.
If this is right
- Generation and ranking become a single decoding process instead of separate stages.
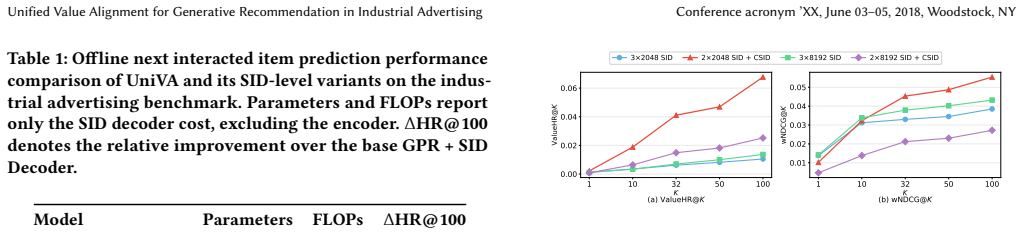
- Offline Hit Rate@100 rises 37.04 percent over a semantics-only baseline.
- Online gross merchandise value increases 1.5 percent in A/B tests on the production platform.
- The same decoder logits serve as both generation probabilities and real-time value guidance.
Where Pith is reading between the lines
- The same injection-plus-RL pattern could be tested on other multi-objective recommendation domains such as news or video feed ranking.
- Unifying the stages may reduce serving latency compared with cascaded interest-then-value pipelines.
- If value injection proves robust, the framework could be applied to non-advertising generative recommenders that must balance multiple business constraints.
Load-bearing premise
Value-related attributes can be injected into SID tokenization and fused via RL without substantially harming the semantic quality or user-interest alignment of the generated recommendations.
What would settle it
An ablation that removes the value-injection and RL components while keeping the same generative architecture and tokenizer vocabulary, then measures whether offline Hit Rate@100 and online GMV both drop relative to the full UniVA system.
Figures


read the original abstract
Generative Recommendation (GR) reformulates recommendation as a next-token generation problem and has shown promise in industrial applications. However, extending GR to industrial advertising is non-trivial because the system must optimize not only user interest but also commercial value. Existing GR pipelines remain largely semantics-centric, making it difficult to align value signals across tokenization, decoding, and online serving. To address this issue, we propose UniVA, a Unified Value Alignment framework for advertising recommendation. We first introduce a Commercial SID tokenizer that injects value-related attributes into SID construction, yielding value-discriminative item representations. We then develop a Generation-as-Ranking SID Decoder jointly optimized by supervised learning and eCPM-aware reinforcement learning, which fuses value scores into next-item SID generation to perform generation and ranking in one decoding process. Finally, we design a value-guided personalized beam search that reuses generation-as-ranking logits as online value guidance and applies a personalized trie tree to constrain decoding to request-valid SID paths. Experiments on the Tencent WeChat Channels advertising platform show that UniVA achieves a 37.04\% improvement in offline Hit Rate@100 over the baseline and a 1.5\% GMV lift in online A/B tests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents UniVA, a Unified Value Alignment framework for generative recommendation in industrial advertising. It introduces a Commercial SID tokenizer that injects value-related attributes into item representations, a Generation-as-Ranking SID Decoder jointly optimized via supervised learning and eCPM-aware reinforcement learning to fuse value scores during next-item generation, and a value-guided personalized beam search that reuses decoder logits with a trie tree for valid paths. Experiments on the Tencent WeChat Channels advertising platform report a 37.04% offline Hit Rate@100 improvement over baseline and a 1.5% GMV lift in online A/B tests.
Significance. If the empirical results hold after providing full experimental details, the work would be significant for industrial recommender systems by demonstrating a practical end-to-end method to align generative models with both user interest and commercial value (e.g., eCPM). The unified treatment across tokenization, decoding, and serving stages addresses a real deployment gap, and the online A/B test offers credible real-world evidence. The approach could influence production advertising systems if the gains prove robust and non-circular.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: The 37.04% Hit Rate@100 lift and 1.5% GMV gain are presented without baseline architecture details, training/validation splits, number of runs, variance estimates, or statistical tests. These omissions are load-bearing because the central claim rests entirely on the magnitude and attribution of these lifts; without them it is impossible to rule out post-hoc selection or implementation differences.
- [§3.2] Generation-as-Ranking SID Decoder (described in §3.2): The eCPM-aware RL reward is said to fuse value scores into generation, yet no equation or pseudocode shows whether the reward uses the same platform eCPM signals that appear in the online GMV metric. If the reward directly incorporates the evaluation objective, the reported GMV lift risks circularity and cannot be interpreted as independent evidence of improved value alignment.
minor comments (2)
- [Introduction] The expansion of SID (Semantic ID) is not given on first use in the abstract or introduction, and the precise tokenization algorithm for injecting commercial attributes is only sketched at high level; a short formal definition or pseudocode would improve clarity.
- [Figures and Tables] Figure captions and table headers use inconsistent capitalization and occasionally omit units (e.g., for GMV lift); these are minor but reduce readability for an industrial paper.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater experimental transparency and clarification on the RL reward design. We address each major comment below and will revise the manuscript to strengthen the presentation of results and methods.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The 37.04% Hit Rate@100 lift and 1.5% GMV gain are presented without baseline architecture details, training/validation splits, number of runs, variance estimates, or statistical tests. These omissions are load-bearing because the central claim rests entirely on the magnitude and attribution of these lifts; without them it is impossible to rule out post-hoc selection or implementation differences.
