Recognition: unknown
MolRecBench-Wild: A Real-World Benchmark for Optical Chemical Structure Recognition
Pith reviewed 2026-05-08 11:17 UTC · model grok-4.3
The pith
A benchmark of real academic molecular diagrams reveals that existing optical recognition systems perform far worse than patent-based tests suggested.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
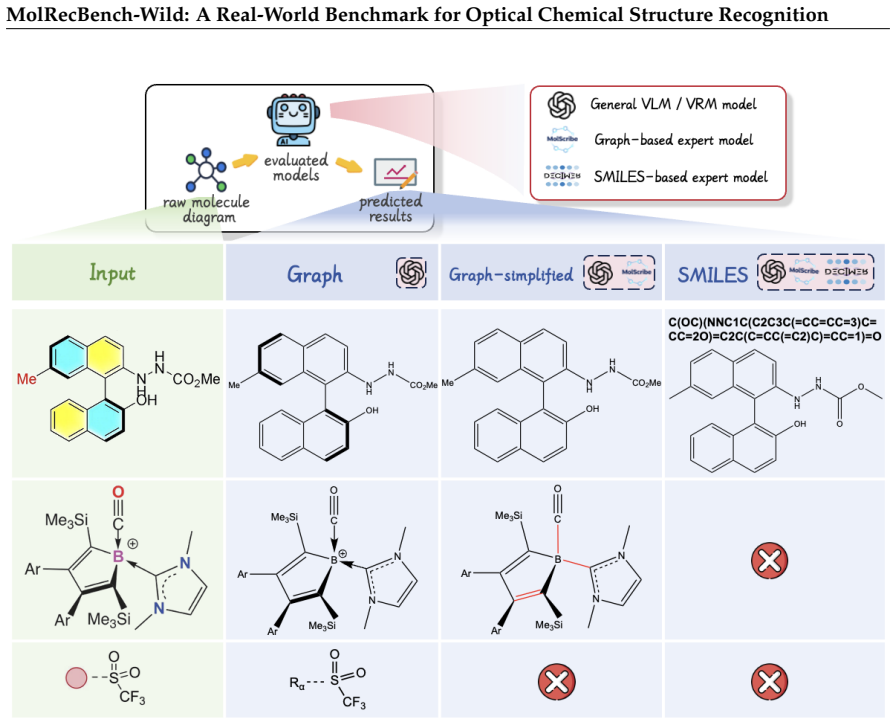
MolRecBench-Wild, a set of 5,029 structures taken from 820 recent papers and labeled with 37 difficulty categories for visual interference and chemical semantics, produces severe accuracy drops for 18 OCSR models relative to patent benchmarks, while the CARBON representation language supports evaluation of non-standard chemical features beyond SMILES.
What carries the argument
MOSAIC, the dual-dimensional difficulty framework that assigns 37 fine-grained labels jointly characterizing visual interference and chemical semantic challenges in molecular diagrams.
If this is right
- Training data for OCSR systems must include examples containing publication artifacts to reduce the observed performance gap.
- Evaluation should accept both standard SMILES strings and richer representations to measure handling of non-canonical chemistry.
- Future diagram-recognition benchmarks in science should draw from current literature rather than older curated patent sources.
- Targeted fixes for individual difficulty labels could produce measurable gains in practical extraction reliability.
Where Pith is reading between the lines
- Fine-tuning on the benchmark could be checked for carry-over benefits when the same models are later tested on patent or textbook diagrams.
- Comparable labeling schemes for difficulty types could be developed for diagram recognition tasks in mathematics or biology.
- Literature-mining pipelines could incorporate periodic runs against this benchmark to track whether real-world extraction accuracy is improving.
Load-bearing premise
The 5,029 selected structures from 820 recent papers faithfully capture the full spectrum of visual interference and chemical semantic challenges present in published molecular diagrams.
What would settle it
If the same 18 models achieve accuracy levels on MolRecBench-Wild that match or exceed their results on prior patent benchmarks, the claim of a substantial real-world performance gap would be refuted.
