Recognition: unknown
Align3D-AD: Cross-Modal Feature Alignment and Dual-Prompt Learning for Zero-shot 3D Anomaly Detection
Pith reviewed 2026-05-09 16:30 UTC · model grok-4.3
The pith
Align3D-AD bridges the domain gap in zero-shot 3D anomaly detection by mapping rendering features to RGB semantics via auxiliary categories and applying dual-prompt contrastive alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Align3D-AD is a two-stage framework that first maps 3D rendering features into the RGB semantic space using auxiliary-category RGB observations and a semantic consistency reweighting strategy, then applies modality-aware prompt learning with dual-prompt contrastive alignment to capture complementary semantics and raise discriminability. The approach requires no training data from the target 3D categories and produces direct semantic transfer rather than implicit reliance on pretrained encoders.
What carries the argument
Cross-modal feature alignment that transfers semantics from auxiliary RGB data into 3D rendering features, combined with modality-aware dual-prompt contrastive alignment.
Load-bearing premise
Auxiliary RGB categories supply enough semantic overlap to map 3D rendering features into the pretrained RGB encoder space without bias or overfitting in the dual-prompt stage.
What would settle it
If Align3D-AD shows no gain over baselines on a new 3D anomaly set whose auxiliary categories share no visual or semantic similarity with the targets, the cross-modal mapping claim would be refuted.
Figures








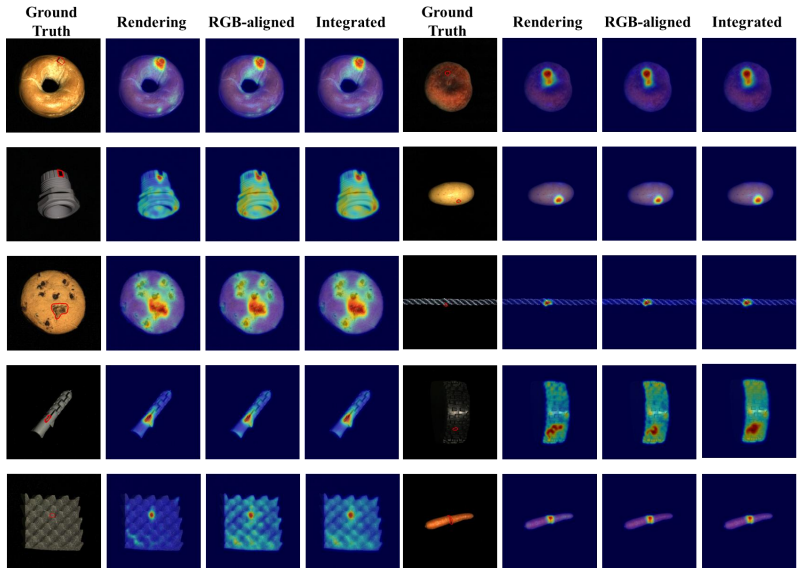
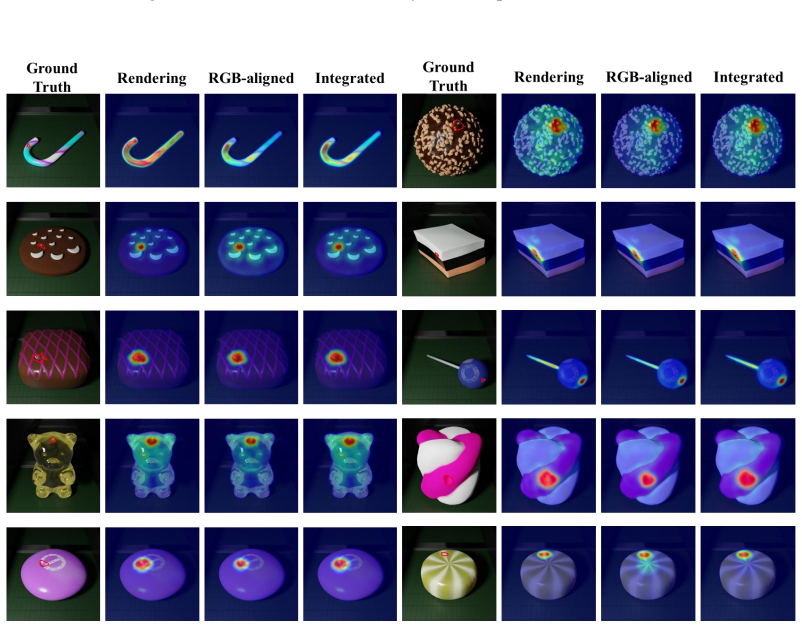
read the original abstract
Zero-shot 3D anomaly detection aims to identify anomalies without access to training data from target categories. However, existing methods mainly rely on projecting 3D observations into multi-view representations that primarily capture geometric cues rather than realistic visual semantics and process them with vision encoders pretrained on RGB data, leading to a significant domain gap between the encoder and the projected representations. To address this issue, we propose Align3D-AD, a unified two-stage framework that leverages the RGB modality from auxiliary categories as cross-modal guidance for zero-shot 3D anomaly detection. First, we introduce a cross-modal feature alignment paradigm that maps rendering features into the RGB semantic space. Unlike prior works that implicitly rely on pretrained encoders, our method enables direct semantic transfer from RGB observations. A semantic consistency reweighting strategy is further introduced to refine feature alignment by reweighting local regions according to holistic semantic consistency. Second, we propose a modality-aware prompt learning framework with dual-prompt contrastive alignment. By assigning independent prompts to RGB-aligned and rendering features, our method captures complementary semantics across modalities, while the contrastive alignment further enhances prompt representations to improve discriminability. Extensive experiments on MVTec3D-AD, Eyecandies, and Real3D-AD demonstrate that Align3D-AD consistently outperforms existing zero-shot methods under both one-vs-rest and cross-dataset settings, highlighting its generalization capability and robustness. Code and the dataset will be made available once our paper is accepted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Align3D-AD, a two-stage framework for zero-shot 3D anomaly detection. The first stage performs cross-modal feature alignment by mapping 3D rendering features into RGB semantic space using auxiliary RGB categories from non-target classes, incorporating a semantic consistency reweighting strategy to refine local regions. The second stage employs a modality-aware prompt learning framework with dual-prompt contrastive alignment to capture complementary semantics between RGB-aligned and rendering features. The authors report that this approach consistently outperforms existing zero-shot methods on MVTec3D-AD, Eyecandies, and Real3D-AD under both one-vs-rest and cross-dataset protocols.
