Recognition: unknown
ChartZero: Synthetic Priors Enable Zero Shot Chart Data Extraction
Pith reviewed 2026-05-08 14:55 UTC · model grok-4.3
The pith
Synthetic priors from simple math functions let a model extract data from arbitrary real-world line charts without any real annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
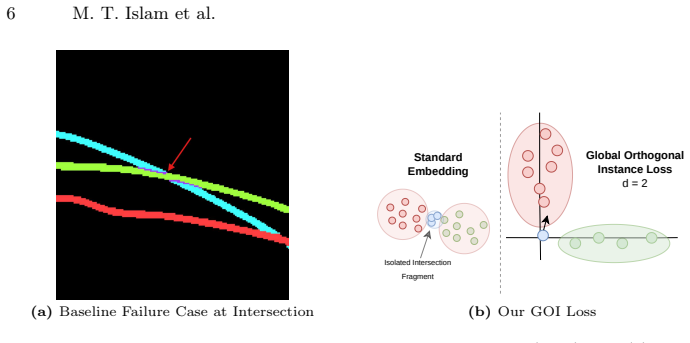
ChartZero is a parsing framework that trains only on a purely synthetic dataset of simple mathematical functions to achieve robust zero-shot chart data extraction. The framework prevents curve fragmentation with a novel Global Orthogonal Instance loss and replaces rigid spatial heuristics with an open-vocabulary VLM-guided legend matching strategy. Together with a new metric and benchmark for full end-to-end reconstruction, the method advances generalized plot digitization without requiring any real-world supervision.
What carries the argument
Synthetic priors generated from simple mathematical functions, paired with the Global Orthogonal Instance loss for preserving thin curves and VLM-guided open-vocabulary legend matching for semantic association.
If this is right
- The real-world annotation bottleneck for chart digitization is removed because only synthetic data is needed for training.
- Thin intersecting curves remain connected and detailed instead of fragmenting during extraction.
- Legend-to-curve association works reliably even when legends appear in arbitrary locations.
- Progress can be tracked with a single holistic metric rather than separate scores for isolated subtasks.
- Generalized extraction becomes feasible across arbitrary chart aesthetics and grid layouts.
Where Pith is reading between the lines
- The same synthetic-prior strategy could be tested on bar charts, scatter plots, or pie charts by generating corresponding synthetic examples.
- If the model succeeds on wild charts, it suggests that other computer-vision tasks with high stylistic diversity may also reduce reliance on real annotated data.
- Integration with larger multimodal systems could extend the approach to extracting data from entire documents or scientific figures.
- The method raises the question of how far simple synthetic functions can be pushed before more complex synthetic generators become necessary.
Load-bearing premise
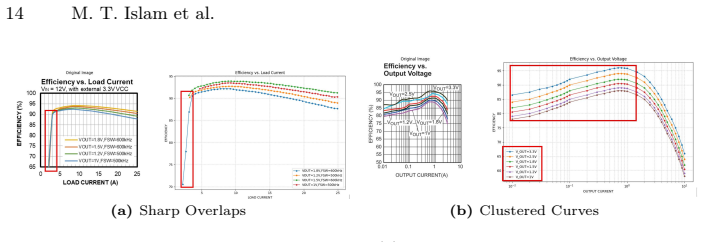
Training solely on simple synthetic mathematical functions will produce a model that handles the extreme stylistic variety, thin intersecting curves, complex backgrounds, and unpredictable legend placements of real-world charts.
What would settle it
Run the model on a large, diverse collection of real-world line charts containing thin crossing lines, cluttered backgrounds, and non-standard legend positions; measure end-to-end data reconstruction error against ground-truth values and compare to supervised baselines—if error remains high or exceeds supervised methods, the generalization claim fails.
Figures



read the original abstract
Automated data extraction from line charts remains fundamentally bottlenecked by extreme stylistic diversity and a severe scarcity of comprehensively annotated, real-world datasets. Current end-to-end pipelines depend heavily on costly manual annotations, crippling their ability to generalize across arbitrary aesthetics and grid layouts. Furthermore, existing models suffer from two critical failure modes during reconstruction. First, extracting thin, intersecting curves frequently causes structural fragmentation and the erasure of fine visual details, as standard architectures struggle against complex backgrounds. Second, semantic association is notoriously error-prone; current pipelines rely on rigid spatial heuristics that easily break down against the unpredictable legend placements of in-the-wild charts. Finally, measuring true progress is hindered by evaluation protocols that assess isolated sub-tasks rather than holistic, end-to-end data reconstruction. To address these foundational issues, we introduce ChartZero, a parsing framework that leverages synthetic priors to enable robust zero-shot chart data extraction. By training exclusively on a purely synthetic dataset of simple mathematical functions, our model completely bypasses the real-world annotation bottleneck. We overcome curve fragmentation via a novel Global Orthogonal Instance (GOI) loss, and replace brittle spatial rules with an open-vocabulary, Vision-Language Model (VLM)-guided legend matching strategy. Accompanied by a new metric and benchmark specifically designed for full end-to-end reconstruction, our evaluations demonstrate that ChartZero significantly advances generalized plot digitization without requiring real-world supervision. Code and dataset will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChartZero, a parsing framework for zero-shot line chart data extraction. It trains exclusively on a purely synthetic dataset of simple mathematical functions to bypass real-world annotation, employs a novel Global Orthogonal Instance (GOI) loss to address curve fragmentation, and uses an open-vocabulary VLM-guided strategy for legend matching. A new end-to-end metric and benchmark for holistic reconstruction are proposed, with the claim that evaluations show significant advances in generalized plot digitization without real supervision.
