Recognition: unknown
Near-Policy: Accelerating On-Policy Distillation via Asynchronous Generation and Selective Packing
Pith reviewed 2026-05-08 14:15 UTC · model grok-4.3
The pith
Asynchronous generation with selective filtering lets on-policy distillation run at SFT speeds while staying near the student policy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
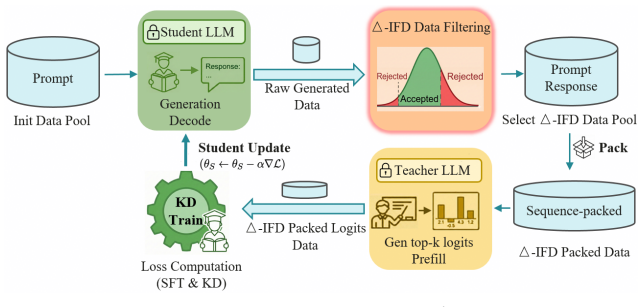
Near-Policy Distillation reformulates on-policy distillation as an asynchronous process: the student generates tokens independently, the data is packed for efficient supervised training, and two lightweight safeguards—sparse student refreshes and Δ-IFD sample filtering—keep the optimization inside a proximal zone around the current policy. The resulting procedure delivers the efficiency of SFT while preserving the distribution-matching benefits that on-policy methods normally obtain only through costly RL loops.
What carries the argument
The Δ-IFD filtering mechanism, which selects training samples whose importance-weighted deviation stays within a safe threshold, paired with asynchronous student generation and periodic sparse updates to counteract policy lag.
If this is right
- Training throughput rises by roughly 8 times because sequence packing and SFT-style loops replace per-step RL rollouts.
- A 1 B model trained this way can surpass a 1.7 B baseline on the reported benchmark, showing that narrower exploration space transfers to better final performance.
- The method supplies a cheap warm-start policy that subsequent RL stages can refine without starting from a fully off-policy SFT checkpoint.
- Because the safeguards are heuristic and lightweight, they can be added to existing distillation pipelines with minimal code change.
Where Pith is reading between the lines
- The same decoupling pattern could be applied to other on-policy algorithms that currently pay a heavy rollout cost, such as certain preference optimization loops.
- If the Δ-IFD threshold can be tuned automatically rather than by hand, the approach might generalize across model scales without per-task retuning.
- The observed narrowing of the exploration space suggests the filtered data acts as a soft curriculum; testing whether this effect compounds over multiple distillation rounds would be a direct next experiment.
Load-bearing premise
The combination of sparse student updates and Δ-IFD filtering is enough to keep the training data close enough to the current student policy that the optimization remains beneficial rather than noisy or biased.
What would settle it
Run the same downstream tasks with an unfiltered asynchronous baseline and measure whether performance collapses below the on-policy reference or whether the filtered version still matches the reference within statistical noise.
Figures




read the original abstract
Standard knowledge distillation for autoregressive models often suffers from distribution mismatch. While on-policy methods mitigate this by leveraging student-generated outputs, they rely on computationally expensive Reinforcement Learning (RL) frameworks. To improve efficiency, we propose Near-Policy Distillation (NPD), an asynchronous approach that decouples student generation from training. This reformulation enables Supervised Fine-Tuning (SFT) with sequence packing. However, asynchronous updates inevitably introduce policy lag and sample noise, which can cause the behavior to drift from near-policy toward off-policy. To counteract this without sacrificing efficiency, NPD integrates sparse student updates and the $\Delta$-IFD filtering mechanism, a heuristic sample selection mechanism that empirically stabilizes the optimization trajectory. By filtering extreme out-of-distribution samples, $\Delta$-IFD prevents noise from dominating the gradients, ensuring updates remain within a safe proximal learning zone. Empirically, the NPD framework achieves a 8.1x speedup over on-policy baselines and outperforms SFT by 8.09%. Crucially, by effectively narrowing the exploration space for subsequent RL, our method enables openPangu-Embedded-1B to reach a state-of-the-art score of 68.73%, outperforming the substantially larger Qwen3-1.7B. Codes will be released soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Near-Policy Distillation (NPD), an asynchronous framework for knowledge distillation of autoregressive models. It decouples student generation from training to enable efficient SFT with sequence packing, while using sparse student updates and a Δ-IFD filtering heuristic to counteract policy lag and sample noise, thereby keeping optimization near-policy. The central empirical claims are an 8.1× speedup over on-policy baselines, an 8.09% improvement over standard SFT, and a new SOTA score of 68.73% on openPangu-Embedded-1B that surpasses the larger Qwen3-1.7B model.
