Recognition: no theorem link
Unifying Scientific Communication: Fine-Grained Correspondence Across Scientific Media
Pith reviewed 2026-05-12 03:19 UTC · model grok-4.3
The pith
A new dataset unites papers, slides, videos and presentations from the same scientific works to benchmark fine-grained cross-format matches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Multimodal Conference Dataset (MCD) integrates research papers, presentation videos, explanatory videos, and slides from the same works and serves as the first benchmark for discovering fine-grained cross-format correspondences. Evaluation of embedding-based and vision-language models shows that vision-language models are robust yet struggle with fine-grained alignment, while embedding-based models capture text-visual correspondences well but place equations and symbolic content in distinct clusters.
What carries the argument
The Multimodal Conference Dataset (MCD) that pairs multiple media from identical scientific works and supplies ground-truth correspondences for alignment evaluation.
If this is right
- Vision-language models can serve as a starting point for cross-format scientific retrieval but require further work on precise segment-level alignment.
- Embedding-based approaches succeed on text-visual pairs yet isolate symbolic content, suggesting separate handling for equations may be needed.
- A shared benchmark allows consistent comparison of new models on the task of unifying scientific media.
- Releasing the dataset resources supports reproducibility and extension by other researchers.
Where Pith is reading between the lines
- Tools built on such alignments could automatically generate linked summaries that jump from a paper paragraph to the matching slide or video clip.
- The dataset might be extended to track how explanations change when the same result is presented in different formats.
- Future models could use the observed clustering of symbolic content to develop specialized encoders for equations and diagrams.
Load-bearing premise
The collected materials from identical works contain meaningful, annotatable fine-grained correspondences that current models can be evaluated against without task-specific training or supervision.
What would settle it
Manual verification of the dataset annotations reveals no reliable patterns of correspondence across formats, or models perform no better than random chance when asked to match specific segments.