Significance. If the reported gains hold under rigorous verification, the work could advance zero-shot 3D anomaly detection by providing an explicit mechanism to bridge the domain gap between geometric renderings and RGB-pretrained encoders via auxiliary data. The dual-prompt contrastive alignment offers a structured way to exploit complementary modality information, and the commitment to release code supports reproducibility.
major comments (2)
- [Method (cross-modal feature alignment and semantic consistency reweighting)] The cross-modal feature alignment stage (described in the abstract and method overview) maps rendering features using auxiliary-category RGB data followed by semantic consistency reweighting of local regions according to holistic semantic consistency. This reweighting risks suppressing local anomaly cues that deviate from the auxiliary RGB distribution, potentially turning the alignment into semantic smoothing that benefits normal samples more than anomalies. This is load-bearing for the central claim that the pipeline enables true cross-modal transfer of anomaly-discriminative semantics; targeted ablations measuring the reweighting's effect on anomaly versus normal patch discriminability (e.g., via feature distance or detection AUC breakdowns) are required to substantiate the domain-bridging benefit.
- [Experiments and results] The abstract claims consistent outperformance over existing zero-shot methods in one-vs-rest and cross-dataset settings on three datasets, but the provided description does not detail the precise baselines, hyperparameter selection protocol, or statistical tests for the reported gains. Without these, it is unclear whether the improvements stem from the proposed alignment and dual-prompt components or from implementation choices that could be replicated by prompt learning alone.
minor comments (1)
- The abstract states that code and the dataset will be made available upon acceptance; confirm that the released auxiliary-category RGB data and rendering pipelines are fully documented to enable exact reproduction of the alignment stage.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications and committing to specific revisions to strengthen the presentation and empirical support.
read point-by-point responses
-
Referee: [Method (cross-modal feature alignment and semantic consistency reweighting)] The cross-modal feature alignment stage (described in the abstract and method overview) maps rendering features using auxiliary-category RGB data followed by semantic consistency reweighting of local regions according to holistic semantic consistency. This reweighting risks suppressing local anomaly cues that deviate from the auxiliary RGB distribution, potentially turning the alignment into semantic smoothing that benefits normal samples more than anomalies. This is load-bearing for the central claim that the pipeline enables true cross-modal transfer of anomaly-discriminative semantics; targeted ablations measuring the reweighting's effect on anomaly versus normal patch discriminability (e.g., via feature distance or detection AUC breakdowns) are required to substantiate the domain-bridging benefit.