Figures














read the original abstract
Optical Chemical Structure Recognition (OCSR) aims to translate molecular diagrams in scientific literature into machine-readable formats, but current systems remain unreliable on real-world images due to substantial visual and chemical complexity. We introduce MOSAIC, a dual-dimensional difficulty framework with 37 fine-grained labels that jointly characterize visual interference and chemical semantic challenges in molecular diagrams. Based on this framework, we construct MolRecBench-Wild, a benchmark of 5,029 structures from 820 recent chemistry papers, covering the full difficulty spectrum observed in real publications. To enable faithful semantic evaluation beyond SMILES and MolFile, we propose CARBON, a representation language capable of expressing valence variations, icon-based groups, and other non-standard chemical semantics. We further adopt a dual-track evaluation protocol supporting both CARBON and SMILES outputs for broad model compatibility. Comprehensive experiments over 18 OCSR-capable models reveal severe performance degradation on MolRecBench-Wild, exposing a large gap between previous patent benchmarks and real-world academic scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MOSAIC, a dual-dimensional difficulty framework with 37 fine-grained labels for visual interference and chemical semantic challenges in molecular diagrams. It constructs MolRecBench-Wild, a benchmark of 5,029 structures from 820 recent chemistry papers, proposes the CARBON representation language for faithful semantic evaluation beyond SMILES/MolFile, adopts a dual-track evaluation protocol, and reports experiments on 18 OCSR models showing severe performance degradation relative to prior patent-based benchmarks.
Significance. If the benchmark construction and labeling are shown to be representative, this work would provide a valuable real-world testbed for OCSR systems and highlight the gap between controlled patent data and academic literature. The MOSAIC framework and CARBON language are concrete, reusable contributions that could improve evaluation standards; the multi-model experiments add breadth to the degradation claim.
major comments (1)
- [Benchmark construction] Benchmark construction section: the paper states that the 5,029 structures were selected from 820 recent papers and labeled via the MOSAIC framework to cover the full difficulty spectrum, but provides no explicit sampling procedure, paper-selection criteria, structure-extraction method, or filtering steps. Without these details or evidence of label reliability (e.g., inter-annotator agreement), it is impossible to verify that the observed degradation on the 18 models reflects a general gap rather than properties of the chosen subset.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief quantitative summary (e.g., top-1 accuracy ranges on MolRecBench-Wild versus prior benchmarks) to make the degradation claim immediately concrete.
- [CARBON representation] CARBON is described as supporting valence variations and icon-based groups, but the manuscript should include at least one concrete example of a CARBON string alongside its SMILES equivalent to illustrate the added expressivity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the potential value of MolRecBench-Wild and the MOSAIC framework. We agree that the benchmark construction details require expansion to support claims of representativeness, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the paper states that the 5,029 structures were selected from 820 recent papers and labeled via the MOSAIC framework to cover the full difficulty spectrum, but provides no explicit sampling procedure, paper-selection criteria, structure-extraction method, or filtering steps. Without these details or evidence of label reliability (e.g., inter-annotator agreement), it is impossible to verify that the observed degradation on the 18 models reflects a general gap rather than properties of the chosen subset.
Authors: We agree with the referee that the current manuscript lacks sufficient detail on the benchmark construction process, which is necessary to allow independent verification of the sampling and labeling procedures. In the revised version, we will substantially expand the Benchmark Construction section (currently Section 3) with the following additions: (1) explicit paper-selection criteria, including the journals, time range (2022–2024), and topic diversity criteria used to select the 820 papers; (2) the structure-extraction pipeline, describing the combination of automated PDF parsing followed by expert manual curation to isolate molecular diagrams; (3) filtering steps applied to reach the final 5,029 structures (e.g., removal of duplicates, low-resolution images, and non-standard depictions); and (4) quantitative evidence of label reliability, including inter-annotator agreement statistics (Cohen’s kappa) computed on a 10% overlap subset annotated independently by two chemists. These revisions will directly address the concern that the observed performance degradation might be an artifact of an unrepresentative subset. revision: yes
Circularity Check
No significant circularity; new benchmark and framework evaluated on external data
full rationale
The paper constructs MolRecBench-Wild from 5,029 newly extracted structures across 820 recent papers and introduces the MOSAIC labeling framework plus CARBON representation as external artifacts. The central claim of severe model degradation rests on direct empirical testing of 18 OCSR models against this fresh collection, without any equations, fitted parameters, self-referential definitions, or load-bearing self-citations that reduce the result to its own inputs by construction. The derivation chain is therefore self-contained and externally grounded.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SMILES and MolFile are accepted standard machine-readable molecular representations
invented entities (2)
-
MOSAIC dual-dimensional difficulty framework
no independent evidence
-
CARBON representation language
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Intern-s1: A scientific multimodal foun- dation model,
Lei Bai, Zhongrui Cai, Yuhang Cao, Maosong Cao, Weihan Cao, Chiyu Chen, Haojiong Chen, Kai Chen, Pengcheng Chen, Ying Chen, et al. Intern-s1: A scientific multimodal foundation model.arXiv preprint arXiv:2508.15763, 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, Junyang Lin, et al. Qwen2.5-vl technical report...
