Recognition: unknown
A Testable Certificate for Constant Collapse in Teacher-Guided VAEs
Pith reviewed 2026-05-08 14:39 UTC · model grok-4.3
The pith
A latent-only witness in teacher-guided VAEs cannot be constant if its alignment loss falls below the teacher mutual information I_T(X;T).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For any fixed nonconstant teacher distribution T(·|x), the best constant student is the dataset-average teacher distribution, and its alignment cost is exactly the teacher mutual information I_T(X;T). Therefore, if a strictly latent-only raw witness achieves alignment loss below this value, with a safety margin, the witness cannot be constant in the input.
What carries the argument
The teacher mutual information I_T(X;T) as the exact alignment cost of the optimal constant (input-independent) student, used as a direct threshold for the raw latent witness loss.
If this is right
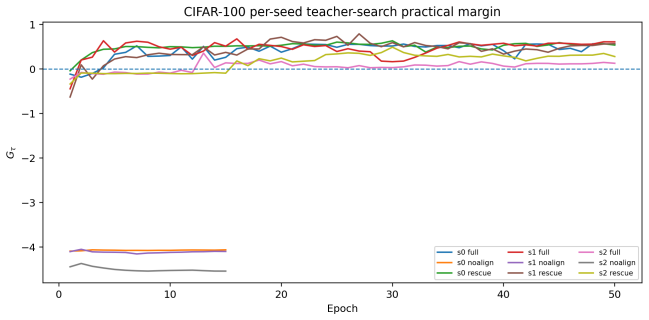
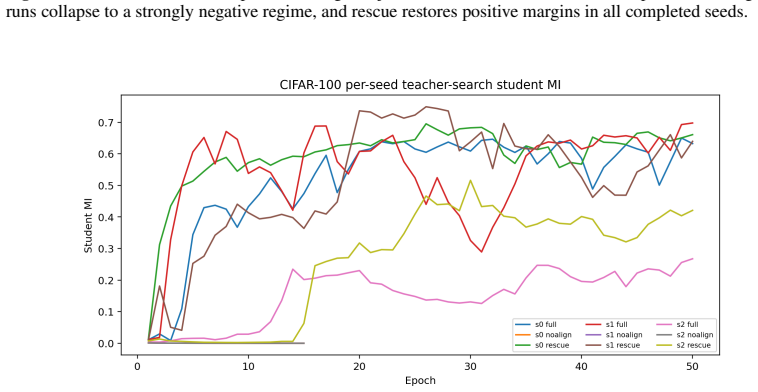
- Full training with alignment keeps the witness certified on the non-constant side of the boundary.
- Disabling alignment pushes the raw witness into the constant-student regime.
- Restarting from a collapsed checkpoint with alignment enabled restores the certificate.
- The same prevention, collapse, and rescue pattern holds across Tiny-ImageNet-200 with multiple independently searched teachers.
- Standard VAE baselines that preserve reconstruction or add post-hoc predictability remain negative under the raw certificate.
Where Pith is reading between the lines
- The same threshold idea could be extended to other guided latent models where a fixed teacher or target distribution is available.
- It offers a way to tune alignment objectives to guarantee information flow through latents without monitoring every indirect collapse symptom.
- Testing the bound on non-image data or with learned rather than fixed teachers would reveal how broadly the identity applies.
Load-bearing premise
The teacher distribution is fixed and non-constant, and alignment loss can be compared directly to the constant-student cost without extra fitting or adjustments.
What would settle it
A constant input-independent witness that still achieves alignment loss strictly below I_T(X;T) on the same fixed teacher would disprove the certificate.
