Recognition: unknown
Training-Free Dense Hand Contact Estimation with Multi-Modal Large Language Models
Pith reviewed 2026-05-09 16:22 UTC · model grok-4.3
The pith
Multi-modal LLMs can predict dense hand contacts at the vertex level without any training by feeding structured part-wise geometry and progressive reasoning prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
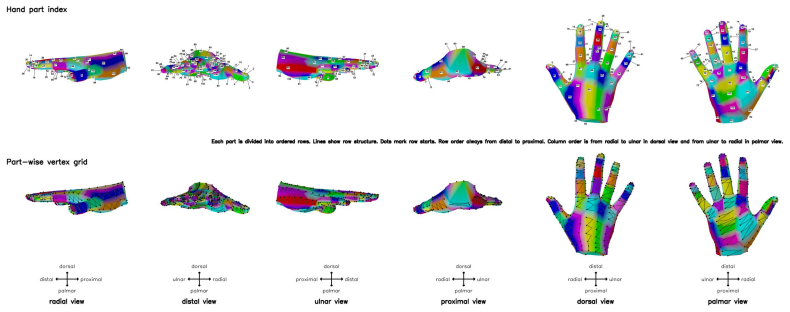
ContactPrompt is a training-free pipeline that encodes a 3D hand mesh through detailed part segmentation and part-wise vertex-grid representations, then performs multi-stage structured contact reasoning with part conditioning to translate global semantics into precise vertex-level contact maps inside a multi-modal LLM.
What carries the argument
The part-wise vertex-grid representation together with multi-stage contact reasoning and part conditioning, which converts 3D geometry into language-readable form and progressively refines contact decisions.
If this is right
- Dense contact labels become available for any hand mesh without collecting or annotating new training sets.
- The same MLLM can be reused for contact estimation across different hand shapes and interaction types.
- Part conditioning acts as an explicit bridge that forces the model to attend to local geometry rather than global semantics alone.
- Performance gains appear even though no gradient updates occur on contact data.
Where Pith is reading between the lines
- Input structuring may be a general way to unlock fine-grained spatial reasoning inside existing language models for other 3D tasks.
- The approach could be tested on full-body contact or object-object contact by extending the same part-grid and conditioning pattern.
- If inference speed improves, the method offers a path to on-device contact estimation without model retraining.
Load-bearing premise
The vision-language knowledge already inside the multi-modal LLM is enough to convert the supplied part grids and conditioning into correct vertex contact labels without ever seeing contact examples.
What would settle it
Running the method on a set of hand-object interactions whose contact patterns are deliberately outside the distribution of data the underlying LLM was trained on, and checking whether vertex predictions remain accurate.
Figures



read the original abstract
Dense hand contact estimation requires both high-level semantic understanding and fine-grained geometric reasoning of human interaction to accurately localize contact regions. Recently, multi-modal large language models (MLLMs) have demonstrated strong capabilities in understanding visual semantics, enabled by vision-language priors learned from large-scale data. However, leveraging MLLMs for dense hand contact estimation remains underexplored. There are two major challenges in applying MLLMs to dense hand contact estimation. First, encoding explicit 3D hand geometry is difficult, as MLLMs primarily operate on vision and language modalities. Second, capturing fine-grained vertex-level contact remains challenging, as MLLMs tend to focus on high-level semantics rather than detailed geometric reasoning. To address these challenges, we propose ContactPrompt, a training-free and zero-shot approach for dense hand contact estimation using MLLMs. To effectively encode 3D hand geometry, we introduce a detailed hand-part segmentation and a part-wise vertex-grid representation that provides structured, localized geometric information. To enable accurate and efficient dense contact prediction, we develop a multi-stage structured contact reasoning with part conditioning, progressively bridging global semantics and fine-grained geometry. Therefore, our method effectively leverages the reasoning capabilities of MLLMs while enabling precise dense hand contact estimation. Surprisingly, the proposed approach outperforms previous supervised methods trained on large-scale dense contact datasets without requiring any training. The codes will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ContactPrompt, a training-free zero-shot method for dense hand contact estimation that encodes 3D hand geometry via hand-part segmentation and a part-wise vertex-grid text representation, then applies multi-stage structured contact reasoning with part conditioning to elicit per-vertex contact predictions from an off-the-shelf MLLM. The central claim is that this pipeline outperforms prior supervised methods trained on large-scale dense contact datasets.