Significance. If the generalization from simple synthetic mathematical functions to in-the-wild charts holds, the work would be significant for removing the annotation bottleneck in chart digitization. The GOI loss and VLM integration target documented failure modes (fragmentation and legend association), and the end-to-end metric represents a constructive step beyond isolated sub-task evaluation. These elements could enable more scalable solutions if empirically validated.
major comments (2)
- [Abstract] Abstract: The assertion that 'our evaluations demonstrate that ChartZero significantly advances generalized plot digitization without requiring real-world supervision' is load-bearing for the central claim but is unsupported by any quantitative results, baselines, dataset statistics, error analysis, or description of the new metric. This leaves the performance claims without visible evidence.
- [Introduction / Method] Introduction and Method: The core assumption that training solely on synthetic data of simple mathematical functions produces priors sufficient for extreme stylistic diversity, thin intersecting curves, complex backgrounds, and arbitrary legend placements in real-world charts is unverified. The GOI loss and VLM components operate on features from this limited distribution; without explicit cross-domain experiments or ablation on real test sets with these characteristics, the bypass of real annotation cannot be substantiated.
minor comments (1)
- [Abstract] Abstract: The phrase 'Code and dataset will be released upon acceptance' is positive for reproducibility but should be accompanied by specific details on synthetic data generation parameters and the new metric definition in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger evidence in the abstract and clearer validation of the synthetic-to-real generalization. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'our evaluations demonstrate that ChartZero significantly advances generalized plot digitization without requiring real-world supervision' is load-bearing for the central claim but is unsupported by any quantitative results, baselines, dataset statistics, error analysis, or description of the new metric. This leaves the performance claims without visible evidence.
Authors: We agree that the abstract, being a high-level summary, does not embed the specific quantitative results, baseline comparisons, dataset details, error analysis, or metric description that appear in the Experiments section. In the revised manuscript we will expand the abstract to include concise highlights of the main end-to-end reconstruction results on the new benchmark, key baseline comparisons, and a brief characterization of the proposed metric, thereby making the supporting evidence visible within the abstract itself. revision: yes
-
Referee: [Introduction / Method] Introduction and Method: The core assumption that training solely on synthetic data of simple mathematical functions produces priors sufficient for extreme stylistic diversity, thin intersecting curves, complex backgrounds, and arbitrary legend placements in real-world charts is unverified. The GOI loss and VLM components operate on features from this limited distribution; without explicit cross-domain experiments or ablation on real test sets with these characteristics, the bypass of real annotation cannot be substantiated.
Authors: The manuscript reports zero-shot evaluations on multiple real-world chart collections that exhibit the cited stylistic diversity, intersecting curves, complex backgrounds, and varied legend placements. These results, together with the design of the synthetic corpus (which incorporates controlled variations in line thickness, intersections, background complexity, and legend positioning), provide the empirical basis for the generalization claim. Nevertheless, we concur that additional targeted ablations isolating performance on thin intersecting curves and complex backgrounds, as well as explicit cross-domain transfer statistics, would further substantiate the synthetic-prior hypothesis. We will add these analyses and corresponding error breakdowns in the revision. revision: partial
Circularity Check
No circularity: synthetic training and zero-shot evaluation are independent of target results
full rationale
The paper trains exclusively on synthetic data from simple mathematical functions, then evaluates zero-shot transfer to real charts using a new end-to-end metric. No derivation step reduces by construction to its own inputs: the GOI loss and VLM legend matching are architectural additions whose effectiveness is measured externally rather than defined into the synthetic prior. No self-citations are load-bearing for the central claim, and no parameters are fitted to real data then relabeled as predictions. The generalization assumption is empirically testable and not tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic data generated from simple mathematical functions is sufficiently representative of real-world chart aesthetics, layouts, and curve intersections to enable zero-shot generalization.