Significance. If the stabilization mechanisms prove robust, the work could meaningfully accelerate on-policy distillation pipelines that currently rely on expensive RL frameworks, making them more practical for large-scale language model training. The reported ability to narrow the exploration space for subsequent RL stages and achieve SOTA with a 1B model is potentially impactful for efficient model development.
major comments (2)
- [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): the reported 8.1× speedup and 8.09% gain over SFT are presented without any mention of the number of runs, random seeds, variance, statistical significance tests, or precise baseline implementations. This absence directly undermines evaluation of whether the sparse-update + Δ-IFD combination reliably prevents off-policy drift.
- [§3.2 (Δ-IFD Filtering)] §3.2 (Δ-IFD Filtering): the mechanism is introduced as a heuristic that filters extreme out-of-distribution samples to keep updates in a 'safe proximal learning zone,' yet no explicit formula, threshold derivation, or ablation isolating its contribution versus simple sparse updates is provided. Without this, the claim that it prevents selection bias while narrowing exploration space remains unverified.
minor comments (1)
- [Abstract] The abstract states 'Codes will be released soon' but provides no link or repository placeholder; this should be clarified or removed for a camera-ready version.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The points raised highlight important aspects of reproducibility and methodological clarity that we will address in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): the reported 8.1× speedup and 8.09% gain over SFT are presented without any mention of the number of runs, random seeds, variance, statistical significance tests, or precise baseline implementations. This absence directly undermines evaluation of whether the sparse-update + Δ-IFD combination reliably prevents off-policy drift.
Authors: We agree that the absence of these details limits the ability to assess reliability. In the revised version, we will report all main results as averages over three independent random seeds, including mean and standard deviation. We will also document the precise baseline implementations (including any re-implementation choices and hyperparameters) and note that formal statistical significance tests were omitted due to computational constraints, while variance metrics are provided to support evaluation of the stabilization mechanisms. revision: yes
-
Referee: [§3.2 (Δ-IFD Filtering)] §3.2 (Δ-IFD Filtering): the mechanism is introduced as a heuristic that filters extreme out-of-distribution samples to keep updates in a 'safe proximal learning zone,' yet no explicit formula, threshold derivation, or ablation isolating its contribution versus simple sparse updates is provided. Without this, the claim that it prevents selection bias while narrowing exploration space remains unverified.
Authors: We acknowledge that the current presentation of Δ-IFD is insufficiently detailed. The revised manuscript will include the explicit mathematical formula for the Δ-IFD score, explain the threshold selection process based on the empirical distribution of IFD values across generated batches, and add a dedicated ablation study in §4 comparing performance with and without Δ-IFD (as well as against sparse updates alone). These additions will directly verify the mechanism's contribution to maintaining near-policy behavior and mitigating selection bias. revision: yes
Circularity Check
No significant circularity; purely empirical engineering claims
full rationale
The paper presents NPD as an asynchronous engineering reformulation of on-policy distillation, relying on sparse updates and the heuristic Δ-IFD filter to maintain near-policy behavior. No equations, derivations, fitted parameters, or uniqueness theorems appear in the provided abstract or referenced full text. All central claims (8.1× speedup, +8.09% over SFT, SOTA score) are framed as experimental outcomes rather than reductions to self-defined inputs or self-citations. The method is self-contained against external benchmarks with no load-bearing step that collapses by construction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Δ-IFD filtering mechanism
no independent evidence
-
Near-Policy Distillation (NPD)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[2]
Gkd: Generalized knowledge distillation for auto- regressive sequence models,
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self- generated mistakes. InThe twelfth international conference on learning representations, 2024a. Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, M...