Authors: We appreciate the referee's concern that the semantic consistency reweighting could inadvertently suppress anomaly cues. The reweighting is computed from the agreement between local rendering features and the global RGB semantic embedding derived from auxiliary categories; normal regions receive higher weights to tighten alignment, while anomalous regions, by construction, exhibit lower consistency scores and thus retain relatively higher residual deviation after alignment. This design aims to transfer anomaly-discriminative semantics rather than smooth them away. To directly substantiate the claim, we will add targeted ablations in the revised manuscript: (i) cosine-distance histograms between aligned and RGB features for anomaly versus normal patches, and (ii) per-class AUC breakdowns with and without the reweighting module. These results will be reported in a new table and discussed in Section 4. revision: yes
-
Referee: [Experiments and results] The abstract claims consistent outperformance over existing zero-shot methods in one-vs-rest and cross-dataset settings on three datasets, but the provided description does not detail the precise baselines, hyperparameter selection protocol, or statistical tests for the reported gains. Without these, it is unclear whether the improvements stem from the proposed alignment and dual-prompt components or from implementation choices that could be replicated by prompt learning alone.
Authors: We apologize for insufficient detail in the initial submission. The baselines are exactly the zero-shot 3D anomaly detection methods listed in Section 4.1 (with citations and implementation references). Hyperparameters for all methods, including our dual-prompt learning, were chosen via a fixed protocol: a 20% validation split from the training set of each dataset, with grid search over learning rate, prompt length, and temperature; the selected values are reported in the supplementary material. To address the concern about attribution, we will expand Section 4.2 with (i) an explicit table of all hyperparameter values, (ii) a description of the baseline re-implementations, and (iii) statistical significance results (paired Wilcoxon tests across 5 random seeds) comparing Align3D-AD to the strongest baseline. These additions will clarify that the reported gains arise from the cross-modal alignment and dual-prompt contrastive objectives rather than generic prompt tuning. revision: yes
Circularity Check
No circularity: empirical method without self-referential derivations
full rationale
The paper introduces Align3D-AD as a two-stage framework: cross-modal feature alignment (mapping rendering features to RGB space via auxiliary categories plus semantic consistency reweighting) followed by dual-prompt contrastive alignment for zero-shot 3D anomaly detection. The provided text contains no equations, no fitted parameters presented as predictions, no uniqueness theorems, and no self-citations that bear the central claim. Performance claims rest on external experiments across MVTec3D-AD, Eyecandies, and Real3D-AD under one-vs-rest and cross-dataset protocols rather than any internal reduction to inputs by construction. The approach applies standard contrastive and prompt-learning techniques to a new setting without self-definitional loops or load-bearing author citations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pretrained vision encoders on RGB data capture transferable semantic information.
- domain assumption Auxiliary categories provide useful cross-modal guidance for target categories.
