Recognition: unknown
Sheet as Token: A Graph-Enhanced Representation for Multi-Sheet Spreadsheet Understanding
Pith reviewed 2026-05-08 11:20 UTC · model grok-4.3
The pith
Treating each worksheet as one compact token linked in a query-specific graph improves retrieval of relevant sheets from multi-sheet spreadsheets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
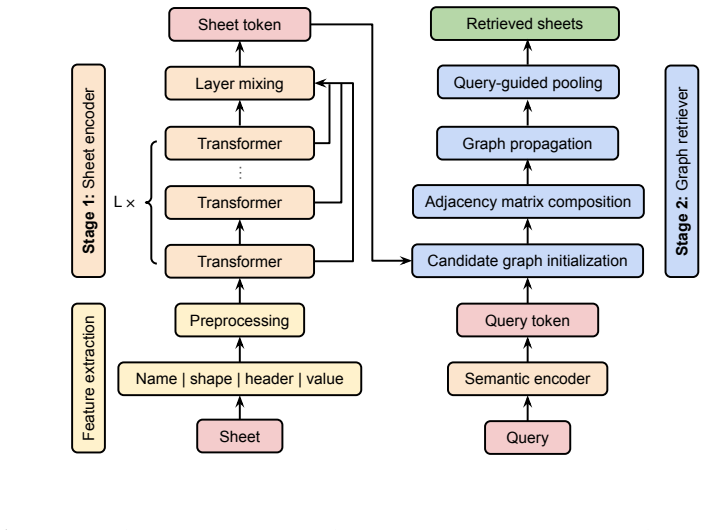
Sheet as Token encodes every worksheet into a compact dense token drawn from its name, headers, representative values, and layout features; a Graph Retriever then assembles a query-specific candidate graph over these tokens through semantic, schema-consistency, and shape-compatibility channels and processes the graph with a multi-stage transformer to retrieve supporting sheet sets.
What carries the argument
The sheet token, a unified dense encoding of an entire worksheet that preserves global semantics and serves as the atomic unit for graph-based cross-sheet reasoning.
If this is right
- Sheet-level tokenization produces stable representations of individual worksheets.
- Graph-enhanced cross-sheet reasoning improves listwise retrieval over a shallow graph baseline.
- The performance gain occurs with only limited additional computation on the graph side.
- The unified sheet tokens maintain global semantics better than chunk-centric decompositions.
Where Pith is reading between the lines
- The same sheet-token abstraction could reduce context loss when language models process large workbooks that exceed typical input limits.
- Multiple relation channels in the candidate graph may surface implicit dependencies between sheets that text-only retrieval overlooks.
- The approach points toward treating other multi-part documents, such as reports divided into sections, as unified tokens for relational reasoning.
Load-bearing premise
The extracted schema-aware records from sheet names, column headers, representative values, and layout features are sufficient to encode the full semantic content of each worksheet for effective cross-sheet reasoning.
What would settle it
A retrieval test on spreadsheets where key semantic links reside in unextracted formulas or detailed cell patterns beyond the representative values and layout features, causing the method to miss relevant sheets that a full-content reader would select.
Figures



read the original abstract
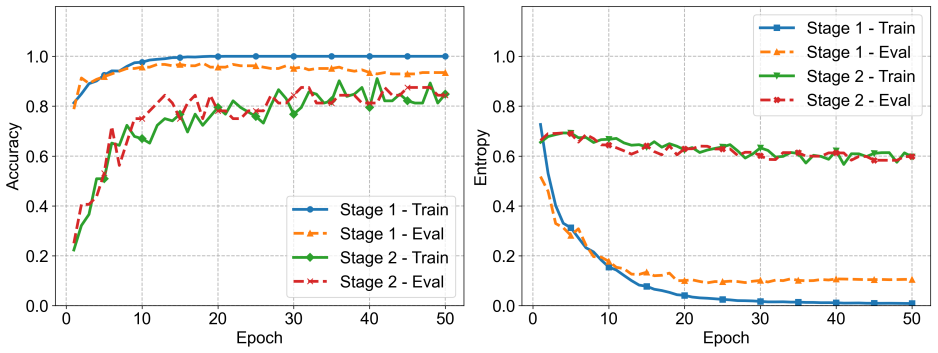
Workbook-scale spreadsheet understanding is increasingly important for language-model-based data analysis agents, but remains challenging because relevant information is often distributed across multiple sheets with heterogeneous schemas, layouts, and implicit relationships. Existing retrieval-augmented approaches typically decompose spreadsheets into rows, columns, or blocks to improve scalability; however, such chunk-centric representations can fragment worksheets into isolated text spans and weaken global sheet-level semantics. We propose Sheet as Token, a graph-enhanced framework that treats each worksheet as a unified semantic unit for multi-sheet spreadsheet retrieval. Our method extracts schema-aware records from sheet names, column headers, representative values, and layout features, and encodes each worksheet into a compact dense token. Given a natural-language query, a Graph Retriever constructs a query-specific candidate graph over sheet tokens using semantic, query-conditioned, schema-consistency, and shape-compatibility relations, and composes these channels through a multi-stage graph transformer to retrieve supporting sheet sets. Experiments on a constructed multi-sheet spreadsheet corpus show that sheet-level tokenization learns stable representations, and that graph-enhanced cross-sheet reasoning improves listwise retrieval over a shallow graph baseline with limited additional graph-side computation. These results suggest that sheet-level tokenization is a promising abstraction for scalable multi-sheet spreadsheet understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes 'Sheet as Token', a graph-enhanced framework for multi-sheet spreadsheet understanding that treats each worksheet as a unified semantic token. It extracts schema-aware records from sheet names, column headers, representative values, and layout features to encode worksheets into dense tokens, then uses a query-conditioned Graph Retriever to build a candidate graph with semantic, schema-consistency, and shape-compatibility edges, composed via a multi-stage graph transformer for listwise retrieval. Experiments on a constructed multi-sheet spreadsheet corpus claim that sheet-level tokenization yields stable representations and that the graph-enhanced approach improves retrieval over a shallow graph baseline with limited extra computation.