Figures

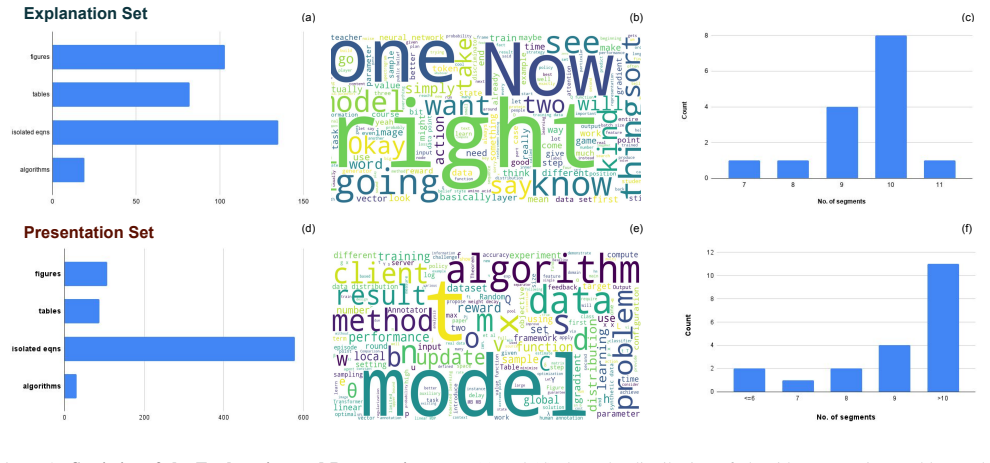




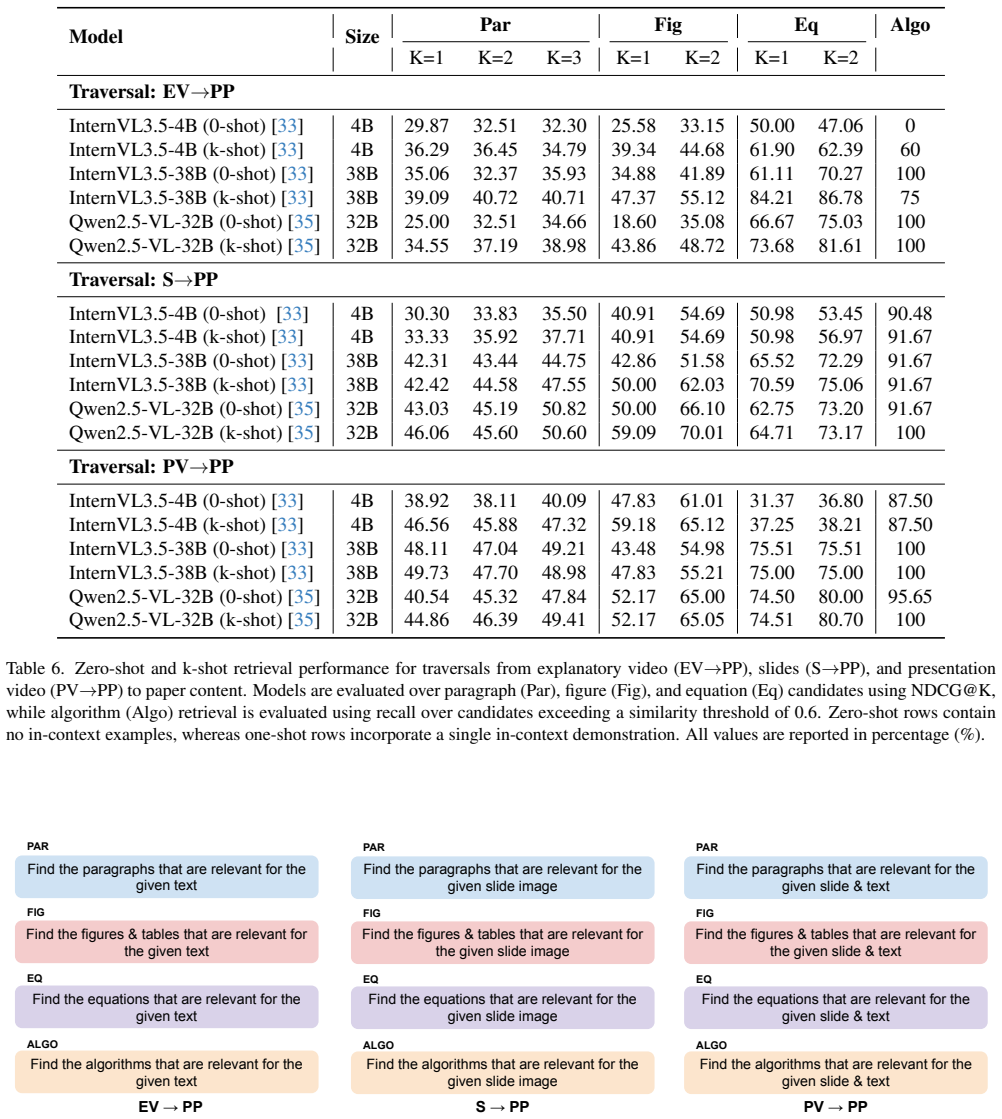

read the original abstract
The communication of scientific knowledge has become increasingly multimodal, spanning text, visuals, and speech through materials such as research papers, slides, and recorded presentations. These different representations collectively convey a study's reasoning, results, and insights, offering complementary perspectives that enrich understanding. However, despite their shared purpose, such materials are rarely connected in a structured way. The absence of explicit links across formats makes it difficult to trace how concepts, visuals, and explanations correspond, limiting unified exploration and analysis of research content. To address this gap, we introduce the Multimodal Conference Dataset (MCD), the first benchmark that integrates research papers, presentation videos, explanatory videos, and slides from the same works. We evaluate a range of embedding-based and vision-language models to assess their ability to discover fine-grained cross-format correspondences, establishing the first systematic benchmark for this task. Our results show that vision-language models are robust but struggle with fine-grained alignment, while embedding-based models capture text-visual correspondences well but equations and symbolic content form distinct clusters in the embedding space. These findings highlight both the strengths and limitations of current approaches and point to key directions for future research in multimodal scientific understanding. To ensure reproducibility, we release the resources for MCD at https://github.com/meghamariamkm2002/MCD
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Multimodal Conference Dataset (MCD), the first benchmark integrating research papers, presentation videos, explanatory videos, and slides from the same works. It evaluates a range of embedding-based and vision-language models on their ability to discover fine-grained cross-format correspondences, reporting that VLMs are robust but struggle with fine-grained alignment while embedding models capture text-visual correspondences well but separate equations and symbolic content into distinct clusters. The resources are released at https://github.com/meghamariamkm2002/MCD to support reproducibility.