work page internal anchor Pith review arXiv 2025
-
[3]
URL https: //docs.chemaxon.com/display/docs/chemaxon-extended-smiles-and-smarts-cxsmiles-and-cxsmarts.md
ChemAxon.ChemAxon Extended SMILES and SMARTS (CXSMILES and CXSMARTS), 2025. URL https: //docs.chemaxon.com/display/docs/chemaxon-extended-smiles-and-smarts-cxsmiles-and-cxsmarts.md . Official documentation
2025
-
[4]
Logics-parsing technical report.arXiv preprint arXiv:2509.19760, 2025
Xiangyang Chen, Shuzhao Li, Xiuwen Zhu, Yongfan Chen, Fan Yang, Cheng Fang, Lin Qu, Xiaoxiao Xu, Hu Wei, and Minggang Wu. Logics-parsing technical report.arXiv preprint arXiv:2509.19760, 2025
-
[5]
Molnextr: a generalized deep learning model for molecular image recognition.Journal of Cheminformatics, 16(1):141, 2024
Yufan Chen, Ching Ting Leung, Yong Huang, Jianwei Sun, Hao Chen, and Hanyu Gao. Molnextr: a generalized deep learning model for molecular image recognition.Journal of Cheminformatics, 16(1):141, 2024
2024
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, and many others. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URLhttps://arxiv.org/abs/2507.06261
work page internal anchor Pith review arXiv 2025
-
[7]
Siqi Fan, Yuguang Xie, Bowen Cai, Ailin Xie, Gaochao Liu, Mu Qiao, Jie Xing, and Zaiqing Nie. Ocsu: Optical chemical structure understanding for molecule-centric scientific discovery.arXiv preprint arXiv:2501.15415, 2025
-
[8]
Molparser: End-to-end visual recognition of molecule structures in the wild
Xi Fang, Jiankun Wang, Xiaochen Cai, Shangqian Chen, Shuwen Yang, Haoyi Tao, Nan Wang, Lin Yao, Linfeng Zhang, and Guolin Ke. Molparser: End-to-end visual recognition of molecule structures in the wild. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24528–24538, 2025
2025
-
[9]
GLM-V Team: Wenyi Hong et al. Glm-4.5v and glm-4.1v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning, 2025. URLhttps://arxiv.org/abs/2507.01006
work page internal anchor Pith review arXiv 2025
-
[10]
OpenAI: Aaron Hurst et al. Gpt-4o system card, 2024. URLhttps://arxiv.org/abs/2410.21276
work page internal anchor Pith review arXiv 2024
-
[11]
Comparing software tools for optical chemical structure recognition.Digital Discovery, 3(4):681–693, 2024
Aleksei Krasnov, Shadrack J Barnabas, Timo Boehme, Stephen K Boyer, and Lutz Weber. Comparing software tools for optical chemical structure recognition.Digital Discovery, 3(4):681–693, 2024
2024
-
[12]
Mario Krenn, Florian Häse, AkshatKumar Nigam, Pascal Friederich, and Alán Aspuru-Guzik. Self- referencing embedded strings (selfies): A 100% robust molecular string representation.Machine Learning: Science and T echnology, 1(4):045024, 2020. doi: 10.1088/2632-2153/aba947. URL https://iopscience.iop. org/article/10.1088/2632-2153/aba947
-
[13]
Molmole_patent300: Full-page patent benchmark for chemical information extraction.https: //huggingface.co/datasets/doxa-friend/MolMole_Patent300, 2025
LG AI Research. Molmole_patent300: Full-page patent benchmark for chemical information extraction.https: //huggingface.co/datasets/doxa-friend/MolMole_Patent300, 2025. Introduced in the MolMole paper; 300 annotated patent pages
2025
-
[14]
Liu, H., Yin, H., Luo, Z., and Wang, X
Junxian Li, Di Zhang, Xunzhi Wang, Zeying Hao, Jingdi Lei, Qian Tan, Cai Zhou, Wei Liu, Yaotian Yang, Xinrui Xiong, Weiyun Wang, Zhe Chen, Wenhai Wang, Wei Li, Shufei Zhang, Mao Su, Wanli Ouyang, Yuqiang Li, and Dongzhan Zhou. Chemvlm: Exploring the power of multimodal large language models in chemistry area, 2025. URLhttps://arxiv.org/abs/2408.07246
-
[15]
Mpocsr: optical chemical structure recognition based on multi-path vision trans- former.Complex & Intelligent Systems, 10(6):7553–7563, 2024
Fan Lin and Jianhua Li. Mpocsr: optical chemical structure recognition based on multi-path vision trans- former.Complex & Intelligent Systems, 10(6):7553–7563, 2024
2024
-
[16]
Molgrapher: graph-based visual recognition of chemical structures
Lucas Morin, Martin Danelljan, Maria Isabel Agea, Ahmed Nassar, Valery Weber, Ingmar Meijer, Peter Staar, and Fisher Yu. Molgrapher: graph-based visual recognition of chemical structures. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19552–19561, 2023. 13 MolRecBench-Wild: A Real-World Benchmark for Optical Chemical Stru...