Significance. If the extraction method robustly captures semantics and the experimental claims are supported by rigorous controls, this could advance scalable retrieval for workbook-scale spreadsheet agents by avoiding fragmentation from row/column chunking and enabling better cross-sheet reasoning. The graph transformer composition of multiple relation channels is a potentially reusable idea for structured data retrieval.
major comments (2)
- [Abstract] Abstract and Experiments section: The abstract states that experiments show 'stable representations' and 'improved listwise retrieval' over a shallow graph baseline, but provides no details on the baselines, metrics (e.g., nDCG, recall@K), error bars, statistical significance tests, or biases in corpus construction. These omissions are load-bearing because the central claim of practical improvement cannot be assessed without them.
- [Method] Method section (record extraction description): The framework relies on the claim that schema-aware records extracted from sheet names, column headers, representative values, and layout features are sufficient to encode full worksheet semantics for stable tokens and effective graph reasoning. This is unvalidated in the provided text and is load-bearing, as spreadsheets frequently embed critical semantics in formulas, named ranges, conditional logic, and inter-cell dependencies that are not recoverable from the listed surface features; omission risks retrieving syntactically compatible but semantically incomplete sheet sets.
minor comments (1)
- [Abstract] Abstract: The phrase 'with limited additional graph-side computation' is vague; a brief quantification or comparison (e.g., FLOPs or runtime) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our contributions. We address each major point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experiments section: The abstract states that experiments show 'stable representations' and 'improved listwise retrieval' over a shallow graph baseline, but provides no details on the baselines, metrics (e.g., nDCG, recall@K), error bars, statistical significance tests, or biases in corpus construction. These omissions are load-bearing because the central claim of practical improvement cannot be assessed without them.
Authors: We agree that the abstract and experiments section require more explicit details to substantiate the claims. In the revised manuscript we will expand the abstract to name the primary metrics (nDCG@K and Recall@K), note the inclusion of error bars, and reference statistical significance testing. The experiments section will be updated to describe the shallow graph baseline in greater detail, report the exact evaluation protocol, and include a short analysis of potential corpus-construction biases (e.g., sheet-size distribution and domain coverage). These additions will make the reported improvements directly verifiable. revision: yes
-
Referee: [Method] Method section (record extraction description): The framework relies on the claim that schema-aware records extracted from sheet names, column headers, representative values, and layout features are sufficient to encode full worksheet semantics for stable tokens and effective graph reasoning. This is unvalidated in the provided text and is load-bearing, as spreadsheets frequently embed critical semantics in formulas, named ranges, conditional logic, and inter-cell dependencies that are not recoverable from the listed surface features; omission risks retrieving syntactically compatible but semantically incomplete sheet sets.