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review arXiv
-
[4]
URL https://api.semanticscholar.org/CorpusID: 11253972. Hanting Chen, Yasheng Wang, Kai Han, Dong Li, Lin Li, Zhenni Bi, Jinpeng Li, Haoyu Wang, Fei Mi, Mingjian Zhu, et al. Pangu embedded: An efficient dual-system llm reasoner with metacognition. arXiv preprint arXiv:2505.22375,
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé, Jared Kaplan, Harrison Edwards, Yura Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mo Bavarian, Clemens Winter, Phi...
work page internal anchor Pith review arXiv
-
[6]
MiniLLM: On-Policy Distillation of Large Language Models
URLhttps://arxiv.org/abs/2306.08543. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review arXiv
-
[7]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review arXiv
-
[8]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review arXiv
-
[9]
arXiv preprint arXiv:2305.08322 , year=
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, Fanchao Qi, Yao Fu, Maosong Sun, and Junxian He. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models.ArXiv, abs/2305.08322,
-
[10]
Sequence-level knowledge distillation
Yoon Kim and Alexander M Rush. Sequence-level knowledge distillation. InProceedings of the 2016 conference on empirical methods in natural language processing, pages 1317–1327, 2016a. Yoon Kim and Alexander M. Rush. Sequence-level knowledge distillation. 2016b. URL https: //arxiv.org/abs/1606.07947. Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se-Young Yun....
-
[11]
URLhttps://arxiv.org/abs/2402.03898. Jongwoo Ko, Tianyi Chen, Sungnyun Kim, Tianyu Ding, Luming Liang, Ilya Zharkov, and Se- Young Yun. Distillm-2: A contrastive approach boosts the distillation of llms
-
[12]
URL https://arxiv.org/abs/2503.07067. Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. Cmmlu: Measuring massive multitask language understanding in chinese.arXiv preprint arXiv:2306.09212,
-
[13]
From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning
Ming Li, Yong Zhang, Zhitao Li, Jiuhai Chen, Lichang Chen, Ning Cheng, Jianzong Wang, Tianyi Zhou, and Jing Xiao. From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech...
2024
-
[14]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review arXiv
-
[15]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108,
work page internal anchor Pith review arXiv 1910
-
[16]
Pangu ultra moe: How to train your big moe on ascend npus,
Yehui Tang, Yichun Yin, Yaoyuan Wang, Hang Zhou, Yu Pan, Wei Guo, Ziyang Zhang, Miao Rang, Fangcheng Liu, Naifu Zhang, et al. Pangu ultra moe: How to train your big moe on ascend npus. arXiv preprint arXiv:2505.04519,
-
[17]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review arXiv
-
[18]
Clue: A chinese language understanding evaluation benchmark.arXiv preprint arXiv:2004.05986,
Liang Xu, Hai Hu, Xuanwei Zhang, Lu Li, Chenjie Cao, Yudong Li, Yechen Xu, Kai Sun, Dian Yu, Cong Yu, et al. Clue: A chinese language understanding evaluation benchmark.arXiv preprint arXiv:2004.05986,
-
[19]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jian- hong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review arXiv
-
[20]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review arXiv
-
[21]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models.arXiv preprint arXiv:2309.12284,
work page internal anchor Pith review arXiv
-
[22]
Instruction-Following Evaluation for Large Language Models
12 Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911,
work page internal anchor Pith review arXiv
-
[23]
The evaluation metric is the average zero-shot accuracy across eight benchmarks
Table 11: Effect of KD loss weight on the average benchmark performance. The evaluation metric is the average zero-shot accuracy across eight benchmarks. All models use greedy decoding with a decode length of 8K. λKD 0.5 0.6 0.7 0.80.91.0 Average 53.94 54.07 53.88 54.4355.2954.44 Top-k Value Effect.To explore the impact of the number of top tokens used in...
-
[24]
Hence, we adoptλ KD = 0.9and top-k=10 by default unless otherwise specified. Table 12: Effect of top- k value on the average benchmark performance. All models use greedy decoding with a decode length of 8K, and the KD loss weight is fixed atλ KD = 0.9. Top-k51015 20 Average Performance 54.7855.2954.24 54.40 C Theoretical and Empirical Analysis C.1 Analysi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.