Significance. If the outperformance claim is substantiated with rigorous quantitative evaluation and ablations, the result would be significant: it would show that general-purpose MLLMs can be prompted to perform fine-grained, vertex-level geometric reasoning on 3D hand interactions without any task-specific training or fine-tuning, reducing dependence on annotated contact datasets in computer vision.
major comments (3)
- [Abstract] Abstract: the headline claim that the method 'outperforms previous supervised methods trained on large-scale dense contact datasets without requiring any training' is stated without any quantitative metrics, named baselines, evaluation protocol, or error analysis. The experiments section must supply concrete numbers (e.g., contact precision, recall, or IoU on standard benchmarks) and a clear comparison table to make this central assertion verifiable.
- [Method] Method (vertex-grid and decoding): the serialization of the 3D hand mesh into the part-wise vertex-grid text format and the exact procedure for decoding contact labels from the MLLM's textual output are not described with sufficient precision (no pseudocode, example input/output strings, or parsing rules). This detail is load-bearing for assessing whether the predictions are truly vertex-precise or merely coarse semantic guesses.
- [Experiments] Experiments: no ablation studies are reported that isolate the contribution of the multi-stage structured reasoning and part conditioning from simpler direct prompting of the MLLM. Given known MLLM weaknesses on precise spatial localization from abstracted text grids, such ablations are required to establish that the reported gains arise from the proposed pipeline rather than other factors.
minor comments (1)
- [Abstract] The acronym MLLM should be expanded on first use in the abstract and introduction for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing honest responses and committing to revisions where appropriate to improve clarity, reproducibility, and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that the method 'outperforms previous supervised methods trained on large-scale dense contact datasets without requiring any training' is stated without any quantitative metrics, named baselines, evaluation protocol, or error analysis. The experiments section must supply concrete numbers (e.g., contact precision, recall, or IoU on standard benchmarks) and a clear comparison table to make this central assertion verifiable.
Authors: We agree that the abstract's claim would be stronger and more verifiable with direct reference to quantitative results. The manuscript's experiments section already reports evaluations on standard dense contact benchmarks (e.g., ContactHands) with comparisons to supervised baselines using metrics such as contact IoU. To address the comment fully, we will revise the abstract to briefly cite key performance figures and ensure the experiments section features a clear, prominent comparison table that explicitly names baselines, describes the evaluation protocol, and includes error analysis. revision: yes
-
Referee: [Method] Method (vertex-grid and decoding): the serialization of the 3D hand mesh into the part-wise vertex-grid text format and the exact procedure for decoding contact labels from the MLLM's textual output are not described with sufficient precision (no pseudocode, example input/output strings, or parsing rules). This detail is load-bearing for assessing whether the predictions are truly vertex-precise or merely coarse semantic guesses.
Authors: We acknowledge that greater precision in describing the vertex-grid serialization and decoding steps is essential for reproducibility and to confirm the vertex-level granularity of predictions. In the revised manuscript, we will add pseudocode for the part-wise vertex-grid construction process, concrete examples of input prompt strings and corresponding MLLM outputs, and explicit parsing rules for mapping textual contact labels back to specific vertices. This will substantiate that the approach achieves fine-grained rather than coarse predictions. revision: yes
-
Referee: [Experiments] Experiments: no ablation studies are reported that isolate the contribution of the multi-stage structured reasoning and part conditioning from simpler direct prompting of the MLLM. Given known MLLM weaknesses on precise spatial localization from abstracted text grids, such ablations are required to establish that the reported gains arise from the proposed pipeline rather than other factors.