Authors: We agree that the current presentation of results would benefit from additional details to allow full assessment of robustness. The Experiments section (§4) already specifies the baseline architectures (including semantic-only SID models and standard generative recommenders) and the overall dataset construction from Tencent WeChat Channels logs. However, we acknowledge the absence of explicit reporting on train/validation splits, number of runs, variance, and statistical tests. In the revised version we will add a new subsection in §4 with a table reporting these elements, including standard deviations across runs and p-values for the reported lifts, to substantiate the 37.04% Hit Rate@100 and 1.5% GMV improvements. revision: yes
-
Referee: [§3.2] Generation-as-Ranking SID Decoder (described in §3.2): The eCPM-aware RL reward is said to fuse value scores into generation, yet no equation or pseudocode shows whether the reward uses the same platform eCPM signals that appear in the online GMV metric. If the reward directly incorporates the evaluation objective, the reported GMV lift risks circularity and cannot be interpreted as independent evidence of improved value alignment.
Authors: This is a valid concern about potential circularity. The eCPM signal used in the RL reward is a model-predicted value score computed from historical training data (user engagement and ad performance logs available at training time), not the live platform eCPM or GMV observed during online A/B testing. The reward encourages the decoder to favor high-value SID paths based on learned patterns, while the online GMV lift reflects actual post-deployment revenue from user conversions, which is measured independently. To make this separation explicit, we will insert the precise reward equation and a short pseudocode block into the revised §3.2. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents UniVA as an engineering framework: a Commercial SID tokenizer that injects value attributes, a decoder jointly trained with supervised loss plus eCPM-aware RL, and a value-guided beam search. All reported gains (offline HR@100 lift, online GMV) are obtained from platform experiments rather than from any closed-form derivation. No equation, definition, or self-citation chain is shown that reduces a claimed result to its own fitted inputs by construction. The pipeline is internally consistent with the empirical measurements and does not rely on renaming known patterns or importing uniqueness theorems from the same authors.
Axiom & Free-Parameter Ledger
free parameters (1)
- eCPM scaling factors and RL reward weights
axioms (1)
- domain assumption Value signals can be injected into SID construction while preserving discriminative item representations for user interest.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review arXiv 2023
-
[2]
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, et al. 2025. Mixture- of-recursions: Learning dynamic recursive depths for adaptive token-level com- putation.arXiv preprint arXiv:2507.10524(2025)
-
[3]
Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Yu Wu, et al. 2024. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1280–1297
2024
-
[4]
Ruidong Han, Bin Yin, Shangyu Chen, He Jiang, Fei Jiang, Xiang Li, Chi Ma, Mincong Huang, Xiaoguang Li, Chunzhen Jing, et al . 2025. Mtgr: Industrial- scale generative recommendation framework in meituan. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5731–5738
2025
- [5]
-
[7]
Yupeng Hou, Zhankui He, Julian McAuley, and Wayne Xin Zhao. 2023. Learning vector-quantized item representation for transferable sequential recommenders. InProceedings of the ACM Web Conference 2023. 1162–1171
2023
-
[8]
Yupeng Hou, Jiacheng Li, Ashley Shin, Jinsung Jeon, Abhishek Santhanam, Wei Shao, Kaveh Hassani, Ning Yao, and Julian McAuley. 2025. Generating long semantic ids in parallel for recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 956–966
2025
- [9]
- [10]
- [11]
-
[12]
Yuchen Jiang, Qi Li, Han Zhu, Jinbei Yu, Jin Li, Ziru Xu, Huihui Dong, and Bo Zheng. 2022. Adaptive domain interest network for multi-domain recommenda- tion. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 3212–3221
2022
-
[13]
Xiaopeng Li, Bo Chen, Junda She, Shiteng Cao, You Wang, Qinlin Jia, Haiying He, Zheli Zhou, Zhao Liu, Ji Liu, et al. 2025. A survey of generative recommendation from a tri-decoupled perspective: Tokenization, architecture, and optimization. (2025)
2025
- [14]
-
[15]
Xinchen Luo, Jiangxia Cao, Tianyu Sun, Jinkai Yu, Rui Huang, Wei Yuan, Hezheng Lin, Yichen Zheng, Shiyao Wang, Qigen Hu, et al . 2025. Qarm: Quantitative alignment multi-modal recommendation at kuaishou. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5915– 5922
2025
-
[16]
Changhua Pei, Xinru Yang, Qing Cui, Xiao Lin, Fei Sun, Peng Jiang, Wenwu Ou, and Yongfeng Zhang. 2019. Value-aware Recommendation based on Rein- forcement Profit Maximization. InThe World Wide Web Conference (WWW ’19). Association for Computing Machinery, New York, NY, USA, 3123–3129
2019
-
[17]
Aleksandr V Petrov and Craig Macdonald. 2024. RecJPQ: training large-catalogue sequential recommenders. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 538–547
2024
-
[18]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[19]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
-
[20]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023). Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Zhang et al
work page internal anchor Pith review arXiv 2023
-
[21]
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See- Kiong Ng, and Tat-Seng Chua. 2024. Learnable item tokenization for generative recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2400–2409
2024
- [22]
- [23]
- [24]
- [25]
-
[26]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Jiayuan He, et al. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. In International Conference on Machine Learning. PMLR, 58484–58509
2024
- [27]
-
[28]
Chujie Zhao, Qun Hu, Shiping Song, Dagui Chen, Han Zhu, Jian Xu, and Bo Zheng. 2025. LLM-Auction: Generative Auction towards LLM-Native Advertising. arXiv preprint arXiv:2512.10551(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [29]
- [30]
- [31]
-
[32]
Hao Zhou, Chengming Hu, Ye Yuan, Yufei Cui, Yili Jin, Can Chen, Haolun Wu, Dun Yuan, Li Jiang, Di Wu, et al. 2024. Large language model (llm) for telecom- munications: A comprehensive survey on principles, key techniques, and oppor- tunities.IEEE Communications Surveys & Tutorials27, 3 (2024), 1955–2005. ,
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.