Recognition: unknown
Toward design-based inference for data integration
Pith reviewed 2026-05-08 07:41 UTC · model grok-4.3
The pith
Treating non-probability samples as certainty strata allows design-consistent finite population inference without any assumptions on their selection mechanism.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that by using a two-phase sampling design where the non-probability sample constitutes the first phase with certainty, generalized regression estimators can be constructed that are consistent for the population total under the overall sampling design, irrespective of the mechanism that generated the non-probability sample.
What carries the argument
The sequential framework treating the observed non-probability sample as a certainty stratum from which a probability sample is subsequently drawn from the complement, enabling design-based generalized regression estimation without selection modeling.
If this is right
- Population parameters can be estimated consistently even under NMAR selection for the non-probability data.
- Consistent variance estimation is available directly from the design.
- A diagnostic test helps decide between separate and combined regression based on stratum homogeneity.
- The non-probability sample can be used to optimize the second-stage sampling probabilities under a working model.
Where Pith is reading between the lines
- This method could be applied in official statistics to combine administrative data with targeted surveys.
- It opens the door to efficiency gains by using large non-probability samples to guide where to allocate probability sampling resources.
- Future work might extend the approach to more than two phases or incorporate multiple non-probability sources.
Load-bearing premise
After observing the non-probability sample, it must be feasible to draw a probability sample from the complementary part of the population.
What would settle it
Compare the estimator to the known population total in a simulation where the non-probability sample is selected based on the outcome variable and the probability sample from the complement is drawn with known inclusion probabilities; significant bias would falsify the consistency claim.
Figures

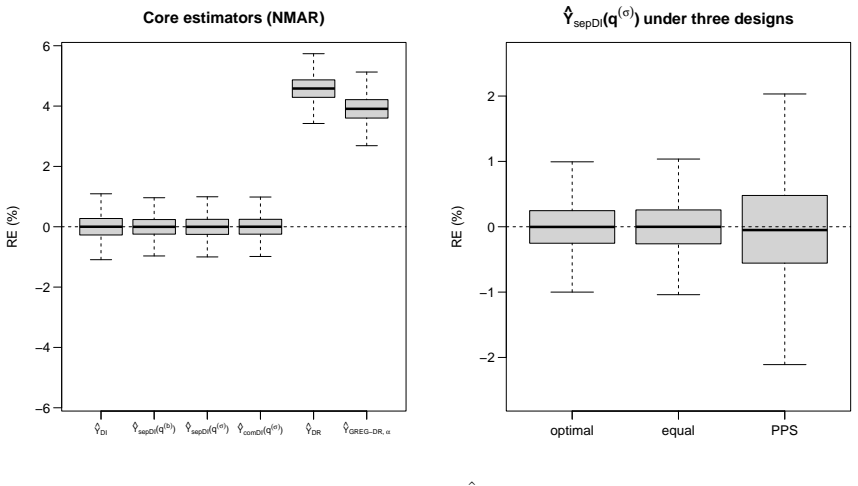

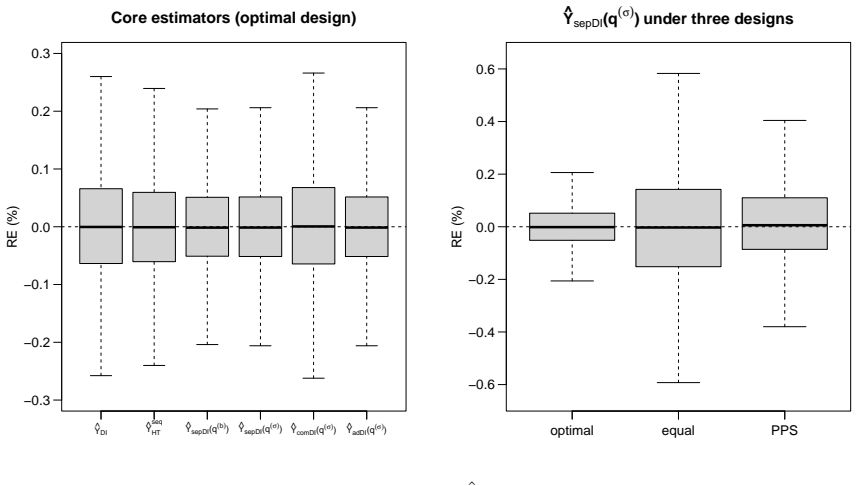
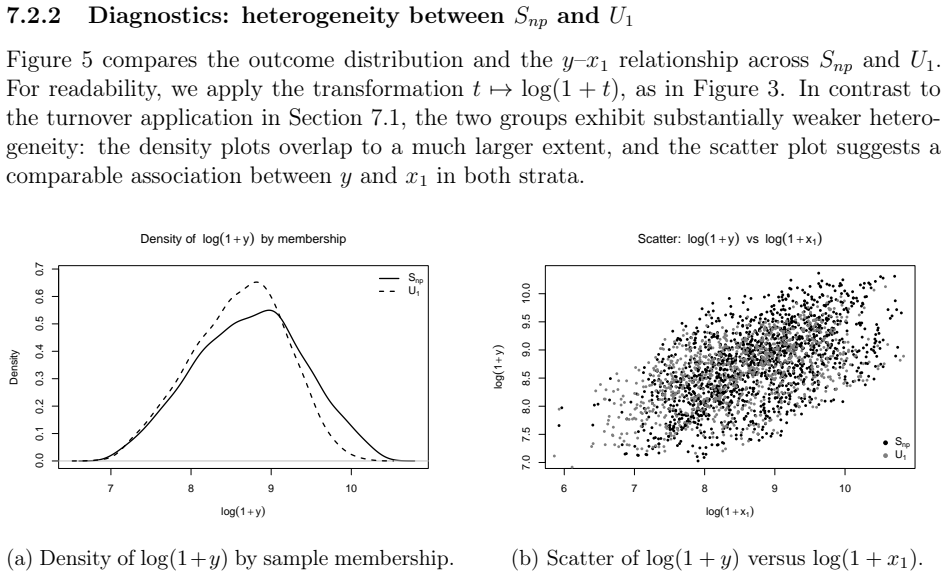
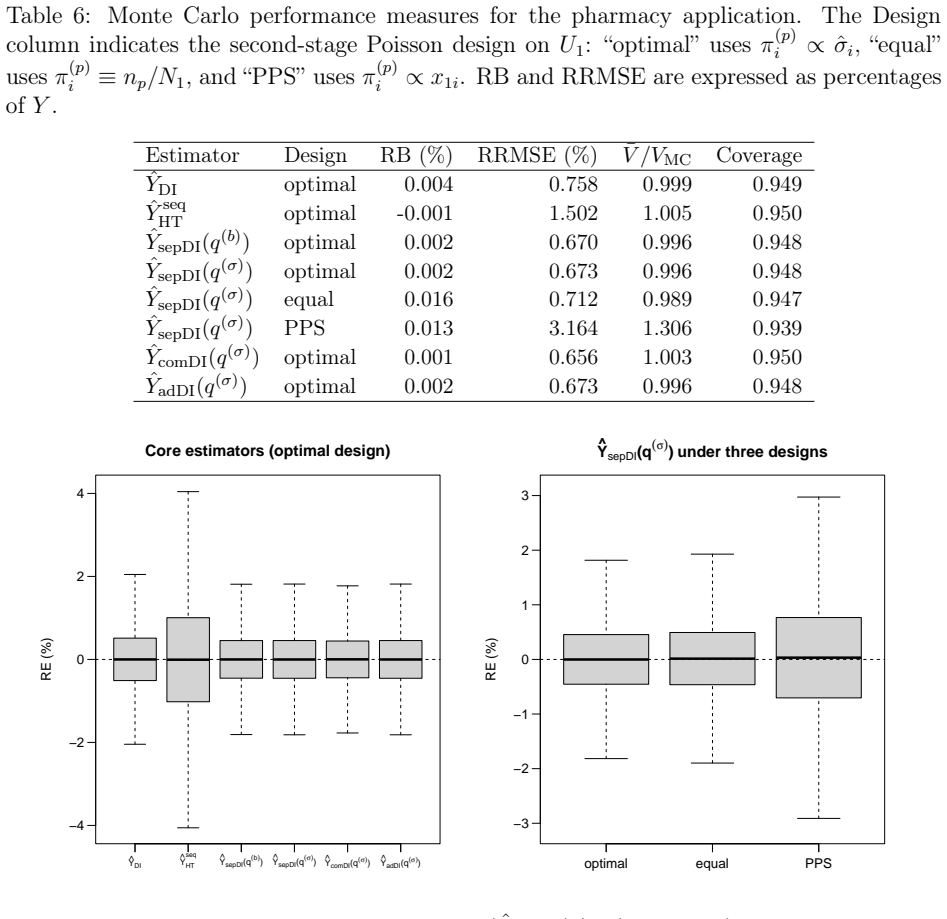
read the original abstract
Integrating non-probability samples into finite-population inference typically requires modeling unknown selection probabilities under a missing-at-random (MAR) assumption that is difficult to verify. We propose a design-based alternative in which the non-probability sample is treated as a fully observed certainty stratum and a probability sample is drawn only from the complementary, previously unsampled units. Within this sequential framework, we develop two generalized regression estimators: one fitting the outcome model separately in the complementary stratum, the other