Recognition: unknown
Understanding Cross-Language Transfer Improvements in Low-Resource HTR: The Role of Sequence Modeling
Pith reviewed 2026-05-09 16:02 UTC · model grok-4.3
The pith
Cross-language gains in low-resource Arabic-script HTR arise from sequence modeling rather than shared visual features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
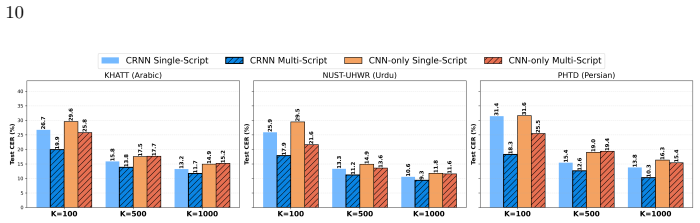
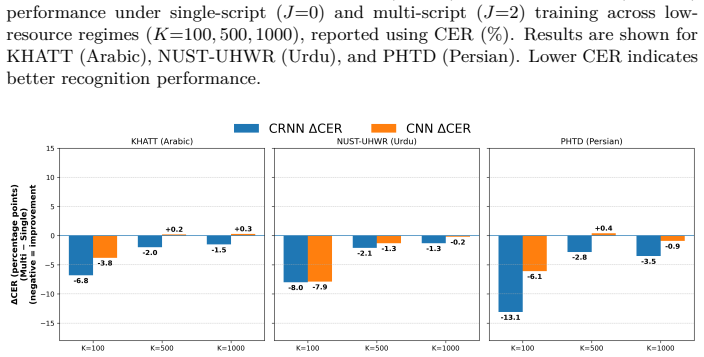
A controlled comparison of CNN-only and CRNN models on line-level HTR for Arabic (KHATT), Urdu (NUST-UHWR), and Persian (PHTD) under low-resource regimes (100, 500, or 1000 lines) reveals that multi-script training improves character error rate only for CRNN models. CNN-only models show limited or unstable transfer. The paper concludes that sequence-level modeling, not the visual representations learned by the shared CNN encoder, accounts for the observed cross-language improvements.
What carries the argument
The side-by-side evaluation of CNN-only models using CTC against CRNN models that combine the same CNN encoder with recurrent sequence modeling, run under identical single-script and multi-script training schedules.
If this is right
- Including recurrent or transformer-based sequence layers makes joint training across scripts more effective in data-scarce settings.
- Visual shape similarity across scripts is not enough by itself to produce reliable transfer.
- Contextual modeling of character sequences becomes especially valuable when labeled lines per language fall below a few hundred.
Where Pith is reading between the lines
- The same pattern may appear in low-resource OCR for other scripts that share visual but not linguistic features.
- Isolating the recurrent component in future ablations could reveal whether bidirectional context or just longer-range dependencies drives the gains.
- Sequence modeling might also help transfer in tasks where the output is a sequence of tokens rather than isolated characters.
Load-bearing premise
The performance gap between CNN-only and CRNN models under multi-script training stems from the addition of sequence modeling rather than from differences in total model capacity, optimization, or dataset quirks.
What would settle it
Training a CNN-only model whose total parameter count and training schedule match those of the CRNN and still finding no consistent multi-script improvement.
Figures


read the original abstract
Handwritten Text Recognition (HTR) for Arabic-script languages benefits from cross-language joint training under low-resource conditions, particularly when using CRNN-based models that combine convolutional encoders with sequence modeling. However, it remains unclear whether these improvements are better explained by shared visual representations or sequence-level dependencies. In this work, we conduct a controlled architectural study of line-level Arabic-script HTR, comparing CNN-only models with CTC decoding and CRNN models under identical single-script and multi-script training regimes. Experiments are performed on Arabic (KHATT), Urdu (NUST-UHWR), and Persian (PHTD) datasets under low-resource settings (K in {100, 500, 1000}). Our results show a clear divergence in transfer behavior: while CNN-only models exhibit limited or unstable improvements, CRNN models achieve better performance under multi-script training, particularly in the most data-constrained regimes. Focusing on transfer improvements (delta CER) rather than absolute performance, we find that cross-language improvements are associated with sequence-level modeling, while sharing visual representations learned by the CNN encoder, corresponding to similarities in character shapes across scripts, alone appears to be insufficient. This finding suggests that contextual modeling plays an important role in enabling effective transfer in low-resource scenarios, and that similar behavior may extend to other low-resource language settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts a controlled empirical comparison of CNN-only (with CTC) versus CRNN architectures for line-level HTR on Arabic-script languages. Using low-resource subsets (K=100/500/1000) from KHATT (Arabic), NUST-UHWR (Urdu), and PHTD (Persian), it reports that multi-script training yields larger CER reductions for CRNN models than for CNN-only models. The central claim is that these transfer gains are attributable to sequence-level modeling rather than shared visual features learned by the CNN encoder alone.