Reference graph
Works this paper leans on
-
[1]
https://github.com/adobe-research/CHART-Synthetic(2019), accessed 2026- 03-05 ChartZero 15
Adobe Research: Chart-synthetic: Synthetic dataset for chart understanding. https://github.com/adobe-research/CHART-Synthetic(2019), accessed 2026- 03-05 ChartZero 15
2019
-
[2]
Gemini: A Family of Highly Capable Multimodal Models
Anil, R., Borgeaud, S., Alayrac, J.B., et al.: Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review arXiv 2023
-
[3]
anthropic.com/news/claude-3-family(2024), accessed 2026-03-05
Anthropic: The claude 3 model family: Opus, sonnet, haiku.https://www. anthropic.com/news/claude-3-family(2024), accessed 2026-03-05
2024
-
[4]
Bai, J., Bai, S., Chu, Y., Cui, H., Dang, K., Deng, X., Dong, Y., Ge, K., Han, J., Huang, F., et al.: Qwen-vl: A versatile vision-language model for understanding, lo- calization, text reading, and beyond (2023),https://arxiv.org/abs/2308.12966
work page internal anchor Pith review arXiv 2023
-
[5]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K.V., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., Rädle, R., Afouras, T., Mavroudi, E., Xu, K., Wu, T.H., Zhou, Y., Momeni, L., Hazra, R., Ding, S., Vaze, S., Porcher, F., Li, F., Li, S., Kamath, A., Cheng, H.K., ...
work page internal anchor Pith review arXiv 2025
-
[6]
In: Proceedings of the European Conference on Computer Vision (ECCV)
Chen, L.C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H.: Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 801–818 (2018)
2018
-
[7]
CVAT.ai: Cvat.ai: Computer vision annotation tool (cvat).https://github.com/ cvat-ai/cvat(2026)
2026
-
[8]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (July 2017)
De Brabandere, B., Neven, D., Van Gool, L.: Semantic instance segmentation for autonomous driving. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (July 2017)
2017
-
[9]
DeepSeek-AI, et al.: Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding (2024),https://arxiv.org/abs/2412.10302
work page internal anchor Pith review arXiv 2024
-
[10]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, et al.: Gemma: Open models based on gemini research and tech- nology. arXiv preprint arXiv:2403.08295 (2024)
work page internal anchor Pith review arXiv 2024
-
[11]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
He, K., Gkioxari, G., Dollar, P., Girshick, R.: Mask r-cnn. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). pp. 2961–2969 (2017)
2017
-
[12]
In: Proceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV)
Kato, H., Nakazawa, M., Yang, H.K., Chen, M., Stenger, B.: Parsing line chart images using linear programming. In: Proceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV). pp. 2109–2118 (January 2022)
2022
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollar, P., Girshick, R.: Segment anything. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4015–4026 (2023)
2023
-
[14]
Lal, J., Mitkari, A., Bhosale, M., Doermann, D.: Lineformer: Rethinking line chart data extraction as instance segmentation (2023),https://arxiv.org/abs/2305. 01837
2023
-
[15]
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning (2023),https:// arxiv.org/abs/2304.08485
work page internal anchor Pith review arXiv 2023
-
[16]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3431–3440 (2015)
2015
-
[17]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Luo, J., Li, Z., Wang, J., Lin, C.Y.: Chartocr: Data extraction from charts images via a deep hybrid framework. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 1917–1925 (January 2021)
1917
-
[18]
OpenAI: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review arXiv 2023
-
[19]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
P., S.V., Hassan, M.Y., Singh, M.: Lineex: Data extraction from scientific line charts. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 6213–6221 (January 2023) 16 M. T. Islam et al
2023
-
[20]
In: Proceedings of the International Conference on Machine Learning (ICML)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning trans- ferable visual models from natural language supervision. In: Proceedings of the International Conference on Machine Learning (ICML). pp. 8748–8763 (2021)
2021
-
[21]
In: Medical Image Computing and Computer-Assisted Intervention (MICCAI)
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention (MICCAI). pp. 234–241 (2015)
2015
-
[22]
In: Leibe, B., Matas, J., Sebe, N., Welling, M
Siegel, N., Horvitz, Z., Levin, R., Divvala, S., Farhadi, A.: Figureseer: Parsing result-figures in research papers. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer Vision – ECCV 2016. pp. 664–680. Springer International Pub- lishing, Cham (2016)
2016
-
[23]
Sensors 24(21), 7015 (2024).https://doi.org/10.3390/s24217015
Yang, W., He, J., Li, Q.: Chartline: Automatic detection and tracing of curves in scientific line charts using spatial-sequence feature pyramid network. Sensors 24(21), 7015 (2024).https://doi.org/10.3390/s24217015
-
[24]
Yang, W., He, J., Zhang, X.: Efficient extraction of experimental data from line charts using advanced machine learning techniques. Graphical Models139, 101259 (2025).https://doi.org/https://doi.org/10.1016/j.gmod.2025.101259, https://www.sciencedirect.com/science/article/pii/S1524070325000062
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.