2023
-
[17]
Molscribe: robust molecular structure recognition with image-to-graph generation.Journal of chemical information and modeling, 63(7):1925–1934, 2023
Yujie Qian, Jiang Guo, Zhengkai Tu, Zhening Li, Connor W Coley, and Regina Barzilay. Molscribe: robust molecular structure recognition with image-to-graph generation.Journal of chemical information and modeling, 63(7):1925–1934, 2023
1925
-
[18]
Decimer: towards deep learning for chemical image recognition.Journal of Cheminformatics, 12(1):65, 2020
Kohulan Rajan, Achim Zielesny, and Christoph Steinbeck. Decimer: towards deep learning for chemical image recognition.Journal of Cheminformatics, 12(1):65, 2020
2020
-
[19]
Decimer v2 benchmark datasets (incl
Kohulan Rajan, Henning Otto Brinkhaus, Christoph Steinbeck, and Achim Zielesny. Decimer v2 benchmark datasets (incl. jpo subset). https://zenodo.org/records/8139328, 2023. Includes the JPO subset (450 images) referenced in OCSR benchmarks
-
[20]
Marcus: Molecular annotation and recognition for curating unravelled structures.Digital Discovery, 2025
Kohulan Rajan, Viktor Kurt Weissenborn, Laurin Lederer, Achim Zielesny, and Christoph Steinbeck. Marcus: Molecular annotation and recognition for curating unravelled structures.Digital Discovery, 2025
2025
-
[21]
Sadawi, Alan P
Noureddin M. Sadawi, Alan P . Sexton, and Volker Sorge. Molrec at clef 2012—overview and analysis of results. InCLEF 2012 Evaluation Labs and Workshop: Online Working Notes, volume 1178 ofCEUR Workshop Proceedings, 2012. URLhttps://ceur-ws.org/Vol-1178/CLEF2012wn-CLEFIP-SadawiEt2012.pdf
2012
-
[22]
Molecular structure extraction from documents using deep learning, 2018
Joshua Staker, Kyle Marshall, Robert Abel, and Carolyn McQuaw. Molecular structure extraction from documents using deep learning, 2018. URLhttps://arxiv.org/abs/1802.04903
-
[23]
Chemmllm: Chemical multimodal large language model, 2025
Qian Tan, Dongzhan Zhou, Peng Xia, Wanhao Liu, Wanli Ouyang, Lei Bai, Yuqiang Li, and Tianfan Fu. Chemmllm: Chemical multimodal large language model, 2025. URLhttps://arxiv.org/abs/2505.16326
-
[24]
Jingchao Wang, Haote Yang, Jiang Wu, Yifan He, Xingjian Wei, Yinfan Wang, Chengjin Liu, Lingli Ge, Lijun Wu, Bin Wang, et al. Gtr-cot: Graph traversal as visual chain of thought for molecular structure recognition. arXiv preprint arXiv:2506.07553, 2025
-
[25]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, and many others. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency, 2025. URLhttps://arxiv.org/abs/2508.18265
work page internal anchor Pith review arXiv 2025
-
[26]
Smiles, a chemical language and information system
David Weininger. Smiles, a chemical language and information system. 1. introduction to methodology and encoding rules.Journal of chemical information and computer sciences, 28(1):31–36, 1988
1988
-
[27]
Swinocsr: end-to-end optical chemical structure recognition using a swin transformer.Journal of cheminformatics, 14(1):41, 2022
Zhanpeng Xu, Jianhua Li, Zhaopeng Yang, Shiliang Li, and Honglin Li. Swinocsr: end-to-end optical chemical structure recognition using a swin transformer.Journal of cheminformatics, 14(1):41, 2022
2022
-
[28]
smiles" key should be null and you must add an error key, like: {
Zihan Zhao, Bo Chen, Jingpiao Li, Lu Chen, Liyang Wen, Pengyu Wang, Zichen Zhu, Danyang Zhang, Yansi Li, Zhongyang Dai, Xin Chen, and Kai Yu. Chemdfm-x: towards large multimodal model for chemistry.Science China Information Sciences, 67(12):220109, 2024. doi: 10.1007/s11432-024-4243-0. URL https://link.springer.com/article/10.1007/s11432-024-4243-0. 14 Mo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.