Authors: We acknowledge that formulas, named ranges, and inter-cell dependencies often carry essential semantics not captured by the surface features we currently extract. Our design choice prioritizes scalable, parse-light record extraction to enable workbook-scale retrieval without requiring full formula evaluation. In the revised manuscript we will add an explicit limitations paragraph in the Method section that states the scope of the extracted records, notes the potential omission of formula-driven semantics, and outlines planned future work on lightweight formula embedding. We will also clarify that the multi-channel graph is intended to compensate for missing signals by leveraging schema-consistency and shape-compatibility edges among the available tokens. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's method is defined through explicit, rule-based extraction of schema-aware records (sheet names, column headers, representative values, layout features) and construction of a query-conditioned graph using semantic, schema-consistency, and shape-compatibility relations, followed by a multi-stage graph transformer. These components are specified independently of the reported retrieval metrics. Experiments on a constructed corpus are presented as validation rather than as fitted inputs renamed as predictions. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes, and no equations or steps reduce the central claims to their own inputs by construction. The derivation chain remains self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Encoding spreadsheets for large language models
Haoyu Dong, Jianbo Zhao, Yuzhang Tian, Junyu Xiong, Mengyu Zhou, Yun Lin, José Cambronero, Yeye He, Shi Han, and Dongmei Zhang. Encoding spreadsheets for large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 20728–20748, Miami, Florida, USA, 2024. Association for Computational Linguistics
2024
-
[2]
SheetCopilot: Bringing software productivity to the next level through large language models
Hongxin Li, Jingran Su, Yuntao Chen, Qing Li, and Zhaoxiang Zhang. SheetCopilot: Bringing software productivity to the next level through large language models. InAdvances in Neural Information Processing Systems, 2023
2023
-
[3]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, volume 33, pages 9459–9474, 2020
2020
-
[4]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 6769–6781, 2020
2020
-
[5]
Anmol Gulati, Sahil Sen, Waqar Sarguroh, and Kevin Paul. From rows to reasoning: A retrieval- augmented multimodal framework for spreadsheet understanding.arXiv preprint arXiv:2601.08741, 2026
-
[6]
Relational inductive biases, deep learning, and graph networks
Peter W. Battaglia, Jessica B. Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational inductive biases, deep learning, and graph networks.arXiv preprint arXiv:1806.01261, 2018
work page internal anchor Pith review arXiv 2018
-
[7]
Graph neural networks: A review of methods and applications.AI Open, 1:57–81, 2020
Jie Zhou, Ganqu Cui, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li, and Maosong Sun. Graph neural networks: A review of methods and applications.AI Open, 1:57–81, 2020. 10
2020
-
[8]
RelBench: A benchmark for deep learning on relational databases
Joshua Robinson, Weihua Hu, Matthias Fey, Jan Eric Lenssen, Rishabh Ranjan, Kexin Huang, Jiaxuan You, Rex Ying, and Jure Leskovec. RelBench: A benchmark for deep learning on relational databases. InAdvances in Neural Information Processing Systems, 2024
2024
-
[9]
Valentine: Evaluating matching techniques for dataset discovery
Christos Koutras, George Siachamis, Andra Ionescu, Kyriakos Psarakis, Jerry Brons, Marios Fragkoulis, Christoph Lofi, Angela Bonifati, and Asterios Katsifodimos. Valentine: Evaluating matching techniques for dataset discovery. InProceedings of the 37th IEEE International Conference on Data Engineering (ICDE), 2021
2021
-
[10]
LongTableBench: Benchmarking long-context table reasoning across real-world formats and domains
Liyao Li, Jiaming Tian, Hao Chen, Wentao Ye, Chao Ye, Haobo Wang, Ningtao Wang, Xing Fu, Gang Chen, and Junbo Zhao. LongTableBench: Benchmarking long-context table reasoning across real-world formats and domains. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 11927–11965, Suzhou, China, 2025. Association for Computational L...
2025
-
[11]
Tabfact: A large-scale dataset for table-based fact verification
Wenhu Chen, Han Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. Tabfact: A large-scale dataset for table-based fact verification. InInternational Conference on Learning Representations, 2020
2020
-
[12]
TAT- QA: A large-scale question answering dataset on tabular and textual content in finance
Fengbin Zhu, Wenqiang Lei, Chao You, Fuliang Wang, Shu Ji, Jianming Wang, and Tat-Seng Chua. TAT- QA: A large-scale question answering dataset on tabular and textual content in finance. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volum...
2021
-
[13]
Ziwei Wang, Jiayuan Su, Mengyu Zhou, Huaxing Zeng, Mengni Jia, Xiao Lv, Haoyu Dong, Xiaojun Ma, Shi Han, and Dongmei Zhang. SheetBrain: A neuro-symbolic agent for accurate reasoning over complex and large spreadsheets.arXiv preprint arXiv:2510.19247, 2025
-
[14]
Capturing row and column semantics in transformer based question answering over tables
Michael Glass, Mustafa Canim, Alfio Gliozzo, Saneem Chemmengath, Vishwajeet Kumar, Rishav Chakravarti, Avi Sil, Feifei Pan, Samarth Bharadwaj, and Nicolas Rodolfo Fauceglia. Capturing row and column semantics in transformer based question answering over tables. InProceedings of the 2021 Conference of the North American Chapter of the Association for Compu...
2021
-
[15]
Nearest neighbor pattern classification.IEEE transactions on information theory, 13(1):21–27, 1967
Thomas Cover and Peter Hart. Nearest neighbor pattern classification.IEEE transactions on information theory, 13(1):21–27, 1967
1967
-
[16]
Morgan & Claypool Publishers, 2020
William L Hamilton.Graph Representation Learning. Morgan & Claypool Publishers, 2020
2020
-
[17]
Valentine data fabricator: A synthetic benchmark generator for schema matching.https://github
Christos Koutras, Kyriakos Psarakis, George Siachamis, Marios Fragkoulis, and Asterios Katsifodimos. Valentine data fabricator: A synthetic benchmark generator for schema matching.https://github. com/delftdata/valentine-data-fabricator, 2021. A Detailed Graph Formulation This appendix provides the detailed formulation of the graph-based retrieval models u...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.