Significance. If the attribution to sequence modeling survives controls for capacity and optimization, the result would clarify why recurrent components enable better cross-script generalization in low-resource HTR, beyond visual shape overlap. The emphasis on delta CER, use of public datasets, and explicit single- versus multi-script regimes constitute a useful empirical contribution to transfer-learning analysis in document analysis.
major comments (1)
- [Experimental setup and results sections] The experimental comparison does not control for model capacity. CRNN architectures add recurrent layers atop the CNN encoder, increasing parameter count and expressive power relative to the CNN-only baseline. In the low-resource regimes examined, this difference alone could produce the observed divergence in transfer behavior, independent of sequence modeling per se. This directly undermines the claim that sequence-level dependencies, rather than capacity, explain the gains (see also the weakest assumption noted in the review).
minor comments (1)
- [Abstract and results] The abstract states a 'clear divergence' without reference to error bars, run-to-run variance, or significance tests; these should be added to the results tables and figures to support the reported transfer deltas.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the empirical contribution. The major comment on model capacity is valid and directly relevant to strengthening the attribution of transfer gains to sequence modeling. We address it below with a commitment to revision.
read point-by-point responses
-
Referee: The experimental comparison does not control for model capacity. CRNN architectures add recurrent layers atop the CNN encoder, increasing parameter count and expressive power relative to the CNN-only baseline. In the low-resource regimes examined, this difference alone could produce the observed divergence in transfer behavior, independent of sequence modeling per se. This directly undermines the claim that sequence-level dependencies, rather than capacity, explain the gains (see also the weakest assumption noted in the review).
Authors: We acknowledge that the CRNN models have substantially higher capacity due to the added recurrent layers (approximately 2-3x parameters depending on the exact configuration), and our experiments did not include an explicit capacity-matched CNN-only control. The design kept the CNN encoder identical across conditions to isolate the effect of adding sequence modeling, and the key observation is the divergence in delta CER (transfer improvement) rather than absolute performance. However, this does not fully rule out capacity as a confounding factor. In the revision, we will add a new experiment section with a capacity-controlled CNN baseline: we will increase the depth and/or width of the CNN-only model (e.g., additional convolutional blocks with matching channel dimensions) to reach a comparable parameter count to the CRNN, then re-run the single-script vs. multi-script comparisons on the same low-resource splits (K=100/500/1000). We will report the resulting delta CER values and discuss whether the transfer advantage persists. This will either corroborate or qualify the central claim. We will also update the discussion to explicitly note the capacity limitation of the original comparison. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential reductions
full rationale
The paper conducts a controlled experimental study comparing CNN-only and CRNN architectures for cross-language HTR transfer on public datasets (KHATT, NUST-UHWR, PHTD) under low-resource regimes. No mathematical derivations, equations, fitted parameters presented as predictions, uniqueness theorems, or ansatzes are present in the provided text. The central claim—that transfer improvements associate with sequence modeling rather than visual sharing alone—rests directly on reported delta CER differences between the two model classes under identical training conditions. This is self-contained empirical evidence without any load-bearing step that reduces by construction to its own inputs or prior self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Datasets represent comparable low-resource scenarios across scripts
Reference graph
Works this paper leans on
-
[1]