pooling both samples; we make two distinct contributions. First, both estimators are design-consistent and admit consistent variance estimators with no assumption whatsoever on the non-probability selection mechanism, including under not-missing-at-random (NMAR) selection. Second, under a working superpopulation model that holds in both strata, the pilot non-probability sample can be used to construct second-stage inclusion probabilities that achieve Isaki-Fuller asymptotic optimality for the separate estimator; this optimality claim relies on assumptions strictly stronger than MAR, but its failure does not invalidate the consistency results above. A diagnostic test for coefficient homogeneity is proposed to guide the choice between the two estimators. Simulations confirm that the sequential estimators remain essentially unbiased under both MAR and NMAR, while propensity-adjusted competitors can be severely biased under NMAR. Two applications from Lithuanian official statistics illustrate that separate regression is preferable when the pilot stratum and its complement are strongly heterogeneous, whereas combined regression offers a modest efficiency gain when the two strata are similar.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a sequential design-based framework for finite-population inference with integrated non-probability samples. The non-probability sample is treated as a fully observed certainty stratum, after which a probability sample is drawn from the complementary units. Two generalized regression estimators are developed: one fitting the outcome model separately within the complement and one pooling both samples. Both are claimed to be design-consistent for the population total (with consistent variance estimators) under arbitrary non-probability selection mechanisms, including NMAR, with no modeling assumptions required on selection. Under a working superpopulation model, the pilot sample informs second-stage probabilities for asymptotic optimality of the separate estimator (conditional on stronger assumptions than MAR). A diagnostic test for coefficient homogeneity guides estimator choice. Simulations show near-unbiased performance under MAR and NMAR (unlike propensity methods under NMAR), and two Lithuanian official statistics applications illustrate practical use.
Significance. If the central claims hold, the work provides a valuable design-based route to data integration that avoids unverifiable MAR assumptions on unknown selection probabilities, a common practical barrier in official statistics. The design-consistency result, which follows from Horvitz-Thompson unbiasedness for the auxiliaries once the certainty stratum is fixed, is a clear strength and is supported by the simulation evidence of robustness under NMAR. The consistent variance estimators, optimality result (explicitly caveated), and homogeneity diagnostic add to the contribution's utility. The approach is grounded in finite-population principles and could meaningfully influence integration practices where a second-stage probability sample from the complement is feasible.