Significance. If the ground-truth correspondences prove reliable, this work is significant as the first systematic benchmark for multimodal scientific understanding across formats, addressing a real gap as research communication becomes increasingly multimodal. The evaluation highlights concrete model limitations (fine-grained alignment and symbolic content handling) that can guide future VLM and embedding research. The explicit release of the dataset and resources is a clear strength for reproducibility and community follow-up.
major comments (2)
- [MCD dataset construction] MCD dataset construction: the manuscript provides no details on dataset size, number of source works, annotation protocol, or inter-annotator agreement for the fine-grained correspondences. This is load-bearing because the central claim that MCD enables fair evaluation of cross-media understanding rests on these correspondences being semantically meaningful rather than derived from coarse structural cues (e.g., timestamps or headings).
- [Evaluation and results] Evaluation protocol and results: no quantitative metrics (accuracy, recall@K, alignment scores, etc.), dataset statistics, or explicit evaluation protocol (zero-shot vs. supervised) are reported; findings remain purely qualitative. This prevents assessment of effect sizes and undermines the claims about model strengths and limitations.
minor comments (2)
- [Abstract] The abstract would benefit from at least one key statistic (e.g., number of papers or correspondences) to give readers a sense of scale.
- [Introduction] Notation for 'fine-grained' should be defined explicitly early in the paper, as it is central to the benchmark task.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of the significance of the MCD dataset and for the constructive feedback. We will revise the manuscript to provide the requested details on dataset construction and to include quantitative evaluation metrics and protocol descriptions.
read point-by-point responses
-
Referee: [MCD dataset construction] MCD dataset construction: the manuscript provides no details on dataset size, number of source works, annotation protocol, or inter-annotator agreement for the fine-grained correspondences. This is load-bearing because the central claim that MCD enables fair evaluation of cross-media understanding rests on these correspondences being semantically meaningful rather than derived from coarse structural cues (e.g., timestamps or headings).
Authors: We agree that the manuscript requires additional details on dataset construction to establish the reliability of the ground-truth correspondences. In the revised version, we will add a dedicated subsection describing the dataset size, the number of source works, the annotation protocol (involving expert semantic alignment across formats), and inter-annotator agreement. The correspondences were created based on semantic content rather than structural cues such as timestamps or headings. revision: yes
-
Referee: [Evaluation and results] Evaluation protocol and results: no quantitative metrics (accuracy, recall@K, alignment scores, etc.), dataset statistics, or explicit evaluation protocol (zero-shot vs. supervised) are reported; findings remain purely qualitative. This prevents assessment of effect sizes and undermines the claims about model strengths and limitations.
Authors: We acknowledge that the current presentation of results is qualitative and would be strengthened by quantitative metrics and a clearer protocol. In the revision, we will report specific metrics including accuracy and recall@K, provide dataset statistics, and explicitly describe the zero-shot evaluation protocol used for the embedding and vision-language models. This will enable assessment of effect sizes and better support the claims about model performance on fine-grained alignment and symbolic content. revision: yes
Circularity Check
No significant circularity in empirical dataset introduction and model evaluation
full rationale
The paper introduces the Multimodal Conference Dataset (MCD) as a new benchmark integrating papers, videos, slides, and explanatory videos, then evaluates off-the-shelf embedding and vision-language models on cross-format correspondence tasks. No mathematical derivations, equations, parameter fittings, or self-referential definitions appear in the provided text. The central contribution is the dataset creation and empirical benchmarking, which stands independently without reducing to fitted inputs, self-citations, or ansatzes by construction. The validity of ground-truth correspondences is an unverified empirical assumption but does not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Embedding-based and vision-language models can capture correspondences between text, images, and video in scientific content.