E. F. Bilgin Tasdemir, Printed Ottoman text recognition using synthetic data and data augmentation, International Journal on Document Analysis and Recognition (IJDAR) 26 (3) (2023) 273–287
2023
-
[2]
Cross-Language Learning within Arabic Script for Low-Resource HTR
S. Al-azzawi, E. Barney, M. Liwicki, Cross-Language Learning within Ara- bic Script for Low-Resource HTR, arXiv:2605.02089 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Borisyuk, A
F. Borisyuk, A. Gordo, V. Sivakumar, Rosetta: Large scale system for text detection and recognition in images, in: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018, pp. 71–79
2018
-
[4]
J. Baek, G. Kim, J. Lee, S. Park, D. Han, S. Yun, S. J. Oh, H. Lee, What is wrong with scene text recognition model comparisons? dataset and model analysis, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 4715–4723
2019
- [5]
-
[6]
Coquenet, C
D. Coquenet, C. Chatelain, T. Paquet, Recurrence-free unconstrained hand- written text recognition using gated fully convolutional network, in: 2020 17th International Conference on Frontiers in Handwriting Recognition (ICFHR), IEEE, 2020, pp. 19–24
2020
-
[7]
S. A. Mahmoud, I. Ahmad, W. G. Al-Khatib, M. Alshayeb, M. T. Parvez, V. Märgner, G. A. Fink, KHATT: An open Arabic offline handwritten text database, Pattern Recognition 47 (3) (2014) 1096–1112
2014
-
[8]
ul Sehr Zia, M
N. ul Sehr Zia, M. F. Naeem, S. M. K. Raza, M. M. Khan, A. Ul-Hasan, F. Shafait, A convolutional recursive deep architecture for unconstrained Urdu handwriting recognition, Neural Computing and Applications 34 (2) (2022) 1635–1648
2022
-
[9]
Alaei, U
A. Alaei, U. Pal, P. Nagabhushan, Dataset and ground truth for handwrit- ten text in four different scripts, International Journal of Pattern Recogni- tion and Artificial Intelligence 26 (04) (2012) 1253001
2012
-
[10]
C. Luo, Y. Zhu, L. Jin, Y. Wang, Learn to augment: Joint data augmen- tation and network optimization for text recognition, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 13746–13755. 15
2020
-
[11]
Salaheldin Kasem, M
M. Salaheldin Kasem, M. Mahmoud, H.-S. Kang, Advancements and chal- lenges in Arabic optical character recognition: A comprehensive survey, ACM Computing Surveys 58 (4) (2025) 1–37
2025
-
[12]
Ahmad, S
R. Ahmad, S. Naz, M. Z. Afzal, S. F. Rashid, M. Liwicki, A. Dengel, The impact of visual similarities of Arabic-like scripts regarding learning in an OCR system, in: 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Vol. 7, IEEE, 2017, pp. 15–19
2017
-
[13]
Nemati, C
F. Nemati, C. Westbury, G. Hollis, H. Haghbin, The Persian lexicon project: minimized orthographic neighbourhood effects in a dense language, Journal of Psycholinguistic Research 51 (5) (2022) 957–979
2022
-
[14]
Corbillé, E
S. Corbillé, E. H. Barney Smith, Applying center loss to neural networks for sequence prediction: A study for handwriting recognition, in: International Joint Conference on Neural Networks (IJCNN), IEEE, 2025
2025
-
[15]
Barrere, Y
K. Barrere, Y. Soullard, A. Lemaitre, B. Coüasnon, Training transformer architectures on few annotated data: an application to historical hand- written text recognition, International Journal on Document Analysis and Recognition 27 (4) (2024) 553–566
2024
-
[16]
Retsinas, G
G. Retsinas, G. Sfikas, B. Gatos, C. Nikou, Best practices for a handwritten text recognition system, in: International Workshop on Document Analysis Systems, Springer, 2022, pp. 247–259
2022
-
[17]
S. Al-azzawi, E. Barney, M. Liwicki, CER-HV: A human-in-the-loop frame- work for cleaning datasets applied to Arabic-script HTR, arXiv preprint arXiv:2601.16713 (2026)
-
[18]
Ul-Hasan, T
A. Ul-Hasan, T. M. Breuel, Can we build language-independent OCR using LSTM networks?, in: Proceedings of the 4th International Workshop on Multilingual OCR, 2013, pp. 1–5
2013
-
[19]
N. Riaz, H. Arbab, A. Maqsood, K. Nasir, A. Ul-Hasan, F. Shafait, Conv- transformer architecture for unconstrained off-line Urdu handwriting recog- nition, International Journal on Document Analysis and Recognition (IJ- DAR) 25 (4) (2022) 373–384
2022
-
[20]
Hamza, S
A. Hamza, S. Ren, U. Saeed, ET-Network: A novel efficient transformer deep learning model for automated Urdu handwritten text recognition, PLOS One 19 (5) (2024) e0302590
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.