Authors: We agree that targeted ablations are necessary to isolate the benefits of the multi-stage structured reasoning and part conditioning, especially given potential MLLM limitations on spatial tasks. While the current experiments demonstrate the end-to-end effectiveness of ContactPrompt, we will add new ablation studies in the revision. These will directly compare the full pipeline against simpler baselines using direct prompting of the MLLM on the vertex-grid input, quantifying the incremental contributions of each proposed component. revision: yes
Circularity Check
No significant circularity; prompting pipeline is self-contained against external baselines
full rationale
The paper describes a training-free, zero-shot ContactPrompt pipeline that encodes 3D hand geometry via part segmentation and vertex-grid text representations, then applies multi-stage structured prompting to an off-the-shelf MLLM. No equations, parameter fittings, or derivations appear. Performance claims are positioned as empirical comparisons to external supervised methods rather than outputs derived from the method's own inputs or self-citations. The central premise (MLLM zero-shot accuracy on the provided abstractions) is an unverified empirical assumption, not a self-definitional or fitted tautology. This is the expected honest non-finding for a prompting-based method without mathematical reduction steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLLMs can perform fine-grained geometric reasoning over structured text or grid inputs without task-specific training
invented entities (1)
-
ContactPrompt
no independent evidence
Reference graph
Works this paper leans on
-
[1]
System card: Claude Opus 4.7, 2026
Anthropic. System card: Claude Opus 4.7, 2026
2026
-
[2]
System card: Claude Sonnet 4.6, 2026
Anthropic. System card: Claude Sonnet 4.6, 2026
2026
-
[3]
NGL-Prompter: Training-free sewing pattern estimation from a single image
Anna Badalyan, Pratheba Selvaraju, Giorgio Becherini, Omid Taheri, Victoria Fernandez Abrevaya, and Michael Black. NGL-Prompter: Training-free sewing pattern estimation from a single image. In3DV, 2026
2026
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Reconstructing hand-object interactions in the wild
Zhe Cao, Ilija Radosavovic, Angjoo Kanazawa, and Jitendra Malik. Reconstructing hand-object interactions in the wild. InICCV, 2021
2021
-
[6]
DexYCB: A benchmark for capturing hand grasping of objects
Yu-Wei Chao, Wei Yang, Yu Xiang, Pavlo Molchanov, Ankur Handa, Jonathan Tremblay, Yashraj S Narang, Karl Van Wyk, Umar Iqbal, Stan Birchfield, Jan Kautz, and Dieter Fox. DexYCB: A benchmark for capturing hand grasping of objects. InCVPR, 2021
2021
-
[7]
Learning to disambiguate strongly interacting hands via probabilistic per-pixel part segmentation
Zicong Fan, Adrian Spurr, Muhammed Kocabas, Siyu Tang, Michael J Black, and Otmar Hilliges. Learning to disambiguate strongly interacting hands via probabilistic per-pixel part segmentation. In3DV, 2021
2021
-
[8]
ARCTIC: A dataset for dexterous bimanual hand-object manipulation
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kaufmann, Michael J Black, and Otmar Hilliges. ARCTIC: A dataset for dexterous bimanual hand-object manipulation. InCVPR, 2023
2023
-
[9]
Transcribe3D: Grounding LLMs using transcribed information for 3D referential reasoning with self-corrected finetuning
Jiading Fang, Xiangshan Tan, Shengjie Lin, Hongyuan Mei, and Matthew Walter. Transcribe3D: Grounding LLMs using transcribed information for 3D referential reasoning with self-corrected finetuning. InCoRL, 2023
2023
-
[10]
Chat-Edit-3D: Interactive 3D scene editing via text prompts