Reference graph
Works this paper leans on
-
[1]
Anomaly detection in 3d point clouds using deep geometric descriptors
Paul Bergmann and David Sattlegger. Anomaly detection in 3d point clouds using deep geometric descriptors. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2613–2623, 2023
2023
-
[2]
Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings
Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4183–4192, 2020
2020
-
[3]
Paul Bergmann, Xin Jin, David Sattlegger, and Carsten Steger. The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization.arXiv preprint arXiv:2112.09045, 2021
-
[4]
The eyecandies dataset for unsupervised multimodal anomaly detection and localization
Luca Bonfiglioli, Marco Toschi, Davide Silvestri, Nicola Fioraio, and Daniele De Gregorio. The eyecandies dataset for unsupervised multimodal anomaly detection and localization. In Proceedings of the Asian Conference on Computer Vision, pages 3586–3602, 2022
2022
-
[5]
Anomaly detection under distribution shift
Tri Cao, Jiawen Zhu, and Guansong Pang. Anomaly detection under distribution shift. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6511–6523, 2023
2023
-
[6]
Iaenet: An importance-aware ensemble model for 3d point cloud-based anomaly detection.Information Fusion, page 104097, 2025
Xuanming Cao, Chengyu Tao, Yifeng Cheng, and Juan Du. Iaenet: An importance-aware ensemble model for 3d point cloud-based anomaly detection.Information Fusion, page 104097, 2025
2025
-
[7]
Complementary pseudo multimodal feature for point cloud anomaly detection.Pattern Recognition, 156:110761, 2024
Yunkang Cao, Xiaohao Xu, and Weiming Shen. Complementary pseudo multimodal feature for point cloud anomaly detection.Pattern Recognition, 156:110761, 2024
2024
-
[8]
Adaclip: Adapting clip with hybrid learnable prompts for zero-shot anomaly detection
Yunkang Cao, Jiangning Zhang, Luca Frittoli, Yuqi Cheng, Weiming Shen, and Giacomo Boracchi. Adaclip: Adapting clip with hybrid learnable prompts for zero-shot anomaly detection. InEuropean Conference on Computer Vision, pages 55–72. Springer, 2024
2024
-
[9]
Yuqi Cheng, Yunkang Cao, Guoyang Xie, Zhichao Lu, and Weiming Shen. Toward zero-shot point cloud anomaly detection: a multiview projection framework.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 56(3):1747–1760, 2026. doi: 10.1109/TSMC.2025. 3648581
-
[10]
Shape-guided dual-memory learning for 3d anomaly detection
Yu-Min Chu, Chieh Liu, Ting-I Hsieh, Hwann-Tzong Chen, and Tyng-Luh Liu. Shape-guided dual-memory learning for 3d anomaly detection. InProceedings of the 40th International Conference on Machine Learning, pages 6185–6194, 2023
2023
-
[11]
Niv Cohen and Yedid Hoshen. Sub-image anomaly detection with deep pyramid correspon- dences.arXiv preprint arXiv:2005.02357, 2020
-
[12]
Zehao Deng, An Liu, and Yan Wang. Gs-clip: Zero-shot 3d anomaly detection by geometry- aware prompt and synergistic view representation learning.arXiv preprint arXiv:2602.19206, 2026
-
[13]
3d vision-based anomaly detection in manufacturing: A survey.Frontiers of Engineering Management, 12(2):343–360, 2025
Juan Du, Chengyu Tao, Xuanming Cao, and Fugee Tsung. 3d vision-based anomaly detection in manufacturing: A survey.Frontiers of Engineering Management, 12(2):343–360, 2025. 10
2025
-
[14]
Filo: Zero-shot anomaly detection by fine-grained description and high-quality localization
Zhaopeng Gu, Bingke Zhu, Guibo Zhu, Yingying Chen, Hao Li, Ming Tang, and Jinqiao Wang. Filo: Zero-shot anomaly detection by fine-grained description and high-quality localization. InProceedings of the 32nd ACM International Conference on Multimedia, pages 2041–2049, 2024
2041
-
[15]
Anoma- lygpt: Detecting industrial anomalies using large vision-language models
Zhaopeng Gu, Bingke Zhu, Guibo Zhu, Yingying Chen, Ming Tang, and Jinqiao Wang. Anoma- lygpt: Detecting industrial anomalies using large vision-language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 1932–1940, 2024
1932
-
[16]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review arXiv 2016
-
[17]
Back to the feature: classical 3d features are (almost) all you need for 3d anomaly detection
Eliahu Horwitz and Yedid Hoshen. Back to the feature: classical 3d features are (almost) all you need for 3d anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2968–2977, 2023
2023
-
[18]
Winclip: Zero-/few-shot anomaly classification and segmentation
Jongheon Jeong, Yang Zou, Taewan Kim, Dongqing Zhang, Avinash Ravichandran, and Onkar Dabeer. Winclip: Zero-/few-shot anomaly classification and segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19606–19616, 2023
2023
-
[19]