Reference graph
Works this paper leans on
-
[1]
Self-supervised multimodal versatile networks
Jean-Baptiste Alayrac, Adri `a Recasens, Rosalia Schneider, Relja Arandjelovi´c, Jason Ramapuram, Jeffrey De Fauw, Lu- cas Smaira, Sander Dieleman, Andrew Zisserman, and Joao Carreira. Self-supervised multimodal versatile networks. In Advances in Neural Information Processing Systems, 2020. 2
work page 2020
-
[2]
Katharina Anderer, Andreas Reich, and Matthias W ¨olfel. Mavils, a benchmark dataset for video-to-slide alignment, assessing baseline accuracy with a multimodal alignment algorithm leveraging speech, ocr, and visual features. In Proceedings of Interspeech 2024, pages 1375–1379, Kos, Greece, 2024. ISCA. 2
work page 2024
-
[3]
Multimodal alignment of scholarly documents and their presentations
Bamdad Bahrani and Min-Yen Kan. Multimodal alignment of scholarly documents and their presentations. InACM MM, page 281–284, 2013. 2
work page 2013
-
[4]
Automatic slides gen- eration in the absence of training data
Luca Cagliero and Moreno La Quatra. Automatic slides gen- eration in the absence of training data. InIEEE Annu. Com- put. Softw. Appl. Conf. (COMPSAC), pages 103–108, 2021. 3
work page 2021
-
[5]
Multi-modal language models for lecture video re- trieval
Huizhong Chen, Matthew Cooper, Dhiraj Joshi, and Bernd Girod. Multi-modal language models for lecture video re- trieval. InACM MM, pages 1081–1084, 2014. 2
work page 2014
-
[6]
Pdffigures 2.0: Min- ing figures from research papers
Christopher Clark and Santosh Divvala. Pdffigures 2.0: Min- ing figures from research papers. InACM/IEEE-CS Joint Conf. Digital Libraries (JCDL), pages 143–152, 2016. 4
work page 2016
-
[7]
arXiv preprint arXiv:2009.09941 , year=
Yuning Du, Chenxia Li, Ruoyu Guo, Xiaoting Yin, Weiwei Liu, Jun Zhou, Yifan Bai, Zilin Yu, Yehua Yang, Qingqing Dang, and Haoshuang Wang. PP-OCR: A practical ultra lightweight OCR system.CoRR, abs/2009.09941, 2020. 4
-
[8]
Quanfu Fan, Kobus Barnard, Arnon Amir, and Alon Efrat. Robust spatiotemporal matching of electronic slides to pre- sentation videos.IEEE Transactions on Image Processing, 20(8):2315–2328, 2011. 2
work page 2011
-
[9]
Col- pali: Efficient document retrieval with vision language mod- els
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, C ´eline Hudelot, and Pierre Colombo. Col- pali: Efficient document retrieval with vision language mod- els. InInternational Conference on Learning Representa- tions (ICLR), 2025. 5, 8
work page 2025
-
[10]
Corrado, Jonathon Shlens, Samy Bengio, Jeffrey Dean, Marc’Aurelio Ranzato, and Tomas Mikolov
Andrea Frome, Greg S. Corrado, Jonathon Shlens, Samy Bengio, Jeffrey Dean, Marc’Aurelio Ranzato, and Tomas Mikolov. Devise: A deep visual-semantic embedding model. InProceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2, page 2121–2129, 2013. 2
work page 2013
-
[11]
Doc2ppt: Automatic presentation slides generation from sci- entific documents
Tsu-Jui Fu, William Wang, Daniel McDuff, and Yale Song. Doc2ppt: Automatic presentation slides generation from sci- entific documents. InAAAI, pages 634–642, 2022. 3
work page 2022
-
[12]
Multi-modal transformer for video retrieval
Valentin Gabeur, Chen Sun, Karteek Alahari, and Cordelia Schmid. Multi-modal transformer for video retrieval. In Proceedings of the European Conference on Computer Vi- sion (ECCV), 2020. 2
work page 2020
-
[13]
Alignment between a technical paper and presentation sheets using a hidden markov model
Tessai Hayama, Hidetsugu Nanba, and Susumu Kunifuji. Alignment between a technical paper and presentation sheets using a hidden markov model. InProceedings of the 9th In- ternational Conference on Knowledge-Based Intelligent In- formation and Engineering Systems (KES 2005), pages 102– 106, Melbourne, Australia, 2005. IEEE. 2
work page 2005
-
[14]
E5-V: universal embeddings with multi- modal large language models