Shuangkang Fang, Yufeng Wang, Yi-Hsuan Tsai, Yi Yang, Wenrui Ding, Shuchang Zhou, and Ming-Hsuan Yang. Chat-Edit-3D: Interactive 3D scene editing via text prompts. InECCV, 2024
2024
-
[11]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 2025
2025
-
[12]
TSTMotion: Training-free scene-aware text-to-motion generation
Ziyan Guo, Haoxuan Qu, Hossein Rahmani, Dewen Soh, Ping Hu, Qiuhong Ke, and Jun Liu. TSTMotion: Training-free scene-aware text-to-motion generation. InICME, 2025
2025
-
[13]
HOnnotate: A method for 3D annotation of hand and object poses
Shreyas Hampali, Mahdi Rad, Markus Oberweger, and Vincent Lepetit. HOnnotate: A method for 3D annotation of hand and object poses. InCVPR, 2020
2020
-
[14]
Keypoint Transformer: Solving joint identification in challenging hands and object interactions for accurate 3D pose estimation
Shreyas Hampali, Sayan Deb Sarkar, Mahdi Rad, and Vincent Lepetit. Keypoint Transformer: Solving joint identification in challenging hands and object interactions for accurate 3D pose estimation. InCVPR, 2022
2022
-
[15]
Resolving 3D human pose ambiguities with 3D scene constraints
Mohamed Hassan, Vasileios Choutas, Dimitrios Tzionas, and Michael J Black. Resolving 3D human pose ambiguities with 3D scene constraints. InICCV, 2019
2019
-
[16]
Populating 3D scenes by learning human-scene interaction
Mohamed Hassan, Partha Ghosh, Joachim Tesch, Dimitrios Tzionas, and Michael J Black. Populating 3D scenes by learning human-scene interaction. InCVPR, 2021
2021
-
[17]
Learning joint reconstruction of hands and manipulated objects
Yana Hasson, Gul Varol, Dimitrios Tzionas, Igor Kalevatykh, Michael J Black, Ivan Laptev, and Cordelia Schmid. Learning joint reconstruction of hands and manipulated objects. InCVPR, 2019
2019
-
[18]
Capturing and inferring dense full-body human-scene contact
Chun-Hao P Huang, Hongwei Yi, Markus Höschle, Matvey Safroshkin, Tsvetelina Alexiadis, Senya Polikovsky, Daniel Scharstein, and Michael J Black. Capturing and inferring dense full-body human-scene contact. InCVPR, 2022. 10
2022
-
[19]
Learning dense hand contact estimation from imbalanced data
Daniel Sungho Jung and Kyoung Mu Lee. Learning dense hand contact estimation from imbalanced data. InNeurIPS, 2025
2025
-
[20]
PromptVFX: Text-driven fields for open-world 3D gaussian animation
Mert Kiray, Paul Uhlenbruck, Nassir Navab, and Benjamin Busam. PromptVFX: Text-driven fields for open-world 3D gaussian animation. In3DV, 2026
2026
-
[21]
H2O: Two hands manipulating objects for first person interaction recognition
Taein Kwon, Bugra Tekin, Jan Stühmer, Federica Bogo, and Marc Pollefeys. H2O: Two hands manipulating objects for first person interaction recognition. InICCV, 2021
2021
-
[22]
GECO: GPT-driven estimation of 3D human-scene contact in the wild
Chaehong Lee, Simranjit Singh, Michael Fore, Georgios Pavlakos, and Dimitrios Stamoulis. GECO: GPT-driven estimation of 3D human-scene contact in the wild. InECCV, 2024
2024
-
[23]
See&Trek: Training-free spatial prompting for multimodal large language model
Pengteng Li, Pinhao Song, Wuyang Li, Huizai Yao, Weiyu Guo, Yijie Xu, Dugang Liu, and Hui Xiong. See&Trek: Training-free spatial prompting for multimodal large language model. In NeurIPS, 2025
2025
-
[24]
3DAxisPrompt: Promoting the 3D grounding and reasoning in GPT-4o.Neurocomputing, 2025
Dingning Liu, Cheng Wang, Peng Gao, Renrui Zhang, Xinzhu Ma, Yuan Meng, and Zhihui Wang. 3DAxisPrompt: Promoting the 3D grounding and reasoning in GPT-4o.Neurocomputing, 2025
2025
-
[25]
HOI4D: A 4D egocentric dataset for category-level human-object interaction
Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, and Li Yi. HOI4D: A 4D egocentric dataset for category-level human-object interaction. InCVPR, 2022
2022
-
[26]
The target has a shorter shade
Sining Lu, Guan Chen, Nam Anh Dinh, Itai Lang, Ari Holtzman, and Rana Hanocka. LL3M: Large language 3D modelers.arXiv preprint arXiv:2508.08228, 2025
-
[27]
InterHand2.6M: A dataset and baseline for 3D interacting hand pose estimation from a single RGB image
Gyeongsik Moon, Shoou-I Yu, He Wen, Takaaki Shiratori, and Kyoung Mu Lee. InterHand2.6M: A dataset and baseline for 3D interacting hand pose estimation from a single RGB image. In ECCV, 2020
2020
-
[28]
GPT-5.4 thinking system card, 2026
OpenAI. GPT-5.4 thinking system card, 2026
2026
-
[29]
GPT-5.5 system card, 2026
OpenAI. GPT-5.5 system card, 2026
2026
-
[30]
Expressive body capture: 3D hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3D hands, face, and body from a single image. InCVPR, 2019
2019
-
[31]
Embodied hands: Modeling and capturing hands and bodies together.ACM TOG, 2017
Javier Romero, Dimitrios Tzionas, and Michael J Black. Embodied hands: Modeling and capturing hands and bodies together.ACM TOG, 2017
2017
-
[32]
Decaf: Monocular deformation capture for face and hand interactions.ACM TOG, 2023
Soshi Shimada, Vladislav Golyanik, Patrick Pérez, and Christian Theobalt. Decaf: Monocular deformation capture for face and hand interactions.ACM TOG, 2023
2023
-
[33]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. OpenAI GPT-5 system card. arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Learning structured output representation using deep conditional generative models
Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning structured output representation using deep conditional generative models. InNeurIPS, 2015
2015
-
[35]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
DECO: Dense estimation of 3D human-scene contact in the wild
Shashank Tripathi, Agniv Chatterjee, Jean-Claude Passy, Hongwei Yi, Dimitrios Tzionas, and Michael J Black. DECO: Dense estimation of 3D human-scene contact in the wild. InICCV, 2023
2023
-
[37]
Capturing hands in action using discriminative salient points and physics simulation
Dimitrios Tzionas, Luca Ballan, Abhilash Srikantha, Pablo Aponte, Marc Pollefeys, and Juergen Gall. Capturing hands in action using discriminative salient points and physics simulation. IJCV, 2016. 11
2016
-
[38]
AffordDexGrasp: Open-set language-guided dexterous grasp with generalizable- instructive affordance
Yi-Lin Wei, Mu Lin, Yuhao Lin, Jian-Jian Jiang, Xiao-Ming Wu, Ling-An Zeng, and Wei- Shi Zheng. AffordDexGrasp: Open-set language-guided dexterous grasp with generalizable- instructive affordance. InICCV, 2025
2025
-
[39]
SG-Nav: Online 3D scene graph prompting for LLM-based zero-shot object navigation.NeurIPS, 2024
Hang Yin, Xiuwei Xu, Zhenyu Wu, Jie Zhou, and Jiwen Lu. SG-Nav: Online 3D scene graph prompting for LLM-based zero-shot object navigation.NeurIPS, 2024
2024
-
[40]
Hi4D: 4D instance segmentation of close human interaction
Yifei Yin, Chen Guo, Manuel Kaufmann, Juan Jose Zarate, Jie Song, and Otmar Hilliges. Hi4D: 4D instance segmentation of close human interaction. InCVPR, 2023
2023
-
[41]
contact_parts
Fanghua Yu, Jinjin Gu, Zheyuan Li, Jinfan Hu, Xiangtao Kong, Xintao Wang, Jingwen He, Yu Qiao, and Chao Dong. Scaling up to excellence: Practicing model scaling for photo-realistic image restoration in the wild. InCVPR, 2024. 12 A Appendix In this appendix, we provide additional technical details of ContactPrompt that were omitted from the main manuscript...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.