major comments (2)
- [Theoretical development of variance estimators] The design-consistency and variance-estimator consistency claims are load-bearing for the first contribution. Explicit derivations of the variance formulas (or at minimum the precise form of the variance estimator and the conditions for its consistency) should be provided in the theoretical section, as the abstract asserts consistency without assumptions on the non-probability mechanism but the auditability of this step is limited without the details.
- [Framework description and consistency proof] The sequential framework treats the non-probability sample as a certainty stratum with inclusion probability 1 and draws the probability sample only from the complement. While this is presented as a design choice, the manuscript should explicitly state the conditions under which such a second-stage sample can be drawn in practice and discuss any resulting limitations on applicability, because this underpins the Horvitz-Thompson property used for unbiasedness.
minor comments (4)
- [Abstract] The abstract states that 'we make two distinct contributions' but then folds the optimality result and diagnostic test into the narrative; rephrasing to list the contributions more crisply would improve readability.
- [Simulations] In the simulation section, report the exact finite-population size, sample sizes for both stages, and the precise mechanism used to generate the non-probability sample under NMAR (e.g., how the selection probabilities are constructed) to facilitate replication and verification of the unbiasedness results.
- [Applications] The applications section would benefit from a brief table or description of the auxiliary variables employed in the GREG calibration and the outcome of the homogeneity diagnostic test, so readers can see how the choice between separate and combined estimators was made.
- [Notation and definitions] Notation for the two estimators (separate vs. pooled) and for the inclusion probabilities should be introduced once and used consistently; a small notation table or clear definitions early in the methods would reduce ambiguity.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the detailed suggestions for improving the manuscript. We address each major comment below and have revised the paper accordingly to enhance clarity and completeness.
read point-by-point responses
-
Referee: [Theoretical development of variance estimators] The design-consistency and variance-estimator consistency claims are load-bearing for the first contribution. Explicit derivations of the variance formulas (or at minimum the precise form of the variance estimator and the conditions for its consistency) should be provided in the theoretical section, as the abstract asserts consistency without assumptions on the non-probability mechanism but the auditability of this step is limited without the details.