Ting Jiang, Minghui Song, Zihan Zhang, Haizhen Huang, Weiwei Deng, Feng Sun, Qi Zhang, Deqing Wang, and Fuzhen Zhuang. E5-V: universal embeddings with multi- modal large language models.CoRR, abs/2407.12580, 2024. 2, 5, 8
-
[15]
Vilt: Vision- and-language transformer without convolution or region su- pervision
Wonjae Kim, Bokyung Son, and Ildoo Kim. Vilt: Vision- and-language transformer without convolution or region su- pervision. InProceedings of the 38th International Confer- ence on Machine Learning (ICML), 2021. 2
work page 2021
-
[16]
Lecture presentations multimodal dataset: Towards understanding multimodality in educational videos
Dong Won Lee, Chaitanya Ahuja, Paul Pu Liang, Sanika Natu, and Louis-Philippe Morency. Lecture presentations multimodal dataset: Towards understanding multimodality in educational videos. InICCV, pages 20030–20041, 2023. 2
work page 2023
-
[17]
Align before fuse: Vision and language representation learning with momentum distillation
Yuan Li, Haoxuan Lin, Deyao Zhou, Bin Zhao, Zhiqiang Guan, Jinqiao Wang, and Shiliang Pu. Align before fuse: Vision and language representation learning with momentum distillation. InAdvances in Neural Information Processing Systems, 2021. 2
work page 2021
-
[18]
Cs-papersum: A large- scale dataset of ai-generated summaries for scientific papers
Javin Liu, Aryan Vats, and Zihao He. Cs-papersum: A large- scale dataset of ai-generated summaries for scientific papers. CoRR, abs/2502.20582, 2025. 3
-
[19]
Megha Mariam K M and C. V . Jawahar. Attend to what i say: Highlighting relevant content on slides. InProceedings of the International Conference on Document Analysis and Recognition (ICDAR), 2025. 3
work page 2025
-
[20]
Davis, Yaohui Zhang, Jonathan K
Jiacheng Miao, Joe R. Davis, Yaohui Zhang, Jonathan K. Pritchard, and James Zou. Paper2agent: Reimagining re- search papers as interactive and reliable ai agents, 2025. 3
work page 2025
-
[21]
Howto100m: Learning a text-video embedding by watching hundred million narrated video clips
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019. 2
work page 2019
-
[22]
Ishani Mondal, Shwetha S, Anandhavelu Natarajan, Aparna Garimella, Sambaran Bandyopadhyay, and Jordan Boyd- Graber. Presentations by the humans and for the humans: Harnessing llms for generating persona-aware slides from documents. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Lin- guistics (Volume 1: Lo...
work page 2024
-
[23]
Multi-modal and cross-modal for lecture videos retrieval
Nhu-Van Nguyen, Micka ¨el Coustaty, and Jean-Marc Ogier. Multi-modal and cross-modal for lecture videos retrieval. In ICPR, pages 2667–2672, 2014. 2 9
work page 2014
-
[24]
Jan L. Plass and Bruce D. Homer. Cognitive load in multime- dia learning: The role of learner preferences and abilities. In Proceedings of the International Conference on Computers in Education, page 564, USA, 2002. IEEE Computer Soci- ety. 3
work page 2002
-
[25]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning (ICML), 2021. 2
work page 2021
-
[26]
PresentAgent: Multi- modal agent for presentation video generation
Jingwei Shi, Zeyu Zhang, Biao Wu, Yanjie Liang, Meng Fang, Ling Chen, and Yang Zhao. PresentAgent: Multi- modal agent for presentation video generation. InProceed- ings of the 2025 Conference on Empirical Methods in Nat- ural Language Processing: System Demonstrations, pages 760–773, Suzhou, China, 2025. Association for Computa- tional Linguistics. 3
work page 2025
-
[27]
M. Sravanthi, C. R. Chowdary, and P. Kumar. Slidesgen: Automatic generation of presentation slides for a technical paper using summarization. InProceedings of the Interna- tional Conference on Intelligent Agent & Multi-Agent Sys- tems (IAMA). IEEE, 2009. 3
work page 2009
-
[28]
Edward Sun, Yufang Hou, Dakuo Wang, Yunfeng Zhang, and Nancy X. R. Wang. D2S: Document-to-slide generation via query-based text summarization. InProceedings of the 2021 Conference of the North American Chapter of the As- sociation for Computational Linguistics: Human Language Technologies, pages 1405–1418, Online, 2021. Association for Computational Lingu...