Towards scalable 3d anomaly detection and localization: A benchmark via 3d anomaly synthesis and a self-supervised learning network
Wenqiao Li, Xiaohao Xu, Yao Gu, Bozhong Zheng, Shenghua Gao, and Yingna Wu. Towards scalable 3d anomaly detection and localization: A benchmark via 3d anomaly synthesis and a self-supervised learning network. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22207–22216, 2024
2024
-
[20]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. InProceedings of the IEEE International Conference on Computer Vision, pages 2980–2988, 2017
2017
-
[21]
Real3d-ad: A dataset of point cloud anomaly detection.Advances in Neural Information Processing Systems, 36:30402–30415, 2023
Jiaqi Liu, Guoyang Xie, Ruitao Chen, Xinpeng Li, Jinbao Wang, Yong Liu, Chengjie Wang, and Feng Zheng. Real3d-ad: A dataset of point cloud anomaly detection.Advances in Neural Information Processing Systems, 36:30402–30415, 2023
2023
-
[22]
Aa-clip: Enhancing zero-shot anomaly detection via anomaly-aware clip
Wenxin Ma, Xu Zhang, Qingsong Yao, Fenghe Tang, Chenxu Wu, Yingtai Li, Rui Yan, Zihang Jiang, and S Kevin Zhou. Aa-clip: Enhancing zero-shot anomaly detection via anomaly-aware clip. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4744–4754, 2025
2025
-
[23]
Yunfeng Ma, Min Liu, Shuai Jiang, Jingyu Zhou, Yuan Bian, Xueping Wang, and Yaonan Wang. Zuma: Training-free zero-shot unified multimodal anomaly detection.IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–14, 2026. doi: 10.1109/TPAMI.2026. 3658856
-
[24]
V-net: Fully convolutional neural networks for volumetric medical image segmentation
Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In2016 Fourth International Conference on 3D Vision (3DV), pages 565–571. Ieee, 2016
2016
-
[25]
Bayesian prompt flow learning for zero-shot anomaly detection
Zhen Qu, Xian Tao, Xinyi Gong, Shichen Qu, Qiyu Chen, Zhengtao Zhang, Xingang Wang, and Guiguang Ding. Bayesian prompt flow learning for zero-shot anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 30398–30408, 2025
2025
-
[26]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, pages 8748–8763. PmLR, 2021
2021
-
[27]
Towards total recall in industrial anomaly detection
Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, and Peter Gehler. Towards total recall in industrial anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14318–14328, 2022. 11
2022
-
[28]
Asymmetric student- teacher networks for industrial anomaly detection
Marco Rudolph, Tom Wehrbein, Bodo Rosenhahn, and Bastian Wandt. Asymmetric student- teacher networks for industrial anomaly detection. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2592–2602, 2023
2023
-
[29]
Pointsgrade: Sparse learning with graph representation for anomaly detection by using unstructured 3d point cloud data.IISE Transactions, 57(2):131–144, 2025
Chengyu Tao and Juan Du. Pointsgrade: Sparse learning with graph representation for anomaly detection by using unstructured 3d point cloud data.IISE Transactions, 57(2):131–144, 2025
2025
-
[30]
G2sf: Geometry-guided score fusion for multimodal industrial anomaly detection
Chengyu Tao, Xuanming Cao, and Juan Du. G2sf: Geometry-guided score fusion for multimodal industrial anomaly detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20551–20560, 2025
2025
-
[31]
Mul- timodal industrial anomaly detection via hybrid fusion
Yue Wang, Jinlong Peng, Jiangning Zhang, Ran Yi, Yabiao Wang, and Chengjie Wang. Mul- timodal industrial anomaly detection via hybrid fusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8032–8041, 2023
2023
-
[32]
Cheating depth: Enhancing 3d surface anomaly detection via depth simulation
Vitjan Zavrtanik, Matej Kristan, and Danijel Skoˇcaj. Cheating depth: Enhancing 3d surface anomaly detection via depth simulation. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2164–2172, 2024
2024
-
[33]
Anomalyclip: Object- agnostic prompt learning for zero-shot anomaly detection
Qihang Zhou, Guansong Pang, Yu Tian, Shibo He, and Jiming Chen. Anomalyclip: Object- agnostic prompt learning for zero-shot anomaly detection. InThe Twelfth International Confer- ence on Learning Representations, 2023
2023
-
[34]
Pointad: Compre- hending 3d anomalies from points and pixels for zero-shot 3d anomaly detection.Advances in Neural Information Processing Systems, 37:84866–84896, 2024
Qihang Zhou, Jiangtao Yan, Shibo He, Wenchao Meng, and Jiming Chen. Pointad: Compre- hending 3d anomalies from points and pixels for zero-shot 3d anomaly detection.Advances in Neural Information Processing Systems, 37:84866–84896, 2024. A Dataset Dataset choice and description.We conduct experiments on three publicly available 3D anomaly detection dataset...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.