Authors: We agree that the explicit derivations strengthen the theoretical section. In the revised manuscript, we have added a dedicated subsection (Section 3.3) that provides the full derivations of the variance estimators for both the separate and pooled generalized regression estimators. Starting from the Horvitz-Thompson unbiasedness for the auxiliary totals (which holds once the certainty stratum is fixed), we derive the exact variance expressions under the sequential design and state the conditions for design-consistency of the variance estimators without any assumptions on the non-probability selection mechanism. These derivations are now in the main text rather than relying solely on the appendix. revision: yes
-
Referee: [Framework description and consistency proof] The sequential framework treats the non-probability sample as a certainty stratum with inclusion probability 1 and draws the probability sample only from the complement. While this is presented as a design choice, the manuscript should explicitly state the conditions under which such a second-stage sample can be drawn in practice and discuss any resulting limitations on applicability, because this underpins the Horvitz-Thompson property used for unbiasedness.
Authors: We have revised the framework description in Section 2 to explicitly state the practical conditions required: the availability of a sampling frame for the target finite population that permits identification of the non-probability sample units so they can be excluded from the second-stage draw. We now discuss the resulting limitations, including scenarios with incomplete frames, imperfect matching between the non-probability sample and the frame, or logistical constraints on drawing from the complement. These additions clarify when the Horvitz-Thompson property applies and the scope of applicability, while noting that the design-consistency results remain valid under the stated conditions. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims of design-consistency for both generalized regression estimators follow directly from the sequential two-stage sampling framework: non-probability units are assigned inclusion probability 1 as a certainty stratum, a probability sample is drawn from the complement, and GREG calibration ensures the design expectation equals the finite-population total via Horvitz-Thompson unbiasedness for auxiliaries. This holds conditionally on the observed stratum without reference to the non-probability selection mechanism or any fitted parameters derived from it. The optimality result for the separate estimator is explicitly conditional on a working superpopulation model and does not affect the consistency results. No self-definitional reductions, fitted-input predictions, or load-bearing self-citations appear in the load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Finite-population design-based inference framework
- domain assumption Ability to draw a probability sample from the previously unsampled units
Reference graph
Works this paper leans on
-
[1]
J.\ Breidt and J
F. J.\ Breidt and J. D.\ Opsomer. Model-assisted survey estimation with modern prediction techniques. Statistical Science. 2017
2017
-
[2]
Doubly robust inference with nonprobability survey samples
Y.\ Chen and P.\ Li and C.\ Wu. Doubly robust inference with nonprobability survey samples. Journal of the American Statistical Association. 2020
2020
-
[3]
Evaluating the impact of a non-probability sample-based estimator in a linear combination with an estimator from a probability sample
A.\ C iginas and D.\ Krapavickaitė and V.\ Nekrašaitė - Liegė. Evaluating the impact of a non-probability sample-based estimator in a linear combination with an estimator from a probability sample. Journal of Official Statistics. 2025
2025
-
[4]
J.\ Carroll
M.\ Davidian and R. J.\ Carroll. Variance function estimation. Journal of the American Statistical Association. 1987
1987
-
[5]
R.\ Elliott and R.\ Valliant
M. R.\ Elliott and R.\ Valliant. Inference for nonprobability samples. Statistical Science. 2017
2017
-
[6]
A.\ Fuller
W. A.\ Fuller. Sampling Statistics. 2009
2009
-
[7]
Integrating probability and big non-probability samples data to produce O fficial S tatistics
N.\ Golini and P.\ Righi. Integrating probability and big non-probability samples data to produce O fficial S tatistics. Statistical Methods & Applications. 2024
2024
-
[8]
T.\ Isaki and W
C. T.\ Isaki and W. A.\ Fuller. Survey design under the regression superpopulation model. Journal of the American Statistical Association. 1982
1982
-
[9]
J. K.\ Kim. Statistics in Survey Sampling. 2025
2025
-
[10]
K.\ Kim and S.\ Tam
J. K.\ Kim and S.\ Tam. Data integration by combining big data and survey sample data for finite population inference. International Statistical Review. 2021
2021
-
[11]
K.\ Kim and Z.\ Wang
J. K.\ Kim and Z.\ Wang. Sampling techniques for big data analysis. International Statistical Review. 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.