Figures









read the original abstract
Posterior collapse in variational autoencoders is often diagnosed by its symptoms: a small KL term, a strong decoder, or weak use of the latent code. These signals are useful, but they do not define a collapse boundary. We study a concrete failure mode, input-independent constant collapse, and show that this case admits an exact threshold. For any fixed nonconstant teacher distribution \(T(\cdot\mid x)\), the best constant student is the dataset-average teacher distribution, and its alignment cost is the teacher mutual information \(I_T(X;T)\). Therefore, if a strictly latent-only raw witness achieves alignment loss below this value, with a safety margin, the witness cannot be constant in the input. This identity turns a qualitative failure mode into a measurable one. In CIFAR-100 experiments with per-seed teacher search, full training stays on the certified side of the boundary, removing alignment drives the raw witness into the constant-student regime, and restarting from a collapsed checkpoint with alignment enabled restores the certificate. Tiny-ImageNet-200 fixed-target runs show the same prevention--collapse--rescue pattern across three independently searched teachers. Standard VAE-style baselines, including methods that preserve reconstruction quality or post-hoc predictability, remain negative under the raw certificate. The guarantee is intentionally narrow: it certifies that the matched nonconstant teacher-relative variation passes through the latent pathway, rather than claiming that all forms of posterior collapse have been ruled out.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that constant (input-independent) collapse in teacher-guided VAEs admits an exact, testable threshold: for any fixed non-constant teacher T(·|x), the minimal alignment cost incurred by a constant student equals the teacher mutual information I_T(X;T), achieved precisely by the marginal teacher distribution. Consequently, a strictly latent-only raw witness achieving alignment loss below this value (with safety margin) certifies that the witness cannot be constant in the input. Experiments on CIFAR-100 (per-seed teacher search) and Tiny-ImageNet-200 (fixed-target) illustrate that full training with alignment stays certified, removing alignment drives the witness into the constant regime, and re-enabling alignment rescues the certificate; standard VAE baselines remain negative under the raw certificate. The guarantee is explicitly narrow, certifying only teacher-relative non-constant variation through the latent pathway.
Significance. If the central identity holds, the work converts a qualitative symptom of posterior collapse into a precise, falsifiable boundary derived from standard information theory. The narrow scope is a deliberate strength rather than a weakness, and the reproducible prevention-collapse-rescue pattern across two datasets and multiple teachers provides concrete empirical grounding. The result offers a clean diagnostic tool for teacher-guided models that is independent of decoder strength or reconstruction quality, distinguishing it from existing collapse heuristics.
major comments (2)
- [Abstract and §3 (certificate derivation)] The central identity is presented as immediate from the definition of alignment loss as expected KL (or equivalent f-divergence), yet the manuscript provides no explicit derivation steps, error analysis, or proof that the loss is exactly comparable to I_T(X;T) without post-hoc adjustments. This step is load-bearing for the certificate claim.
- [Experiments (§5, CIFAR-100 and Tiny-ImageNet-200 results)] Experiments are described only qualitatively ('stays on the certified side', 'drives into the constant-student regime'). Without reported numerical values for achieved alignment losses, estimated I_T(X;T), safety margins, or per-run statistics, it is impossible to verify that the observed patterns actually cross or respect the claimed threshold.
minor comments (3)
- [Abstract and §4] The phrase 'with a safety margin' appears in the abstract and main claim but is never defined or operationalized; the manuscript should specify how the margin is chosen and whether it depends on estimation error in I_T(X;T).
- [§2 (problem setup)] The alignment loss is referred to as 'raw witness' loss but its precise functional form (KL, f-divergence, or other) is not stated explicitly in the provided abstract; the full text should include the equation.
- [Experiments] Table or figure summarizing numerical certificate values across seeds, teachers, and baselines would make the empirical claims more transparent and reproducible.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the recommendation of minor revision, and the constructive comments that will improve the clarity and verifiability of the central claim. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3 (certificate derivation)] The central identity is presented as immediate from the definition of alignment loss as expected KL (or equivalent f-divergence), yet the manuscript provides no explicit derivation steps, error analysis, or proof that the loss is exactly comparable to I_T(X;T) without post-hoc adjustments. This step is load-bearing for the certificate claim.