work page 2021
-
[29]
Ting Sun, Cheng Cui, Yuning Du, and Yi Liu. Pp-doclayout: A unified document layout detection model to accelerate large-scale data construction, 2025. 4
work page 2025
-
[30]
P2p: Automated paper-to-poster gen- eration and fine-grained benchmark
Tao Sun, Enhao Pan, Zhengkai Yang, Kaixin Sui, Jiajun Shi, Xianfu Cheng, Tongliang Li, Wenhao Huang, Ge Zhang, Jian Yang, and Zhoujun Li. P2p: Automated paper-to-poster gen- eration and fine-grained benchmark. InProceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS 2025), 2025. 3
work page 2025
-
[31]
SlideA VSR: A dataset of paper explanation videos for audio-visual speech recognition
Hao Wang, Shuhei Kurita, Shuichiro Shimizu, and Daisuke Kawahara. SlideA VSR: A dataset of paper explanation videos for audio-visual speech recognition. InProceedings of the 3rd Workshop on Advances in Language and Vision Research (ALVR), pages 129–137, Bangkok, Thailand, 2024. Association for Computational Linguistics. 3
work page 2024
-
[32]
Haochen Wang, Kai Hu, and Liangcai Gao. Docvideoqa: Towards comprehensive understanding of document-centric videos through question answering. In2025 IEEE Inter- national Conference on Acoustics, Speech and Signal Pro- cessing, ICASSP 2025, Hyderabad, India, April 6-11, 2025, pages 1–5. IEEE, 2025. 3
work page 2025
-
[33]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Sheng- long Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, Guanzhou Chen, Zichen Ding, Changyao Tian, Zhenyu Wu, JingJing Xie, Zehao Li, Bowen Yang, Yuchen Duan, Xuehui Wang, Zhi Ho...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Robust alignment of presentation videos with slides
Xiangyu Wang and Mohan Kankanhalli. Robust alignment of presentation videos with slides. InAdvances in Multime- dia Modeling: 16th International Conference, MMM 2010, pages 311–322, Chongqing, China, 2010. Springer. 2
work page 2010
-
[35]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Bridging modalities: Improving universal multimodal retrieval by multimodal large language models
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. Bridging modalities: Improving universal multimodal retrieval by multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9274–9285,
-
[37]
Paper2video: Automatic video generation from scientific papers.arXiv preprint arXiv:2510.05096, 2025
Zeyu Zhu, Kevin Qinghong Lin, and Mike Zheng Shou. Pa- per2video: Automatic video generation from scientific pa- pers.CoRR, abs/2510.05096, 2025. 3
-
[38]
Anette Andresen Øistein Anmarkrud and Ivar Br˚aten. Cogni- tive load and working memory in multimedia learning: Con- ceptual and measurement issues.Educational Psychologist, 54(2):61–83, 2019. 3 Appendix A. Benchmark Utility The core contribution of this benchmark is to enable seam- less navigation and alignment across different forms of sci- entific comm...
work page 2019
-
[39]
Determine how relevant each paper segment is to the video segment
-
[40]
If relevant, briefly explain why
-
[41]
If not relevant, state that it is not relevant and explain why
-
[42]
There must be a direct, fine-grained overlap between the video content and the equation. Only assign a high score if most of the concepts mentioned in the video appear explicitly in the equation. When giving the relevance score consider the paper segment in isolation (do not compare it with others). Output Format (strict JSON): {{ "results": {{"<paper_segm...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.