Authors: We agree that an explicit derivation strengthens the presentation. The alignment loss for a student S is E_{x~p(x)}[KL(T(·|x) || S(·|z))]. When S is constant (input- and latent-independent), this simplifies to E_x[KL(T(·|x) || S(·))]. By the standard information-theoretic identity, this expectation is minimized precisely when S equals the marginal teacher distribution T(·) = E_x[T(·|x)], and the minimum value equals I_T(X;T) with no post-hoc adjustments or approximations required. The same holds for any f-divergence that satisfies the corresponding variational characterization of mutual information. We will insert this short derivation (with the relevant steps) into the revised §3. revision: yes
-
Referee: [Experiments (§5, CIFAR-100 and Tiny-ImageNet-200 results)] Experiments are described only qualitatively ('stays on the certified side', 'drives into the constant-student regime'). Without reported numerical values for achieved alignment losses, estimated I_T(X;T), safety margins, or per-run statistics, it is impossible to verify that the observed patterns actually cross or respect the claimed threshold.
Authors: We accept that the current qualitative descriptions limit independent verification. In the revised manuscript we will add tables (one per dataset) reporting, for each teacher and phase (full training, alignment removed, rescue), the mean alignment loss with standard deviation over seeds, the estimated I_T(X;T), the safety margin employed, and the resulting certificate status. These numbers will directly confirm the threshold crossings described in the prevention-collapse-rescue experiments. revision: yes
Circularity Check
No significant circularity; core identity is a direct information-theoretic consequence
full rationale
The paper's central derivation states that for fixed non-constant teacher T(·|x), the minimal alignment cost of any constant student equals I_T(X;T) by the definition I(X;T) = E_x[KL(T(·|x) || T_avg)]. This is an immediate consequence of the alignment loss being the expected KL (or f-divergence) and requires no fitting, no parameter estimation inside the VAE, and no self-citation for the inequality itself. The certificate threshold is therefore independent of student parameters. Experiments demonstrate usage of the threshold but do not modify or presuppose the identity. No load-bearing step reduces to a fit, self-definition, or author-specific uniqueness theorem.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math The minimizer of expected KL divergence to a fixed distribution is the expectation of that distribution
- standard math Mutual information I_T(X;T) equals the expected KL between T(·|x) and its marginal
Reference graph
Works this paper leans on
-
[1]
Fixing a broken ELBO
Alemi, A., Poole, B., Fischer, I., Dillon, J., Saurous, R., and Murphy, K. Fixing a broken ELBO. ICML, 2018
2018
-
[2]
Generating sentences from a continuous space
Bowman, S., Vilnis, L., Vinyals, O., Dai, A., Jozefowicz, R., and Bengio, S. Generating sentences from a continuous space. CoNLL, 2016
2016
-
[3]
Variational lossy autoencoder
Chen, X., Kingma, D., Salimans, T., Duan, Y., Dhariwal, P., Schulman, J., Sutskever, I., and Abbeel, P. Variational lossy autoencoder. ICLR, 2017
2017
-
[4]
Deep unsupervised clustering with Gaussian mixture variational autoencoders
Dilokthanakul, N., Mediano, P., Garnelo, M., Lee, M., Salimbeni, H., Arulkumaran, K., and Shanahan, M. Deep unsupervised clustering with Gaussian mixture variational autoencoders. arXiv:1611.02648, 2016
-
[5]
Lagging inference networks and posterior collapse in variational autoencoders
He, J., Spokoyny, D., Neubig, G., and Berg-Kirkpatrick, T. Lagging inference networks and posterior collapse in variational autoencoders. ICLR, 2019
2019
-
[6]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., and Dean, J. Distilling the knowledge in a neural network. arXiv:1503.02531, 2015
work page internal anchor Pith review arXiv 2015
-
[7]
and Welling, M
Kingma, D. and Welling, M. Auto-encoding variational Bayes. ICLR, 2014
2014
-
[8]
Learning multiple layers of features from tiny images
Krizhevsky, A. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
2009
-
[9]
and Yang, X
Le, Y. and Yang, X. Tiny ImageNet visual recognition challenge. CS 231N, 2015
2015
-
[10]
Neural discrete representation learning
van den Oord, A., Vinyals, O., and Kavukcuoglu, K. Neural discrete representation learning. NeurIPS, 2017
2017
-
[11]
InfoVAE: information maximizing variational autoencoders
Zhao, S., Song, J., and Ermon, S. InfoVAE: information maximizing variational autoencoders. AAAI, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.